零 前言
Zookeeper、Hadoop、Hbase、Hive、Scala、Spark 完全分布式平台安装教程
以下内容为个人学习分布式平台搭建过程中记录,仅用于学习,如有错误或者纰漏,欢迎留言指正。
更新日期[已完结]: 2021 年 6 月 13 日
导读
引用格式一般为:在终端中输入的命令
代码块中的内容一般为:文件内容
开始前提
- 三台已安装好 CentOS 7 系统的机器(虚拟机、物理机都行,可以是文本界面)
- 三台机器之间是可到达的(互连,能ping通)
- 安装包资源
百度云链接链接:https://pan.baidu.com/s/114qygpZrtRqoCRtEIY3IRA#list/path=%2F
提取码:qwer
一 配置网卡
| 机器角色 | 主机名称 | IP地址 |
|---|---|---|
| Master | Master | 192.168.31.170 |
| Slave | Slave1 | 192.168.31.171 |
| Slave | Slave2 | 192.168.31.172 |
1. 修改网卡文件
vi /etc/sysconfig/network-scripts/ifcfg-ens33
# 文件 /etc/sysconfig/network-scripts/ifcfg-ens33
# 这里只粘贴了需要修改的项
NAME=ens33 # 网卡设备名称
TYPE=Ethernet # 网络类型:Ethernet以太网
BOOTPROTO=static # 引导协议:自动获取、static静态、none不指定
ONBOOT=yes # 开机自动激活网卡
IPADDR=192.168.31.170 # IP地址
PREFIX=24 # 子网掩码
GATEWAY=192.168.31.1 # 网关
DNS1=123.125.81.6 # DNS
DNS2=140.207.198.6
2. 重启网络服务
service network restart
若是从别的机器上复制的虚拟机,可能需要修改网卡文件中的MAC地址成(ip addr)中的MAC 地址,或启动虚拟机时选择复制虚拟机。
二 修改主机名, 配置 hosts 文件
1. 修改主机名
vi /etc/hostname
# 文件 /etc/hostname
Master
2. 添加主机名与IP地址对照表
vi /etc/hosts
# 文件 /etc/hosts
127.0.0.1 localhost.localdomain localhost
::1 localhost6.localdomain6 localhost6
192.168.31.170 Master
192.168.31.171 Slave1
192.168.31.172 Slave2
三 关闭防火墙
1. 关闭命令
systemctl stop firewalld.service # 关闭防火墙
systemctl disable firewalld.service # 取消开机自启
systemctl status firewalld.service # 查看防火墙状态

tips:关闭防火墙后使用ssh连接其他机器提示 22端口被拒绝,可能是因为SELINUX没有关闭。
sestatus # 查看selinux状态
2. 关闭 SELINUX
vi /etc/sysconfig/selinux
# 修改SELINUX=enforcing→SELINUX=disabled
# 需要重启系统生效
四 配置SSH免密钥登录
1. 启动SSH服务
/usr/sbin/sshd
2. 设置SSH服务开机自启动
chkconfig sshd on
3. 在本地机器上产生公钥私钥对
ssh-keygen
此命令会在用户目录 .ssh下创建公钥(id_rsa)和 私钥(id_rsa.pub)
| 参数 | 解释 |
|---|---|
| -t | 加密算法类型,这里是使用rsa算法 |
| -P | 指定私钥的密码,不需要可以不指定 |
| -f | 指定生成秘钥对保存的位置 |
4. 将本机公钥发送给其他机器
命令格式:ssh-copy-id UserName@IP地址
服务端(本机)会把公钥追加到服务端对应用户的$HOME/.ssh/authorized_keys文件中
例如:给Slave1发送公钥(如下两条指令效果一样)
ssh-copy-id Slave1
ssh-copy-id [email protected]
5. 验证是否成功
ssh Slave1
输入 exit 或者按下Ctrl + D退出登录。
为节省篇幅只示范了免密登录Slave1,实际需要做到三台都可以互相免密登录。
五 时间同步
tips:使用虚拟机需要把Vmware里的 虚拟机与主机时间同步 关闭,否则可能影响后面 zookeeper 的启动
1. 安装ntp服务
yum install -y ntp
2. Master角色
① 修改ntp配置文件:/etc/ntp.conf
vi /etc/ntp.conf
# 文件 /etc/ntp.conf
# 去掉了所有的默认注释,对其中的修改写了的注释,没有写注释的是默认配置
driftfile /var/lib/ntp/drift
restrict default kod nomodify notrap nopeer noquery
restrict 127.0.0.1
restrict ::1
# 允许192.168.31.0网段内所有机器从本机同步时间
restrict 192.168.31.0 mask 255.255.255.0 nomodify notrap
# 设置默认策略为允许任何主机进行时间同步
restrict default ignore
# 注释掉默认服务器
# server 0.centos.pool.ntp.org iburst
# server 1.centos.pool.ntp.org iburst
# server 2.centos.pool.ntp.org iburst
# server 3.centos.pool.ntp.org iburst
######################################################
# 添加NTP时间服务器
server ntp.aliyun.com
server time1.cloud.tencent.com
server cn.ntp.org.cn
server 202.112.10.36
# 允许上层时间服务器主动修改本机时间
restrict ntp.aliyun.com nomodify notrap
restrict time1.cloud.tencent.com nomodify notrap
restrict cn.ntp.org.cn nomodify notrap
restrict 202.112.10.36 nomodify notrap
# 外部时间server不可用时,以本地时间作为时间服务
server 127.127.1.0
fudge 127.127.1.0 stratum 10
######################################################
includefile /etc/ntp/crypto/pw
keys /etc/ntp/keys
disable monitor
② 同步硬件时间
ntp服务默认只会同步系统时间。如果想要让ntp同时同步硬件时间,可以设置/etc/sysconfig/ntpd文件,就可以让硬件时间与系统时间一起同步。(也可以通过hwclock -w 命令同步)
vi /etc/sysconfig/ntpd
# 文件 /etc/sysconfig/ntpd
SYNC_HWCLOCK=yes # 允许BIOS与系统时间同步
③ 启动ntp服务前,先手动同步一次时间
这是因为 ntpd 服务开启之后,就不能手动同步时间了。如果 server(授时中心服务器)与 client(Master)之间的时间误差过大时 ,同步时间可能对系统和应用带来不可预知的问题,如停止时间同步。
如果发现 Master 启动 ntp 服务之后时间并没有进行同步时,可能是时间差过大引起的,此时需要先手动进行时间同步,再启动ntp服务!
