@TOC
预备知识
selenium库
selenium库是一个用来模拟人们的一般上网操作来进行网络数据爬取的Python库,他模拟人们上网时所进行的大部分操作,比如说点击按钮、输入文字等操作。
在爬取微信公众号的过程中,我们会使用到以下操作:
- 点击按钮
# 使用xpath语法定位我们需要点击的按钮
button = driver.find_element_by_xpath('//*[@id="js_editor_insertlink"]')
# 执行单击操作
button.click()
- 悬停鼠标
# 定位新的标签
collect = driver.find_element_by_xpath('//*[@id="js_main"]/div[3]/div[2]/div/div/div/div[2]/div/div/div[1]')
# 悬停至收藏标签处
ActionChains(driver).move_to_element(collect).perform()
- 切换窗口
# 切换窗口
driver.switch_to.window(driver.window_handles[-1])
- 输入文字
# 定位搜索输入框
text_label = driver.find_element_by_xpath('//*[@id="vue_app"]/div[2]/div[1]/div/div[2]/div[2]/form[1]/div[4]/div/div/div/div/div[1]/span/input')
# 在搜索框中输入搜索内容
text_label.send_keys('丁香园')
仅仅需要学会以上的操作就可以进行微信公众号文章的爬取了,是不是特别简单!
爬取过程
由于selenium库是通过模拟人们的上网操作来进行爬取数据,我们需要知道人们正常的获取数据的过程,再让selenium库去模拟。想要获取某一个微信公众号的所有文章,就需要知道如何一步步跳转到包含某一公众号所有文章链接的页面。
- 注册登录微信公众号平台 (https://mp.weixin.qq.com/)
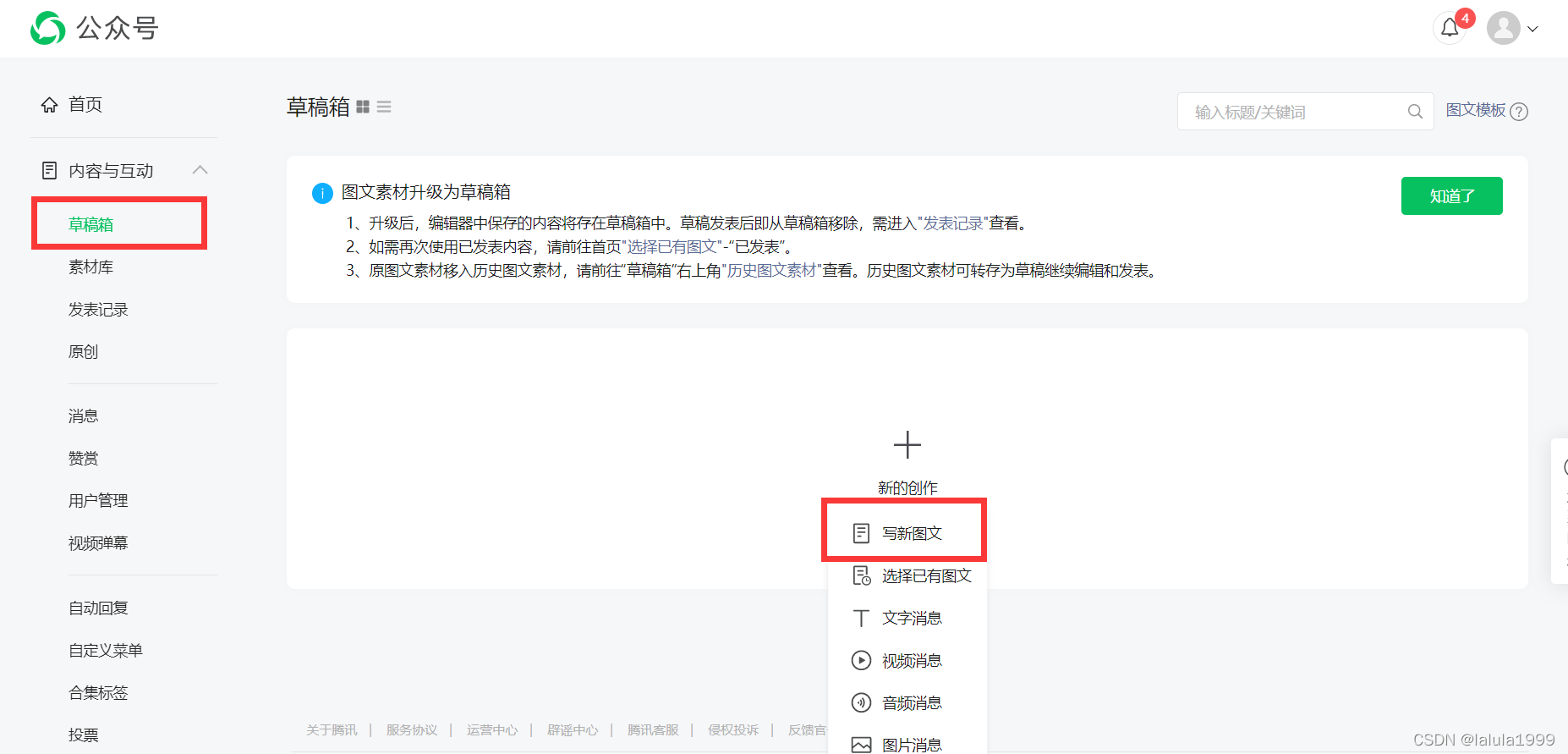
- 新建公众号文章
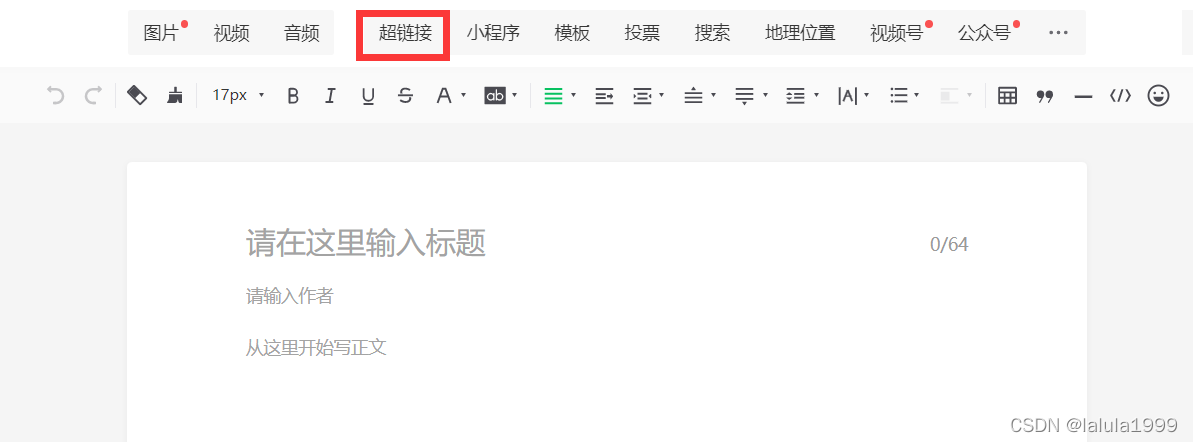
- 点击超链接
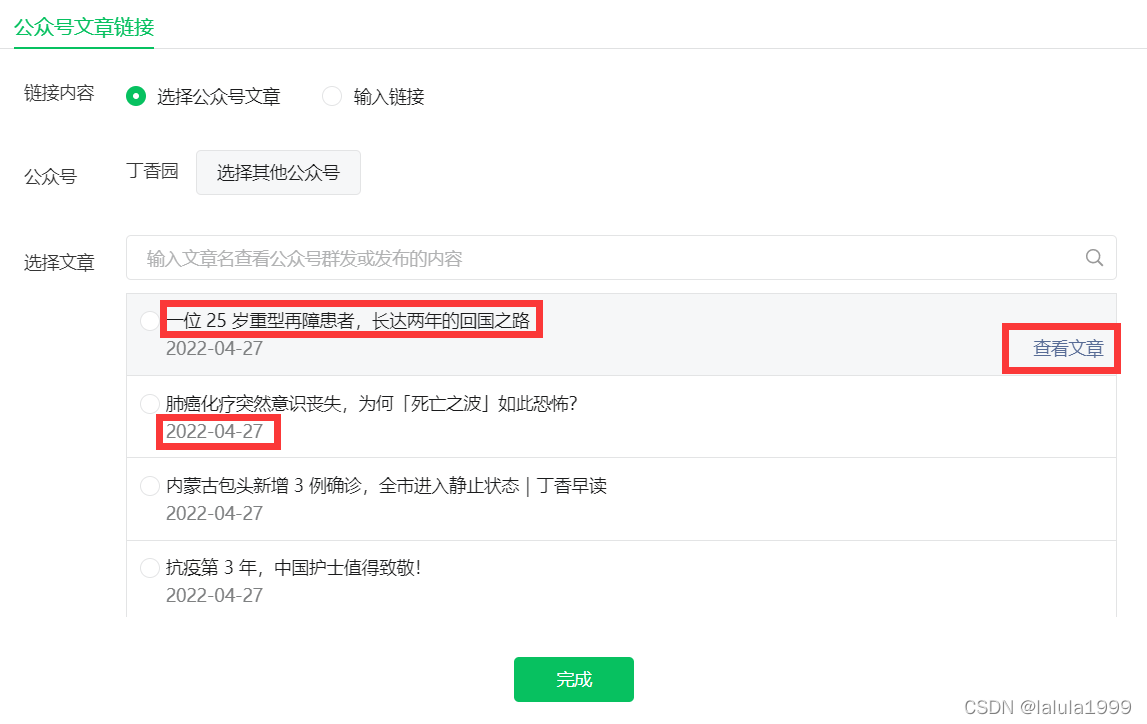
- 选择其他公众号并搜索你想要爬取的公众号名称
