文章目录
概念
1、DB:database 数据库。
2、DBMS:Database Management System 数据库管理系统:用来管理数据库的计算机系统。
3、RDB:Relational Database 关系数据库:采用行列组成的二维表管理数据,使用专门的SQL对数据进行操作。这种类型的DBMS称为RDBMS。
4、字段:表的列;记录:表的行。关系数据库必须以行为单位进行数据读写。
5、DDL:创建/删除库表(e.g. CREATE/DROP/ALTER);DML:查询/变更记录(e.g. SELECT/INSERT/UPDATE/DELETE);DCL:确认/取消变更、设定权限(COMMIT/ROLLBACK/GRANT/REVOKE)
6、事务是需要在同一个处理单元中执行的一系列更新处理的集合
7、标量子查询:只返回一行一列的结果的查询,标量子查询的返回值可以用在>/</=
8、谓词:返回值是真值(TRUE/FALSE/UNKNOWN)的函数:LIKE/BETWEEN/IS NULL/IS NOT NULL/IN/EXISTS
法则
1、不能用全角空格作为单词的分隔符;
2、插入空行会造成执行错误
e.g.
SELECT *
FROM Product;
//wrong
3、SQL中有真值、假值,还有不确定值
e.g.
SELECT ... WHERE purchase_price=20;
SELECT ... WHERE NOT purchase_price=20;
上述两种语句中,purchase_price是NULL的都不会被选出来。也就是说,“NULL=20”这个判断,既不为真,也不为假,是个不确定值。只有SQL中的逻辑运算被称为三值运算。
语法
对表进行修改
//创建数据库
CREATE DATABASE SHOP;
//创建表
CREATE TABLE Product
(product_id CHAR(4) NOT NULL,
PRODUCT_TYPE VARCHAR(4) NOT NULL,
PRIMARY KEY (product_id));
//CHAR:定长字符串,使用半角空格补充到最大长度。VARCHAR:可变长字符串。
//删除表
DROP TABLE product;
//往表里添加列
ALTER TABLE Product ADD COLUMN product_name_pinyin VARCHAR(100);
//sqlserver不写COLUMN
//从表里删除列
ALTER TABLE Product DROP COLUMN product_name_pinyin;
//插入数据
INSERT INTO Product VALUES('0001','T-SIHRT');
//修改表名
//sqlserver
sp_rename 'Poduct','Product';
//mysql
RENAME TABLE Poduct to Product;
SELECT基础
SELECT product_id AS id,
product_name AS name,
product_price AS "进货单价"
From Product;
//别名用中文的时候要用双引号括起来
//去除重复行
SELECT DISTINCT product_type,regist_date FROM Product;
//DISTINCT只能用在第一个列名之前
SELECT (100+200)*3 AS calculation;
//1、可以使用运算符;2、from不是必不可少的(但并不所有的RDBMS都使用)
SELECT product_name FROM Product WHERE sale_price <> 500;
//最好不要使用!=,这个不是标准sql
SELECT product_name FROM Product WHERE sale_price-purchase_price>=500;
//WHERE子句的条件表达式也可以使用计算表达式
聚合查询
普通聚合
SELECT COUNT(*) FROM Product;//为NULL的也会选出来
SELECT COUNT(purchase_price) FROM Product;//只会选出这一列不为NULL的非空行
SELECT COUNT(DISTINCT purchase_price) FROM Product;//删除重复值
SELECT SUM(sale_price) FROM Product;//数值
SELECT SUM(DISTINCT sale_price) FROM Product;
SELECT AVG(sale_price) FROM Product;//数值
SELECT MAX(sale_price),MIN(purchase_price) FROM Product;//任何数据类型都可以用
分组查询
SELECT purchase_price,COUNT(*)
FROM Product
WHERE product_type = 'cloth'
GROUP BY purchase_price;
//GROUP BY如果有NULL值,也会把NULL值作为一组特定的数据,会以空行的形式输出
//先按WHERE语句过滤再输出
tips:
1、使用聚合函数+GROUP BY的时候,SELECT后面只能跟①常数②聚合函数③GROUP BY子句中指定的列名
2、执行顺序 FROM->WHERE->GROUP BY->SELECT,所以GROUP BY后面不能跟别名
3、WHERE后面不能跟聚合函数,要使用HAVING
SELECT product_type,COUNT(*)
FROM Product
GROUP BY product_type
Having count(*)=2;
tips:having子句中可以使用的元素①常数②聚合函数③GROUP BY子句指定的列名
WHERE是先筛选,后处理数据,HAVING是先处理数据后筛选,所以能写在WHERE后面的就就要写在WHERE后面。(“行对应的条件写在WHERE子句中,“组”对应的条件写在HAVING子句中”)
ORDER BY
1、执行顺序:group by->select->order by,所以order by中可以使用select中有写的别名
2、ORDER BY子句中可以使用SELECT子句中未使用的列和聚合函数
INSERT INTO
1、在括号中用列名字和逗号分隔开来这种方式叫清单
INSERT INTO(‘’,‘’,‘’)
2、可以插入默认值
法1:显示方式插入
INSERT INTO ProductIns(product_id,product_name,prchase_price) VALUES ( '0007','board',DEFAULT)
--CREATE ProductIns(product_id CHAR(4),
...
