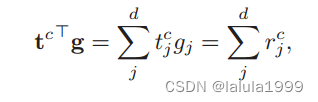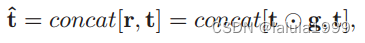文章目录
相关资料
代码:https://github.com/ZiqinZhou66/ZegCLIP
论文:ZegCLIP: Towards Adapting CLIP for Zero-shot Semantic Segmentation
摘要
最近,CLIP 通过两阶段方案被应用于像素级zero-shot学习任务。其总体思路是首先生成与类别无关的区域建议,然后将裁剪过的建议区域输入 CLIP,以利用其图像级零镜头分类能力。这种方案虽然有效,但需要两个图像编码器,一个用于生成建议,另一个用于 CLIP,从而导致复杂的流水线和高昂的计算成本。
在这项工作中,我们追求一种更简单高效的单阶段解决方案,直接将 CLIP 的zero-shot预测能力从图像级扩展到像素级。我们的研究以直接扩展为基线,通过比较文本和从 CLIP 提取的补丁嵌入之间的相似性来生成语义掩码。然而,这种范例可能会严重过度拟合已见类别,无法推广到未见类别。为了解决这个问题,我们提出了三种简单而有效的设计,并发现它们可以显著保留 CLIP 固有的零点能力,并提高像素级的泛化能力。通过这些修改,我们开发出了一种高效的零镜头语义分割系统,称为 ZegCLIP。
通过在三个公共基准上进行广泛的实验,ZegCLIP 展示了卓越的性能,在 "inductive"和 "transductive "零镜头设置下都远远优于最先进的方法。此外,与两阶段方法相比,我们的单阶段 ZegCLIP 在推理过程中的速度提高了约 5 倍。
- 归纳(Inductive)设置:
在归纳设置中,零样本学习模型的目标是识别在训练阶段从未见过的类别。未见的类名和图像在训练期间都不可访问。- 传导(Transductive)设置:
传导设置在零样本学习的上下文中不如归纳设置常见,但它涉及到使用一些关于未知类别的辅助信息来提高模型的性能。它假设在测试阶段之前未知类的名称是已知的。
引言
zero-shot语义分割定义
zero-shot语义分割尤其具有挑战性和吸引力,因为它需要根据给定类别的语义描述直接生成语义分割结果。
zero-shot前人工作
CLIP 最初是为匹配文本和图像而构建的,它在图像级零镜头分类方面表现出了卓越的能力。不过,zsseg 和 Zegformer采用的是常见的策略,即需要两阶段处理,首先生成区域建议,然后将裁剪后的区域输入 CLIP 进行零镜头分类。这种策略需要两个图像编码过程,一个用于生成建议,另一个用于通过 CLIP 对每个建议进行编码。这种设计产生了额外的计算开销,并且不能在提案生成阶段利用CLIP编码器的知识。此外,MaskCLIP+利用CLIP生成新类的伪标签进行自我训练,但如果推理中未见的类名在训练阶段未知(“inductive”零射设置),则无效。
