接触这篇paper的理由——据说这是第一篇将GAN应用到超分领域的论文。在SRGAN之前,个人认为,超分网络的本质就是从某一分辨率的图像想尽各种办法恢复成更高分辨率的图像,也就是想尽各种办法进行上采样操作,比如说插值、先插值再卷积、先Padding再卷积等等等等。那我们如何打破这种传统的上采样的模式去考虑超分辨率并且如何恢复更加逼真的图像——这就是SRGAN做的事情,也是我觉得这篇论文很新颖的地方。
Paper:Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
Github:Keras-SRGAN
1、为什么提出SRGAN?
这篇文章在开始的时候提到了,在超分辨率问题中有三种图像:HR图像(高分辨率图像)、LR图像(低分辨率图像)、SR图像(超分后的高分辨率图像),通过比较HR图像和SR图像可以发现,虽然训练网络时用均方差作为损失函数,虽然能够获得很高的峰值信噪比,但是SR图像中丢失了很多的高频信息,并不能让人有很好的视觉感受。那么问题就来了,如何在上采样过程中恢复更多的细节信息? 作者从Perceptual Losses for Real-Time Style Transfer and Super-Resolution这篇论文中得到了启示,这篇论文如果做过Neural Style的伙伴们肯定不陌生,这篇论文主要内容就是两个部分:一个是Fast Neural Style(快速的画风迁移),另一个是提出了一种单张图像的超分辨率算法。此外,在这篇文章中还提出了一种新的损失Perceptual Loss(感知损失),感知损失由三个部分组成:感知损失=特征重构损失+风格重构损失+简单损失,不仅考虑到了特征重构后的相似性,也考虑到了低层特征的相似性。感兴趣的伙伴们可以看我之前的博客深度学习与艺术——Fast Neural Style,里面详细介绍了这两个部分。
我们来思考一个问题,为什么超分中丢失的是高频信息?
我们可以这样考虑,超分问题的本质是通过不同的上采样的方式从一个低分辨率图像恢复到高分辨率图像,从像素级别的角度来看,这是一个一对多或者多对多的问题,那么我们就可以认为这是一个回归问题。既然是回归问题,在拟合的过程中要保证尽量多的信息可以恢复准确,而在图像中,低频信息占大多数,而高频信息占少数,所以在超分问题中高频信息就丢失了。
