53. 寻宝
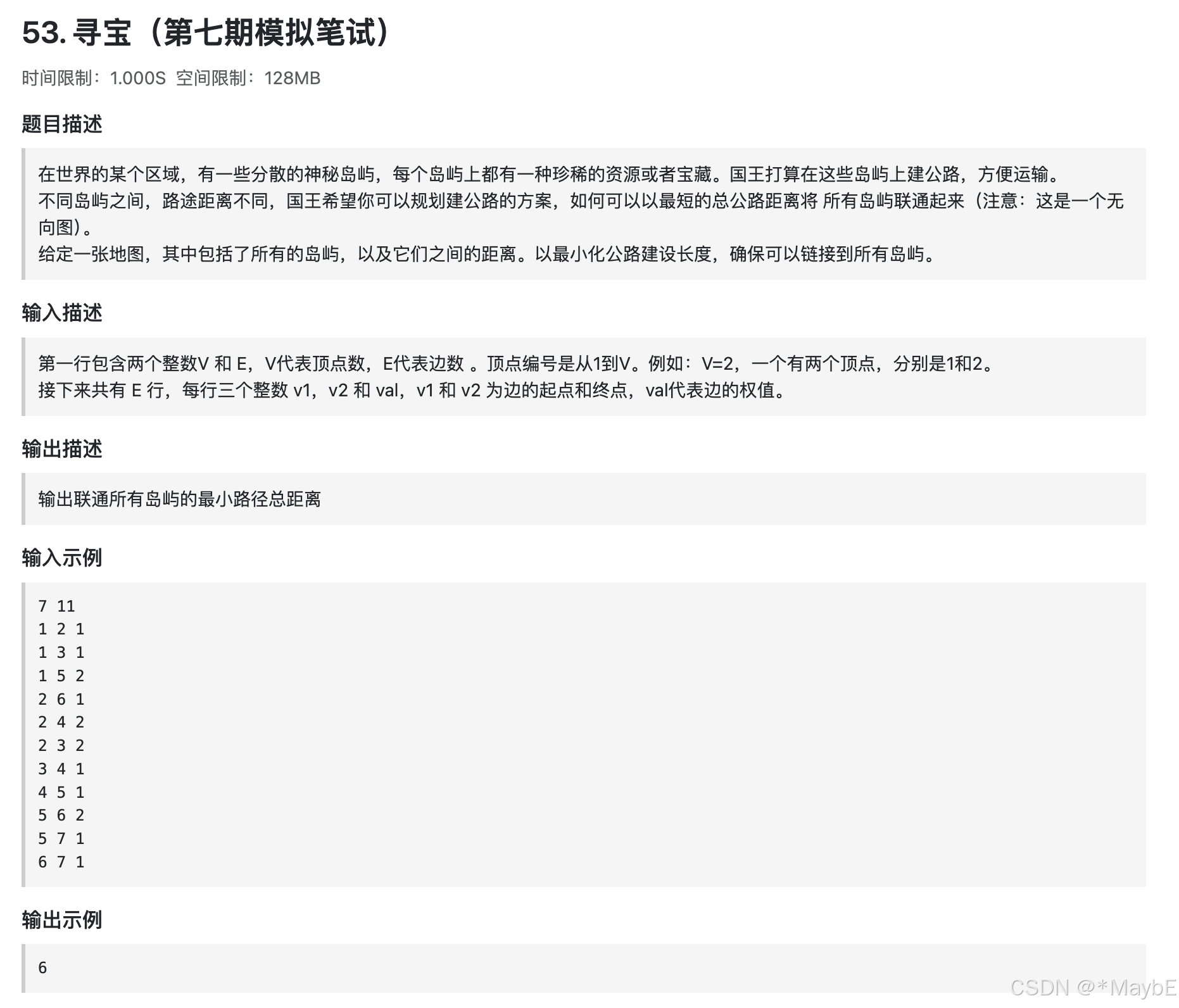
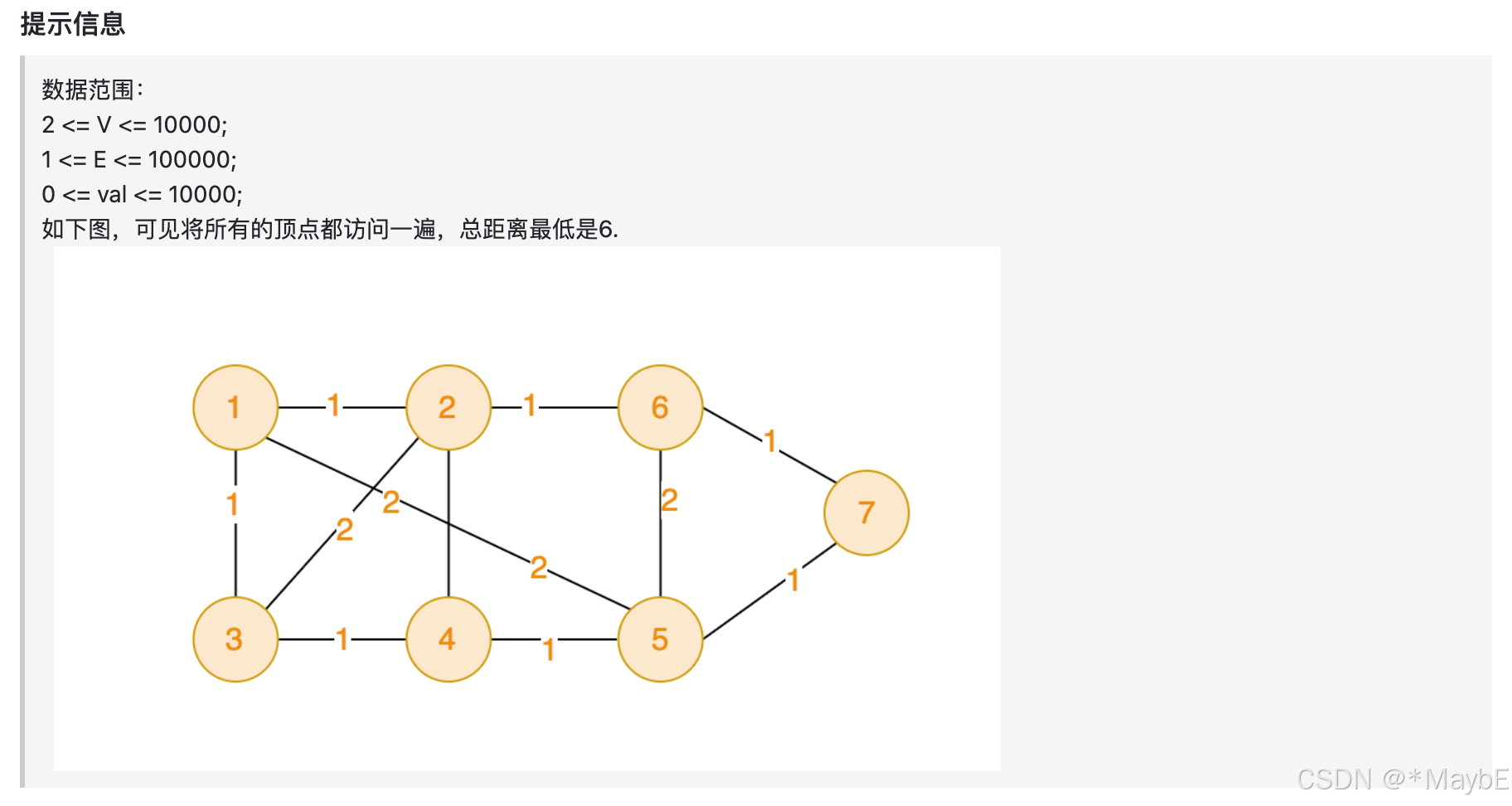
Prim算法
Prim 算法用于寻找加权连通图的最小生成树(Minimum Spanning Tree,MST)。最小生成树是指连接图中所有顶点的最小权重的树。该算法从一个起始节点开始,不断选择与已加入生成树的节点集最近的节点,并将其加入生成树,直到所有节点都包含在生成树中。
实现思路:
1.初始化:
- 创建一个邻接矩阵 grid 来存储图中每条边的权重,初始值为一个大数(如 10001),表示两点间没有边。
- 创建一个数组 minDist,用于存储每个顶点到生成树的最小距离,初始值也为一个大数。
- 创建一个布尔数组 isInTree,用于标记顶点是否已在生成树中。
2.读取输入数据:
- 读取每条边的信息,并更新邻接矩阵 grid。
3.Prim 算法主循环:
- 循环 v-1 次,每次将一个顶点加入生成树。
- 在每次循环中,找到当前未在生成树中的最小距离顶点 cur。
- 将 cur 顶点标记为已在生成树中。
- 更新所有与 cur 相连的未在生成树中的顶点的最小距离。
prim三部曲
第一步:选距离生成树最近的非生成树节点
- 选取最小生成树节点的条件:
- (1)不在最小生成树里
- (2)距离最小生成树最近的节点
第二步:最近节点(cur)加入生成树
第三步:更新非生成树节点到生成树的距离(即更新minDist数组)
- cur节点加入之后, 最小生成树加入了新的节点,那么所有节点到 最小生成树的距离(即minDist数组)需要更新一下。由于cur节点是新加入到最小生成树,那么只需要关心与 cur 相连的 非生成树节点 的距离 是否比 原来 非生成树节点到生成树节点的距离更小了呢。
- 更新的条件:
- 节点是 非生成树里的节点
- 与cur相连的某节点的权值 比 该某节点距离最小生成树的距离小
