matlab/simlulink强化学习环境搭建与智能体训练方法
强化学习分为两个部分,智能体代理和与智能体交互的环境,即便代理可以用现成的模型调调参,但应用场景的数学模型依然是非常难搭建的部分,matlab和simulink的联合仿真无疑给Reinforcement Learning提供了一个非常强大的仿真平台,本篇以DDPG算法为例,详细讲讲matlab/simlulink强化学习环境搭建与智能体训练的具体步骤,及一些参数的设置和调整。
首先得有一个已经搭建好的simulink环境,至于simulink怎么用以及数学模型怎么建得要根据自己的应用场景和需要来解决,这部分不是这篇文章要解决的内容,我也没能力去给各位建模,第一步就自动默认各位的环境都已经搭好了。
simulink里需要进行的操作
接着在simulink里加入RL agent 模块,根据环境需要对一个输出action和三个输入reward、observation、stop signal进行连接,这里输入输出最好都用simulink里的块进行连接,有助于提高训练速度。observation数值太大的话最好在simulink里的相关模块里归一化,不然你会发现不管奖励函数怎么写,算法参数怎么调,无论代理训练多少次依然是人工智障。stop signal在设置的时候没什么好说的,尽量别太让训练过程结束的太早或者太晚,过早可能导致代理没来得及对失败经验进行尝试就结束了,过晚的话浪费时间。有关于reward函数怎么写的问题一般会成为整个强化学习过程最核心也是最难的部分,可以说奖励函数的写法是根本没有一个系统的方法或者评判标准的,如果说真的有一个评判标准的话我觉得能快速训练出来智能体的就是好函数,训练不出来必然就有问题。很多人们自以为很好的奖励函数依然会被智能体抓到漏洞,要么在局部最优里疯狂迭代,要么就会导致学习梯度过大,代理只输出边界值。总结一下奖励函数的建立方法就是要根据具体情况无中生有,随机应变,条条大路通罗马。
simulink里的RL代理连接好了大概就跟下面差不多:
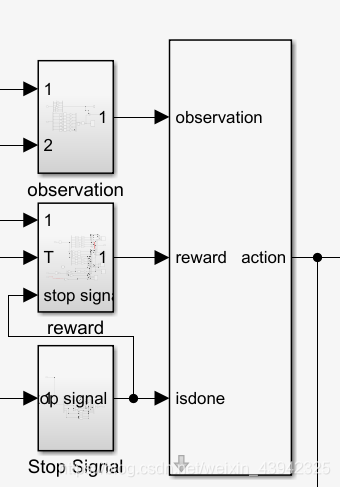
主程序部分
首先打开环境
open_system('XXXXXXXXXX')然后对观测值和代理输出值的边界和维度进行定义
numObs = 12;
obsInfo = rlNumericSpec([numObs 1],...
'LowerLimit',[-inf -inf -inf -inf -inf -inf -inf -inf -inf -inf -inf -inf ]',...
'UpperLimit',[ inf inf inf inf inf inf inf inf inf inf inf inf]');
obsInfo.Name = 'observations';
obsInfo.Description = 'anchor,anchor error, w,w error';
numObservations = obsInfo.Dimension(1);
numAct =3;
actInfo = rlNumericSpec([numAct 1]);
actInfo.Name = 'Torque';
numActions = actInfo.Dimension(1);定义强化学习环境和智能体
env = rlSimulinkEnv('XXXXXXXXXX','XXXXXXXXXX/RL Agent',...
obsInfo,actInfo);自定义环境初始化函数,函数在最后
env.ResetFcn = @localResetFcn;定义仿真时间和智能体行动时间步长
Ts = 5.0;
Tf = 3000;确定随机种子,保证可复现性
rng(0)创建DDPG智能代理
创建critic网络
criticLayerSizes = [400 300];
statePath = [
imageInputLayer([numObs 1 1],'Normalization','none','Name', 'observation')
fullyConnectedLayer(criticLayerSizes(1), 'Name', 'CriticStateFC1', ...
'Weights',2/sqrt(numObs)*(rand(criticLayerSizes(1),numObs)-0.5), ...
'Bias',2/sqrt(numObs)*(rand(criticLayerSizes(1),1)-0.5))
reluLayer('Name','CriticStateRelu1')
fullyConnectedLayer(criticLayerSizes(2), 'Name',