言归正传,我们来看SRGAN。SRGAN的独特性不仅仅是是将GAN和SR结合了起来,更多的工作是在损失函数上的设计。从GAN的角度来看,是两个分支:生成网络和判别网络。生成网络的主要工作是得到超分后的图像,判别网络的主要工作是判别生成网络生成的图像是真还是假。在SRGAN中还加入了一个vgg的网络,做为新加入的loss。
SRGAN主要由如下三个贡献:
(1)使用16个block的SRResNet做为backbone,上采样因子为x4,在超分评价指标PSNR和SSIM上取得了最好的成绩;
(2)提出了一种基于GAN网络的新损失——感知损失;
(3)我们在三个公共的数据集上测试了MOS,并且验证SRGAN是当时最好的算法;
2、SRGAN的网络模型
SRGAN的网络模型如下图所示,网络很简单,主要是生成器、判别器和vgg网络。训练过程中生成器和判别器交替训练,不断迭代;vgg网络使用在ImageNet上预训练的权重,权重不做训练和更新,只参与Loss的计算。
生成器:【3x3 conv + BN + PReLU + 2 sub-pixel conv】 x n
生成器是在SRResNet的基础上做了改进,在生成网络部分(SRResNet)部分包含多个残差块,每个残差块中包含两个3×3的卷积层,卷积层后接批规范化层(batch normalization, BN)和PReLU作为激活函数,两个2×亚像素卷积层(sub-pixel convolution layers)被用来增大特征尺寸。
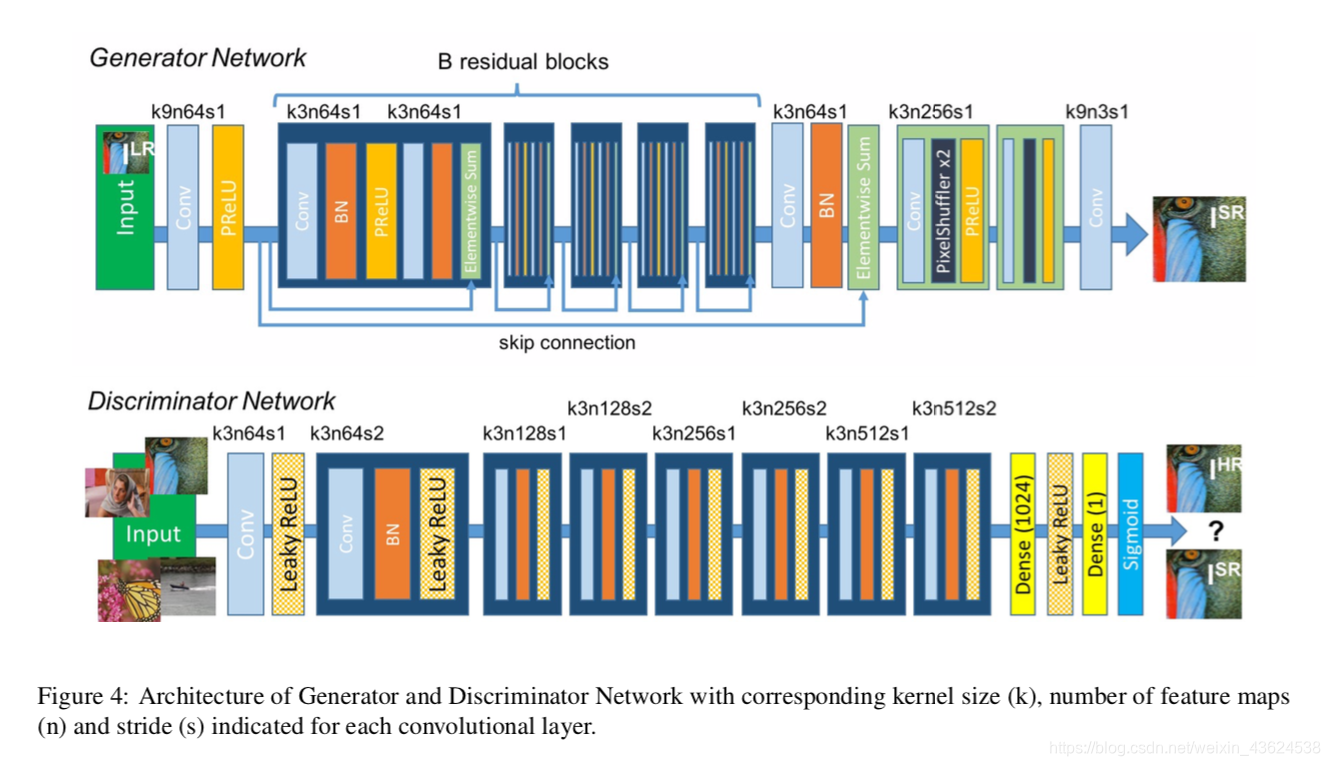
判别器:【8 conv + LeakyReLU + 2 fc + sigmoid】
在判别网络部分包含8个卷积层,随着网络层数加深,特征个数不断增加,特征尺寸不断减小,选取激活函数为LeakyReLU,最终通过两个全连接层和最终的sigmoid激活函数得到预测为自然图像的概率。
vgg网络:【Pretrained vgg loss】