我们便可以获取我们想要爬取公众号的所有文章的文章标题、发布时间和文章链接。
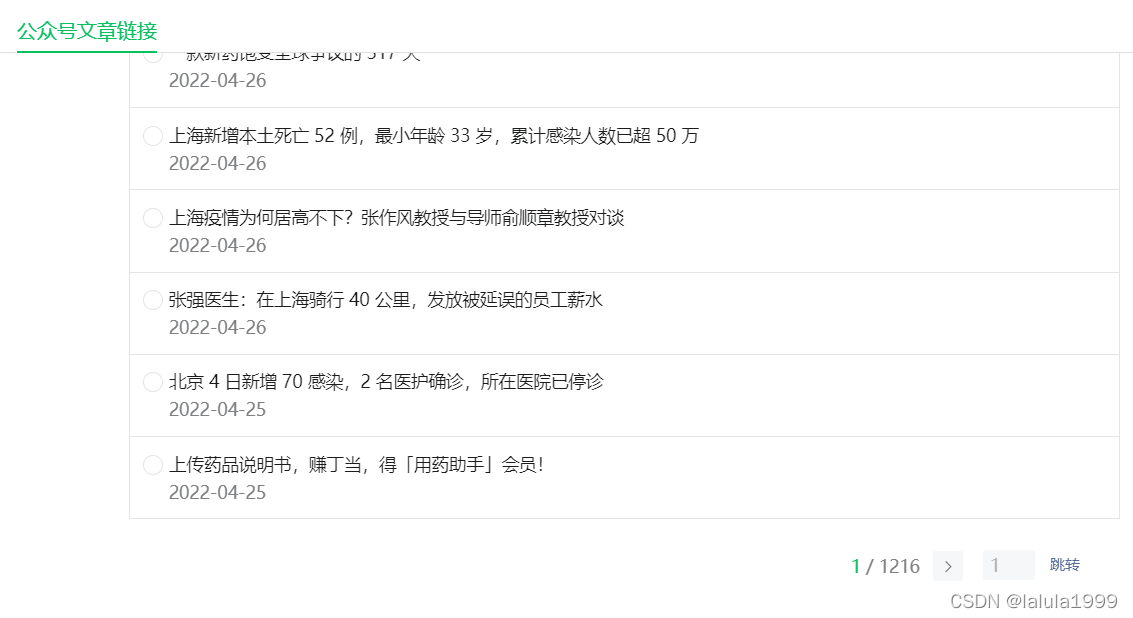
实战代码
0.引入所需要的库
import xlwt
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.action_chains import ActionChains
1.登录微信公众号平台
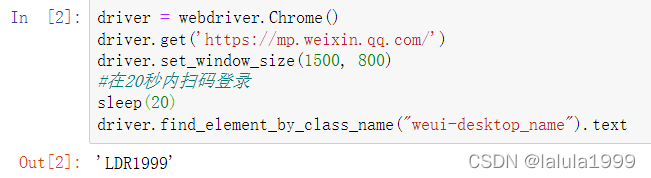
由于微信对于用户信息的安全保护,在selenium库模拟登录微信公众号号时需要扫码登录,本文并没有实现对二维码登录的破解,所以需要手动扫码登录网站。
driver = webdriver.Chrome()
driver.get('https://mp.weixin.qq.com/')
driver.set_window_size(1500, 800)
#在20秒内扫码登录
sleep(20)
driver.find_element_by_class_name("weui-desktop_name").text
如果登录成功,该代码会返回你的登录名。
2.新建公众号文章
# 定位草稿箱按钮
button = driver.find_element_by_xpath('//*[@id="js_level2_title"]/li[1]/ul/li[1]/a/span/span')
# 执行单击操作
button.click()
sleep(2)
# 定位新的创作
collect = driver.find_element_by_xpath('//*[@id="js_main"]/div[3]/div[2]/div/div/div/div[2]/div/div/div[1]')
# 悬停至收藏标签处
ActionChains(driver).move_to_element(collect).perform()
sleep(2)
#定位新建公众号
button = driver.find_element_by_xpath('//*[@id="js_main"]/div[3]/div[2]/div/div/div/div[2]/div/div/div[2]/ul/li[1]')
button.click()
sleep(2)
3.搜索想要爬取的公众号并进行搜索
# 切换窗口
driver.switch_to.window(driver.window_handles[-1])