-- purchase_price INTEGER DEFAULT 0,
-- ...
)
法2:隐式方式插入
在列清单和VALUES中省略设定了默认值的列就可以,如果没有设定默认值,就会是NULL,如果设定了NOT NULL,就会出错。
3、复制行
INSERT INTO ProductType(product_type,sum_price) SELECT product_type,SUM(sale_price) FROM Product GROUP BY product_type;
SELECT后面可以用WHERE,GROUP BY等任何sql语法,不过使用ORDER BY 不会产生任何效果
DELETE
delete from TABLE<> where
注意只能用where,不能用group by之类的,因为delete from删除的是记录而不是字段,所以也不能写delete某一列
UPDATE
UPDATE Product SET sale_price=sale_price*10 WHERE product_type='c';
SET子句中赋值表达式的右边可以是包含列的表达式
多列更新:
UPDATE Product
SET sale_price=sale_price * 10,
purchase_price=purchase_price * 2
WHERE product_type='c'
事务
一个事务中包含多少个更新处理,或者包含哪些处理,都是根据用户要求决定的。如果想在DBMS中创建事务,可以按照如下语法结构编写SQL语句:
事务开始语句;(BEGIN TRANSACTION;)
DML语句1;(UPDATE ... SET...WHERE...;)
DML语句2;(UPDATE...SET...WHERE...;)
……
事务结束语句;(COMMIT;)
事务结束语句:
COMMIT:一旦提交不能回到事务开始前的状态,必须重新建表处理表
ROLLBACK:回滚,回滚到事务结束前的状态
事务特性:ACID
原子性(Atomicity):要么全部执行要么全部不执行
一致性(Consistency):DDL要满足数据库提前设置的约束
隔离性(Isolation):事务之间互不干扰
持久性(Durability)事务结束后,DBMS能保证该时间点的数据状态会被保存
视图
视图和表的区别:视图可以被作为表读取,但是并未保存实际数据
优点①:节省存储设备的容量
优点②:随原表自动更新,不需要每次重新书写SELECT
CREATE VIEW ProductSum(product_type,cnt_product)
AS
SELECT product_type,count(*)
FROM product
GROUP BY product_type;
注意,应该尽量避免在视图的基础上创建视图,不然会降低SQL的性能
视图的限制
①不能使用ORDER BY
②对视图直接更新存在限制,视图和表要同时更新,不是通过汇总得到的视图就可以进行更新(SELECT子句中未使用DISTINCT,FROM中只有一张表,未使用group by,未使用having)
子查询
标量子查询
--------wrong!!!!!!-----
SELECT product_id FROM Product WHERE sale_price>AVG(sale_price);
因为where中不能有聚合函数,所以这个语句是错误的,此时应该改成标量子查询:
SELECT product_id FROM Product WHERE sale_price>(SELECT AVG(sale_price) FROM Product);
SELECT product_type,AVG(sale_price)
FROM Product
GROUP BY product_type
HAVING AVG(sale_price)>(SELECT AVG(sale_price) FROM Product);
关联子查询
SELECT product_id FROM Product AS P1
WHERE sale_price>(
SELECT AVG(sale_price) FROM Product AS P2
WHERE p1.product_type=p2.product_type
GROUP BY product_type);
这个WHERE语句的意思是,在同一商品种类中对商品的销售单价和平均单价进行比较。在细分的组内进行比较的时候,需要用到关联子查询。由于关联子查询实际只能返回1行结果,这就是关联子查询不出错的关键