本文在生成器结束以后生成的SR图像输送到在ImageNet上已经预训练好的网络,在训练时不训练权重,只参与Loss的计算。
3、SRGAN的损失函数
以往的SR问题的损失函数都是基于MSE的,作者受到Perceptual Loss这篇文章的启发,提出了SRGAN的损失函数,分别为G_Loss和D_Loss。
G_Loss是GAN的生成器的损失,内容损失(Content loss)里面包括MSE loss和VGG loss, 损失函数具体如下:
其中,
l
X
S
R
l^{SR}_{X}
lXSR是内容损失(content loss),
l
G
e
n
S
R
l^{SR}_{Gen}
lGenSR是对抗损失。
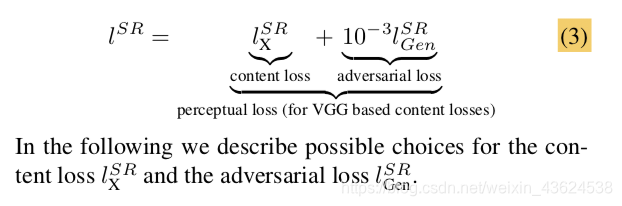
我们可以这样理解:MSE loss计算的是像素间的匹配程度,Vgg loss计算的是某一特征层的匹配程度。这样设计的理由:因为在SR问题中,常见的评价指标由两种PSNR和SSIM,使用MSE可以得到很好的PSNR和SSIM的值,但是通过比较发现,只使用MSE loss超分后的图像丢失了很多的高频信息,这使图像的直接感受效果也不好,所以我们需要将高频的信息更有效的恢复出来,所以加入了经过预训练网络的vgg损失,希望在Feature Map上也有约束和比较。
MSE损失公式如下:
Vgg损失公式如下:
对抗损失公式如下:
D_Loss是GAN网络判别器的损失,和普通的GAN网络判别器的损失基本一样,具体的损失公式如下:
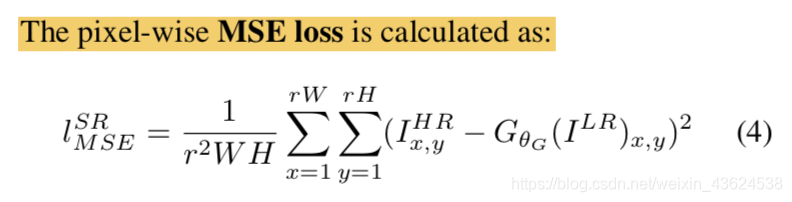

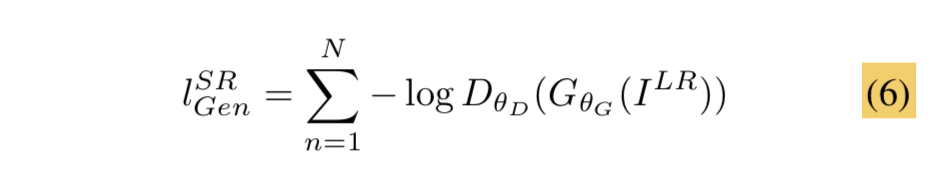
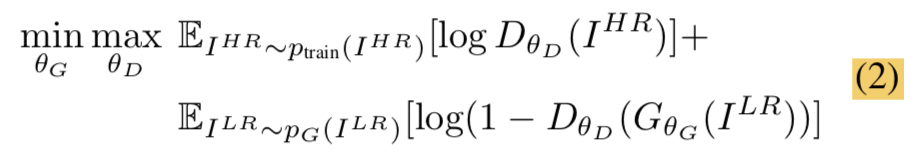
4、SRGAN的评价指标
我们在博客的最开始提到,从HR图像和SR图像比较发现,SR图像是缺少高频信息的,所以我们在损失函数中加入了对于恢复高频信息的损失设计。那么反过来思考,为什么缺少高频信息的人眼感受较差的SR图像却在PSNR和SSIM这两个指标中表现良好?是不是在评价指标的设计过程中也存在一定的问题呢?
