文章目录
Structure-CLIP: Towards Scene Graph Knowledge to Enhance Multi-modal Structured Representations
相关资料
摘要
大规模视觉-语言预训练在多模态理解和生成任务中取得了显著的性能。然而,现有方法在需要结构化表示的图像-文本匹配任务上表现不佳,即表示对象、属性和关系的能力。模型无法区分“宇航员骑马”和“马骑宇航员”。这是因为它们在学习多模态表示时未能充分利用结构化知识。在本文中,我们提出了一个端到端的框架StructureCLIP,它通过整合场景知识图谱(SGK)来增强多模态结构化表示。首先,我们使用场景图指导构建语义负样本,这增加了学习结构化表示的重视。此外,我们提出了一个知识增强编码器(KEE),利用SGK作为输入进一步增强结构化表示。为了验证所提出框架的有效性,我们采用上述方法对模型进行预训练,并在下游任务上进行实验。实验结果表明,Structure-CLIP在VG-Attribution和VG-Relation数据集上实现了最先进的性能,分别比多模态最先进模型领先12.5%和4.1%。同时,MSCOCO上的结果表明,Structure-CLIP在保持通用表示能力的同时显著增强了结构化表示。我们的代码可在https://github.com/zjukg/Structure-CLIP上获得。
引言

尽管多模态模型在各种任务中的表现令人印象深刻,但这些模型是否能有效捕获结构化知识——即理解对象属性和对象间关系的能力——这一问题仍未解决。如图1(a)所示,图像与正确匹配的标题(“宇航员正在骑马”)之间的CLIP得分(即语义相似性),与图像和不匹配的标题(“马正在骑宇航员”)之间的得分相比,呈现出较低的值。CLIP模型表现出与词袋方法类似的倾向,它不领会句子中的细粒度语义。
我们提出了Structure-CLIP,这是一种新方法,利用场景知识图谱(SGK)来增强多模态结构化表示。首先,我们利用SGK构建更符合背后意图的词交换。其次,我们提出了一个知识增强编码器(KEE),利用SGK提取基本结构信息。通过在输入级别整合结构化知识,所提出的KEE可以进一步增强结构化表示的能力。
方法
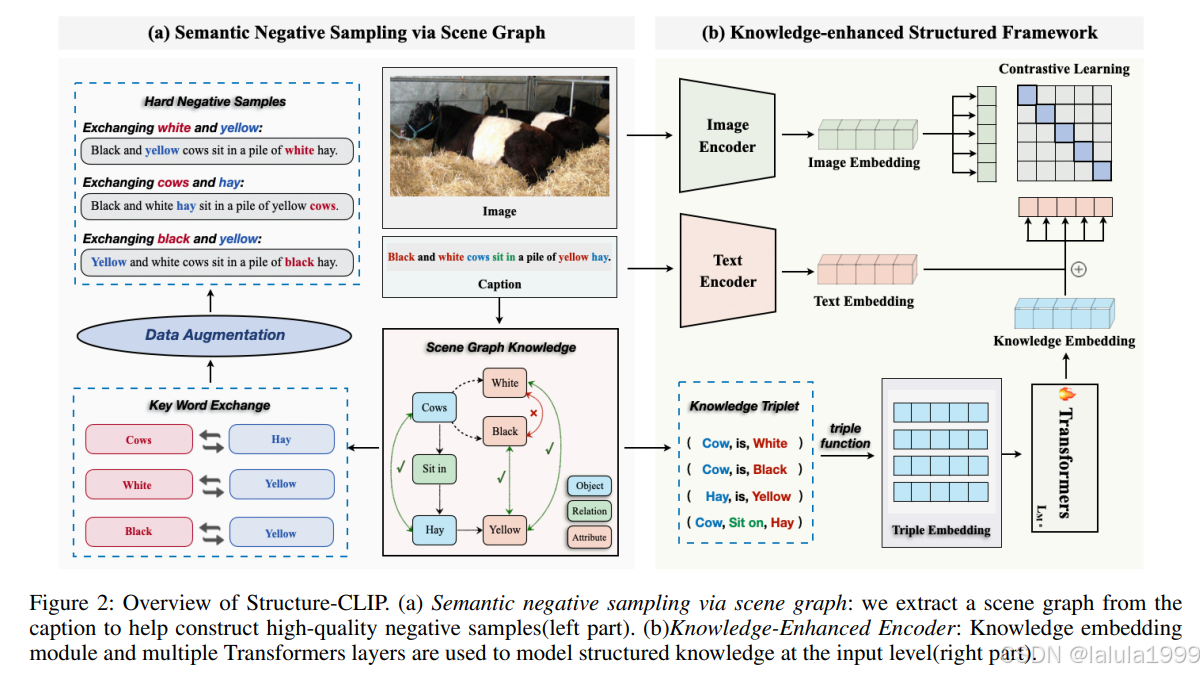
通过场景图进行语义负采样
Faghri等人(2018)提出了一种负采样方法,该方法通过与正样本比较来构建负样本,以增强表示。我们的目标是构建具有相似通用表示但不同详细语义的样本,从而鼓励模型专注于学习结构化表示。
场景图生成
在我们的框架中,采用了Wu等人(2019b)提供的场景图解析器来解析文本到场景图。给定文本句子 w w w,我们将其解析为场景图 G ( w ) = < O ( w ) , E ( w ) , K ( w ) > G(w) = <O(w), E(w), K(w)> G(w)=<O(w),E(w),K(w)>,其中 O ( w ) O(w) O(w)是 w w w中提到的对象集合, E ( w ) E(w) E(w)是关系节点集合, K ( w ) K(w) K(w)是与对象相关联的属性对集合。
选择语义负样本
