目录
优化主要包括 4 个方面:
(1)综合优化 综合优化使得设计系统在FPGA中的映射得到最大优化。
(2)布局布线优化 在布局布线过程中,合理的约束会大大提高整个系统的布局布线效果; (3)设计优化 在设计阶段规划整个系统的架构,利用FPGA的特点尽可能简化设计;
(4)静态时序分析 静态时序分析用于在布局布线后检查整个工程的时序,找出最差的路径,进行一定的调整和修改来优化系统时序;
Quartus Prime优化设置
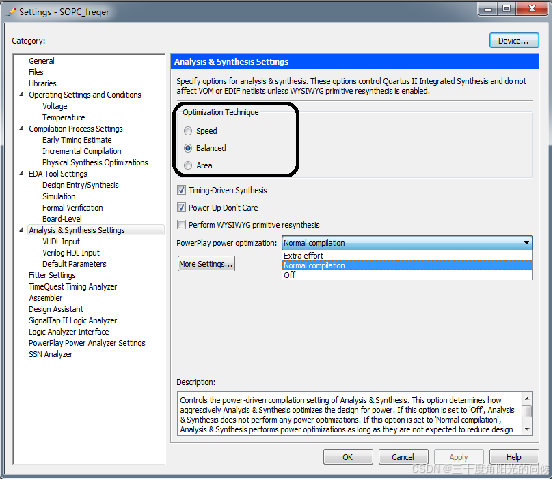
1. 分析与综合设置
Speed 是以提高系统的工作速度为目标进行优化,Area 是以节约占用的 逻辑资源为目标进行优化,而 Balanced 选项则是速度与占用资源的折中选项。
2. 物理综合优化
逻辑综合是将 HDL代码转换成不含布局布线信息并且能够映射(map)到门级电路过程。因为逻辑综合不包含布局布线的信息,所以综合后的时序仅限于转换后的门级电路 或者器件内部逻辑单元或者节点间逻辑单元级数等时延信息,而对于 FPGA 内部互联的时延是无法分析的。
物理综合是通过改变网表的布局(placement)优化综合结果, 在不改变设计功能的情况下调整网表的布局或者修改增加部分节点从而达到优化设计性能和设计资源利用率等目的。
(1)针对性能的物理综合优化选项
Perform Physical synthesis for combinationial logic: 用于优化组合逻辑关键路径的逻辑层数。
Perform Register Retiming: 通过移动寄存器中组合逻辑中的位置来平衡寄存器之间的路径时延以提升系统性能。 Perform automatic asynchronous signal pipelining: 是通过自动在异步 信号路径上插入流水寄存器来改善异步信号的建立时间和保持时间。 Perform register duplication: 是通过寄存器复制优化多扇出长路径上的时序,从而提升系统的性能。
effort level: 不同级别的差异主要体现在了编译时间的长短,与性能的提升呈反比的关系。
(2)针对面积的物理综合优化选项
针对面积的物理综合优化选项适用于适配(fit)阶段的优化,其功能就是使得设计优化可以适配到目标器件。 Physical Synthesis for Combinational Logic: 是指适配时针对组合逻辑的优化,尽可能地减少组合逻辑以提高资源利用率,只有在“no-fit”事件发生时才会起作用。
Logic to MemoryMapping: 是指在适配时将部分逻辑移到未使用的Memory里,同样也是在“no-fit”事件发生时才会起作用。
3. 适配设置
适配设置包括保持时序优化和多拐角时序优化。 保持时序优化(Optimize hold timing)允许适配器通过在合适的路径中添加延迟,从而实现保持时序的优化。关闭该选项时,则不会对任何路径进行优化。 多拐角时序优化(Optimize multi-corner timing)用于控制适配器是否对设计进行优化以 满足所有拐角的时序要求和操作条件。使用这项功能,必须使能时序逻辑优化。
Extra effort模式需要的编译时间比较长,但可以提高系统的最高工作频率; Off 模式可以节省约 50%的编译时间,但会使最高工作频率有所降低; Normal compilation模式在达到设计要 求的条件下,自动平衡最高工作频率和编译时间
描述方法对综合的影响
1. 操作符的应用差异
对于代码(1)
input[3:0] din;
output dout;
assign dout = (xin == 4'b0); // 关系操作符
若应用代码(2)
input [3:0] din;
output dout;
assign dout = (xin == 4'b0)? 1'b1 : 1'b0; // 条件操作符

若应用代码(3)
input[3:0] din;
output dout;
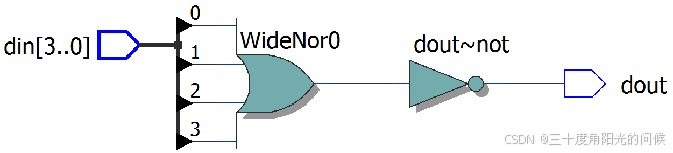
assign dout = ~|xin; // 缩位或非
应用代码(4)
input[3:0] din;
