- 这是Radu大佬所在的Würzburg大学的computer vision lab实验室发表在ECCV2024上的一篇论文,代码开源。
- 文章提出了一种文本引导的All-in-One的restoration模型,如下图所示:
- 这个工作其实跟"InstructPix2Pix: Learning to Follow Image Editing Instructions"这个工作很像,下面是instructPix2Pix的流程,其核心思想是利用GPT-3,stable diffusion和prompt2prompt这三个方法,生成图像编辑数据集,用来train一个stable diffusion model,实现文本引导图像编辑
- 而下面是instructIR的流程,backbone的模型用的是NAFNet。首先用GPT4先生成一堆prompt,并手动筛除掉一些低质量的prompt,这些prompt都是带有degradation type的标注的(可能是生成的时候就带有标注,并手动修正了),最终产生用于训练的1w个带分类标注的prompt。然后用一个纯NLP的sentence text encoder(而非常见的CLIP text encoder)来对句子提取文本编码。这个text encoder是在NLP任务上pretrain好后fix住的,文章说finetue这个text encoder效果不好,所以直接fix住,在其输出上再接一层MLP,只train这个MLP,MLP的输出e即是直接用到instructIR的文本embedding
e
e
e。
- 在训练的时候,会增加一个分类loss,把 e e e送进一个分类头,输出degradation type的分类结果,并计算分类损失。
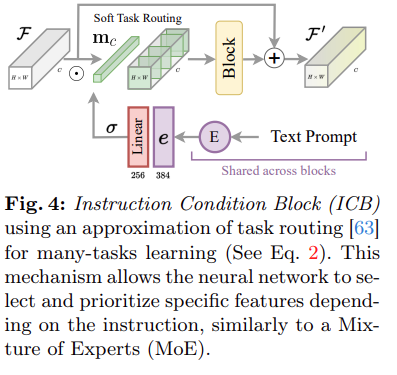
- NAFNet本来是没有文本进去的,所以要改一下,其实就是加了个通道的加权,把这个文本的embedding,送进MLP+sigmoid,得到的1维向量用来对特征进行通道乘法,然后加了个block进一步处理,再加个残差,这就是往NAFNet的encoder和decoder的各个layer中添加的ICB:
- 训练的时候,是在多种degradation的数据集的混合数据集上train的,包括BSD400,LOL等,然后每个sample是已知degradation(不过强度是多种的,比如denoise就有3种sigma,所以文章专门说自己是blind restoration因为只知道type不知道强度),所以从预先生成的对应degradation的prompt库中随机抽一个prompt。
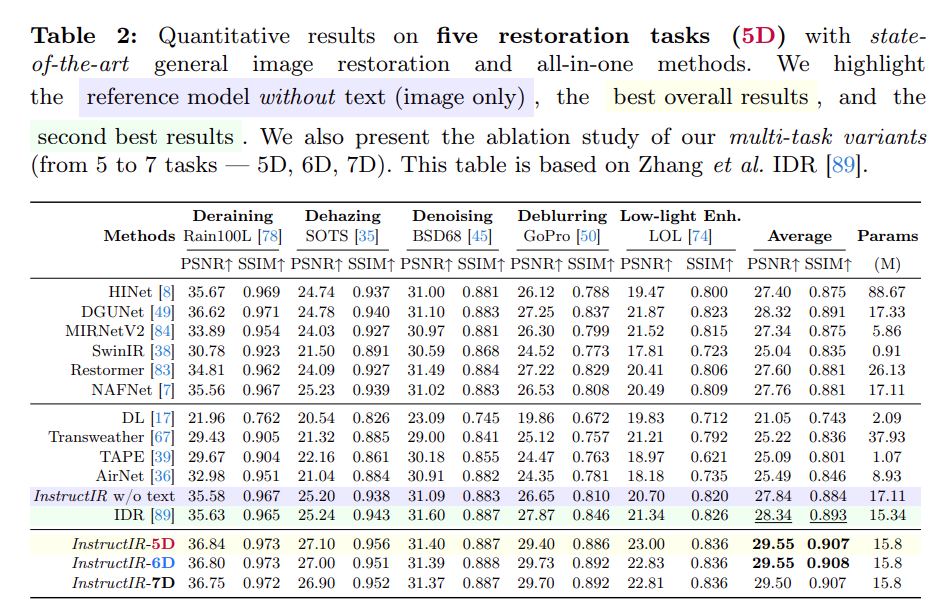
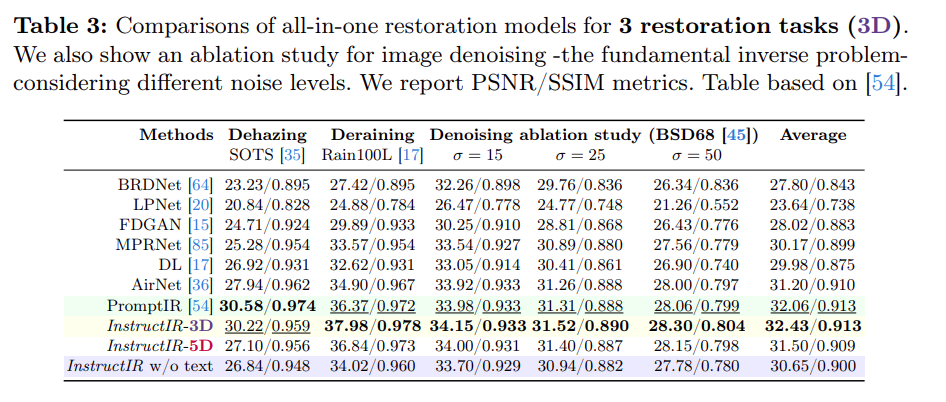
- 实验结果看起来不错:
- 这里的w/o text就是消融实验,把文本的部分拆掉重新train一个模型出来,可以看到效果是很差的,说明文本确实起作用。