👉博__主👈:米码收割机
👉技__能👈:C++/Python语言
👉公众号👈:测试开发自动化【获取源码+商业合作】
👉荣__誉👈:阿里云博客专家博主、51CTO技术博主
👉专__注👈:专注主流机器人、人工智能等相关领域的开发、测试技术。

【Python】 Q-learning 强化学习的贪吃蛇游戏(源码)【独一无二】
一、设计要求
该项目的设计要求是开发一个基于 Q-learning 强化学习的贪吃蛇游戏系统,包括环境搭建、算法实现和图形界面展示。首先,需要创建一个贪吃蛇游戏环境(SnakeEnv 类),定义游戏规则、状态空间和动作空间,并实现重置和执行动作的逻辑,确保游戏的基本运行。其次,使用 Q-learning 算法(QLearningAgent 类)来训练代理,代理需要能够根据环境状态选择合适的动作,并通过学习优化其策略。具体要求包括初始化 Q-learning 参数、状态键转换、动作选择策略和 Q 表更新。再者,利用 Tkinter 创建图形界面(SnakeGame 类),用于实时展示游戏过程,包含游戏初始化、状态更新和画布绘制等功能。图形界面需要直观展示蛇和食物的位置,用户可以通过界面观察强化学习的训练过程和效果。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 强化贪吃蛇 ” 获取,拿来即用。👈👈👈
二、效果展示
自动寻找食物,可以自动躲避撞墙。
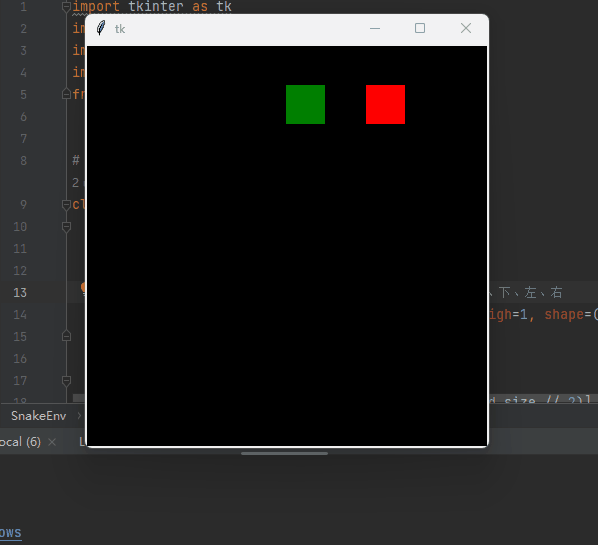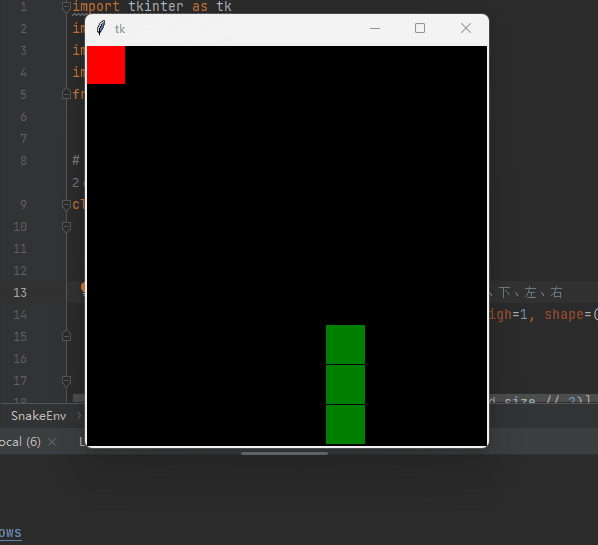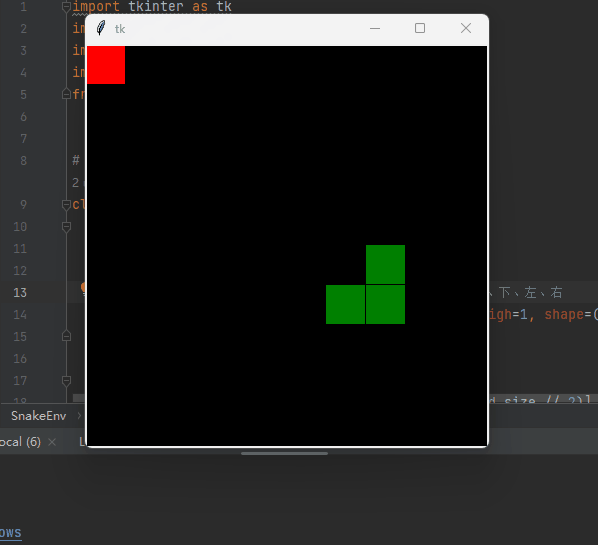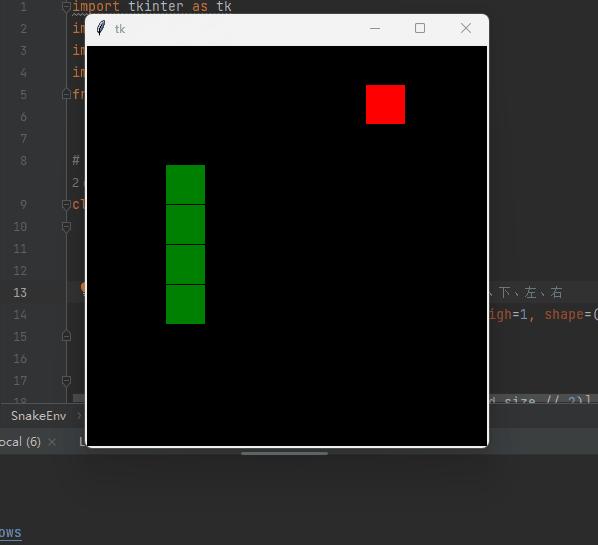
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 强化贪吃蛇 ” 获取,拿来即用。👈👈👈
三、设计思路
代码实现了一个使用强化学习(Q-learning)算法来玩贪吃蛇游戏的环境,并使用 Tkinter 创建一个图形界面来展示游戏过程。代码主要分为三个模块:贪吃蛇环境、Q-learning 算法代理和游戏窗口。
1. 贪吃蛇环境模块(SnakeEnv 类)
功能:创建一个贪吃蛇游戏环境,定义游戏的规则、状态空间、动作空间,以及重置和执行动作的方法。
主要方法:
__init__:初始化环境,包括网格大小、动作空间和状态空间。reset:重置环境,初始化蛇的位置、方向、食物位置等,返回初始观察值。step:执行一个动作,更新蛇的位置和状态,计算奖励,判断游戏是否结束,返回新的观察值、奖励、游戏是否结束的标志和额外信息。_get_obs:生成当前环境的观察值,包括蛇和食物的位置。_place_food:在随机位置生成食物,确保食物不会出现在蛇的位置上。_get_safe_direction:在撞墙的情况下,选择一个安全的方向来移动蛇。
代码示例:
class SnakeEnv(gym.Env):
def __init__(self, grid_size=10):
super(SnakeEnv, self).__init__()
self.grid_size = grid_size
self.action_space = spaces.Discrete(4) # 上、下、左、右
self.observation_space = spaces.Box(low=0, high=1, shape=(grid_size, grid_size, 3), dtype=np.float32)
self.reset()
# 代码略(至少十行)...
# 代码略(至少十行)...
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 强化贪吃蛇 ” 获取,拿来即用。👈👈👈
2. Q-learning 算法代理模块(QLearningAgent 类)