手动同步时间出现提示: the NTP socket is in use, exiting
是因为系统ntpd服务器正在运行中,需要先停止ntp服务,再手动同步时间。
# 手动与阿里云同步时间
systemctl stop ntpd
ntpdate ntp.aliyun.com
④ 启动Master的ntpd服务,并设置开机自启
systemctl start ntpd
chkconfig ntpd on
如果ntp服务开机自启没有生效,有可能是存在服务和ntp冲突导致开机启动未生效。
例如 chrony ,使用 systemctl is-enabled chronyd 查看chrony的启动状态设置,如果是enabled说明这个服务也是开机自启,输入如下命令将其关闭,再次重启ntp即可随着系统自启。
systemctl disable chronyd
⑤ 检查ntp端口是否已经开启
netstat -unlnp | grep ntpd
可以看到输出的第一行的内容,表示连接和监听已正确

⑥ 查看网络中的ntp服务器,显示客户端和每个服务器的关系
ntpq -p
这里的前4行就是 ntp.conf 文件中配置的4个授时中心的服务器的信息,最后一行是本地时间服务的信息。
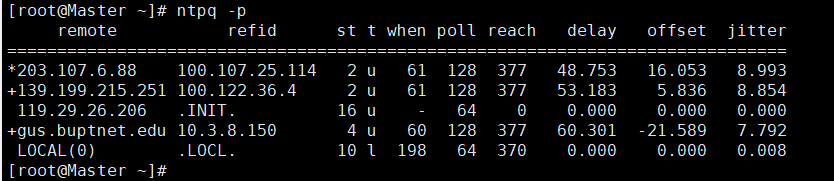
说明:ntp服务启动后,一般需要5-10分钟左右的时候才能与外部时间服务器开始同步时间,所以需要等待几分钟才能看到正常的现象,否则你看到的是响应的NTP服务器和最精确的服务器是LOCAL(0)。
| 名字 | 含义 |
|---|---|
| remote地址前的符号 | * :响应的NTP服务器和最精确的服务器 + :响应这个查询请求的NTP服务器 blank(什么都没有):没有响应的NTP服务器 |
| remote | 提供时间来源的服务器地址 |
| refid | 提供时间来源的服务器的上层时间来源服务器地址 |
| st | 表示stratum,即remote的层级 |
| when | 表示最后一次同步距离现在过去了多长时间(默认单位为秒) |
| poll | 本地和远程服务器多少时间进行一次同步,单位秒,在一开始运行NTP的时候这个poll值会比较小,服务器同步的频率大,可以尽快调整到正确的时间范围,之后poll值会逐渐增大,同步的频率也就会相应减小 |
| reach | 用来测试能否和服务器连接,是一个八进制值,每成功连接一次它的值就会增加 |
| delay | 示本地到remote的延迟,即建立通信往返所用的时间,单位是毫秒 |
| offset | 主机通过NTP时钟同步与所同步时间源的时间偏移量,单位为毫秒,offset越接近于0,主机和ntp服务器的时间越接近 |
| jitter | 统计了在特定个连续的连接数里offset的分布情况。简单地说这个数值的绝对值越小,主机的时间就越精确 |
⑦ 查看 Master 的 ntp 服务状态
ntpstat
如果输出的是 unsynchronised是因为需要5-10分钟后才能成功连接和同步。

2. Slave角色
方法 1: 手动与Master同步
tips:手动同步时,Slave角色不要启动ntp服务!
