微服务专题-面试篇
说明
以下总结来自于黑马程序员网课,地址:https://www.bilibili.com/video/BV1LQ4y127n4?p=172&spm_id_from=pageDriver
Spring Cloud常见组件有哪些?
问题说明:这个题目主要考察对SpringCloud的组件基本了解
难易程度:简单
参考话术:
SpringCloud包含的组件很多,有很多功能是重复的。其中最常用组件包括:
-
- 注册中心组件: Eureka、Nacos等
-
- 负载均衡组件:Ribbon
-
- 远程调用组件:OpenFeign
-
- 网关组件:Zull、Gateway
-
- 服务保护组件:Hystrix、Sentinel
-
- 服务配置管理组件:SpringCloudConfig、Nacos
Nacos的服务注册表结构是怎样的?
问题说明:考察对Nacos数据分级结构的了解,以及Nacos源码的掌握情况
难易程度:一般
参考话术:
Nacos采用了数据的分级存储模型,最外层是NameSpace,用来隔离环境,然后是Group,用来对服务分组。接下来就是服务(Service)了,一个服务包含多个实例,但是可能处于不同机房,因此Service下有多个集群(Cluster),Cluster下是不同的实例(Instance)。
对应到Java代码中,Nacos采用了一个多层的Map来表示。结构为Map<String,Map<String,Service>>,其中最外层Map的key就是namespaceId,值是一个Map。内层Map的Key是group拼接serviceName,值是Service对象。Service对象内部又是一个Map,key是集群名称,值是Cluster对象。而Cluster对象。而Cluster对象内部维护了Instance的集合。
部分源码组成
Map(namespace,Map(group::serviceName,Service))
Service - > Map<String,Cluster>
Cluster - > Set<Instance>
Nacos如何支撑数十万服务注册压力?
问题说明:考察对Nacos源码的掌握情况
难易程度:难
参考话术:
Nacos内部接收到注册的请求时,不会立即写数据,而是将服务注册的任务放入一个阻塞队列就立即响应给客户端。然后利用线程池读取阻塞队列中的任务,异步来完成实例更新,从而提高并发写能力。
Nacos如何避免并发读写冲突问题?
问题说明:考察对Nacos源码的掌握情况
难易程度:难
参考话术:
Nacos在更新实例列表时,会采用CopyOnWrite技术,首先将旧的实例列表拷贝一份,然后更新拷贝的实例列表,再用更新后的实例列表来覆盖旧的实例列表。
这样在更新的过程中,就不会对读实例列表的请求产生影响,也不会出现脏读问题了。
Nacos与Eureka的区别有哪些?
问题说明:考察对Nacos、Eureka的底层实现的掌握情况
难易程度:难
参考话术:
Nacos与Eureka有相同点,也有不同之处,可以从以下几点来描述:
1、接口方式:Nacos与Eureka都对外暴露了Rest风格的API接口,用来实现服务注册、发现等功能
2、实例类型:Nacos的实例有永久和临时实例之分;而Eureka只支持临时实例
3、健康检测:Nacos对临时实例采用心跳模式检测,对永久实例采用主动请求来检测;Eureka只支持心跳
4、服务发现:Nacos支持定时拉取和订阅推送两种模式;Eureka只支持定时拉取模式
Sentinel的线程隔离与Hystix的线程隔离有什么差别?
问题说明:考察对线程隔离方案的掌握情况
难易程度:一般
参考话术:
Hystix默认是基于线程池实现的线程隔离,每一个被隔离的业务都要创建一个独立的线程池,线程过多会带来额外的CPU开销,性能一般,但是隔离性更强。
Sentinel是基于信号量(计数器)实现的线程隔离,不用创建线程池,性能较好,但是隔离性一般。
Sentinel的限流与Gateway的限流有什么差别?
问题说明:考察对限流算法的掌握情况
难易程度:难
参考话术:
限流算法常见的有三种实现:滑动时间窗口、令牌桶算法、漏桶算法。Gateway则采用了基于Redis实现的令牌桶算法。
而Sentinel内部却比较复杂:
-
- 默认限流模式是基于滑动时间窗口算法
-
- 排队等待的限流模式则基于漏桶算法
-
- 而热点参数限流则是基于令牌桶算法
什么是限流?
