1 介绍
年份:2024
期刊: Proceedings of the AAAI Conference on Artificial Intelligence
引用量:3
代码:https://github.com/Lsabetta/MIND
Bonato J, Pelosin F, Sabetta L, et al. MIND: Multi-Task Incremental Network Distillation[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2024, 38(10): 11105-11113.
本文介绍了MIND算法,它是一种用于类增量学习的多任务网络蒸馏方法,通过参数隔离和蒸馏技术来提升模型在新任务上的学习性能,同时保留对旧任务的记忆。MIND通过分配子网络来处理单个任务,并在子网络之间共享一部分参数以促进知识转移。MIND利用蒸馏程序将新任务训练的新模型的知识封装并压缩到子网络片段中。
2 创新点
- 参数隔离方法:提出了一种新的参数隔离方法MIND,通过创建针对每个增量任务的子网络,实现对新任务的学习,同时保留对旧任务的记忆。
- 交替蒸馏程序:引入了两种替代的蒸馏程序,显著提高了MIND的效率,增加了每个子网络的累积知识。
- BatchNorm层的优化:在子网络内跨任务优化BatchNorm层,提高了模型对数据分布变化的适应能力。
- 自蒸馏机制:提出了一种自蒸馏过程,允许MIND在内存限制下工作,通过使用MIND自身替代新模型进行知识蒸馏。
- 门控机制:引入了门控机制来指导反向传播过程中的梯度流动,确保梯度更准确地流向活跃的网络单元。
3 相关研究
- 架构基础方法(Architectural-Based):
- 目标是通过修改模型架构来减轻灾难性遗忘。
- 代表性工作包括:
- Progressive Neural Networks (PNN) [Rusu et al., 2016]
- Dynamically Expandable Networks (DEN) [Yoon et al., 2018]
- PackNet [Mallya and Lazebnik, 2018]
- 正则化基础方法(Regularization-Based):
- 专注于通过修改学习目标或引入正则化项来保留以前任务的知识。
- 代表性工作包括:
- Learning without Forgetting (LwF) [Li and Hoiem, 2018]
- Learning without Memorizing (LwM) [Dhar et al., 2019]
- Synaptic Intelligence (SI) [Zenke, Poole, and Ganguli, 2017]
- Memory Aware Synapses (MAS) [Aljundi et al., 2018]
- Elastic Weight Consolidation (EWC) [Kirkpatrick et al., 2017]
- RWalk [Chaudhry et al., 2018]
- PASS [Zhu et al., 2021]
- 回放基础方法(Rehearsal-Based):
- 通过在训练过程中显式存储和回放过去的经验来解决灾难性遗忘。
- 代表性工作包括:
- Experience Replay (ER) [Rolnick et al., 2019]
- GDumb [Prabhu, Torr, and Dokania, 2020]
- iCarl [Rebuffi et al., 2017]
- 此外,还有通过生成网络生成回放数据的伪回放方法,如 [Shin et al., 2017]。
4 算法
4.1 算法原理
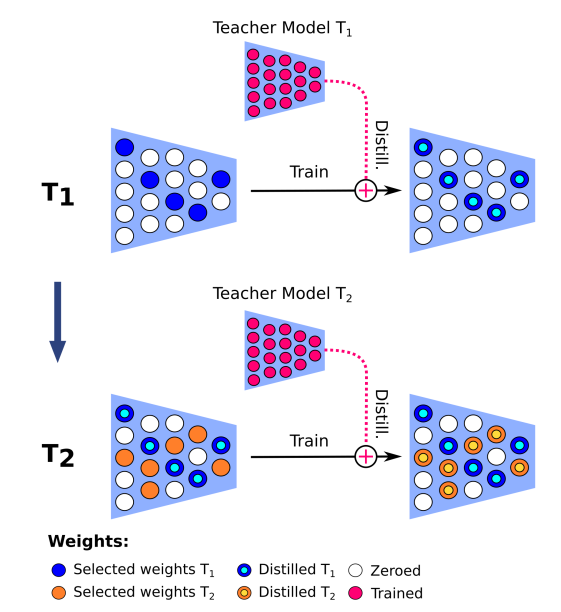
