-
本文翻译整理自编程🐷的这篇文章
-
博主自己也去看了编程🐷提到的相关源码(通过vscode查找)
-
代码版权所有(c)2017 The Chromium Authors
-
博主对编程🐷的文章进行了小幅度修改(比如客户端请求时返回frame的 stream id 的单数应该是服务器造成的,即:frame发送方的stream id)
-
😛读完本文您可以学到HTTP/2的几种特性
-
头部压缩,通过规定头部字段的静态表格和实际传输过程中动态创建的表格,减少多个相似请求里面大量冗余的HTTP头部字段,并且引入了霍夫曼编码减少字符串常量的长度。
-
多路复用,
只使用一个TCP连接传输多个资源,减少TCP连接数,为了能够让高优先级的资源如CSS等更先处理,引入了优先级依赖的方法。由于并发数很高,同时传递的资源很多,如果网速很快的时候,可能会导致缓存空间溢出,所以又引入了流控制,双方通过window size控制对方的发送。 -
Server Push,解决传统HTTP传输中
资源加载触发延迟的问题,浏览器在创建第一个流的时候,服务告诉浏览器哪些资源可以先加载了,浏览器提前进行加载而不用等到解析到的时候再加载。
文章目录
1、头部压缩
HTTP头部是比较长的,如果发送数据比较小,也要发送一个头部。
就比如下面只有12个字节的text,然而要发300个字节,HTTP报文头就占了288字节
如果请求数太多就会导致吞吐量不高,并且,比较大的HTTP头部会迅速占满慢启动过程中的拥塞窗口,导致延迟变大。
PS:

-
算法的思路:主机开发发送数据报时,如果立即将大量的数据注入到网络中,可能会出现网络的拥塞。慢启动算法就是在主机刚开始发送数据报的时候先探测一下网络的状况,如果网络状况良好,发送方每发送一次文段都能正确的接受确认报文段。那么就从小到大的增加拥塞窗口的大小,即增加发送窗口的大小。
-
例子:开始发送方先设置cwnd(拥塞窗口)=1,发送第一个报文段M1,接收方接收到M1后,发送方接收到接收方的确认后,把cwnd增加到2,接着发送方发送M2、M3,发送方接收到接收方发送的确认后cwnd增加到4,慢启动算法每经过一个传输轮次(认为发送方都成功接收接收方的确认),拥塞窗口cwnd就加倍。
对常用HTTP头部字段编号
其中冒号开头的如:method是请求行里的,2就表示Method: POST,如果要表示Method: OPTION呢?用下面的表示:

0206OPTION
其中02表示在静态表格的索引index,查一下这个表格可知道2表示的Header Name为:method。接着的06表示method名的长度为6,后面紧接着就是字段的内容即method名为OPTION。那它怎么知道02后面跟着的06不是表示index为6的":scheme http"的头字段呢?因为如果Header Name和Header Value都是用的这个表的,如Method POST表示为:
0x82
而不是02了,这里就是把第8位置成了1,变成了二进制的1000 0002,表示name/value完全匹配。而如果第8位不是1,如0000 0002那么value值就是自定义的,后面紧跟着的一个字节就是表示value的字符长度,然后再跟着相应长度的字符。
value字符霍夫曼编码
value字符是使用霍夫曼编码的,规范根据字符的使用频率高低定了一个编码表,这个编码表把常用的字符的大小控制在5 ~ 7位,比ASCII编码的8位要小些。根据编码表:
OPTION会被编码为:6a6b 6f64 6a69,所以Method: OPTION最终被编码为:
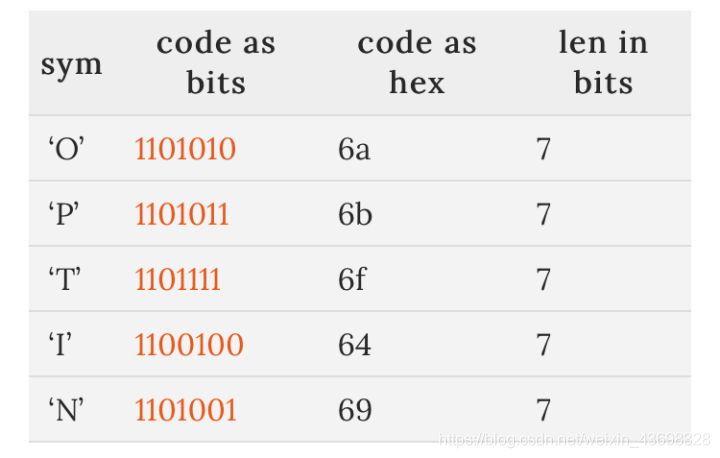
0206 6a6b 6f64 6a69
一共是8个字节,原先用字符串需要14个字节。
多次请求时从静态压栈(越晚越靠前)到动态列表