函数
算数函数
绝对值:ABS()
求余数:MOD()
四舍五入:ROUND(对象数值,保留小数的位数)
字符串函数
拼接:CONCAT(STR1,STR2,STR3)
计算长度:LENGTH() / LEN()
小写转换:LOWEWR() / 大写转换:UPPER()
字符串替换:REPLACE(对象字符串,替换前的字符串,替换后的字符串)
字符串截取:SUBSTRIN(对象字符串 FROM 截取的起始位置 FOR 截取的字符数) ----- *sqlserver:SUBSTRING(对象字符串,截取的起始位置,截取的字符数)
日期函数
日期截取:
EXTRACT(mysql)、DATEPART(sqlserver)
EXTRACT(YEAR FROM CURRENT_TIMESTAMP) AS Year 同理可得月日时
DATEPART(YEAR , CURRENT_TIMESTAMP) AS Year
转换函数:
CAST(转换前的值 AS 转换后的数据类型)
空值处理:COALESCE()
主流数据库系统都支持COALESCE()函数,这个函数主要用来进行空值处理,其参数格式如下:
COALESCE ( expression,value1,value2……,valuen)
COALESCE()函数的第一个参数expression为待检测的表达式,而其后的参数个数不定。
COALESCE()函数将会返回包括expression在内的所有参数中的第一个非空表达式。
如果expression不为空值则返回expression;否则判断value1是否是空值,
如果value1不为空值则返回value1;否则判断value2是否是空值,
如果value2不为空值则返回value2;……以此类推,
如果所有的表达式都为空值,则返回NULL。
谓词
LIKE:
LIKE ‘%D’ :在D前面有0个字符以上的任意字符串
LIKE ‘_D’ : _代表任意一个字符
BETWEEN:范围查询,会包含临界值,如果不要临界值必须使用< AND >
IS NULL/IS NOT NULL:选NULL值不能用=,而要用谓词IS NULL
IN:
IN/NOT IN具有其他谓词都没有的用法,那就是可以用子查询作为参数。也就是说能够将视图/表作为IN的参数。
SELECT product_name
FROM Product
WHERE purchase_price IN (320,550,500);-- 等于三个or并列
SELECT product_name
FROM Product
WHERE purchase_price NOT IN (320,550,500); -- 不在这里面的才选出来
SELECT product_name
FROM Product
WHERE product_id IN (SELECT product_id FROM ShoProduct WHERE shop_id='000C');
EXIST:
1、首先查询select * from table_name的结果
2、将外查询的结果按行代入到子查询,看子查询有没有结果。
3、子查询有结果,exists返回true,not exists返回false;子查询无结果,exists返回false,not exists返回true。
4、返回true则将代入行显示出来,返回false则将带入行隐藏(不显示)。
5、当外查询的结果按行全部代入到子查询中,得到的新的查询结果即该语句的查询结果。
CASE
CASE WHEN <求值表达式> THEN <表达式>
WHEN <求值表达式> THEN <表达式>
...
ELSE <表达式>
END
求值表达式:返回真值的表达式,所以可以看做是谓词编写出来的表达式
集合运算
表的加减法
集合:记录的集合
表的加法:UNION
①UNION会去除重复的记录
②作为运算对象的记录的列数必须相同
③作为运算对象的记录中的列的类型必须一致
④可以使用SELECT语句,但ORDER BY子句只能在最后使用一次
SELECT...FROM
UNION
SELECT...FROM..
ORDER BY...
包含重复行的集合运算:UNION ALL
选取表中公共部分:INTERSECT(选取交集)
SELECT..FROM..
INTERSECT
SELECT..FROM..
ORDER BY...
记录的减法:EXCEPT
是去除表2中记录之后剩余的部分
SELECT..FROM..
EXCEPT
SELECT..FROM..ORDER BY...
