介绍
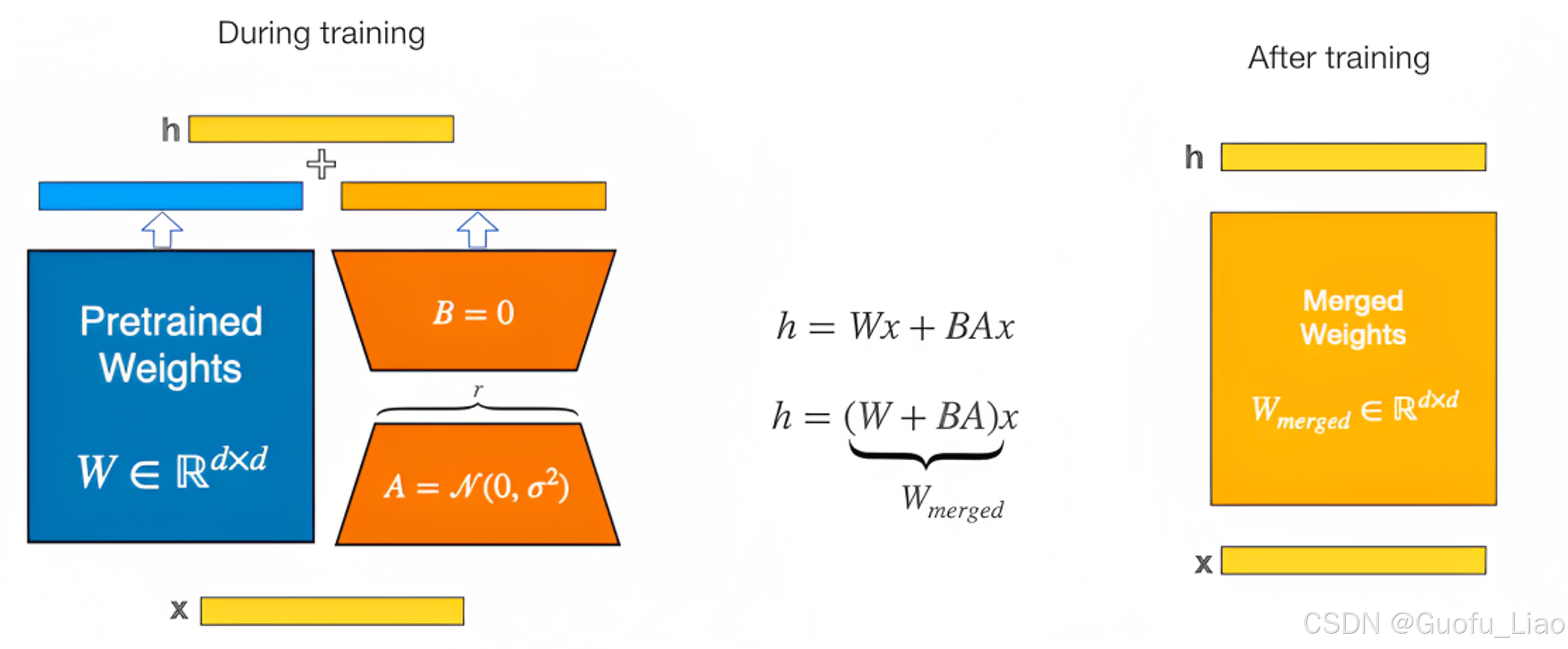
LoRA(Low-Rank Adaptation)是一种用于高效微调大模型的技术,它通过在已有模型的基础上引入低秩矩阵来减少训练模型时所需的参数量和计算量。具体来说,LoRA在训练模型时将模型中的某些权重矩阵分解为两个低秩矩阵A和B,并对这些矩阵进行微调(finetune),而模型的其他部分保持冻结不变。
LoRA的优势
- 它冻结了预训练的模型权重,并将可训练的秩分解矩阵注入到 Transformer 架构的每一层中,大大减少了下游任务的可训练参数的数量。
- 与使用 Adam 微调的 GPT3-175B 相比,LoRA 可以将可训练参数数量减少10,000,GPU内存需求减少3倍。
LoRA训练步骤:
-
选择目标层:首先,在预训练神经网络模型中选择要应用LoRA的目标层。这些层通常是与特定任务相关的,如自注意力机制中的查询Q和键K矩阵。
-
初始化映射矩阵A和逆映射矩阵B:映射矩阵A一般用随机高斯分布初始化,当然实际代码实现时,比如微软的deepspeedchat在用到LoRA时,一开始通过0矩阵占位,然后调用搭配ReLU激活函数的kaiming均匀分布初始化;逆映射矩阵B用0矩阵初始化。
-
微调模型:用新的参数矩阵替换目标层的原始参数矩阵,然后在特定任务的训练数据上对模型进行微调。
-
参数更新:在微调过程中,计算损失函数关于映射矩阵A和逆映射矩阵B的梯度,并使用优化算法(如Adam、SGD等)对矩阵A和B进行更新。(注意,在更新过程中,原始参数矩阵W保持不变,只训练降维矩阵A与升维矩阵B)
-
重复更新:在训练的每个批次中,重复步骤3-5,直到达到预定的训练轮次(epoch)或满足收敛条件 。
-
合并权重参数:将训练好的映射矩阵A和逆映射矩阵B,跟模型预先训练的权重矩阵进行合并。