代码实现:
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int v = sc.nextInt();
int e = sc.nextInt();
int x, y, k;
// grid 是一个邻接矩阵,用于存储图中每条边的权重,权重默认最大值,题目描述val最大为10000
int[][] grid = new int[v + 1][v + 1];
for (int i = 0; i <= v; i++) {
Arrays.fill(grid[i], 10001);
}
while (e-- > 0) {
x = sc.nextInt();
y = sc.nextInt();
k = sc.nextInt();
// 因为是双向图,所以两个方向都要填上
grid[x][y] = k;
grid[y][x] = k;
}
// 所有节点到最小生成树的最小距离
int[] minDist = new int[v + 1];
Arrays.fill(minDist, 10001);
// 用来判断是否是生成树节点
boolean[] isInTree = new boolean[v + 1];
// 我们只需要循环 n-1次,建立 n - 1条边,就可以把n个节点的图连在一起
for (int i = 1; i < v; i++) {
// 1、prim三部曲,第一步:选距离生成树最近的非生成树节点,
int cur = -1; // 选中哪个节点 加入最小生成树
int minVal = Integer.MAX_VALUE;
for (int j = 1; j <= v; j++) { // 1 - v,顶点编号,这里下标从1开始
// 选取最小生成树节点的条件:
// (1)不在最小生成树里
// (2)距离最小生成树最近的节点
if (!isInTree[j] && minDist[j] < minVal) {