联结
内联结
内联结:以A中的列作为桥梁,将B中满足同样条件的列汇集到同一结果之中。进行内联结必须使用ON子句。可以将联结之后的结果想象为一张新的表,对这张表可以使用WHERE/GROUP BY/HAVING/ORDER BY。
外联结:内联结只能选出同时存在两张表中的数据,而对于外联结来说,只要数据存在某一张表中就能够读取出来。外联结中还有一点非常重要,就是把哪张表作为主表,最终的结果包含主表中的所有数据。指定主表的关键字是LEFT和RIGHT。使用LEFT的时候,左边的表是主表,使用RIGHT的时候右边的表是主表。
交叉联结:CROSS JOIN,将全部的记录进行交叉结合,记录数是两张表行数的乘积。
窗口函数
<窗口函数> OVER ([PARTITION BY <列清单>] order by <排序用列清单> )
窗口函数分为以下两种:
①能够作为窗口函数的聚合函数(SUM/AVG/COUNT/MAX/MIN)
②RANK/DENSE_RANK/ROW_NUMBER等专用窗口函数
RANK/DENSE_RANK/ROW_NUMBER
SELECT product_name,product_type,sale_price
RANK() OVER (PARTITION BY product_type ORDER BY sale_price) AS ranking
FROM Product;
PARTITION BY能够设定排序的对象范围,而ORDER BY指定按照哪一列排序。PARTITION BY在横向上进行分组而ORDER BY决定了纵向的排序规则。
用PARTITION BY分组后的集合成为窗口,这里的窗口代表范围,这就是窗口函数名称的由来。
※具有代表性的专用窗口函数