功能:实现 Q-learning 算法,用于学习和决策贪吃蛇的动作选择。
主要方法:
__init__:初始化 Q-learning 参数,包括学习率、折扣因子、探索率和 Q 表。get_state_key:将环境的观察值转换为一个状态键,用于在 Q 表中存储和查找。choose_action:根据 epsilon-greedy 策略选择一个动作。learn:根据 Q-learning 更新规则,更新 Q 表中的值。
代码示例:
class QLearningAgent:
def __init__(self, state_space, action_space, lr=0.1, gamma=0.99, epsilon=0.1):
self.state_space = state_space
self.action_space = action_space
self.lr = lr
self.gamma = gamma
self.epsilon = epsilon
self.q_table = {}
def get_state_key(self, state):
return tuple(map(int, state.flatten()))
# 代码略(至少十行)...
# 代码略(至少十行)...
3. 游戏窗口模块(SnakeGame 类)
功能:使用 Tkinter 创建一个图形界面来展示贪吃蛇游戏的过程,并与环境和 Q-learning 代理进行交互。
主要方法:
__init__:初始化 Tkinter 窗口和画布,设置游戏的初始状态。reset:重置游戏状态,开始新的游戏循环。step:执行一个游戏步骤,包括选择动作、更新状态和学习。update_canvas:更新 Tkinter 画布,显示当前的游戏状态。
代码示例:
class SnakeGame:
def __init__(self, root, env, agent):
self.root = root
self.env = env
self.agent = agent
self.canvas = tk.Canvas(root, width=400, height=400, bg='black')
self.canvas.pack()
self.reset()
def reset(self):
self.state = self.env.reset()
self.update_canvas()
self.done = False
self.root.after(100, self.step)
# 代码略(至少十行)...
# 代码略(至少十行)...
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 强化贪吃蛇 ” 获取,拿来即用。👈👈👈
程序启动
创建环境和代理,初始化 Tkinter 窗口并启动游戏。
if __name__ == "__main__":
env = SnakeEnv(grid_size=10)
agent = QLearningAgent(state_space=env.observation_space, action_space=env.action_space)
root = tk.Tk()
game = SnakeGame(root, env, agent)
root.mainloop()
总结
- 贪吃蛇环境模块:定义了游戏规则、状态空间、动作空间,并实现了环境的重置和步进逻辑。
- Q-learning 算法代理模块:实现了 Q-learning 算法,用于学习和决策游戏中的动作选择。
- 游戏窗口模块:使用 Tkinter 创建图形界面展示游戏过程,并与环境和 Q-learning 代理进行交互。
该设计使得贪吃蛇游戏能够通过强化学习算法进行自动训练,并通过图形界面展示训练过程。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 强化贪吃蛇 ” 获取,拿来即用。👈👈👈