systemctl stop ntpd # 关闭ntp服务
ntpdate Master # 手动与Master同步时间
方法 2:自动与Master同步(推荐)
每个Slave角色操作相同,且与Master区别仅在于ntp.conf文件的配置,这里选择 Slave1 做示范。
① 修改ntp配置文件:/etc/ntp.conf
vi /etc/ntp.conf
# 文件 /etc/ntp.conf
# 去掉了所有的默认注释,对其中的修改写了的注释,没有写注释的是默认配置
driftfile /var/lib/ntp/drift
restrict default kod nomodify notrap nopeer noquery
restrict 127.0.0.1
restrict ::1
# 默认的服务器列表注释掉
# server 0.centos.pool.ntp.org iburst
# server 1.centos.pool.ntp.org iburst
# server 2.centos.pool.ntp.org iburst
# server 3.centos.pool.ntp.org iburst
######################################################
# 从 Master 中同步时间 perfer表示优先主机
server 192.168.31.170 perfer
# 允许 Master 修改本地时间
restrict 192.168.31.170 nomodify notrap
# 如果 Master 不可用,用本地的时间服务
server 127.127.1.0
fudge 127.127.1.0 stratum 10
######################################################
includefile /etc/ntp/crypto/pw
keys /etc/ntp/keys
disable monitor
⑥ 同步时间后,写到硬件中
vi /etc/sysconfig/ntpd
# 文件 /etc/sysconfig/ntpd
SYNC_HWCLOCK=yes #允许BIOS与系统时间同步
⑦ 启动ntpd服务
Slave在启动ntpd服务之前,手动与Master同步一下时间,再启动ntpd服务
ntpdate Master
systemctl start ntpd
chkconfig ntpd on # 设置开机启动
⑧ 查看时间同步的状态
ntpq -p
ntpstat
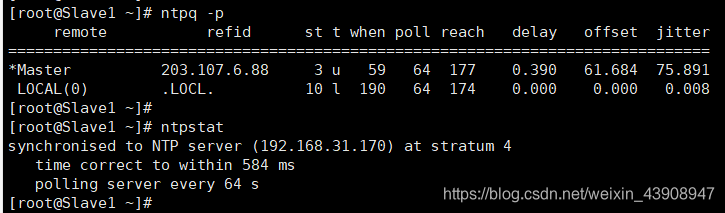
若以上提供的网络时间服务器不可用,请自行上网寻找可用的网络时间服务器,另外需要关闭各服务器的防火墙,才能进行时间同步。
到这里,利用局域网内一台时间服务器来同步整个集群时间的全部配置就已经完成。
六 安装JDK
1. Master角色
① 准备软件
将Java安装包,发送到其他机器(发送文件夹内全部安装包则将命令中的 /jdk-8u171-linux-x64.tar.gz 改成 /* )
scp /root/software/jdk-8u171-linux-x64.tar.gz Slave1:/root/software/
scp /root/software/jdk-8u171-linux-x64.tar.gz Slave2:/root/software/
② 清理旧版本
rpm -qa | grep jdk # 查看已经安装的 JDK
yum remove (旧版本OpenJDK)
③ 解压安装包
创建 java 文件夹,将 /root/software/ 下的 jdk-8u171-linux-x64.tar.gz 解压到 /usr/java/ 目录内
mkdir /usr/java
tar -xzvf /root/software/jdk-8u171-linux-x64.tar.gz -C /usr/java
④ 配置环境变量
vi /etc/profile
# 文件 /etc/profile
# Java enviroment
export JAVA_HOME=/usr/java/jdk1.8.0_171
export CLASSPATH=$JAVA_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin
### 若不卸载旧版本JDK,则需要将上方第三行修改成下行 ###
export PATH=$JAVA_HOME/bin:$PATH
tips:一般修改后需要重启或重新登录才可以生效,也可以使用source命令:在当前bash环境下读取并执行FileName中的命令
⑤ 读取并执行 /etc/profile 文件,使添加的环境变量生效
source /etc/profile
2. Slave角色
① 在Master上给Slave发送Java文件
scp -r /usr/java root@Slave1:/usr
scp -r /usr/java root@Slave2:/usr
② 发送环境变量文件
scp /etc/profile root@Slave1:/etc/
scp /etc/profile root@Slave2:/etc/
③ 读取并执行 /etc/profile 文件
source /etc/profile
④ 查看 Java 版本
java -version

!!! 注意 !!!
-
要注意 PATH 值的修改,一定要引用原 PATH 值,否则 Linux 的很多操作命令就不能使用了。
-
export 是把变量导出为全局变量。
-
大小写必须严格区分。
-
如果想清除重复的$PATH变量值,可在profile中添加下面内容:
# 文件 /etc/profile #######清除重复的PATH变量值######### awk -F: '{ sep = "" for (i = 1; i <= NF; ++i) if (unique[$i] != 1) { out = out sep $i sep = ":" unique[$i] = 1 } print out }' <<< $PATH #################################
七 安装Zookeeper
1. Master角色
① 建立zookeeper目录,并解压安装包
mkdir /usr/zookeeper
tar -xzvf /root/software/zookeeper-3.4.10.tar.gz -C /usr/zookeeper
② 修改hosts文件
vi /etc/hosts
# 文件 /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.31.170 Master Master.root
192.168.31.171 Slave1 Slave1.root
192.168.31.172 Slave2 Slave2.root
③ 添加环境变量
vi /etc/profile
# 文件 /etc/profile
# zookeeper enviroment
export ZOOKEEPER_HOME=/usr/zookeeper/zookeeper-3.4.10