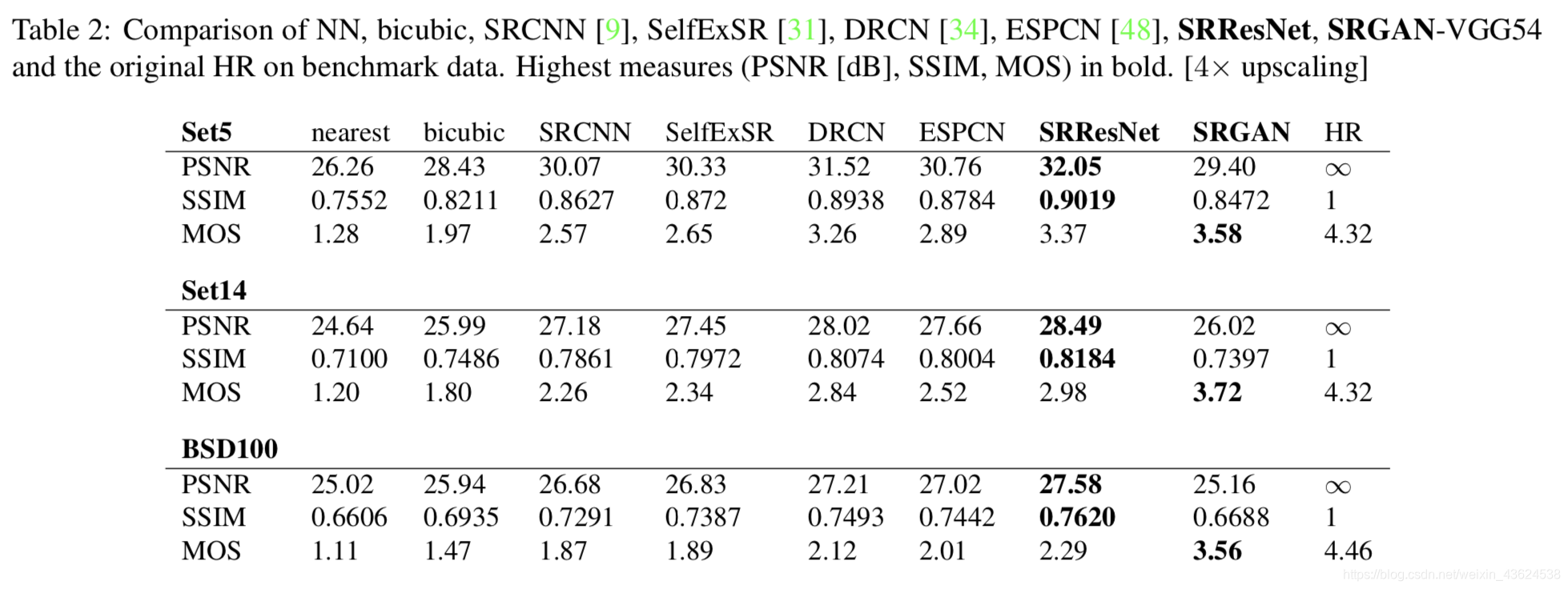
所以在本文中,除了用PSNR和SSIM来衡量超分的效果,还用了MOS(Mean opinion score)来衡量超分的效果。我们要求26名评分者对于不同算法超分后的图像进行从1分-5分的品质打分,可以看出我们的SRGAN算法虽然在PSNR和SSIM上略微逊色,但是在MOS的指标上还是很出色的。下图就是几种超分算法在Set5、Set14和BSD100上的三种指标的结果:
5、SRGAN的代码详解
再给大家安利一下这个代码Keras-GAN,这是用Keras搭建的各种基础GAN的网络,Keras框架封装性超好,虽然用起来有些局限,对于新手来说还是很快可以上手的。我们就拿这个代码中的SRGAN做一个简单的代码详解。
可以看到,在SRGAN中只有两个文件,data_loader.py和srgan.py,data_loader.py文件主要是数据的获取和处理成低分辨率的图像;srgan.py文件主要是搭建网络和训练过程。我们使用的是celeba的人脸数据集,先给大家放上我们迭代4000次的图像结果。
我们主要来看一下srgan.py的代码内容。在SRGAN网络中主要需要搭建三个部分:vgg,GAN的生成网络,GAN的判别网络。 所以我们要清楚每个网络的输入输出是什么,如下表:


| 子网络 | 输入 | 输出 | 损失 |
|---|---|---|---|
| SRGAN_G网络 | 低分辩率LR图像 | 经过生成器的超分SR图像 | 对抗生成损失 |
| vgg网络 | SRGAN生成器产生的SR图像 | 经过预训练的vgg网络的Feature Map | vgg的损失 |
| SRGAN_D网络 | SRGAN生成器产生的SR图像和高分辨率HR图像 | 判断图像的True/False | 对抗生成损失 |
需要注意的的几个细节:
细节一: 训练过程中vgg网络的权重是预训练的,我们在GAN训练的过程中是不训练vgg网络的,所以在代码中需要设置trainable=False。
self.vgg = self.build_vgg()
self.vgg.trainable = False # 关闭训练权重的过程
self.vgg.compile(loss='mse', optimizer=optimizer, metrics=['accuracy'])
细节二: GAN的训练中很重要的是判别器的训练,理论上生成器的训练和判别器的训练是相辅相成的,GoodFellow在原始GAN的论文中提到,生成器和判别器的就像造假钞的人和验假钞的专家,如果造假钞的人技术越高超,那么验假钞的专家技术也越高超。那么,在判别器中如何判别这些图的真假?也就是说,图的真假由grondtruth或者label是真/假。 所以,在图像输入判别器之前还有打label的过程。
# Train Networks
imgs_hr, imgs_lr = self.data_loader.load_data(batch_size)
# 标注真的HR图像为真
valid = np.ones((batch_size,) + self.disc_patch)
# 得到经过vgg网络输出的Feature Map
image_features = self.vgg.predict(imgs_hr)
# 得到g_loss
g_loss = self.combined.train_on_batch([imgs_lr, imgs_hr], [valid, image_features])
6、代码运行报错解决
【20190808-20190813】
运行Keras-GAN srgan(celeba)的代码,这个是GAN用在超分上的始祖,所以还是比较重要的,光看代码就看了好几天,还有乱七八糟的配环境的事情。
Code报错一:AttributeError: module ‘scipy’ has no attribute 'misc’
Traceback (most recent call last):
File "srgan.py", line 273, in <module>
gan.train(epochs=1, batch_size=1, sample_interval=50)
File "srgan.py", line 202, in train
imgs_hr, imgs_lr = self.data_loader.load_data(batch_size)
File "/home/tensor/jupyter/xmq/HCL2000-1000/Keras-GAN/srgan/data_loader.py", line 21, in load_data
img = self.imread(img_path)
File "/home/tensor/jupyter/xmq/HCL2000-1000/Keras-GAN/srgan/data_loader.py", line 44, in imread