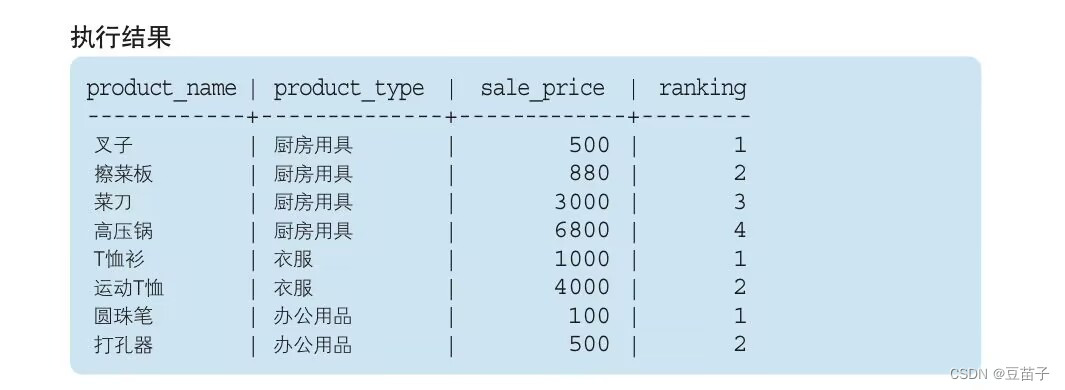
- RANK函数
计算排序时,如果存在相同位次的记录,则会跳过之后的位次:1、1、1、4… - DENSE_RANK
同样是计算排序,即使存在相同位次的记录也不会跳过之后的位次:1、1、1、2… - ROW_NUMBER函数
赋予唯一的连续位次,要对比的列相同的时候,会根据适当的顺序进行排列:1、2、3、4…
tips:窗口函数只能使用在SELECT子句之中
使用聚合函数作为窗口函数
- SUM
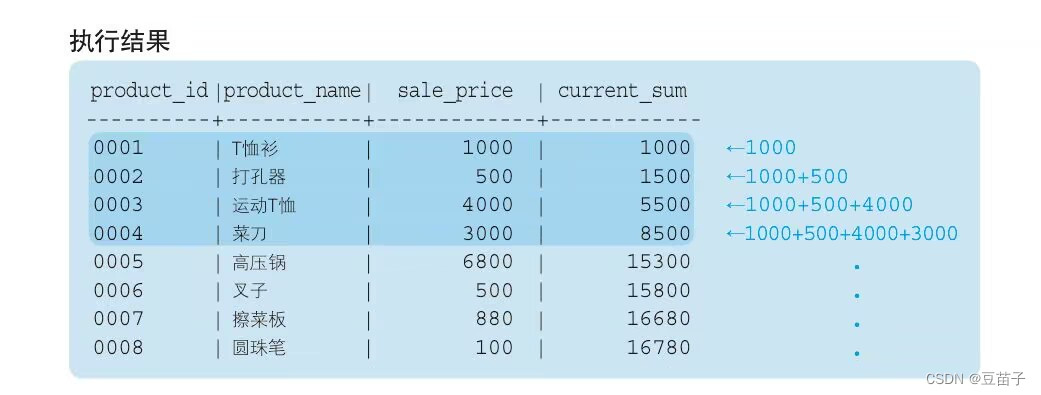
SELECT product_id,product_name,sale_price,
SUM(sale_price) OVER (ORDER BY product_id) AS current_sum
FROM Product;
聚合的逻辑像金字塔堆积那样,一行一行逐渐添加计算对象。是一种累计的统计方法。统计的对象是“排在自己之上的记录”。
- AVG
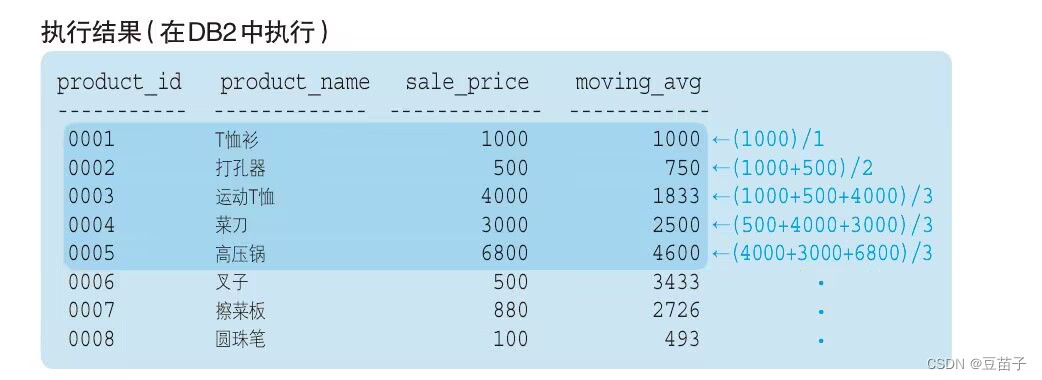
SELECT product_id,product_name,sale_price,
AVG(sale_price) OVER ( ORDER BY product_id ROWS 2 PRECEDING) AS moving_avg
FROM Product
使用ROWS(行) 和 PRECEDING(之前) / FOLLOWING(之后)限制框架为截止到之前~行
将当前记录前后作为汇总对象
SELECT product_id,product_name,sale_price,