export PATH=$PATH:$ZOOKEEPER_HOME/bin
④ 读取并执行 /etc/profile 文件
source /etc/profile
⑤ 建立两个目录,用于设置zoo.cfg文件的dataDir和dataLogDir
mkdir /usr/zookeeper/zookeeper-3.4.10/zkdata
mkdir /usr/zookeeper/zookeeper-3.4.10/zkdatalog
⑥ 配置zoo.cfg
进入文件所在地址,复制配置文件并更名为 zoo.cfg
cd /usr/zookeeper/zookeeper-3.4.10/conf
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
# 文件 /usr/zookeeper/zookeeper-3.4.10/conf/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
clientPort=2181
dataDir=/usr/zookeeper/zookeeper-3.4.10/zkdata
dataLogDir=/usr/zookeeper/zookeeper-3.4.10/zkdatalog
server.1=Master:2888:3888
server.2=Slave1:2888:3888
server.3=Slave2:2888:3888
| 参数 | 解释 |
|---|---|
| tickTime | 这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。 |
| initLimit | 这个配置项是用来配置 Zookeeper 接受客户端(这里所说的客户端不是用户连接 Zookeeper 服务器的客户端,而是 Zookeeper 服务器集群中连接到 Leader 的 Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。 当已经超过 10个心跳的时间(也就是 tickTime)长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 10*2000=20 秒 |
| syncLimit | 配置follower和leader之间发送消息,请求和应答的最大时间长度。 |
| clientPort | 这个端口就是客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。 |
| dataDir | 顾名思义就是 Zookeeper 保存数据的目录,默认情况下,Zookeeper 将写数据的日志文件也保存在这个目录里。 |
| server.A=B:C:D | 其中 A 是一个数字,表示这个是第几号服务器;B 是这个服务器的 ip 地址;C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。 |
⑦ 创建myid文件
内容为 zoo.cfg 文件中的数字 A (↑server.A=B:C:D)
例如:Master的myid是 1,Slave1是 2,Slave2是 3
vi /usr/zookeeper/zookeeper-3.4.10/zkdata/myid
2. Slave角色
① 在Master上给Slave发送Zookeeper文件
scp -r /usr/zookeeper root@Slave1:/usr
scp -r /usr/zookeeper root@Slave2:/usr
② 发送环境变量文件
scp /etc/profile root@Slave1:/etc/
scp /etc/profile root@Slave2:/etc/
③ 读取并执行 /etc/profile 文件
source /etc/profile
④ 修改Slave角色中 myid文件机器号
这里Slave1 的 myid 为 2, Slave2 的 myid 为 3
vi /usr/zookeeper/zookeeper-3.4.10/zkdata/myid
3. 启动Zookeeper集群
① 启动Zookeeper
要确定Master角色中ntpd服务运行,Slave角色与Master同步时间,再启动Zookeeper。
三台机器上都需要输入如下命令,启动Zookeeper
/usr/zookeeper/zookeeper-3.4.10/bin/zkServer.sh start
② 查看状态
三台机器都启动成功后,输入如下命令查看
/usr/zookeeper/zookeeper-3.4.10/bin/zkServer.sh status
# 关闭Zookeeper命令如下
# /usr/zookeeper/zookeeper-3.4.10/bin/zkServer.sh stop
Master角色机器在Zookeeper中不一定时 leader,leader是通过选举出来的。
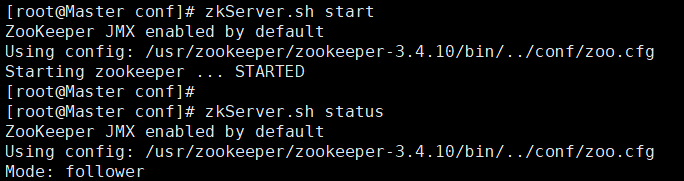

奥义云环境需要删除 /etc/hosts 文件中127.0.0.1 localhost,否则可能启动失败。
八 安装hadoop
1. Master角色
① 建立hadoop目录,并解压安装包
mkdir /usr/hadoop
tar -xzvf /root/software/hadoop-2.7.3.tar.gz -C /usr/hadoop
② 配置环境变量
vi /etc/profile
# 文件 /etc/profile
# Hadoop enviroment
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export CLASSPATH=$CLASSPATH:$HADOOP_HOME/lib
export PATH=$PATH:$HADOOP_HOME/bin
③ 读取并执行 /etc/profile 文件
source /etc/profile
④ 修改Hadoop配置文件
-
修改
hadoop-env.sh该文件设置的是Hadoop运行时需要的环境变量。JAVA_HOME是必须设置的,即使我们当前的系统设置了JAVA_HOME,它也是不识别的;因为Hadoop即使是在本机上执行,它也是把当前执行的环境当成远程服务器。所以这里设置的目的是确保Hadoop能正确的找到jdk。
vi /usr/hadoop/hadoop-2.7.3/etc/hadoop/hadoop-env.sh
# 文件 /usr/hadoop/hadoop-2.7.3/etc/hadoop/hadoop-env.sh export JAVA_HOME=/usr/java/jdk1.8.0_171 -
修改核心组件文件
core-site.xmlHadoop全局的配置文件,以及一些HDFS的宏观配置
在<configuration></configuration>中添加如下内容(注释不用写,第3、4、5点同样)