sleep(2)
# 定位超链接按钮
button = driver.find_element_by_xpath('//*[@id="js_editor_insertlink"]')
# 执行单击操作
button.click()
sleep(2)
# 定位选择其他公众号按钮,也就是想获取得公众号名称
button = driver.find_element_by_xpath('//*[@id="vue_app"]/div[2]/div[1]/div/div[2]/div[2]/form[1]/div[4]/div/div/p/div/button')
# 执行单击操作
button.click()
sleep(2)
# 定位搜索输入框
text_label = driver.find_element_by_xpath('//*[@id="vue_app"]/div[2]/div[1]/div/div[2]/div[2]/form[1]/div[4]/div/div/div/div/div[1]/span/input')
# 在搜索框中输入丁香园
text_label.send_keys('丁香园')
sleep(2)
# 定位搜索按钮
button = driver.find_element_by_xpath('//*[@id="vue_app"]/div[2]/div[1]/div/div[2]/div[2]/form[1]/div[4]/div/div/div/div/div[1]/span/span/button[2]')
# 执行单击操作
button.click()
sleep(5)
# 定位第一条搜索结果
button = driver.find_element_by_xpath('//*[@id="vue_app"]/div[2]/div[1]/div/div[2]/div[2]/form[1]/div[4]/div/div/div/div[2]/ul/li[1]/div[1]')
# 执行单击操作
button.click()
sleep(5)
4.获取数据
datas_list = []
page_number = driver.find_elements_by_class_name('weui-desktop-pagination__num')[1].text
for i in range(int(page_number)):
# 定位数据
datas = driver.find_elements_by_class_name('inner_link_article_item')
# 向列表中添加数据
for i in datas:
row_list = []
title = i.find_element_by_class_name('inner_link_article_title').text
row_list.append(title)
print(title)
date = i.find_element_by_class_name('inner_link_article_date').text
row_list.append(date)
print(date)
link = i.find_element_by_tag_name('a').get_attribute('href')
row_list.append(link)
print(link)
print('****************************************************************************')
datas_list.append(row_list)
# 实现翻页
button = driver.find_elements_by_xpath('//*[@id="vue_app"]/div[2]/div[1]/div/div[2]/div[2]/form[1]/div[5]/div/div/div[3]/span[1]/a')[-1]
button.click()
sleep(4)
print(datas_list)
5.写入excel
book = xlwt.Workbook(encoding='utf-8',style_compression=0)
sheet = book.add_sheet('data',cell_overwrite_ok=True)
col = ('标题','发表时间','文章链接')
for i in range(0,3):
sheet.write(0,i,col[i])
for i in range(len(datas_list)):
data = datas_list[i]
for j in range(0,3):
sheet.write(i+1,j,data[j])
savepath = r'C:\Users\hp\Desktop\公众号数据.xls'
book.save(savepath)