AVG(sale_price) OVER (ORDER BY product_id ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS moving
FROM Product
要注意的是,窗口中的ORDER BY对结果的排序没有任何影响,因此如果要对结果排序,还要再SELECT的语句再用一次ORDER BY。
grouping运算符
ROLLUP
一次计算出不同聚合键组合的结果
SELECT prodcuct_type,SUM(sale_price) AS sum_price
FROM Product
GROUP BY ROLLUP(product_type)
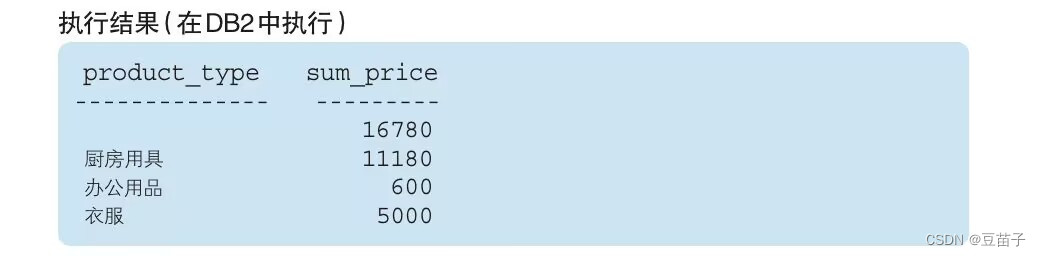
一次计算出了两种聚合的结果:①GROUP BY() ②GROUP BY(product_type)
①中的GROUP BY()默认NULL为聚合键
SELECT product_type,regist_date,SUM(sale_price) AS sum_price
FROM Product
GROUP BY ROLLUP(product_type,regist_date)
该SELECT语句的结果相当于使用UNION对如下三种模式的聚合级的不同结果进行连接
①GROUP BY()
②GROUP BY(product_type)
③GROUP BY(product_type,regist_date)
※※※ 如何判断regist_date为NULL值的时候,sum_price是小计合计还是真的是NULL呢
※※※ 使用GROUPING函数
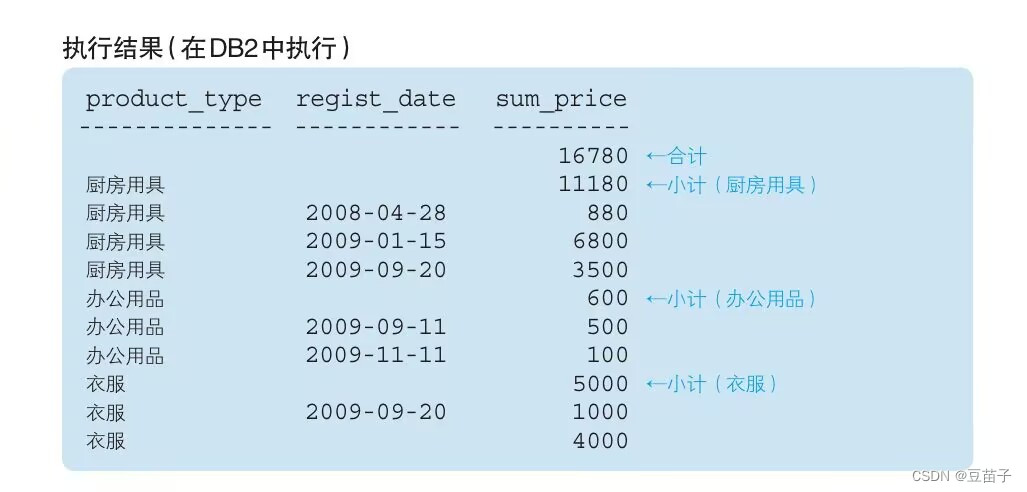