vi /usr/hadoop/hadoop-2.7.3/etc/hadoop/core-site.xml
# 文件 /usr/hadoop/hadoop-2.7.3/etc/hadoop/core-site.xml <!-- 指定Hadoop所使用的文件系统schema(URL),HDFS的老大(NameNode)的地址 --> <configuration> <property> <name>fs.default.name</name> <value>hdfs://Master:9000</value> </property> <!-- 指定Hadoop运行时产生文件的储存目录,默认是/tmp/hadoop-${user.name} --> <property> <name>hadoop.tmp.dir</name> <value>/usr/hadoop/hadoop-2.7.3/hdfs/tmp</value> <description>A base for other temporary directories.</description> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> <property> <name>fs.checkpoint.period</name> <value>60</value> </property> <property> <name>fs.checkpoint.size</name> <value>67108864</value> </property> </configuration> -
修改
hdfs-site.xmlvi /usr/hadoop/hadoop-2.7.3/etc/hadoop/hdfs-site.xml
# 文件 /usr/hadoop/hadoop-2.7.3/etc/hadoop/hdfs-site.xml <!-- 指定HDFS副本的数量 --> <configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/hadoop/hadoop-2.7.3/hdfs/name</value> <final>true</final> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/hadoop/hadoop-2.7.3/hdfs/data</value> <final>true</final> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>Master:9001</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration> -
修改
yarn-site.xmlvi /usr/hadoop/hadoop-2.7.3/etc/hadoop/yarn-site.xml
# 文件 /usr/hadoop/hadoop-2.7.3/etc/hadoop/yarn-site.xml <!-- Site specific YARN configuration properties --> <configuration> <property> <!--ResourceManager 对客户端暴露的地址--> <name>yarn.resourcemanager.address</name> <value>Master:18040</value> </property> <property> <!--ResourceManager 对ApplicationMaster暴露的地址--> <name>yarn.resourcemanager.scheduler.address</name> <value>Master:18030</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>Master:18088</value> </property> <property> <!--ResourceManager 对NodeManager暴露的地址--> <name>yarn.resourcemanager.resource-tracker.address</name> <value>Master:18025</value> </property> <property> <!--ResourceManager 对管理员暴露的地址--> <name>yarn.resourcemanager.admin.address</name> <value>Master:18141</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> </configuration> -
修改MapReduce配置文件
mapred-site.xml在同一目录下,有一个名为
mapred-site.xml.template的文件,先把它复制并重命名成mapred-site.xml再进行配置。cp /usr/hadoop/hadoop-2.7.3/etc/hadoop/mapred-site.xml.template /usr/hadoop/hadoop-2.7.3/etc/hadoop/mapred-site.xml
vi /usr/hadoop/hadoop-2.7.3/etc/hadoop/mapred-site.xml
# 文件 /usr/hadoop/hadoop-2.7.3/etc/hadoop/mapred-site.xml <!-- 指定mr运行时框架,这里指定在yarn上,默认是local --> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> -
修改从节点列表
slavesslaves文件给出了hadoop集群的Slave节点列表。该文件十分重要,因为启动Hadoop的时候,系统总是根据当前slaves文件中Slave节点名称列表启动集群,不在列表中的Slave节点便不会被视为计算节点。
将原先的localhosts这一行删除,然后添加以下内容
vi /usr/hadoop/hadoop-2.7.3/etc/hadoop/slaves
# 文件 /usr/hadoop/hadoop-2.7.3/etc/hadoop/slaves Slave1 Slave2 -
新建
master文件vi /usr/hadoop/hadoop-2.7.3/etc/hadoop/master
# 文件 /usr/hadoop/hadoop-2.7.3/etc/hadoop/master Master
2. Slave角色
① 在Master上给Slave角色发送Hadoop文件
scp -r /usr/hadoop root@Slave1:/usr
scp -r /usr/hadoop root@Slave2:/usr
② 发送环境变量
scp /etc/profile root@Slave1:/etc
scp /etc/profile root@Slave2:/etc
③ 读取并执行 /etc/profile 文件
source /etc/profile