本文工作
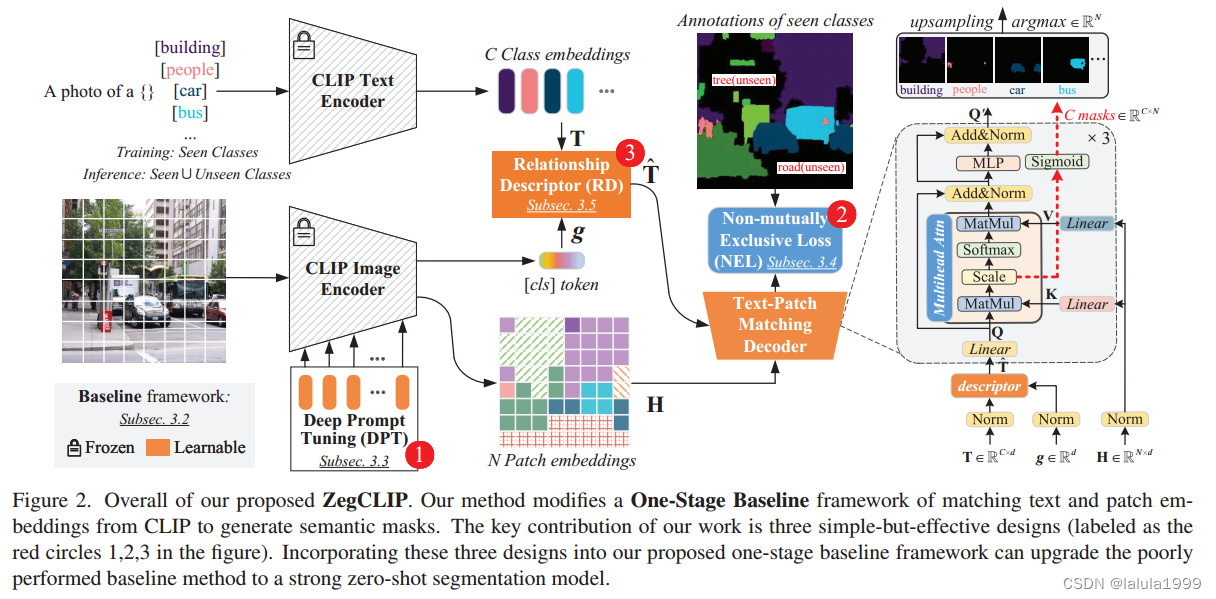
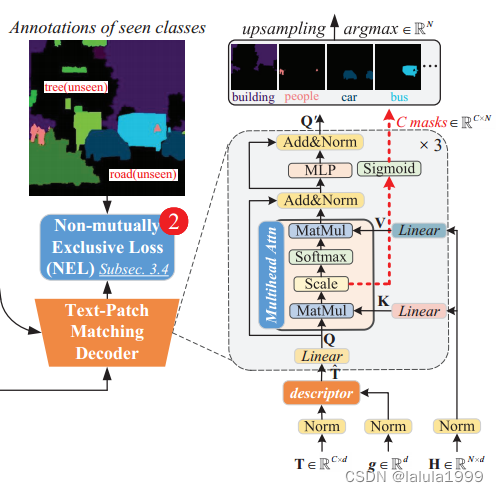
我们使用轻量级解码器将文本提示与从 CLIP 中提取的局部嵌入相匹配,这可以通过基于transformer结构的自注意机制来实现。我们在一个包含来自有限类别的像素级注释的数据集上训练Transformer解码器,并固定或微调 CLIP 图像编码器,期望文本补丁匹配能力能推广到未见过的类别。遗憾的是,这种基本版本往往会过度拟合训练集:虽然对已见类别的分割结果普遍有所改善,但模型却无法对未见类别进行合理分割。以下是改进的3种设计:
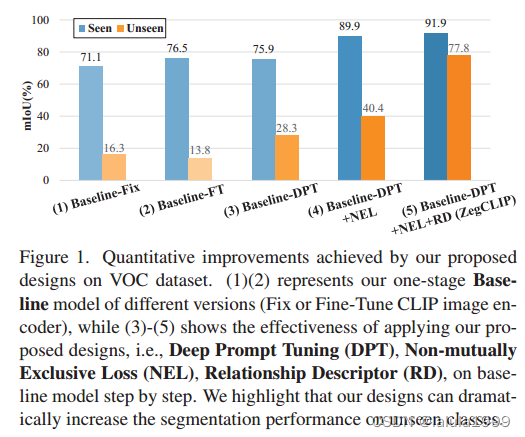
- 设计 1:使用深度提示微调(Deep Prompt Tuning, DPT)代替固定或微调 CLIP 图像编码器。我们发现,微调可能会导致对所见类别的过度拟合,而提示调整则更倾向于保留 CLIP 固有的zero-shot能力。
- 设计 2:在进行像素级分类时应用非互斥损失(Non-mutually Exclusive Loss, NEL)函数,但生成一个类别的后验概率与其他类别的对数无关。
- 设计 3:最重要的也是我们的主要创新–在匹配 CLIP 文本片段嵌入之前,引入关系描述符 (RD) 将图像级先验纳入文本嵌入,可显著防止模型过度拟合所见类别。

方法
问题定义
我们提出的方法遵循广义零次语义分割(generalized zero-shot semantic segmentation, GZLSS),该方法只需要在具有可见部分像素注释的数据集上进行训练,即可分割可见类和未见类。在训练阶段,模型根据所有看到的类的语义描述生成逐像素分类结果。在测试阶段,期望该模型为已知类和新类产生分割结果。零采样分割的关键问题是,在进行推理时,仅仅对已知类别进行训练不可避免地会导致对已知类别的过度偏差。
基线:单阶段文本补丁匹配
最近的研究表明,文本嵌入可以隐式地匹配补丁级图像嵌入,受此启发,我们通过添加一个普通的轻量级Transformer作为解码器来构建一个单阶段基线。然后,我们将语义分割描述为具有代表性的类查询与图像补丁特征之间的匹配问题。
在形式上,我们将
C
C
C类嵌入表示为
T
=
[
t
1
,
t
2
,
.
.
.