output dout;
assign dout=~(din[3]+din[2]+din[1]+din[1]) // 或非逻辑
2. 条件语句和分支语句的应用差异
if...else if...语句隐含有优先级的关系,综合出的电路通常为级联结构的优先编码器,传输延迟时间长,建议输入信号有优先级的的场合使用。 case 语句每个分支是平行的,综合为多路选择器,电路结构规整,传输延迟时间短,因而电路的工作速度快。
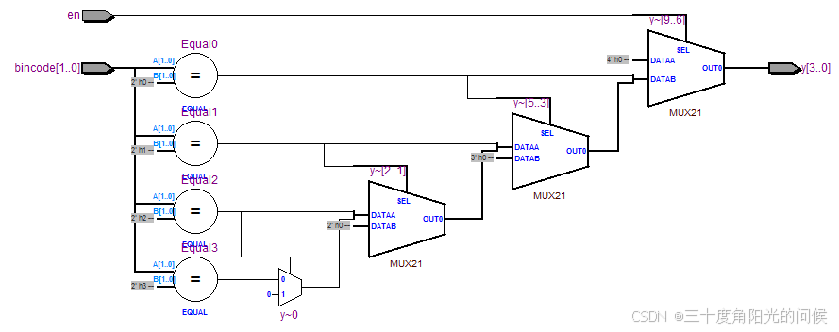
应用多重条件语句描述 2-4线译码器:
module decoder_2to4(en,bincode,y);
input en;
input [1:0] bincode;
output [3:0] y;
reg [3:0] y;
always @(en or bincode )
if (en) begin
if ( bincode == 2'b00 )
y = 4'b0001;
else if ( bincode == 2'b01 )
y = 4'b0010;
else if ( bincode == 2'b10 )
y = 4'b0100;
else if ( bincode == 2'b11 )
y = 4'b1000;
else
y= 4'b0000;
end
else
y = 4'b0000;
endmodule
2-4线译码器综合出的RTL电路:
若改用分支语句描述,其功能描述语句为
always @(en or bincode )
if (en)
case ( bincode )
2'b00: y = 4'b0001;
2'b01: y = 4'b0010;
2'b10: y = 4'b0100;
2'b11: y = 4'b1000;
default: y = 4'b0000;
endcase
else
y = 4'b0000;
endmodule
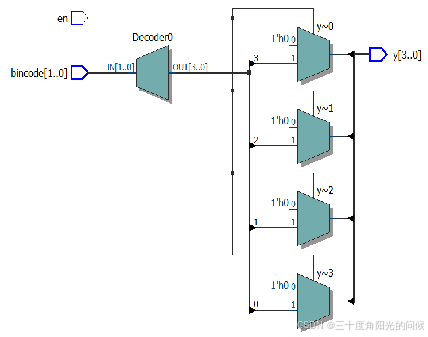
上述两种描述方式从综合效果看,占用的硬件资源相同,但应用 case 语句比用条件语句综合出的电路传输延迟时间小,因此,在速度优化的项目中,使用 case 语句效果更好。 但需要注意的是,无论是用 if 语句还是用 case 语句描述组合电路时,一定要防止综合出不必要的锁存器,这就要求: (1)在 case 语句中配套使用 default 语句; (2)在赋值表达式中,参与赋值的所有量(线网/变量)都必须在 always 语句的事件列表中列出; (3)if 语句判断表达式中的所有量都必须在always 语句中的事件列表中列出。
3. 描述方式对综合电路的影响
Verilog支持行为描述、数据流描述和结构描述三种方式描述应用电路。描述方式不同,综合占用的资源不同,综合出的电路性能也有差异。明晰这些描述方式之间的差异,对于优化电路的性能有着至关重要的影响。
对于具有使能端的3-8线译码器,若应用行为方式描述,则Verilog描述代码参考如下:
module dec3_8a(s_n,bincode,y_n);
input s_n;
input [2:0] bincode;
output reg [7:0] y_n;
always @(s_n,bincode)
if (!s_n)
case (bincode)
3'b000: y_n=8'b11111110;
3'b001: y_n=8'b11111101;
3'b010: y_n=8'b11111011;
3'b011: y_n=8'b11110111;
3'b100: y_n=8'b11101111;
3'b101: y_n=8'b11011111;
3'b110: y_n=8'b10111111;
3'b111: y_n=8'b01111111;
default: y_n=8'b11111111;
endcase
else
y_n=8'b11111111;
endmodule
若采用数据流方式描述,Verilog参考代码如下:
module dec3_8b(s_n,a,y_n);
input s_n;
input [2:0] a;
output [7:0] y_n;