- 子网络划分:MIND将整个网络划分为多个子网络,每个子网络负责处理一个特定的任务。这些子网络在参数上不是完全独立的,它们共享一部分参数,以便于知识迁移。
- 知识蒸馏:对于每个新任务,MIND会训练一个新模型(称为教师模型),然后将这个新模型的知识蒸馏到对应的子网络中。这一过程通过匹配新模型和子网络的输出概率分布来实现。
- 参数优化:MIND采用了一种迭代的优化过程,包括训练、剪枝(设置一部分权重为零)和重新训练,以适应新任务。在这个过程中,与当前任务相关的参数会被优化,而与之前任务相关的参数则被冻结。
- 门控机制:MIND引入了门控机制来指导反向传播过程中的梯度流动,确保梯度只流向活跃的网络单元。这有助于更精确地计算梯度,从而实现更快速和有效的学习。
- Batch Norm层的优化:MIND在每个任务中训练Batch Norm层,并保存每个子网络对应的参数。在推理阶段,使用与选定子网络相匹配的Batch Norm参数,以更好地适应每个任务。
- 自蒸馏机制:为了在内存受限的环境中使用,MIND提出了一种自蒸馏过程。在这一过程中,MIND直接在子网络上训练,而不是为每个新任务初始化一个新模型。然后,选择最重要的参数进行蒸馏,以减少内存使用。
- 推理过程:在推理阶段,每个输入图像通过所有子网络传递,收集对应的逻辑向量(logits)。然后,通过softmax函数和温度缩放来计算概率分布,选择概率最高的类别作为预测结果。
4.2 算法步骤
- 初始化子网络:MIND算法开始时,会初始化一个包含多个子网络的模型,每个子网络负责处理一个特定的任务。
- 新任务训练:对于每个新任务,MIND会初始化一个新的网络(教师模型),并从零开始训练这个网络。
- 知识蒸馏:
- 一旦新网络(教师模型)训练完成,它将作为知识源,通过蒸馏过程将其知识传递给MIND中的对应子网络(学生模型)。
- 蒸馏过程使用Jensen-Shannon损失(LSD),结合交叉熵损失(LCE),通过匹配教师模型和子网络的输出概率分布来优化子网络。
- 参数剪枝:
- 在蒸馏过程中,MIND会随机选择一部分网络权重进行剪枝,即设置为零,这些未被选择的权重在后续任务中将不会被优化。
- 剪枝后的网络(记为 ˆf)将只更新与当前任务相关的权重,而与之前任务相关的权重则被冻结。
- 门控机制:
- MIND引入了门控机制,通过一个二进制门控掩码来控制反向传播过程中的梯度流动,确保梯度只流向活跃的网络单元。
- Batch Norm层优化:
- 对于每个任务,MIND会训练Batch Norm层,并保存每个子网络对应的参数。
- 在推理阶段,根据选定的子网络使用相应的Batch Norm参数,以适应任务特定的数据分布。
- 自蒸馏过程(可选):
- 在内存受限的环境中,MIND可以采用自蒸馏过程,其中MIND自身替代新模型进行知识蒸馏。
- 剪枝后的模型中,未被剪枝的权重(蓝色圆圈)将作为“教师”,而剩余的(未激活的)权重将作为“学生”,进行自蒸馏过程。用于降低模型规模。
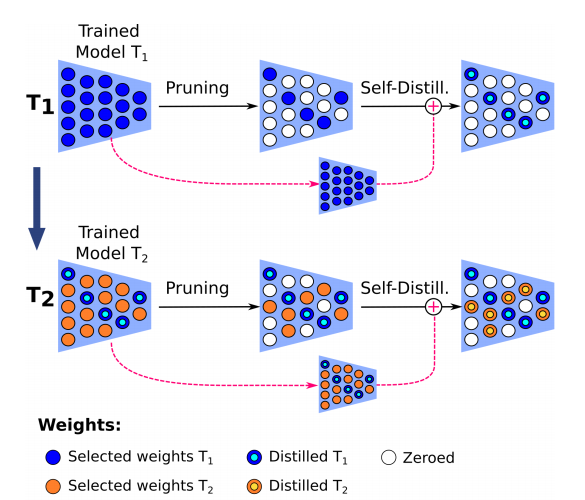
- 推理:
- 在推理阶段,每个输入图像通过所有子网络传递,收集每个子网络的逻辑向量(logits)。
- 通过softmax函数和温度缩放来计算概率分布,选择概率最高的类别作为预测结果。
5 实验分析
(1)数据集
- 实验涉及四个标准数据集:CIFAR100/10、TinyImageNet/10、Core50/10和Synbols/10,这些数据集被用来测试类增量(CI)学习场景下的性能。
- 实验还包括了Core50数据集的域增量(DI)学习场景。
(2)评价指标
- 任务感知准确率(Task-Aware Accuracy, ACCT AW):
- 这个指标衡量了在测试时可以访问任务标签的情况下模型的性能。
- 在这种设置下,模型能够查询正确的子网络来进行预测,因此能够直接评估每个任务的准确率。
