一、先说结论
parallelStream在中间处理时都是并行的(这里不展开说明并行的实现),所以parallelStream中间处理的结果都是乱序的,但是在使用了Collect收集器后,parallelStream被收集的结果默认都是按照集合的原序列进行排序的。
二、实例测试
2.1、先上代码
/**
* collect 收集时可以排序成原数组数据
*/
@Test
public void myParallelTest() {
List<Integer> testList = Lists.newArrayList(1, 91, null, 8, 100, 78, 9, 68);
testList.parallelStream()
.map(m -> {
if (Objects.isNull(m)) {
return null;
}
return m + 1;
})
.forEach(f -> System.out.print(f + " "));
System.out.println();
System.out.println("-----------------");
List<Integer> collect = testList.parallelStream()
.map(m -> {
if (Objects.isNull(m)) {
return null;
}
return m + 1;
})
.collect(Collectors.toList());
collect.forEach(f -> System.out.print(f + " "));
}
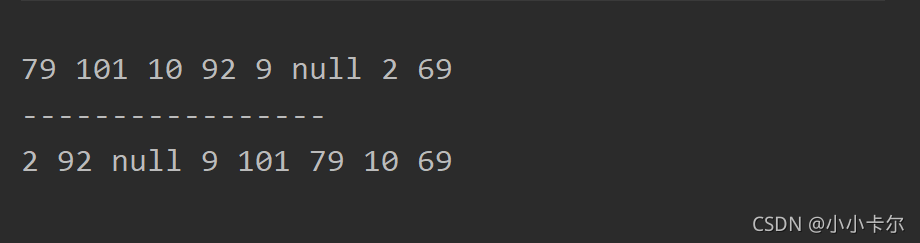
2.2、运行结果
2.3、说明
测试代码上定义一个Integer类型集合:
第一次使用parallelStream进行对集合遍历输出时发现中间处理的结果都是乱序的。
第二次使用parallelStream进行对集合经过map处理后,再通过collect进行收集,发现collect收集的结果的顺序和原集合的顺序是一样的。
这个测试结果可以证明开头结论的正确性。
三、parallelStream结果差异分析
问题其实很明朗,主导因素在collect收集器上。