1. 概要
在使用 LLaMA(Large Language Model Meta AI)权重时,通常会涉及到与模型权重存储和加载相关的文件。这些文件通常是以二进制格式存储的,具有特定的结构来支持高效的模型操作。以下以Llama-7B为例,对这些文件的详细介绍:
2. 文件组成
1. 模型权重文件
模型权重文件包含了用于神经网络层的参数矩阵(例如权重矩阵和偏置向量)。这些参数是训练时优化得到的。
文件格式通常是 .bin 或 .pt,
如下图所示:
- pytorch_model.bin
- model-00001-of-00002.bin
权重文件通常是分片存储的,如果模型较大(如 LLaMA-13B 或 LLaMA-65B),会分成多个文件

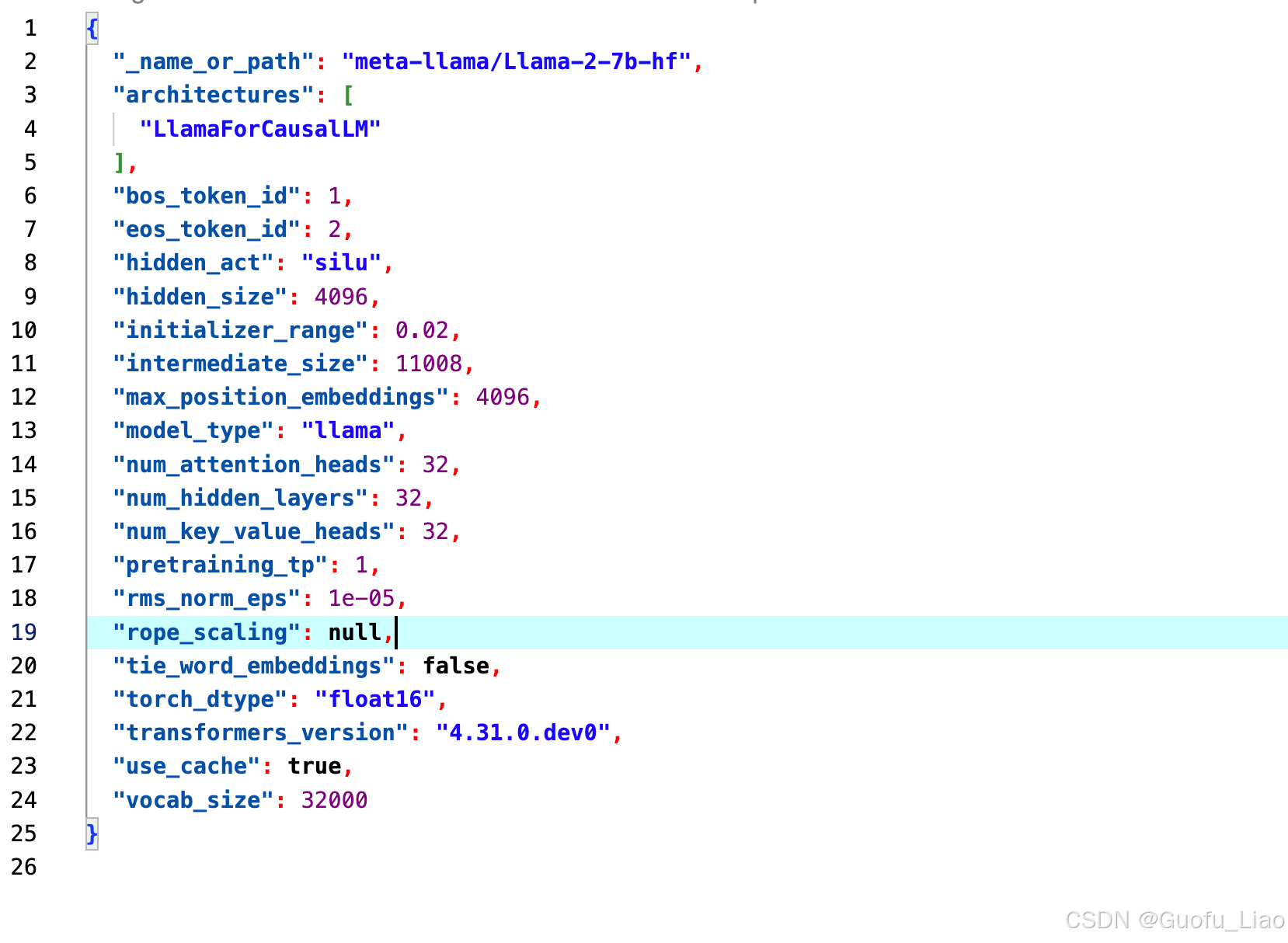
- 配置文件
名为 config.json 或 model_config.json,包含模型的结构和超参数等关键信息,是加载模型时解析权重的关键文件,如:
- 隐藏层大小
- 注意力头数
- 词嵌入维度
- 层数
- 词汇表文件
名为 tokenizer.json 或 vocab.json,存储模型的词汇表,用于将文本数据转换为模型的输入。
通常与 merges.txt 配合使用,支持 Byte Pair Encoding (BPE) 或 SentencePiece 的分词方式
tokenizer.json主要功能
- 文本到seq的映射
将输入文本切分成较小的片段(通常是词、子词或字符)。
使用唯一编号(ID)对每个片段进行编码。
例如,“Hello, LLaMA!” 转换为 [15496, 11, 12745, 0]。 - seq到文本的逆映射
在生成模型输出时,将模型生成的整数序列映射回文本。例如,[15496, 11, 12745, 0] 转换回 “Hello, LLaMA!”。