,
t
C
]
∈
R
C
×
d
T=[t^1,t^2,...,t^C]\in \mathbb{R}^{C\times d}
T=[t1,t2,...,tC]∈RC×d,其中
d
d
d为CLIP模型的特征维数,
t
i
t^i
ti表示第i个类
图像的N个patch令牌为
H
=
[
h
1
,
h
2
,
.
.
.
,
h
C
]
∈
R
C
×
d
H=[h_1,h_2,...,h_C]\in \mathbb{R}^{C\times d}
H=[h1,h2,...,hC]∈RC×d,
h
j
h_j
hj表示第j个补丁
然后使用线性映射生成
Q
,
K
,
V
Q, K, V
Q,K,V
语义掩码可以通过多头注意模型(MHA)的中间产物——标度点积注意来计算
对mask的类维度进行Argmax运算得到最终的分割结果,它由三层Transformer组成。
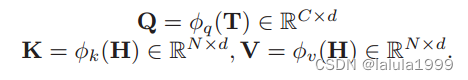
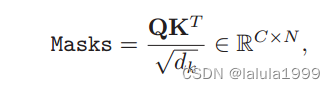
- 如何更新CLIP图像编码器——对应设计1
补丁特征表示由CLIP图像编码生成。在我们的基线方法中,我们认为 H H H是从参数固定的CLIP或参数可调的CLIP中获得的,分别表示为 B a s e l i n e − F i x Baseline - Fix Baseline−Fix和 B a s e l i n e − F T Baseline - FT Baseline−FT - 如何训练分割模型——对应设计2
为了正确训练解码器和(可选的)CLIP模型,我们应用常用的softmax算子将从标度点积注意计算的logits转换为后验概率。然后使用交叉熵等排他性损失(EL)作为目标函数。然而,这种看似简单的策略可能对泛化有潜在的危害。 - 如何进行查询嵌入的设计——对应设计3
查询嵌入是我们方法的关键。在我们的基线模型中,我们使用来自CLIP文本编码器的嵌入。然而,这样的选择可能会导致严重的过拟合。
设计1:深度提示微调(Deep Prompt Tuning, DPT)
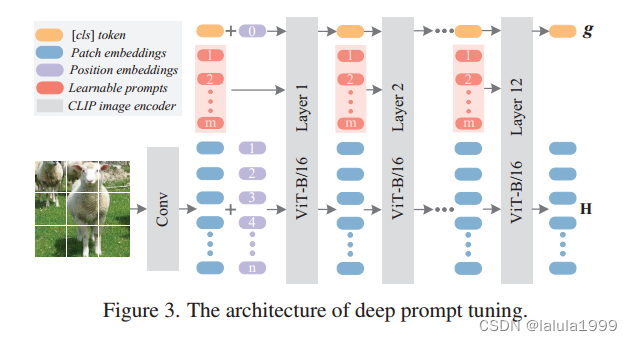
提示微调(prompt tuning)是最近提出的一种方案,用于使预训练的Transformer模型适应目标域。它已成为迁移学习环境中微调的一种竞争性替代方案。在这项工作中,我们探索了deep prompt tuning,使CLIP适应零镜头图像分割。Prompt tuning固定了 CLIP 的原始参数,并为每一层添加了可学习的提示标记作为额外输入。
由于零镜头分割模型是在有限数量的所见类别上训练出来的,直接微调模型往往会过度拟合所见类别,因为模型参数的调整只是为了优化所见类别的损失。因此,在微调过程中,针对训练集中未见过的视觉概念所学到的知识可能会被丢弃。由于原始参数在训练过程中保持不变,因此提示微调有可能缓解这一问题。
形式上,我们将 CLIP 中基于 ViT 的图像编码器第
l
l
l 个 MHA 模块的输入嵌入表示为
{
g
l
,
h
1
l
,
h
2
l
,
.
.
.
,
h
N
l
}
\{g^l , h^l_1, h^l_2, ... , h^l_N \}
{gl,h1l,h2l,...,hNl},其中
g
l
g^l
gl 表示
[
C
L
S
]
[CLS]
[CLS] 标记嵌入,
H
l
=
{
h
1
l
,
h
2
l
,
.
.
.
,
h
N
l
}
H^l = \{h^l_1, h^l_2, ... , h^l_N\}
Hl={h1l,h2l,...,hNl} 表示图像补丁嵌入。在 CLIP 图像编码器的每个 ViT 层中,Deep Prompt Tuning将可学习标记
P
l
=
{
p
1
l
,
p
2
l
,
.
.
.
,
p
M
l
}
P^l = \{p^l_1, p^l_2,..., p^l_M\}
Pl={p1l,p2l,...,pMl}附加到上述标记序列中。然后,第
l
l
l 个 MHA 模块对输入标记进行如下处理:
其中,
{
p
1
l
,
p
2
l
,
.