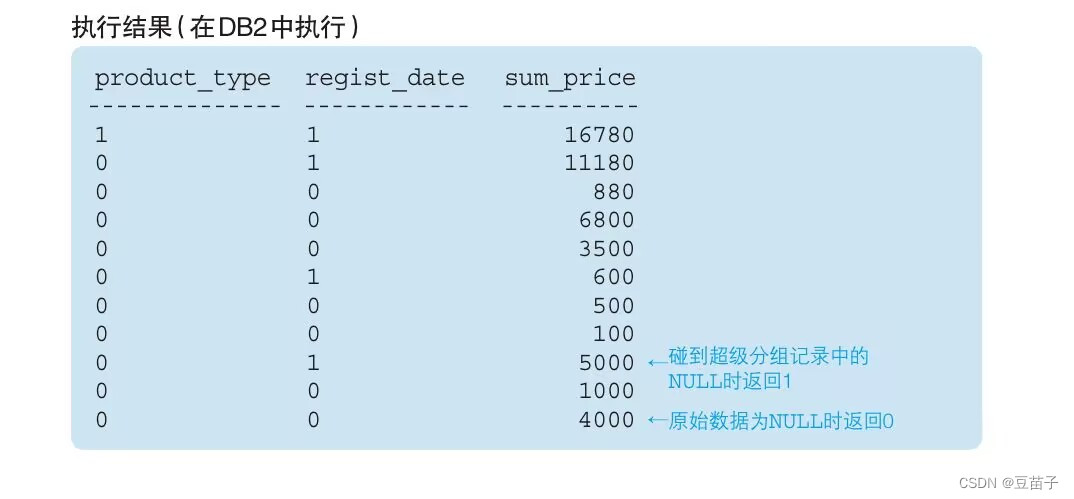
SELECT GROUPING(product_type) AS product_type,
GROUPING(regist_date) AS regist_date,
SUM(sale_price) AS sum_price
FROM product
GROUP BY ROLLUP(product_type,regist_date)
GROUPING函数在其参数列的值为超级分组记录所产生的NULL时返回1,其他情况返回0
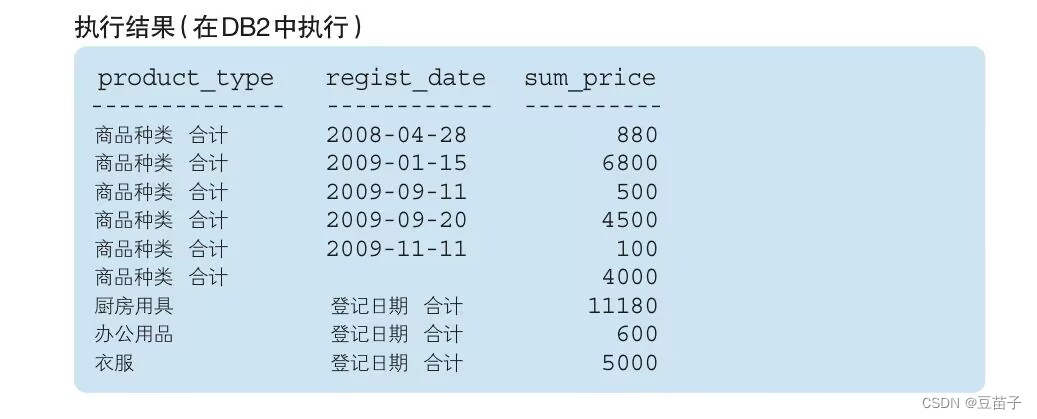
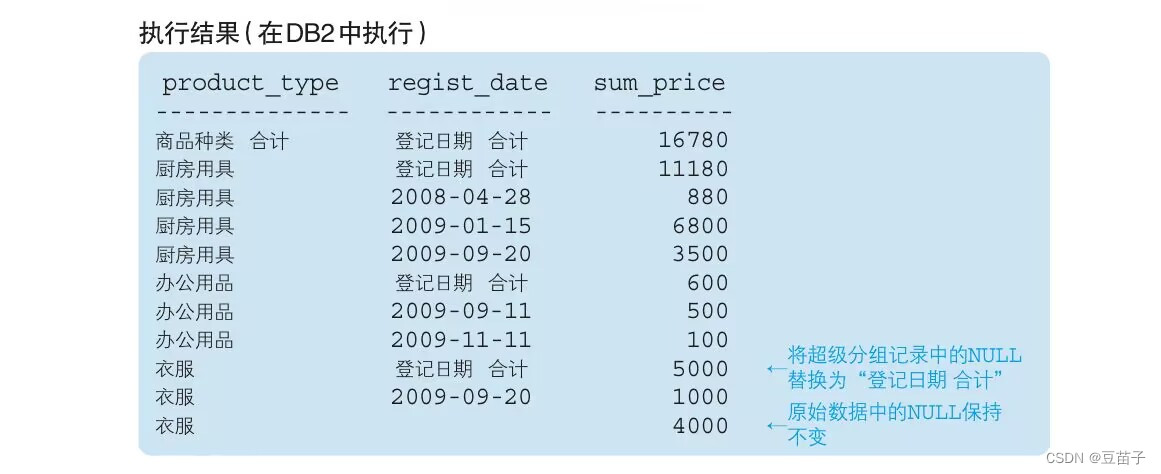
SELECT CASE WHEN GROUPING(product_type) = 1
THEN '商品种类合计'
ELSE product_type END AS product_type,
CASE WHEN GROUPING(regist_date) = 1
THEN '登记日期合计'
ELSE CAST(regist_date AS VARCHAR(16)) END AS regist_date,
SUM(sale_price) AS sum_price
FROM product
GROUP BY ROLLUP(product_type,regist_date)
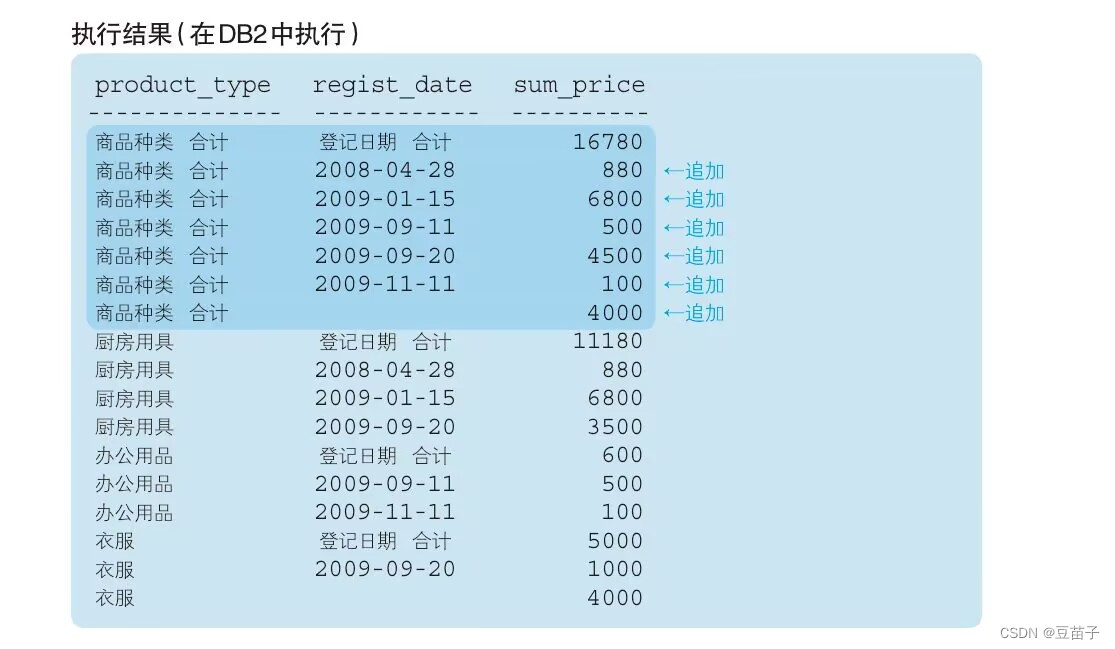
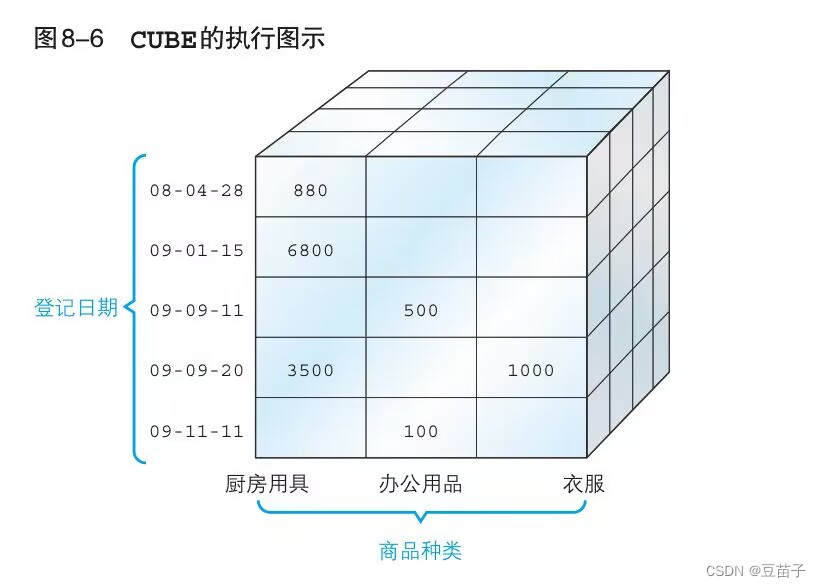
CUBE
SELECT CASE WHEN GROUPING(product_type) = 1
THEN '商品种类合计'
ELSE product_type END AS product_type,
CASE WHEN GROUPING(regist_date) = 1
THEN '登记日期合计'
ELSE CAST(regist_date AS VARCHAR(16)) END AS regist_date,
SUM(sale_price) AS sum_price
FROM product
GROUP BY CUBE(product_type,regist_date)
把ROLLUP改成CUBE,会多出只把regist_date作为聚合键所得到的汇总结果
①GROUP BY
②GROUP BY (product_type)
③GROUP BY (regist_date)
④GROUP BY (product_type,regist_date)
GROUPING SETS
如果希望从中选出将“商品种类”和“登记日期”各自作为聚合键的结果,或者不想得到“合计记录和使用两个聚合建的记录”时,可以使用GROUPING SETS
SELECT CASE WHEN GROUPING(product_type) = 1
THEN '商品种类合计'
ELSE product_type END AS product_type,
CASE WHEN GROUPING(regist_date) = 1
THEN '登记日期合计'
ELSE CAST(regist_date AS VARCHAR(16)) END AS regist_date,
SUM(sale_price) AS sum_price
FROM product
GROUP BY GROUPING SETS(product_type,regist_date)