3. 启动Hadopp
① 格式化文件系统
第一次启动前,需要先在Master角色中输入如下命令格式化文件系统,创建fsimage和edits文件。如果不是第一次启动,可跳过这一步直接启动Hadoop集群。
若格式化没有出现错误提示信息,则说明格式化成功。
hadoop namenode -format
注意:如果HDFS集群已经使用了一段时间,再次进行格式化时,需要先将所有Datanode存储的数据块删除。(数据块存储目录可以在配置文件中查找到)
原因:Namenode格式化后,会形成新的集群ID(Cluster ID),但Datanode中存储的集群ID仍是旧的,当Datanode向Namenode上报信息时,会由于集群ID不同而出现错误,导致集群启动失败。
② 启动Hadoop集群
在 Master 终端输入如下命令启动Hadoop集群
/usr/hadoop/hadoop-2.7.3/sbin/start-all.sh
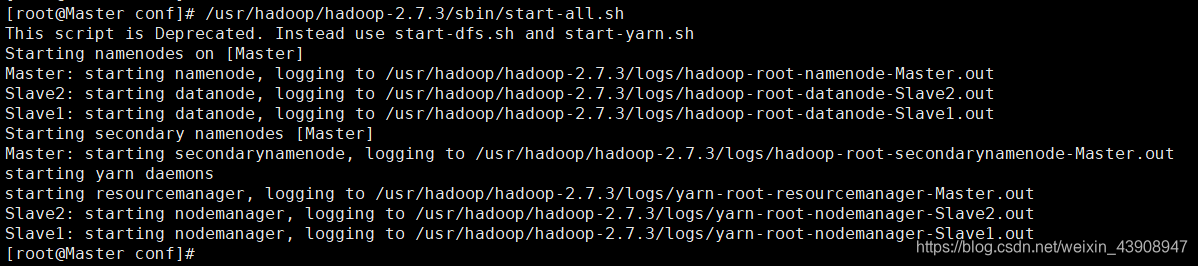
③ 查看启动情况
-
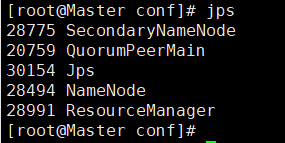
输入 jps
在三台服务器里分别输入
jps可以判断是否启动成功,出现下面内容说明成功(QuorumPeerMain是zookeeper集群的启动入口类,是用于加载配置启动QuorumPeer线程) -
在浏览器中查看Hadoop状态
如:系统的启动时间,版本,集群ID等http://192.168.31.170:50070
④ 关闭Hadoop集群
在Master角色终端里输入如下命令关闭Hadoop集群
/usr/hadoop/hadoop-2.7.3/sbin/stop-all.sh
九 安装Hbase
1. Master角色
① 创建Hbase目录,并解压安装包
mkdir /usr/hbase
tar -xzvf /root/software/hbase-1.2.4-bin.tar.gz -C /usr/hbase
② 配置环境变量
vi /etc/profile
# 文件 /etc/profile
# HBase enviroment
export HBASE_HOME=/usr/hbase/hbase-1.2.4
export PATH=$PATH:$HBASE_HOME/bin
③ 使环境变量生效
source /etc/profile
④ 修改配置文件
-
修改
hbase-env.shvi /usr/hbase/hbase-1.2.4/conf/hbase-env.sh
# 文件 /usr/hbase/hbase-1.2.4/conf/hbase-env.sh # 不使用Hbase自带Zookeeper export HBASE_MANAGES_ZK=false export JAVA_HOME=/usr/java/jdk1.8.0_171 export HBASE_CLASSPATH=/usr/hadoop/hadoop-2.7.3/etc/hadoop -
修改
hbase-site.xmlvi /usr/hbase/hbase-1.2.4/conf/hbase-site.xml
# 文件 /usr/hbase/hbase-1.2.4/conf/hbase-site.xml <configuration> <property> <name>hbase.rootdir</name> <value>hdfs://Master:9000/hbase</value> </property> <property> <!--是否启动集群模式--> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.master</name> <value>hdfs://Master:6000</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>Master,Slave1,Slave2</value> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/usr/zookeeper/zookeeper-3.4.10</value> </property> </configuration> -
修改
regionservers删除原来的内容localhost,并添加如下内容。
vi /usr/hbase/hbase-1.2.4/conf/regionservers
# 文件 /usr/hbase/hbase-1.2.4/conf/regionservers Slave1 Slave2 -
复制Hadoop配置文件
hdfs-site.xml和core-site.xmlcp /usr/hadoop/hadoop-2.7.3/etc/hadoop/hdfs-site.xml /usr/hbase/hbase-1.2.4/conf/
cp /usr/hadoop/hadoop-2.7.3/etc/hadoop/core-site.xml /usr/hbase/hbase-1.2.4/conf/
2. Slave角色
① 发送Hbase
scp -r /usr/hbase root@Slave1:/usr/
scp -r /usr/hbase root@Slave2:/usr/
② 发送环境变量
scp /etc/profile root@Slave1:/etc/
scp /etc/profile root@Slave2:/etc/
③ 读取并执行 /etc/profile 文件
source /etc/profile
3. 启动Hbase
① 启动hbase
启动前需要依次启动zookeeper、Hadoop,再启动Hbase
在Master角色终端中输入如下命令启动Hbase集群
/usr/hbase/hbase-1.2.4/bin/start-hbase.sh

② 查看启动情况
- 输入 jps 查看状态
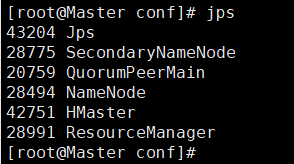
-
在浏览器中查看Hbase状态信息
http://192.168.31.170:16010/master-status
-
进入Hbase的命令行环境(exit或quit退出)
hbase shell
tips:若进入Hbase命令行环境时出现如下警告
SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/usr/hbase/hbase-1.2.4/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/usr/hadoop/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]原因:jar包冲突,删除其中一个jar包即可
rm -f /usr/hbase/hbase-1.2.4/lib/slf4j-log4j12-1.7.5.jar

③ 关闭Base
/usr/hbase/hbase-1.2.4/bin/stop-hbase.sh