.
.
,
p
M
l
}
\{p^l_1, p^l_2,..., p^l_M\}
{p1l,p2l,...,pMl}的输出嵌入将被丢弃(表示为 _),不会进入下一层。
因此,
{
p
1
l
,
p
2
l
,
.
.
.
,
p
M
l
}
\{p^l_1, p^l_2,..., p^l_M\}
{p1l,p2l,...,pMl}仅仅是调整 MHA 模型的一组可学习参数。
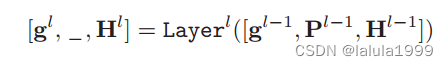
设计2:非互斥损失(Non-mutually Exclusive Loss, NEL)
语义分割模型的一般做法是将其视为每个像素的多分类问题,并使用 Softmax 运算来计算后验概率,然后使用交叉熵(Cross Entropy)等互斥损失(EL)作为损失函数。不过,Softmax 基本上假定了待分类类别之间的互斥关系:一个像素必须属于其中一个感兴趣的类别。因此,在计算后验概率时,只有对数的相对强度(即对数比率)才是最重要的。然而,当将模型应用于未见类别时,类别空间将与训练场景不同,这使得未见类别的对数与其他未见类别的对数校准不佳。
为了解决这个问题,我们建议在训练时避免使用互斥机制,而使用非互斥损失(NEL),更具体地说,使用 Sigmoid 和二元交叉熵(BCE)损失,以确保每个类别的分割结果都是独立生成的。此外,我们还使用了 BCE 损失的 focal 损失变体,并将其与额外的 dice 损失结合起来:
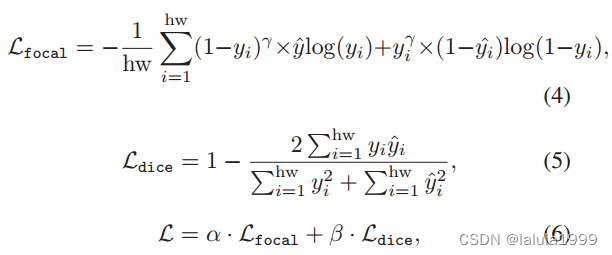
设计3:关系描述符(Relationship Descriptor, RD)
在上述设计中,从 CLIP 文本编码器中提取的类嵌入将与解码头中从 CLIP 图像编码器中提取的补丁嵌入相匹配。
虽然非常直观,但我们发现这种设计可能会导致严重的过拟合。我们推测,这是因为文本查询和图像模式之间的匹配能力仅在见过的类数据集上进行过训练。
这促使我们将从原始 CLIP 训练中学到的匹配能力纳入 Transformer 解码器。具体来说,我们注意到 CLIP 通过以下方式计算文本提示和图像之间的匹配得分:
式中
t
c
∈
R
d
t^c\in \mathbb{R^d}
tc∈Rd表示第
c
c
c 类的文本嵌入,
t
j
t_j
tj 是其第
j
j
j 维;
g
g
g 为图像嵌入( [cls] 令牌);
r
j
c
=
t
j
c
g
j
r^c_j = t^c_j g_j
rjc=tjcgj。我们假设
r
c
=
[
r
1
c
,
r
2
c
,
⋅
⋅
⋅
,
r
d
c
]
r^c = [r^c_1, r^c_2,···,r^c_d]
rc=[r1c,r2c,⋅⋅⋅,rdc]描述了图像和文本(即代表
c
c
c 类的文本提示)的匹配方式,并将其称为文本图像关系描述符(RD),对于所有
c
c
c 类,表示为
R
∈
R
C
×
d
R∈ \mathbb{R}^{C×d}
R∈RC×d。然后,我们将 RD 与原始文本嵌入
T
∈
R
C
×
d
T ∈ \mathbb{R}^{C×d}
T∈RC×d连接起来,作为特定于图像的文本查询
T
^
=
{
t
^
1
,
t
^
2
,
.
.
.
,
t
^
C
}
∈
R
C
×
2
d
\hat{T} =\{\hat{t}^1,\hat{t}^2, ...,\hat{t}^C \}∈\mathbb{R}^{C×2d}
T^={t^1,t^2,...,t^C}∈RC×2d,用于变换解码器。具体而言,在此方案下,每个类的Transformer解码器输入文本查询为:
其中
⊙
\odot
⊙是Hadamard乘积。
注意,我们在
T
^
\hat{T}
T^ 和
H
H
H 上都应用了可学习的线性投影层,使它们具有相同的特征维度。