对比学习旨在通过将语义上接近的邻居拉近,将非邻居推远来学习有效的表示。我们的目标是构建具有相似组成但不同详细语义的语义负样本。因此,负样本的质量在结构化表示学习中起着至关重要的作用。给定一个图像-文本对 ( I i , W i ) (I_i, W_i) (Ii,Wi)和从 W i W_i Wi生成的相关场景图 G ( W i ) G(W_i) G(Wi),通过以下方式生成高质量的语义负样本 W i − W^−_i Wi−:
W i − = F ( W i , G ( W i ) ) , ( 1 ) W^−_i = F(W_i, G(W_i)),(1) Wi−=F(Wi,G(Wi)),(1)
其中F是提出的采样函数,W− i表示高质量的语义负样本。具体来说,对于场景图中的三元组(对象1,关系,对象2), W i − W^−_i Wi−通过以下方式生成:
W i − = S w a p ( ( O 1 , R , O 2 ) ) = ( O 2 , R , O 1 ) , ( 2 ) W^−_i = Swap((O_1, R, O_2)) = (O_2, R, O_1),(2) Wi−=Swap((O1,R,O2))=(O2,R,O1),(2)
其中Swap是交换句子中的对象和主体的函数。对于属性对 ( A 1 , O 1 ) (A_1, O_1) (A1,O1)和 ( A 2 , O 2 ) (A_2, O_2) (A2,O2), W i − W^−_i Wi−通过以下方式生成:
S w a p ( ( A 1 O 1 ) , ( A 2 O 2 ) ) = ( A 2 O 1 ) , ( A 1 O 2 ) 如果 O 1 ≠ O 2 ,如果 O 1 = O 2 则保持不变, ( 3 ) Swap((A_1O_1), (A_2O_2)) = (A_2O_1), (A_1O_2)如果O_1 ≠ O_2,如果O_1 = O_2则保持不变,(3) Swap((A1O1),(A2O2))=(A2O1),(A1O2)如果O1=O2,如果O1=O2则保持不变,(3)
对比学习目标
我们的对比学习目标是通过将图像 I i I_i Ii和原始标题 W i W_i Wi拉近,将图像 I i I_i Ii和负样本 W i − W^−_ i Wi−推远来学习足够的表示。具体来说,我们引入了一个多模态对比学习模块,其损失函数为:
L h i n g e = m a x ( 0 , γ − d + d ′ ) , ( 4 ) L_{hinge} = max(0, γ − d + d^′),(4) Lhinge=max(0,γ−d+d′),(4)
同时,为了保持模型的通用表示能力,我们将原始的小批量图像-文本对比学习损失和提出的损失结合进行联合训练。原始的图像-文本对比学习损失 L I T C L L_{IT CL} LITCL包含一个图像到文本的对比损失 L i 2 t L_{i2t} Li2t和一个文本到图像的对比损失 L t 2 i L_{t2i} Lt2i:
L I T C L = ( L i 2 t + L t 2 i ) / 2 , ( 5 ) L_{IT CL}=(L_{i2t}+L_{t2i})/2,(5) LITCL=(Li2t+Lt2i)/2,(5)
最终损失:
L f i n a l = L h i n g e + L I T C L , ( 8 ) L_{final} = L_{hinge} + L_{IT CL}, (8) Lfinal=Lhinge+LITCL,(8)