tips:关闭时出现stopping hbasecat:/tmp/hbase-root-master.pid:No such file or directory 是因为默认情况下pid文件保存在/tmp目录下,/tmp目录下的文件很容易丢失(重启后基本就会删除)
解决办法:修改hbase-env.sh 中 pid文件的存放路径
vi /usr/hbase/hbase-1.2.4/conf/hbase-env.sh
# The directory where pid files are stored. /tmp by default.
export HBASE_PID_DIR=/var/hadoop/pids
十 安装Hive
1. Master(作为Hive的Client)
① 创建Hive目录,并解压安装包
mkdir /usr/hive
tar -zxvf apache-hive-2.1.1-bin.tar.gz -C /usr/hive/
② 配置环境变量
vi /etc/profile
# 文件 /etc/profile
# Hive enviroment
export HIVE_HOME=/usr/hive/apache-hive-2.1.1-bin
export PATH=$PATH:$HIVE_HOME/bin
③ 读取并执行 /etc/profile 文件
source /etc/profile
④ 修改hive-env.sh
添加 HADOOP_HOME 环境变量
cp /usr/hive/apache-hive-2.1.1-bin/conf/hive-env.sh.template /usr/hive/apache-hive-2.1.1-bin/conf/hive-env.sh
vi /usr/hive/apache-hive-2.1.1-bin/conf/hive-env.sh
# 文件 /usr/hive/apache-hive-2.1.1-bin/conf/hive-env.sh
HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
⑤ 新建hive-site.xml配置文件
vi /usr/hive/apache-hive-2.1.1-bin/conf/hive-site.xml
# 文件 /usr/hive/apache-hive-2.1.1-bin/conf/hive-site.xml
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_remote/warehouse</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://Slave1:9083</value>
</property>
</configuration>
⑥ 解决版本冲突和jar包依赖问题
cp /usr/hive/apache-hive-2.1.1-bin/lib/jline-2.12.jar /usr/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/
2. Slave1(作为Hive的Server)
① 在Master角色上给slave1发送hive文件
同时将Software文件夹中的 mysql 的驱动程序发送到 Slave1 的 hive安装目录lib中
scp -r /usr/hive root@slave1:/usr/hive
scp mysql-connector-java-5.1.5-bin.jar slave1:/usr/hive/apache-hive-2.1.1-bin/lib/
② 新建hive-site.xml配置文件
vi /usr/hive/apache-hive-2.1.1-bin/conf/hive-site.xml
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_remote/warehouse</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURI</name>
<value>jdbc:mysql://slave2:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
</configuration>
3. Slave2(安装MySQL)
① 安装mysql
- 安装wget
yum -y install wget
- 下载 mysql的repo源
wget http://repo.mysql.com/mysql57-community-release-el7-9.noarch.rpm
- 安装mysql的 repo 源以及 Mysql
rpm -ivh mysql57-community-release-el7-9.noarch.rpm
yum install mysql-community-server
② 查看安装的mysql版本(注意V是大写)
mysql -V

③ 重载所有修改过的配置文件
systemctl daemon-reload
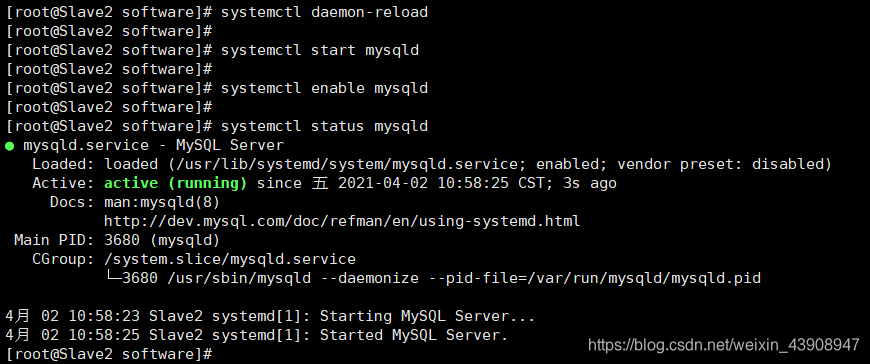
④ 启动 Mysql 服务
systemctl start mysqld # 启动mysql服务
systemctl enable mysqld # 设置开机自启
systemctl status mysqld # 查看mysql启动状态
⑤ 登陆mysql
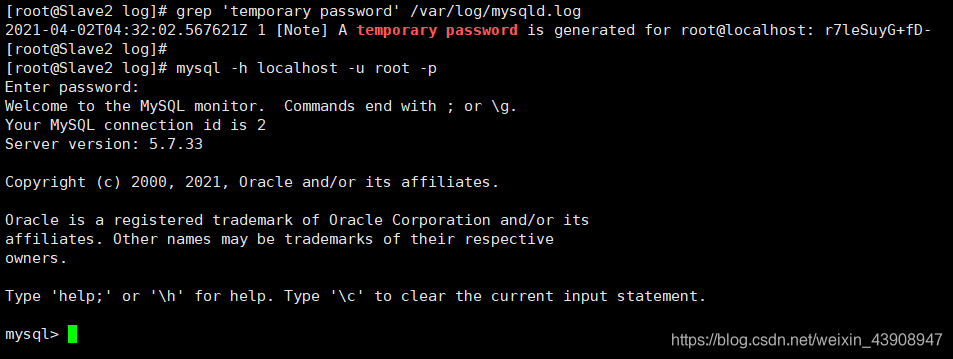
查看mysql root用户的初始密码,复制密码,登录
tips:如果没有查找到初始密码,可能是有之前安装过MySQL,卸载不干净还有残留的数据
### 此处为终端输入命令,因为使用引用格式会改变下行引号,所以此处特例使用代码块
grep "temporary password" /var/log/mysqld.log
mysql -h localhost -u root -p
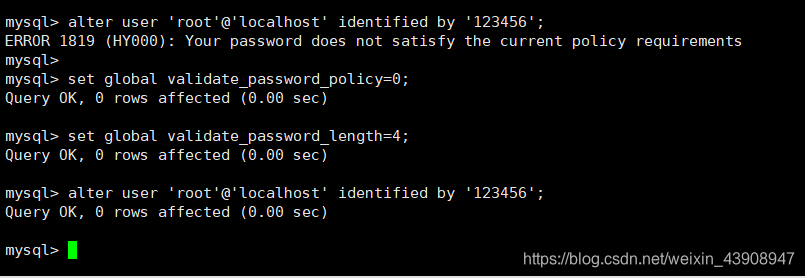
⑥ 修改mysql的root用户密码
此处设置密码为 ‘123456’ ,因为密码太简单会被拒绝,所以前两句修改了mysql的密码安全策略
### 此处为终端输入命令,因为使用引用格式会改变下行引号,所以此处特例使用代码块
### Mysql 命令环境中 ###
set global validate_password_policy=0;
set global validate_password_length=4;
alter user 'root'@'localhost' identified by '123456';
⑦ 退出 Mysql
按下 ctrl + D 即可退出,或者输入 quit 退出
⑧ 设置远程登陆
登陆mysql
mysql -h localhost -u root -p
创建一个远程用户root
添加远程登录用户(授权)
刷新权限
### 此处为终端输入命令,因为使用引用格式会改变下行引号,所以此处特例使用代码块
### Mysql 命令环境中 ###
# 创建一个远程用户root
create user 'root'@'%' identified by '123456';