assign y_n[0]=~((~s_n)&(~a[2])&(~a[1])&(~a[0]));
assign y_n[1]=~((~s_n)&(~a[2])&(~a[1])&a[0]);
assign y_n[2]=~((~s_n)&(~a[2])&a[1]&(~a[0]));
assign y_n[3]=~((~s_n)&(~a[2])&a[1]&a[0]);
assign y_n[4]=~((~s_n)&a[2]&(~a[1])&(~a[0]));
assign y_n[5]=~((~s_n)&a[2]&(~a[1])&a[0]);
assign y_n[6]=~((~s_n)&a[2]&a[1]&(~a[0]));
assign y_n[7]=~((~s_n)&a[2]&a[1]&a[0]);
endmodule
若采用结构方式,调用Verilog基元进行描述,参考代码如下:
module dec3_8c(s_n,a,y_n);
input s_n;
input [2:0] a;
output [7:0] y_n;
nand U0 (y_n[0],~s_n,~a[2],~a[1],~a[0]);
nand U1 (y_n[1],~s_n,~a[2],~a[1], a[0]);
nand U2 (y_n[2],~s_n,~a[2], a[1],~a[0]);
nand U3 (y_n[3],~s_n,~a[2], a[1], a[0]);
nand U4 (y_n[4],~s_n, a[2],~a[1],~a[0]);
nand U5 (y_n[5],~s_n, a[2], ~a[1], a[0]);
nand U6 (y_n[6], s_n, a[2], a[1],~a[0]);
nand U7 (y_n[7],~s_n, a[2], a[1], a[0]);
endmodule
优化设计方法
EDA优化设计包含两层含义:一是在满足系统性能要求的情况下,尽可能节约芯片面积;二是占用面积一定的情况下,尽可能提升系统的性能。
1. FPGA设计的基本原则
(1)速度与面积的平衡与互换
Quartus Prime软件中的分析与综合设置(Analysis & Synthesis Settings)页面中的Speed、Balanced和Area选项,分别对应于速度优先、性能折衷和面积优先三种综合优化选择,就是速度与面积原则的具体体现。
(2)硬件原则
应用Verilog HDL描述数字电路时,不能像写C程序那样,片面追求代码的简洁,而应该时时刻刻牢记Verilog描述的是硬件电路,清楚描述代码与硬件电路的相关关系。
module encode_83 ( // 注:本段代码来源于网络
input wire[7:0] x, // 注:8路高/低电平输入
output reg[2:0] y, // 注:3位二进制码输出
output reg e ); // 注:有无编码输入标志
integer i;
integer j=0;
always @(*) begin // 注:这种隐式敏感量列表方式不推荐使用
for (i=0;i<8;i=i+1) begin
if (x[i]==1) // 注:x[i]=1时更新输出
y<=i;
else // 否则,只将j加1
j=j+1; end
if (j==8) // j等于8时表示无编码信号输入
e<=1; // 无编码标志e设置为1
else
e<=0; end
endmodule
上述代码不适合于综合成硬件电路,而且是错误的。因为:(1) 上述代码综合出了时序电路,而不是组合逻辑电路;(2)从资源消耗上看,应用条件语句和分支语句描述的8-3线优先编码器综合后均占用了(EP4CE115F29C7)10个逻辑单元,而上述代码综合后占用了703个逻辑单元,资源占用是前两者的70倍!因此,应用Verilog HDL时,除了在编写测试平台文件testbench中,描述仿真测试激励时可以使用for循环语句外,建议在可综合电路设计中应尽量避免使用循环语句,而是选用if语句和case语句来描述类似的逻辑。
其次,用 HDL 描述数字电路时,应对所要描述的硬件电路的结构有清晰的概念和构想, 选择正确的描述方法,并用适当的代码描述出来。因为综合软件对 HDL 代码在进行综合时, 综合出的硬件电路会因为描述方法和描述代码的不同而不同,从而直接影响着系统的性能。