还有,如果有多次请求,后面的请求有一些头部字段和前面的一样,那么会用一个动态表格维护相同的头部字段。如果name/value是在上面说的静态表格都有的就不会保存到动态表格。动态表格可以用一个栈或者动态数组来存储。
例如,第一次请求头部字段"Method: OPTION"在静态表格没有,它会被压到一个栈里面去,此时栈只有一个元素,用索引为62 = 61 + 1表示这个字段,在接下来的第二次、第三次请求如果用到了这个字段就用index为62表示,即遇到了62就表示Method: OPTION。如果又有其它一个自定义字段被压到这个栈里面,这个字段的索引就为62,而Method: OPTION就变成了63,越临近压进去的编号就越往前。
静态表格的index是从1开始,动态表格是从62开始,而index为0的表示自定义字段名,用key长度 + key + value长度 + value表示,当把它这个自定义字段压到动态表格里面之后,它就有index了。当然,可以控制是否需要把字段压到动态表格里面,通过设定标志位,这里不展开说明。
有关HPACK算法
Chromium源码进行
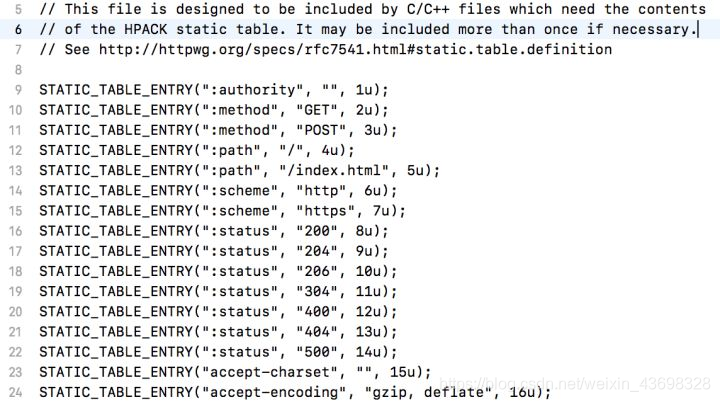
Chrome是在src/net/http2/hpack这个目录做的头部解析,静态表格是在这个文件hpack_static_table_entries,如下图所示:
根据文档,头部动态表格默认最多的字段数为4096:
// The last received DynamicTableSizeUpdate value, initialized to
// SETTINGS_HEADER_TABLE_SIZE.
size_t size_limit_ = 4096; // Http2SettingsInfo::DefaultHeaderTableSize();
可在传输过程中动态改变,受对方能力的限制,因为不仅是存自己请求的字段,还要有一个表格存对方响应的字段。
Chrome里的动态表格是用一个向量vector的数据结构表示的:
const std::vector<HpackStringPair>* const table_;
vector就是C++里面的动态数组。每次插入的时候就在数组前面插入:
table_.push_front(entry);
而查找的时候,直接用数组的索引去定位,下面是查找动态数组的:
// Lookup函数
index -= kFirstDynamicTableIndex; // kFirstDynamicTableIndex等于62
if (index < table_.size()) {
const HpackDecoderTableEntry& entry = table_[index];
return entry;
}
return nullptr;
2、多路复用
HTTP/1.1到HTTP/2实现并发
传统的HTTP/1.1为了提高并发性,得通过提高连接数,即同时多发几个请求,因为一个连接只能发一个请求,所以需要多建立几个TCP连接。建立TCP连接需要线程开销,我们知道Chrome同一个域最多同时只能建立6个连接。所以就有了雪碧图、合并代码文件等减少请求数的解决方案。
在HTTP/2里面,一个域只需要建立一次TCP连接就可以传输多个资源。多个数据流/信号通过一条信道进行传输,充分地利用高速信道,就叫多路复用(Multiplexing)。
在HTTP/1.1里面,一个资源通过一个TCP连接传输,一个大的资源可能会被拆成多个TCP报文段,每个报文段都有它的编号,按照从前往后依次增大的顺序,接收方把收到的报文段按照顺序依次拼接,就得到了完整的资源。当然,这个是TCP传输自然的特性,和HTTP/1.1没有直接关系。
那么怎么用一个连接传输多个资源呢?