return scipy.misc.imread(path, mode='RGB').astype(np.float)
AttributeError: module 'scipy' has no attribute 'misc'
解决办法: pip install scipy==1.0.0
问题解决(原因:scipy版本过高)
Code报错二:Discrepancy between trainable weights and collected trainable
/home/tensor/anaconda2/envs/tensorflow/lib/python3.6/site-packages/keras/engine/training.py:490: UserWarning: Discrepancy between trainable weights and collected trainable weights, did you set `model.trainable` without calling `model.compile` after ? 'Discrepancy between trainable weights and collected trainable'
解决办法: 需要区分不同的model
keras.compile()和keras.trainable()容易混淆,要把model区分开来;修改后的代码为:
# Build and compile the discriminator
base_discriminator = self.build_discriminator()
#self.discriminator = self.build_discriminator()
self.discriminator = Model(inputs=base_discriminator.inputs, outputs=base_discriminator.outputs)
self.discriminator.compile(loss='mse', optimizer=optimizer, metrics=['accuracy'])
# Build the generator
base_generator = self.build_generator()
#self.generator = self.build_generator()
self.generator = Model(inputs=base_generator.inputs, outputs=base_generator.outputs)
# High res. and low res. images
img_hr = Input(shape=self.hr_shape)
img_lr = Input(shape=self.lr_shape)
# Generate high res. version from low res.
fake_hr = self.generator(img_lr)
# Extract image features of the generated img
fake_features = self.vgg(fake_hr)
# For the combined model we will only train the generator
#self.discriminator.trainable = False
frozen_D = Model(inputs=base_discriminator.inputs, outputs=base_discriminator.outputs)
frozen_D.trainable = False
# Discriminator determines validity of generated high res. images
validity = frozen_D(fake_hr)
self.combined = Model([img_lr, img_hr], [validity, fake_features])
self.combined.compile(loss=['binary_crossentropy', 'mse'], loss_weights=[1e-3, 1], optimizer=optimizer)
8、最后的Conclusion
在SRResNet的基础上,和GAN网络结合,提出了SRGAN的算法网络,并且设计了新的损失函数,增加了内容损失和对抗损失,以解决超分问题中如何恢复高频信息。在超分的评价指标上,仍以PSNR和SSIM评价指标为中心,但是加入MOS评价指标,在超分问题上取得了较好的效果。顺便提一句,在2018年ECCV的PIRM workshop上,ESRGAN被提出,我们也会在后续的博客中详细分享增强版的ESRGAN。