- ACCT AW计算公式为:$ ACCT AW = \frac{1}{T} \sum_{t=1}^{T} a_t < f o n t s t y l e = " c o l o r : r g b ( 6 , 6 , 7 ) ; " > < / f o n t > < f o n t s t y l e = " c o l o r : r g b ( 6 , 6 , 7 ) ; " > 其中 T 是总任务数, < / f o n t > <font style="color:rgb(6, 6, 7);"> </font><font style="color:rgb(6, 6, 7);">其中T是总任务数,</font> <fontstyle="color:rgb(6,6,7);"></font><fontstyle="color:rgb(6,6,7);">其中T是总任务数,</font> a_t $是第t个任务的准确率。
- 任务不可知准确率(Task-Agnostic Accuracy, ACCT AG):
- 这个指标衡量了在测试时无法访问任务标签的情况下模型的性能。
- 在这种设置下,模型必须独立识别每个输入样本属于哪个任务,并且只能使用该任务对应的子网络来进行预测。
- ACCT AG计算公式为:$ ACCT AG = \frac{1}{C} \sum_{c=1}^{C} a_c < f o n t s t y l e = " c o l o r : r g b ( 6 , 6 , 7 ) ; " > < / f o n t > < f o n t s t y l e = " c o l o r : r g b ( 6 , 6 , 7 ) ; " > 其中 C 是数据集中的总类别数, < / f o n t > <font style="color:rgb(6, 6, 7);"> </font><font style="color:rgb(6, 6, 7);">其中C是数据集中的总类别数,</font> <fontstyle="color:rgb(6,6,7);"></font><fontstyle="color:rgb(6,6,7);">其中C是数据集中的总类别数,</font> a_c $是第c个类别的准确率。
(3)结果分析
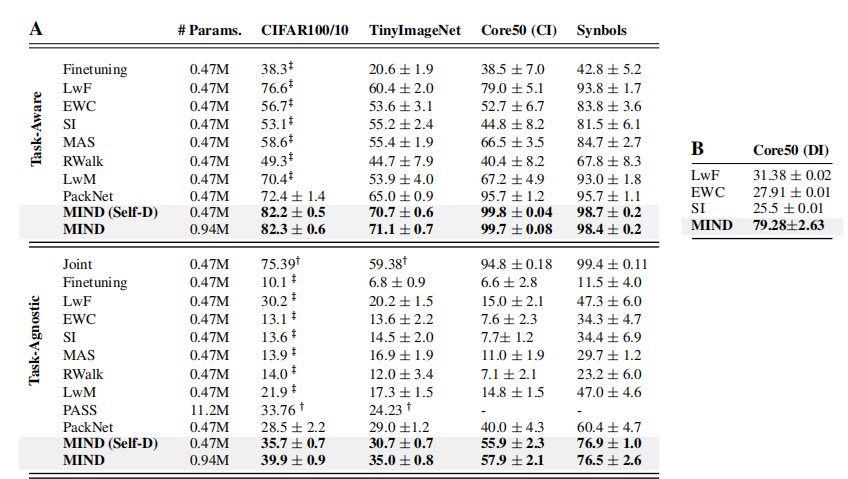
- MIND在多个数据集上一致性地超越了其他方法,包括Finetuning、LwF、EWC、SI、MAS、RWalk、LwM和PackNet等。
- 在CIFAR100/10数据集上,MIND实现了大约+6%的ACCT AG和+10%的ACCT AW提升。
- 在TinyImageNet数据集上,MIND在ACCT AG和ACCT AW上都显著超越了所有对比方法。
6 思考
(1)本文是多任务蒸馏,即第一次N个任务同时学习后,然后将新的N个模型蒸馏到旧的N个模型中。这个蒸馏是多对多的关系。而不是多个子任务的模型蒸馏到一个模型,多对一的关系。
MIND算法采用的蒸馏策略是分别对每个子任务的模型进行蒸馏。这意味着,对于每个新任务,都会训练一个新模型(教师模型),然后将这个新模型的知识蒸馏到MIND框架中的相应子网络(学生模型)。
具体来说,MIND算法的蒸馏步骤如下:
- 单独训练:对于每个新任务,MIND都会初始化并训练一个全新的网络(教师模型),这个网络专门针对当前任务的数据进行训练。
- 单独蒸馏:训练完成后,这个新模型(教师模型)的知识会被蒸馏到MIND中的一个特定子网络(学生模型)。这个过程是针对每个任务单独进行的,确保每个子网络能够学习到对应任务的特定知识。
- 参数隔离:MIND利用参数隔离技术,确保每个子网络在处理其特定任务时,只更新与该任务相关的参数,而与其它任务相关的参数则保持冻结状态。
- 迭代优化:这个过程会迭代进行,每个新任务都会经历训练和蒸馏步骤,从而使得MIND能够持续地学习新任务,同时保留对旧任务的记忆。
(2)MIND算法蒸馏方法是什么?