HTTP/2把每一个资源的传输叫做流Stream,每个流都有它的唯一编号stream id,一个流又可能被拆成多个帧Frame,每个帧按照顺序发送,TCP报文的编号可以保证后发送的帧的顺序比先发送的大。在HTTP/1.1里面同一个资源顺序是依次连续增大的,因为只有一个资源,而在HTTP/2里面它很可能是离散变大的,中间会插着发送其它流的帧,但只要保证每个流按顺序拼接就好了。如下图所示:
为什么叫它流呢,因为数据就像水流一样会流动,所以叫它为流/数据流,流的特点是有序的,它是数据的一个序列。它可以从键盘传到内存,再由内存传输到硬盘,或者传输到服务端。
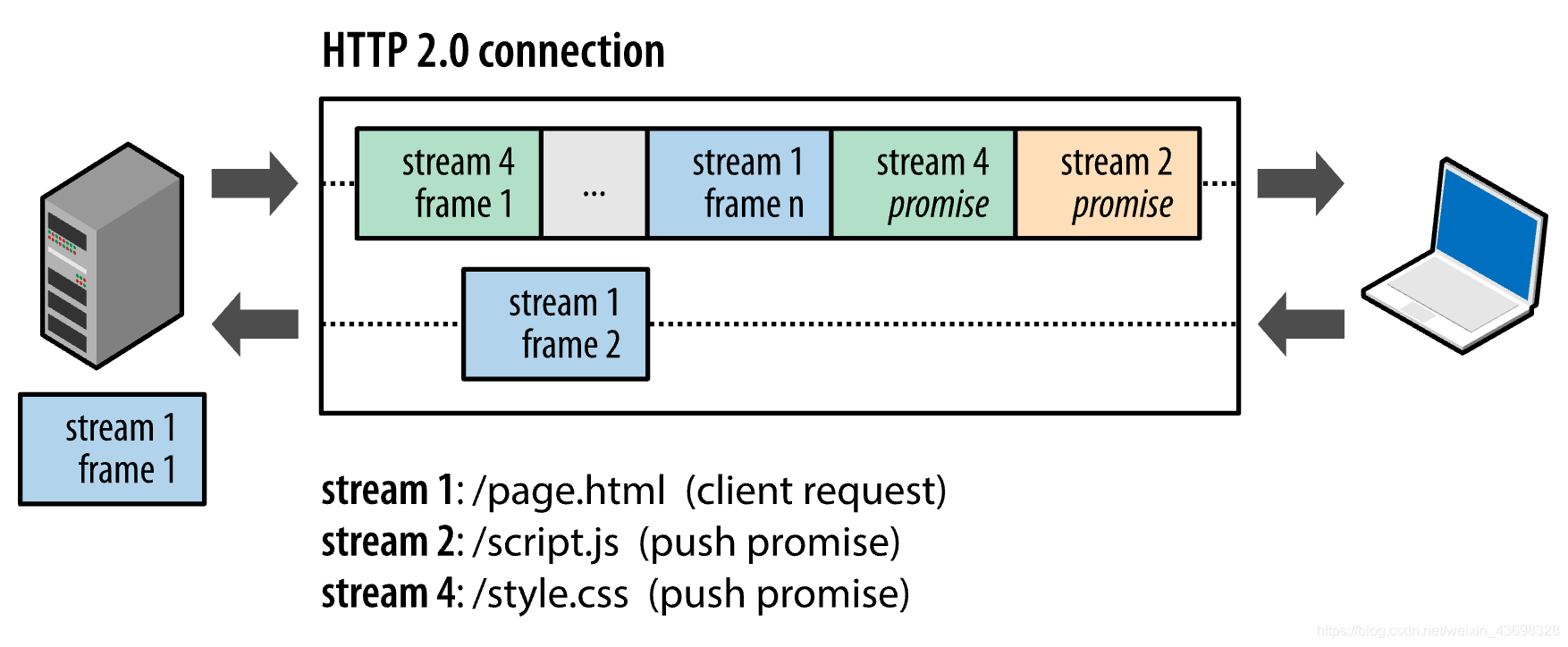
帧的格式
在通信里面,流被分成若干帧,HTTP/2规定了11种类型的帧,包括HEADERS/DATA/SETTINGS等
HEADERS是用来传输http头部的
DATA是用来发送请求/响应数据的
SETTINGS是在传输过程中用来做控制的。
一个帧的格式如下图所示:

- 帧的头部有9个字节(72位)
- 前3个字节(24位)表示帧有效数据(Frame Payload)的长度,所以每个帧最大能传送的数据为2 ^ 24 = 16MB,但标准规定默认最大为2 ^ 14 = 16Kb,除非双方通过settings帧进行控制。
- 第4个字节Type表示帧类型,如0x0表示data,0x1是headers,0x4是settings。
- Flags是每种帧用来控制一些参数的标志位,如在data帧里面第一个标志位打开0x1是表示END_STREAM,即当前数据帧是当前流的最后一个数据帧。
- Stream Identifier是流的标志符即流的编号,它的首位R是保留位(留着以后用)。
- 最后就是Payload,当前帧的有效负载。
流和帧的传输
每个请求都会创建一个流,每个流的创建都是请求方通过发送头部帧,即头部帧用来打开一个流,每个流都有它的优先级,放在头部帧里面。流的头部帧还包含了上面第1点提到的HTTP压缩头部字段。
每个流都有一个半关闭的状态,当一方收到END_STREAM的时候,当前流就处于半关闭(remote)的状态,这个时候另一方不再发送数据了,当前方也发一个END_STREAM给对方的时候,这个时候流就处于完全关闭的状态。已关闭的流的编号在当前连接不能复用,避免在新的流收到延迟的相同编号的老的流的帧。所以流的编号是递增的。 (四次挥手的第二次和第四次)
更多请参考
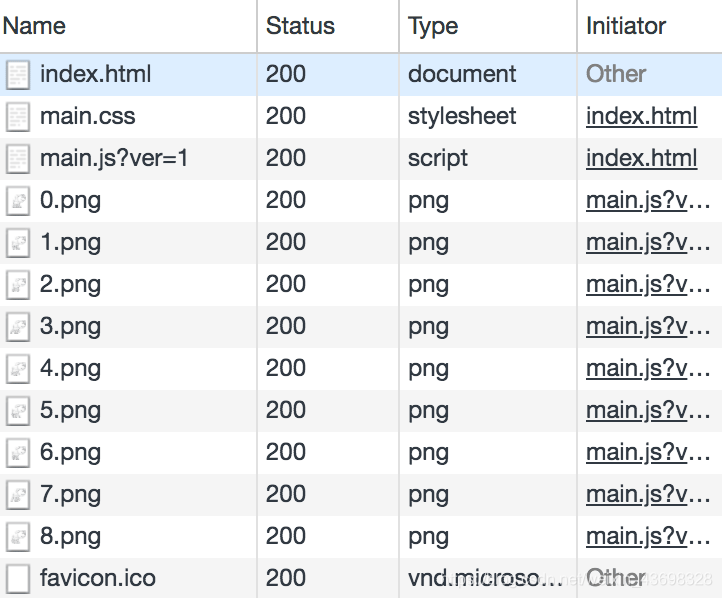
我们以访问Walking Dog这个页面做为说明,看一下流和帧是怎么传输的,这个页面总共加载13个资源:
包括index.html、main.js、main.css和10张图片。
Chrome解码HTTP/2帧的目录在src/net/http2,而编码的目录在src/net/spdy。
// Copyright 2017 The Chromium Authors. All rights reserved.
// Use of this source code is governed by a BSD-style license that can be
// found in the LICENSE file.
#include <stddef.h>
#include <stdint.h>
#include <fuzzer/FuzzedDataProvider.h>
#include <list>
#include <vector>
#include "net/third_party/quiche/src/http2/decoder/http2_frame_decoder.h"
// Entry point for LibFuzzer.
extern "C" int LLVMFuzzerTestOneInput(const uint8_t* data, size_t size) {
FuzzedDataProvider fuzzed_data_provider(data, size);
http2::Http2FrameDecoder decoder;
// Store all chunks in a function scope list, as the API requires the caller
// to make sure the fragment chunks data is accessible during the whole
// decoding process. |http2::DecodeBuffer| does not copy the data, it is just
// a wrapper for the chunk provided in its constructor.
//将所有块存储在函数作用域列表中,因为API要求调用方确保片段块数据在整个解码过程中是可访问的。|http2::DecodeBuffer|不复制数据,它只是在其构造函数中提供的块的包装。
std::list<std::vector<char>> all_chunks;
while (fuzzed_data_provider.remaining_bytes() > 0) {
size_t chunk_size = fuzzed_data_provider.ConsumeIntegralInRange(1, 32);
all_chunks.emplace_back(
fuzzed_data_provider.ConsumeBytes<char>(chunk_size));
const auto& chunk = all_chunks