若定义
input [3:0] a,b,c,d,e,f,g,h;
output [5:0] sum;
实现加法时,应用代码
assign sum=((a+b)+(c+d))+((e+f)+(g+h));
和直接使用代码
assign sum=a+b+c+d+e+f+g+h;
(3)系统原则 模块化设计是系统原则的一个很好体现,是自顶向下、分工协作设计思路的具体体现, 是复杂系统的推荐设计方法。
(4)同步原则 时序电路有异步和同步两种实现方法。同步电路工作速度快,可靠性高,但电路比异步 电路复杂。异步电路结构简单,但容易产生竞争-冒险,因而可靠性不高。 对于同步电路设计,稳定可靠的时序设计必须遵从以下两个基本原则: (1)在时钟的有效沿到达前,数据输入至少已经稳定了建立时间之久,这条原则简称满足建立时间原则; (2)在时钟的有效沿作用后,数据输入至少还要稳定保持时间之久,这条原则简称满足保持时间原则。
2. 常用优化设计方法
(1)串-并转换方法。串行化是指把消耗资源大、反复使用的逻辑电路分割出来,在时间上共享该电路,采用流水线方式实现相同的功能。
设 a0~a3 和 b0~b3 均为 4 位无符号二进制数,应用并行方式实现乘加运算 y = a0*b0+a1*b1+a2*b2+a3*b3 时,Verilog 描述代码参考如下:
module p_mutl_add ( input [3:0] a0,a1,a2,a3,
input [3:0] b0,b1,b2,b3,
output [7:0] yout
);
assign yout = a0*b0+a1*b1+a2*b2+a3*b3;
endmodule
(2)流水线设计思想
流水线(pipelining)设计的基本思想对时序电路中传输延迟时间较大的组合逻辑块进行拆分,将原本在一个时钟周期完成的组合逻辑分割成多个较小的逻辑块,中间插入流水线寄存器,使其在多个时钟周期内完成,目的是提升这部分电路的工作频率,从而提高整个系统的性能。
若将电路中的组合逻辑块拆分成两个传输延迟时间大致相等的组合逻辑块,并在两个组合逻辑块之间插入流水线寄存器,如下图所示,就构成了流水线结构的同步时序电路。
需要注意的是,应用流水线结构能够提高同步电路的性能,但会产生了输入-输出的延迟。这是因为流水线的每一级输出相对于前一级输出,都会延迟一个时钟周期。因此,增加 n 级流水线,输出就会延迟 n 个时钟周期。
流水线思维方式的扩展应用是均衡同步电路的时序。 当两个组合逻辑块的传输延迟时间分别为 15ns和5ns,假设触发器的时钟到输出时间和建立时间均为5ns,则同步电路的最高工作频率为 1/(5ns+15ns+5ns)=40MHz
如果能将两个组合逻辑块的传输延迟时间调整为10ns和10ns,则电路的最高工作频率可以提升到 1/(5ns+10ns+5ns)=50MHz 即经过时序均衡后,同步电路的工作速度提升了25%。
(3)寻找关键路径
关键路径(Critical Path)是指关键信号的传输路径,或者电路中传输延迟时间最大的组合逻辑路径。如果能够减小关键路径的传输延迟时间,就可以有效地提高时序逻辑电路的工作频率。

对于上图所示电路,从输入到输出之间有3条信号传输路径,设每条路径的传输延迟时间分别用td1、td2和td3表示。若td1大于td2和td3,则传输延迟时间为td1的信号路径称为关键路径,优化的主要目标是减小td1,才能有效地提高电路的工作速度。
(4)乒乓操作
“乒乓操作”是串并转化思想的具体体现,常应用于用低速的硬件电路实现高速数据流的处理。
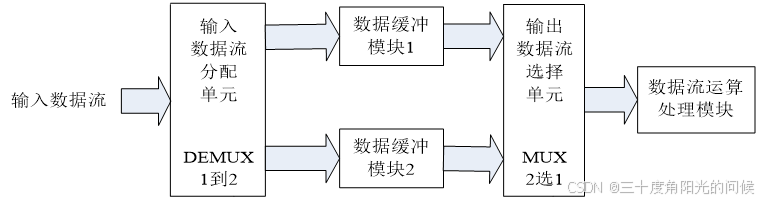
“乒乓操作”的工作原理是:前端通过数据分配器将输入的数据流交替配到两个数据缓冲模块,第一个时钟时将输入的数据存入到“数据缓冲模块1”,第2个时钟将输入的数据存入到“数据缓冲模块2”,依次反复进行。后端再应用数据选择器将两个数据缓冲模块合并为输出数据流,依次反复循环。
乒乓操作的本质是串并转换,将高速的串行数据并行化,利用面积换速度,巧妙运用乒乓操作可以达到用低速模块处理高速数据流的效果。