对应用服务器的请求做限制,避免因过多请求而导致服务器过载甚至宕机。
限流算法常见的包括两种:
1. 计数器算法,又包括窗口计数器算法、滑动窗口计数器算法
2. 令牌桶算法(Token Bucket)
3. 漏桶算法(Leaky Bucket)
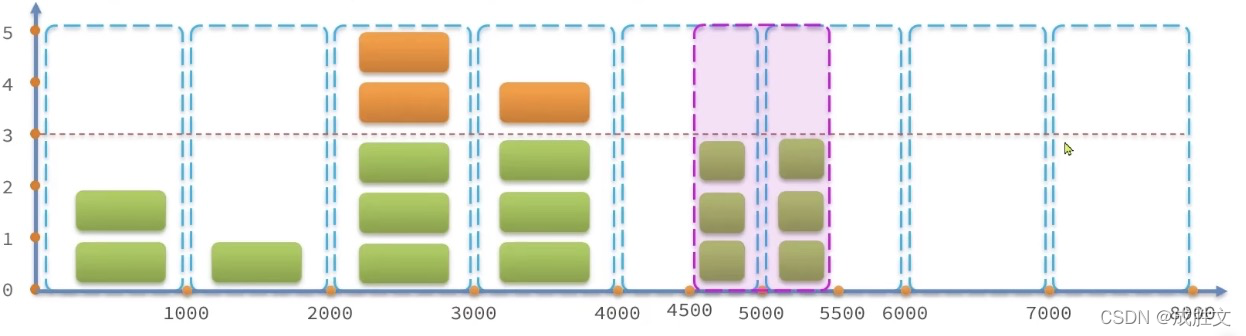
固定窗口计数器算法
固定窗口计数器算法概念如下:
-
- 将时间划分为多个窗口,窗口时间跨度称为Interval,本例中为1000ms;
-
- 每个窗口维护一个计数器,每有一次请求就将计数器加一,限流就是设置计数器阈值,本例为3
-
- 如果计数器超过了限流阈值,则超出阈值的请求都被丢弃。
当4500 - 5500发起了6次请求,可能会出现过多请求而导致服务器过载甚至宕机,
因此就有了滑动窗口计数器算法
滑动窗口计数器算法
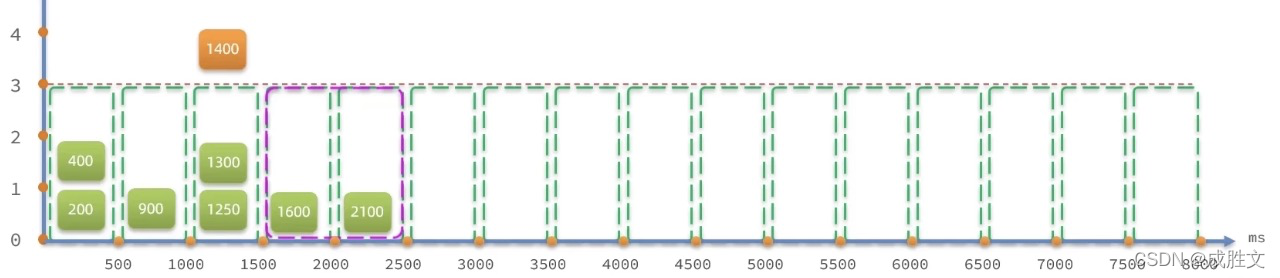
滑动窗口计数器算法会将一个窗口划分为n个更小的区间,例如
-
- 窗口时间跨度Interval为1秒;区间数量 n = 2,则每个小区间时间跨度为500ms
-
- 限流阈值依然为3,时间窗口(1秒)内请求超过阈值时,超出的请求被限流
-
- 窗口会根据当前请求所在时间(currentTime)移动,窗口范围是从(currentTime - Interval)之后的第一个时区开始,到currentTime所在时区结束。