知识增强编码器
知识增强编码器显式地将详细知识作为模型输入建模,即对象、对象的属性和成对对象之间的关系。具体来说,我们为两种结构化知识:对和三元组制定了统一的输入规范。我们在对中添加关系连接词“是”以统一表示。例如,对(白色,奶牛)将被当作三元组(奶牛,是,白色)来处理。这样,我们获得了一组三元组 T i n = ( h 1 , r 1 , t 1 ) , . . . , ( h k , r k , t k ) T_{in} = {(h1, r1, t1), ..., (hk, rk, tk)} Tin=(h1,r1,t1),...,(hk,rk,tk),其中(h, r, t)分别代表头部实体、关系实体和尾部实体。对于每个三元组(h, r, t),我们使用BERT的Tokenizer和Word Vocabulary Embeddings来获得每个实体的嵌入wh, wr, wt:
w x = W o r d E m b ( x ) , x ∈ [ h , r , t ] , ( 11 ) wx = WordEmb(x),x ∈ [h, r, t],(11) wx=WordEmb(x),x∈[h,r,t],(11)
为了获得每个实体嵌入的三元组嵌入,我们使用以下编码函数:
e t r i p l e i = E N C t r i p l e ( h i , r i , t i ) = w h , i + w r , i − w t , i , ( 12 ) etriplei = ENC_{triple}(h_i, r_i, t_i) = w_{h,i} + w_{r,i} − w_{t,i},(12) etriplei=ENCtriple(hi,ri,ti)=wh,i+wr,i−wt,i,(12)
其中 E N C t r i p l e ( . ) ENCtriple(.) ENCtriple(.)是三元组编码函数。通过这个三元组编码器,我们的方法能更好地解决头部和尾部实体顺序颠倒的问题,详细分析见第4.4.3节。这样,K个三元组可以被处理成K个语义嵌入。然后我们将etriple输入到多个Transformer层中以获得最终的表示。
e K E = T R M s ( [ e t r i p l e 1 , . . . , e t r i p l e K ] ) , ( 13 ) eKE = TRMs([etriple1, ..., etripleK]), (13) eKE=TRMs([etriple1,...,etripleK]),(13)
知识增强编码器使我们能够从所有输入的三元组中提取足够的结构化知识,这些知识可以作为有效的结构化知识来提高结构化表示的性能。因此,知识增强编码器可以用来获取文本知识嵌入。然而,仅依赖结构化知识可能会导致一般语义表示的丢失。因此,我们整合了文本嵌入和结构化知识嵌入:
e t e x t = C L I P t e x t ( W i ) + λ ⋅ T R M s ( [ e t r i p l e ∗ ] ) , ( 14 ) etext = CLIPtext(Wi) + λ · TRMs([etriple*]), (14) etext=CLIPtext(Wi)+λ⋅TRMs([etriple∗]),(14)
我们的文本表示既包含了整个句子所携带的词汇信息,也包含了由句子中详细语义构成的结构化知识。