minVal = minDist[j];
cur = j;
}
}
// 2、prim三部曲,第二步:最近节点(cur)加入生成树
isInTree[cur] = true;
// 3、prim三部曲,第三步:更新非生成树节点到生成树的距离(即更新minDist数组)
// cur节点加入之后, 最小生成树加入了新的节点,那么所有节点到 最小生成树的距离(即minDist数组)需要更新一下
// 由于cur节点是新加入到最小生成树,那么只需要关心与 cur 相连的 非生成树节点 的距离 是否比 原来 非生成树节点到生成树节点的距离更小了呢
for (int j = 1; j <= v; j++) {
// 更新的条件:
// (1)节点是 非生成树里的节点
// (2)与cur相连的某节点的权值 比 该某节点距离最小生成树的距离小
// 很多录友看到自己 就想不明白什么意思,其实就是 cur 是新加入 最小生成树的节点,那么 所有非生成树的节点距离生成树节点的最近距离 由于 cur的新加入,需要更新一下数据了
if (!isInTree[j] && grid[cur][j] < minDist[j]) {
minDist[j] = grid[cur][j];
}
}
}
// 统计结果
int result = 0;
for (int i = 2; i <= v; i++) { // 不计第一个顶点,因为统计的是边的权值,v个节点有 v-1条边
result += minDist[i];
}
System.out.println(result);
}
拓展:如果让打印出来 最小生成树的每条边呢?
此时有两个问题:
- 用什么结构来记录
- 如何记录
用什么结构来记录?
我们使用一维数组就可以记录。 parent[节点编号] = 节点编号, 这样就把一条边记录下来了。(当然如果节点编号非常大,可以考虑使用map)
如何记录?
根据 minDist数组,选组距离 生成树 最近的节点 加入生成树,那么 minDist数组里记录的其实也是 最小生成树的边的权值。所以应该在更新 minDist数组 的时候,去更新parent数组来记录一下对应的边
kruskal算法
Kruskal算法是用于寻找加权无向连通图的最小生成树(Minimum Spanning Tree, MST)的贪心算法。其核心思想是按边的权重从小到大进行排序,然后依次选择权重最小且不形成环的边,直至构建出最小生成树。
实现思路:
1.初始化:
- 创建一个列表 edges 来存储所有边的信息。
- 初始化并查集 UnionFind,用于判断顶点是否在同一个集合中并进行集合的合并操作。
2.读取输入数据:
- 读取所有边的信息,并存储到 edges 列表中。
3.边排序:
- 按边的权值从小到大排序。
4.构建最小生成树:
- 遍历排序后的边列表,对于每条边,判断其两个顶点是否在同一个集合中。
- 如果两个顶点不在同一个集合中,则将这条边加入最小生成树,并进行集合的合并操作。
- 累加加入边的权值到 resultVal 中。
代码实现:
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
// 读取节点数和边数
int v = scanner.nextInt();
int e = scanner.nextInt();
List<Edge> edges = new ArrayList<>();
int resultVal = 0;
// 读取所有边的信息
for (int i = 0; i < e; i++) {
int x = scanner.nextInt();
int y = scanner.nextInt();
int val = scanner.nextInt();
edges.add(new Edge(x, y, val));
}
// 按边的权值从小到大排序
edges.sort(Comparator.comparingInt(edge -> edge.val));
// 初始化并查集
UnionFind uf = new UnionFind(v + 1);
// 遍历所有边,使用Kruskal算法构建最小生成树
for (Edge edge : edges) {
int x = uf.find(edge.l);
int y = uf.find(edge.r);
// 如果两个节点不在同一个集合中,加入这条边
if (x != y) {
resultVal += edge.val;
uf.join(x, y);
}
}
// 输出最小生成树的总权值
System.out.println(resultVal);
scanner.close();
}
// 并查集类
static class UnionFind {
private int n;
private int[] father;
public UnionFind(int n) {
this.n = n;
father = new int[n];
init();
}
// 初始化并查集,每个节点的父节点初始化为自己
private void init() {
for (int i = 0; i < n; i++) {
father[i] = i;
}
}
// 判断两个节点是否在同一个集合中
public boolean isSame(int u, int v) {
return find(u) == find(v);
}
// 合并两个节点所在的集合
public void join(int u, int v) {
u = find(u);
v = find(v);
if (u != v) {
father[v] = u;
}
}
// 查找节点u的根节点,并进行路径压缩
public int find(int u) {
return father[u] == u ? u : (father[u] = find(father[u]));
}
}
// 边类
static class Edge {
int l, r, val;
Edge(int l, int r, int val) {
this.l = l;
this.r = r;
this.val = val;
}
}
}
拓展:如果题目要求将最小生成树的边输出的话,应该怎么办呢?
Kruskal 算法 输出边的话,相对prim 要容易很多,因为 Kruskal 本来就是直接操作边,边的结构自然清晰,不用像 prim一样 需要再节点练成线输出边 (因为prim是对节点操作,而 Kruskal是对边操作,这是本质区别)
当判断两个节点不在同一个集合的时候,这两个节点的边就加入到最小生成树, 所以添加边的操作在这里:
// 遍历所有边,使用Kruskal算法构建最小生成树
for (Edge edge : edges) {
int x = uf.find(edge.l);
int y = uf.find(edge.r);
// 如果两个节点不在同一个集合中,加入这条边
if (x != y) {
result.put(edge);// 记录最小生成树的边
resultVal += edge.val;
uf.join(x, y);
}
}
Kruskal 和 Prim 对比
什么情况用哪个算法更合适呢。
Kruskal 与 prim 的关键区别在于,prim维护的是节点的集合,而 Kruskal 维护的是边的集合。 如果 一个图中,节点多,但边相对较少,那么使用Kruskal 更优。
为什么边少的话,使用 Kruskal 更优呢?
因为 Kruskal 是对边进行排序的后 进行操作是否加入到最小生成树。
边如果少,那么遍历操作的次数就少。
在节点数量固定的情况下,图中的边越少,Kruskal 需要遍历的边也就越少。
而 prim 算法是对节点进行操作的,节点数量越少,prim算法效率就越优。
所以在 稀疏图中,用Kruskal更优。 在稠密图中,用prim算法更优。
边数量较少为稀疏图,接近或等于完全图(所有节点皆相连)为稠密图
Prim 算法 时间复杂度为 O(n^2),其中 n 为节点数量,它的运行效率和图中边树无关,适用稠密图。
Kruskal算法 时间复杂度 为 nlogn,其中n 为边的数量,适用稀疏图。