- 窗口会根据当前请求所在时间(currentTime)移动,窗口范围是从(currentTime - Interval)之后的第一个时区开始,到currentTime所在时区结束。
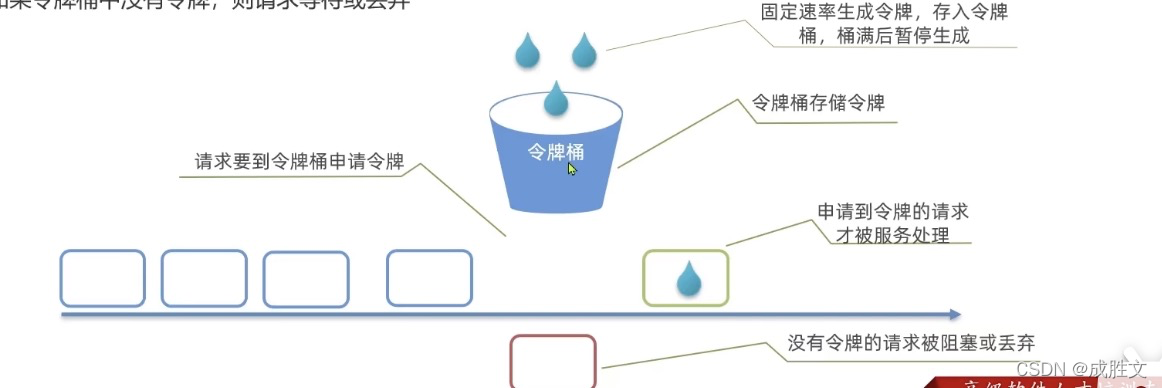
令牌桶算法
令牌桶算法说明:
-
- 以固定的速率生成令牌,存入令牌桶中,如果令牌桶满了以后,多余令牌丢弃
-
- 请求进入后,必须先尝试从桶中获取令牌,获取到令牌后才可以被处理
-
- 如果令牌桶中没有令牌,则请求等待或丢弃
但是这种会有一种现象,如果1秒每生成5个令牌,但是没有人请求,1秒后有10个请求,也会发10个令牌,解决这种问题,可以把阈值设置小一点,比如3
- 如果令牌桶中没有令牌,则请求等待或丢弃
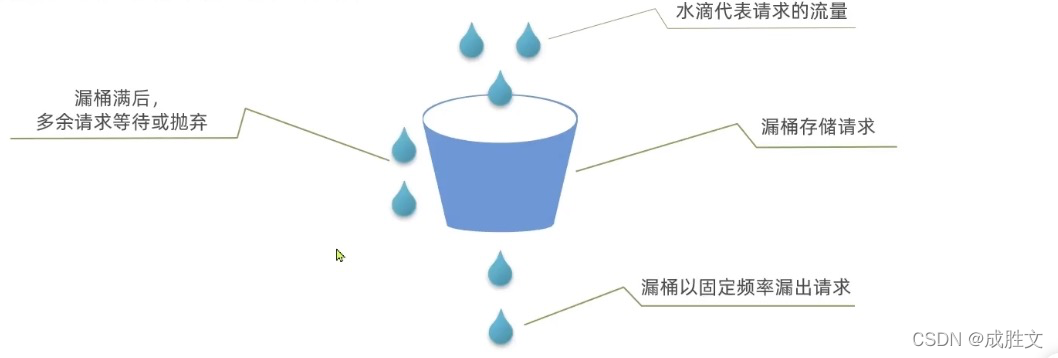
漏桶算法说明:
-
- 将每个请求视作“水滴”放入“漏桶”进行存储;
-
- “漏桶”以固定速率向外“漏”出请求来执行,如果“漏桶”空了则停止“漏水”;
-
- 如果“漏桶”满了则多余的“水滴”会被直接丢弃。
代码实现使用队列实现,先进先出
限流算法对比
因为计数器算法一般都会采用滑动窗口计数器,所以这里我们对比三种算法:
