参考来源:《超标量处理器设计》 —— 姚永斌
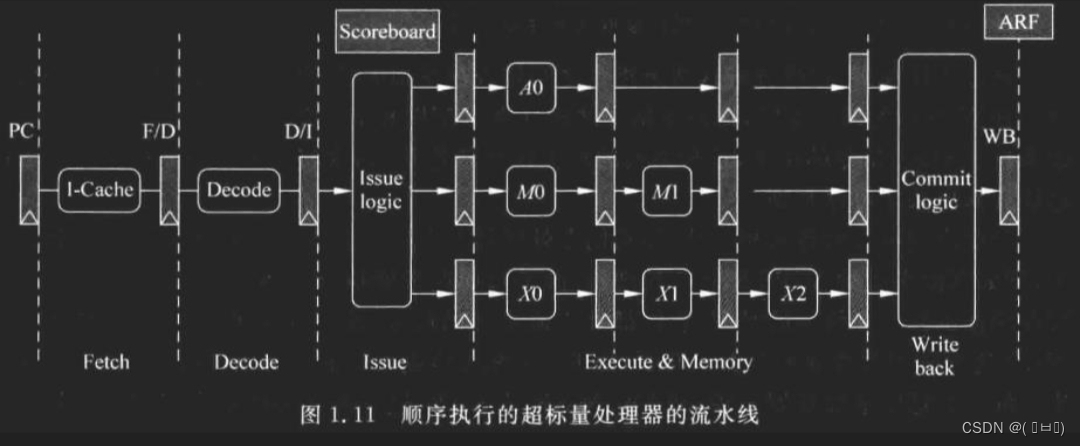
In Order顺序执行
Issue 发射
指令经过解码后,根据自身类型(操作数),送到对应的FU(Function Unit)执行
Execute 执行
三个FU,第一个执行ALU类型指令,第二个执行访问存储器类型指令,第三个执行乘法操作(耗时最长)
ScoreBoard 分数板
记录流水线中每条指令执行情况

- P(Pending):表示指令结果还没有写回逻辑寄存器
- F(Function):记录指令在哪个FU中执行,指令结果进行旁路(bypassing network)传递时会使用此信息
- Result Position:记录指令打到FU中流水段哪一个阶段,3为第一阶段,0为写回阶段
Issue 阶段,指令会写入Score Board,通过查询Score Board确定原操作数是否ready。
例如对于ALU类型指令,指令到达3阶段时,就可以对其结果进行旁路;乘法指令则需要到达1才可以旁路。
如上图,虽然可以通过旁路优化指令相互依赖的等待时间(优化等待数值写回通用寄存器的时间)。在Write Back期间执行即可。
但是像指令F(蓝色框)这种不依赖之前指令寄存器数值的情况,仍然需要等待前面指令全部issue完毕才能执行。

Out of Order 乱序执行
Register Renaming
寄存器重命名主要针对WAR,WAW场景,由于寄存器数量有限,又存在指令相互依赖问题。
需要写入的寄存器正在被另一个指令占用,则对被占用的寄存器重命名。
例如需要写入R2,但是R2正在被占用,则重命名R2‘寄存器使用。
只对覆盖写入场景有效,RAW这种需要依赖寄存器结果的场景并不适用。
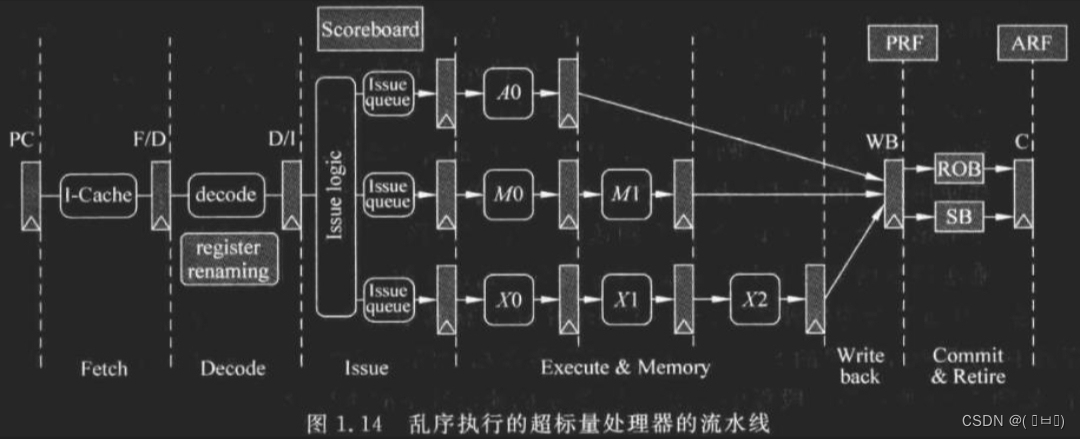
ARF Architecture Register File
指令集定义寄存器基于指令集定义的真实寄存器实现。
PRF Physical Register File
物理寄存器堆用于配合实现register renaming功能,数量大于ARF。
IQ Issue Queue
发射队列,一旦指令操作数准备完成(依赖的资源均可用),就可以离开队列,送到对应的FU执行。
这是乱序执行和顺序执行的差异分界点,发射队列的存在,让乱序执行成为可能。
WB Write Back
乱序执行的写回也是乱序的,一条指令只要执行完毕,就会把结果写入PRF。
如果分支预测失败或者异常,PRF内容未必写入ARF。
ROB Re-Order Buffer
重排序缓存用于保证乱序执行后结果的串行序列(出现异常时,也能够根据顺序反查到现场)。
流水线所有指令都必须在ROB重新排序。
一条指令只有等它前面所有的指令都离开ROB了,才允许它离开ROB退休。
SB Store Buffer
由于指令退休后无法恢复,对于store指令写在存储器的行为会存在风险。
一旦发生异常或者预测失败,则存储器内容无法恢复。
Store Buffer则用于存储store指令未退休前的结果。
Load指令寻找数据时,要同时从D-Cache和SB寻找数据。
Commit
包含ROB以及SB部分,一条指令在此阶段,会将它的结果从PRF搬到ARF。
如果不存在异常或者预测失败,在完成ARF信息搬运后,将此条指令退休retire,并且无法再恢复。
同样是2-Way的6个相同指令,对比执行顺序,乱序执行情况如下:

主要由I-Cache访问和分支预测器决定下一条PC信息。
D Decode 译码
部分RISCV指令需要特殊处理,CISC较为复杂。
I Issue 发射
对比顺序执行,乱序执行ISSUE阶段无需再等待。
由仲裁模块select挑选合适指令发送到FU。
此阶段还有唤醒电路wakeup,将发射队列中对应的源操作数置为有效。
EX 执行
乱序执行下只有RAW需要在IQ中等待,WAW和WAR都可以通过寄存器重命名执行。
或者通过旁路网络bypassing加快执行。
W write back 写回
将FU结果写到PRF,再通过旁路网络把数据送到FU输入端,由FU端口控制模块决定是否使用。
由于旁路网络比较占用布线空间,增加的连线会增加延时。
目前会把FU分为不同的组cluster,同一组内FU布线紧密。
C Commit 提交
前面的步骤都完成后进入ROB等待退休。
ROB将乱序执行的指令重排序为程序中规定的顺序。
确认之前的指令执行完毕后,开始写入ARF,完成后指令退休。