在MIND算法中,蒸馏损失函数 LSD定义为:
$ L_{SD}=\sum_{x_i \in X}\frac{1}{2}D_{KL}(p(z∣x,\psi)|| p(z∣x,\phi_i))+\frac{1}{2}D_{KL}(p(z∣x,\phi_i)|| p(z∣x,\psi)) $
这里 $ \psi < f o n t s t y l e = " c o l o r : r g b ( 6 , 6 , 7 ) ; " > 表示教师模型的参数, < / f o n t > <font style="color:rgb(6, 6, 7);">表示教师模型的参数,</font> <fontstyle="color:rgb(6,6,7);">表示教师模型的参数,</font> \phi_i $表示第 i个子网络的参数,z是网络的输出,x是输入数据。这个损失函数衡量了教师模型和学生模型在给定输入 x下的输出概率分布之间的Jensen-Shannon散度。
(3)MIND算法中门控机制是什么?
在MIND算法中,门控机制的作用是优化学习过程,通过控制反向传播过程中的梯度流动来提高学习效率和性能。具体来说,门控机制通过以下方式实现其作用:
- 梯度流向控制:
- 在反向传播过程中,门控机制确保梯度只流向那些在前向传播中活跃的网络单元(即对当前任务有贡献的单元)。
- 这意味着与当前任务无关的网络单元在反向传播时不会接收到梯度更新,从而减少了无关参数的干扰,提高了学习的目标性和效率。
- 参数活跃状态管理:
- 门控机制通过一个二进制门控掩码(mask)来标记每个参数的活跃状态。如果参数被分配给任何子网络,则被标记为活跃(mask设置为1);如果参数尚未分配,则被标记为非活跃(mask设置为0)。
- 在活跃的权重中,旧子网络的权重在反向传播过程中被冻结,而当前子网络的权重则被更新。
- 推理过程中的应用:
- 在推理阶段,门控机制同样通过二进制掩码来选择和激活相关的子网络,以处理输入数据。
- 这种方法确保了在推理时,只有与当前任务相关的子网络参与计算,从而提高了推理的准确性和效率。
- 实现方式:
- 门控机制的实现通常涉及到在网络的每个可训练参数上附加一个门控信号,这个信号可以是一个二进制值(0或1),用来指示该参数是否应该参与当前任务的学习。
- 在前向传播时,门控信号决定了哪些参数会被激活并参与计算。
- 在反向传播时,门控信号决定了哪些参数会接收梯度更新。未被激活的参数将不会接收到梯度,因此不会被更新。
(3)本文中MIND算法通过从现有子网络中随机选择一些参数进行优化,这些参数之前没有在任何任务中被优化。这种方法虽然有其优势,但也存在一些潜在的缺点:
- 随机性导致不一致性:
- 随机选择参数可能导致每次训练过程中学习到的知识存在较大差异,这会影响模型的一致性和稳定性。
- 忽略先前任务的相关性:
- 随机选择可能忽略了新任务与先前任务之间的潜在相关性,导致无法充分利用已有的知识来加速新任务的学习。
- 参数利用率低:
- 随机选择参数可能导致一些有用的参数未被充分利用,而一些不重要的参数却被频繁更新,降低了参数的利用率。
- 灾难性遗忘:
- 虽然MIND通过蒸馏技术缓解了灾难性遗忘问题,但随机选择参数可能导致一些先前任务的有用知识被新任务的学习所覆盖。
- 过拟合风险:
- 在新任务上随机选择并优化参数可能导致模型在新任务上过拟合,特别是当新任务的数据量较小时。
- 计算资源浪费:
- 随机选择参数可能导致一些参数的重复训练,造成计算资源的浪费。
- 难以找到最优子网络:
- 随机选择使得找到最优子网络结构变得更加困难,因为缺乏一种系统的方法来评估不同子网络结构的性能。
- 难以调试和解释:
- 随机性使得模型的决策过程更加难以调试和解释,特别是在需要模型可解释性的应用场景中。
- 依赖于任务的独立性:
- 如果新任务与先前任务高度相关,随机选择参数可能导致无法有效利用先前任务的知识。
- 难以平衡保留旧知识与学习新知识:
- 随机选择参数可能导致在保留旧任务知识和学习新任务知识之间的权衡不当。
为了克服这些缺点,可以考虑采用更先进的参数选择策略,例如基于任务相关性的参数选择,或者利用元学习(meta-learning)的方法来指导参数的选择和更新。此外,可以通过正则化技术、经验回放(experience replay)或者通过调整网络结构来提高模型的泛化能力和稳定性。)