# 添加远程登录用户
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123456';
grant all privileges on *.* to 'root'@'%' with grant option;
# 刷新权限
flush privileges;
4. 启动Hive
启动Hive前,先同步时间,然后按顺序启动Zookeeper、Hadoop、Hbase,再启动Hive
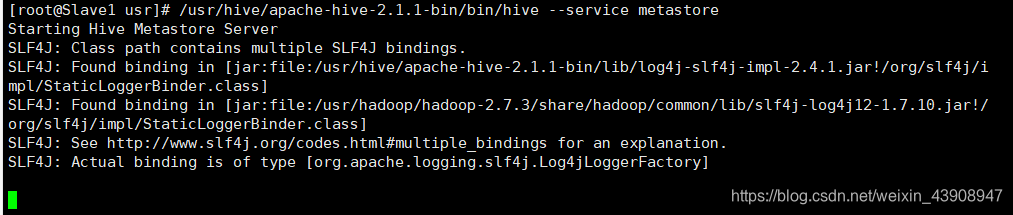
① Slave1:先启动Hive Server(服务器端)
/usr/hive/apache-hive-2.1.1-bin/bin/hive --service metastore & # & 是在后台运行,可不加
② Master:再启动Hive Client(客户端)
/usr/hive/apache-hive-2.1.1-bin/bin/hive

③ 使用 Hive 客户端查看数据库
show databases;
④ 关闭 Hive
Hive Server 可以通过 ps -ef | grep hive 来看hive 的端口号,然后 kill 结束相关的进程。
Hive Client 可以按下 Ctrl + D 退出,或输入 quit
十一 安装Scala
1. Master 角色
① 建立Scala目录,并解压安装包
mkdir /usr/scala
tar -zxvf scala-2.11.12.tgz -C /usr/scala
② 配置环境变量
vi /etc/profile
# 文件 /etc/profile
# SCALA enviroment
export SCALA_HOME=/usr/scala/scala-2.11.12
export PATH=$SCALA_HOME/bin:$PATH
读取并执行 /etc/profile 文件
source /etc/profile
2. Slave角色
① 在Maser上给Slave发送 Scala 文件
scp -r /usr/scala Slave1:/usr
scp -r /usr/scala Slave2:/usr
② 发送环境变量
scp /etc/profile root@Slave1:/etc/
scp /etc/profile root@Slave2:/etc/
③ 读取并执行 /etc/profile 文件
source /etc/profile
④ 查看 Scala 版本
scala -version

十二 安装Spark
1. Master 角色
① 建立Spark目录,并解压安装包
mkdir /usr/spark
tar -zxvf spark-2.4.0-bin-hadoop2.7.tgz -C /usr/spark
② 配置环境变量
vi /etc/profile
# 文件 /etc/profile
# SPARK enviroment
export SPARK_HOME=/usr/spark/spark-2.4.0-bin-hadoop2.7
export PATH=$SPARK_HOME/bin:$PATH
③ 读取并执行 /etc/profile 文件
source /etc/profile
④ 配置 spark-env.sh 文件
cp /usr/spark/spark-2.4.0-bin-hadoop2.7/conf/spark-env.sh.template /usr/spark/spark-2.4.0-bin-hadoop2.7/conf/spark-env.sh
vi /usr/spark/spark-2.4.0-bin-hadoop2.7/conf/spark-env.sh
# 文件 /usr/spark/spark-2.4.0-bin-hadoop2.7/conf/spark-env.sh
export SPARK_MASTER_IP=Master
export SCALA_HOME=/usr/scala/scala-2.11.12
export SPARK_WORKER_MEMRY=2g
export JAVA_HOME=/usr/java/jdk1.8.0_171
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export HADOOP_CONF_DIR=/usr/hadoop/hadoop-2.7.3/etc/hadoop
⑤ 修改slaves文件
cp /usr/spark/spark-2.4.0-bin-hadoop2.7/conf/slaves.template /usr/spark/spark-2.4.0-bin-hadoop2.7/conf/slaves
vi /usr/spark/spark-2.4.0-bin-hadoop2.7/conf/slaves
删除原先内容:localhost,添加如下内容。
# 文件 /usr/spark/spark-2.4.0-bin-hadoop2.7/conf/slaves
Slave1
Slave2
2. Slave角色
① 在Master机器上给Slave发送spark文件
scp -r /usr/spark Slave1:/usr
scp -r /usr/spark Slave2:/usr
② 发送环境变量文件
scp /etc/profile root@Slave1:/etc/
scp /etc/profile root@Slave2:/etc/
③ 读取并执行 /etc/profile 文件
source /etc/profile
④ 启动 Spark
启动Spark前,需要先启动Zookeeper和hadoop,再启动Spark
/usr/spark/spark-2.4.0-bin-hadoop2.7/sbin/start-all.sh
⑤ 查看是否启动成功
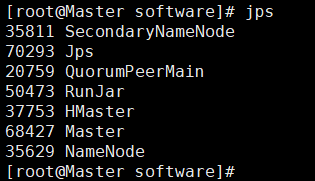
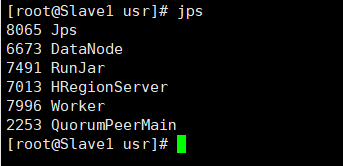
-
jps查看 → worker和master角色
-
浏览器 → https://192.168.31.170:8080
总结:三台机器配置内容的不同点
| 章节 | 主要内容 | 不同机器的主要区别 |
|---|---|---|
| 第一节 | 修改 IP 地址 | IP地址 |
| 第二节 | 修改主机名 | 主机名字 |
| 第三节 | 关闭防火墙 | 相同 |
| 第四节 | SSH 免密登录 | 发送公钥的目标 |
| 第五节 | 时间同步 | 对ntp.conf文件配置 |
| 第六节 | 安装 JDK | 相同 |
| 第七节 | 安装 Zookeeper | myid文件中的机器号 |
| 第八节 | 安装 Hadoop | 相同 |
| 第九节 | 安装 Hbase | 相同 |
| 第十节 | 安装 Hive | 分工:客户端、服务器、数据库 |
| 第十一节 | 安装 Scala | 相同 |
| 第十二节 | 安装 Spark | 相同 |