文章目录
Zero-shot Object Classification with Large-scale Knowledge Graph
相关资料
论文:Zero-shot Object Classification with Large-scale Knowledge Graph
摘要
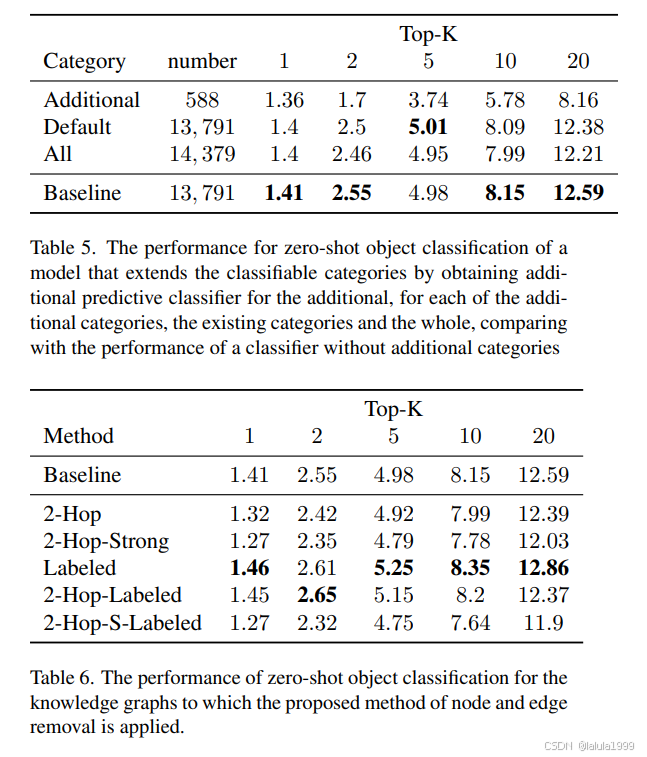
零样本学习是针对预测未见类别的研究,它可以解决在训练时未预见到的类别问题以及缺乏标记数据集的问题。零样本目标分类的方法之一是使用知识图谱,这是一组显性知识。由于识别限于知识图谱中包含的类别,并且随着图谱大小的不同,类别之间的关系在数量和质量上都有望变得更加丰富,因此处理一个包含尽可能多类别的大规模知识图谱是可取的。我们使用的知识图谱包含的类别数量大约是现有研究中主要使用的知识图谱的七倍,以实现对更多类别的分类并实现更准确的识别。在使用大规模知识图谱时,预计噪声节点和边的数量会增加。因此,我们提出了一种方法,通过知识图谱中类别之间的位置关系和边的类型,从整个图中提取有用信息。我们对现有研究中无法分类的图像进行了分类,并展示了所提出数据提取方法与使用整个图谱相比提高了性能。
引言
为了执行零样本目标分类,应该使用训练数据集中的类别所获得的知识,来预测在训练时不存在的未见类别。一种方法是使用知识图谱,如WordNet和ConceptNet。
零样本目标分类的优势在于无需训练数据集即可执行,但它限于知识图谱中包含的类别。此外,随着图谱大小的不同,类别之间的关系在数量和质量上都有望变得更加丰富。因此,使用包含尽可能多类别的大规模知识图谱是可取的。
我们的工作贡献是:
- 在零样本目标分类中,我们应用了大规模知识图谱来对现有研究中未作为识别目标的类别进行分类。
- 在将大规模知识图谱应用于零样本目标分类时,我们提出了基于类别之间的语义连接和关系类型从知识图谱中提取有效信息的方法。
- 我们通过实验表明,所提出数据提取方法提高了零样本目标分类的性能。
方法
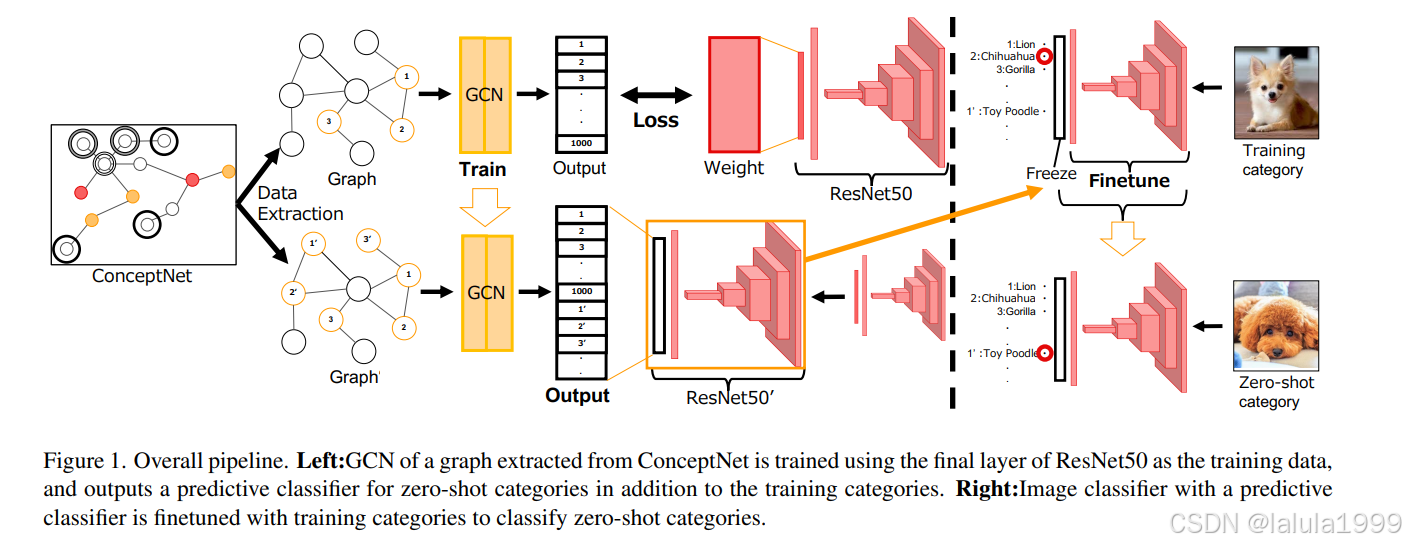
与以往使用知识图谱的研究一样,本研究采用的方法是将嵌入的语义特征作为输入信息,并构建一个通过知识图谱的图卷积网络(GCN)来对零样本类别进行分类的对象分类模型。为了使用大规模知识图谱,模型构建基于Wang等人的框架。然而,包括在ConceptNet中的类别是识别的目标,包括那些无法通过基于WordNet的方法进行分类的类别。此外,为了处理由于ConceptNet中的大规模概念而预计会增加的噪声节点和边,我们使用知识图谱中的类别位置关系和边的类型等图信息,从整个图中提取仅对零样本对象分类有效的信息。
整体流程
- 使用预训练的ResNet50的最后一层权重作为训练数据,训练基于从ConceptNet提取的知识图谱的GCN。GCN的输入是每个节点对应的GloVe词特征嵌入向量,每个节点输出对应于ResNet50预训练类别的最后一层权重的特征向量。在此训练中,最小化了L2距离。学习到的GCN除了训练类别之外,还输出了零样本对象分类的目标类别的预测分类器的权重。预测分类器被替换为ResNet50的最后一层。
- 通过冻结预测分类器权重,通过学习训练类别的分类任务,微调原始分类器部分,该部分提取图像特征。
通过上述训练和微调,可以对零样本对象分类的目标类别进行分类。图卷积网络。由Kiph等人[9]提出的GCN可以描述如下:
H ( ℓ + 1 ) = σ ( D ~ − 1 2 A ~ D ~ − 1 2 H ( ℓ ) W ( ℓ ) ) H^{(\ell+1)} = \sigma \left( \tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}} H^{(\ell)} W^{(\ell)} \right) H(ℓ+1)=σ(D~−21A~D~−21H(ℓ)W(ℓ))
这里,
H
(
ℓ
)
H^{(\ell)}
H(ℓ)表示第
ℓ
\ell
ℓ层中每个节点的特征,
H
(
0
)
H^{(0)}
H(0)表示所有节点的初始特征矩阵,
A
~
=
A
+
I
\tilde{A} = A + I
A~=A+I(其中A是邻接矩阵,I是单位矩阵),
D
~
i
i
=
∑
j
A
~
i
j
\tilde{D}_{ii} = \sum_{j} \tilde{A}_{ij}
D~ii=∑jA~ij,
W
(
ℓ
)
W^{(\ell)}
W(ℓ)是第
ℓ
\ell
ℓ层的权重矩阵。同时,
σ
(
⋅
)
\sigma(\cdot)
σ(⋅)表示激活函数。通过这种方式,每个层的节点特征被更新,并且每层的权重矩阵通过基于最终层输出和训练数据之间的损失进行反向传播来学习。
根据Xu等人[22],可以使用以下函数
AGGREGATE
\text{AGGREGATE}
AGGREGATE从相邻节点聚合特征信息,并使用函数
COMBINE
\text{COMBINE}
COMBINE从聚合的节点更新节点特征,如下所述:
a v ( k ) = AGGREGATE ( k ) ( h u ( k − 1 ) , u ∈ N ( v ) ) a^{(k)}_v = \text{AGGREGATE}^{(k)} \left( h^{(k-1)}_u, u \in \mathcal{N}(v) \right) av(k)=AGGREGATE(k)(hu(k−1),u∈N(v))
h v ( k ) = COMBINE ( k ) ( h v ( k − 1 ) , a v ( k ) ) h^{(k)}_v = \text{COMBINE}^{(k)} \left( h^{(k-1)}_v, a^{(k)}_v \right) hv(k)=COMBINE(k)(hv(k−1),av(k))
其中, h v ( k ) h^{(k)}_v hv(k)表示第 k k k层中节点 v v v的特征, h v ( 0 ) h^{(0)}_v hv(0)是节点 v v v的初始特征。 a v ( k ) a^{(k)}_v av(k)是聚合的节点信息, N ( v ) \mathcal{N}(v) N(v)是与节点 v v v相邻的节点集。
因此,我们模型中使用的GCN可以描述如下:
a v ( ℓ ) = Mean ( h u ( ℓ − 1 ) , u ∈ S ( v ) ) a^{(\ell)}_v = \text{Mean} \left( h^{(\ell-1)}_u, u \in \mathcal{S}(v) \right) av(ℓ)=Mean(hu(ℓ−1),u∈S(v))
h v ( ℓ ) = σ ( W ( ℓ ) a v ( ℓ ) ) h^{(\ell)}_v = \sigma \left( W^{(\ell)} a^{(\ell)}_v \right) hv(ℓ)=σ(W(ℓ)av(ℓ))
Mean是取节点平均值的过程,
S
(
v
)
\mathcal{S}(v)
S(v)是从与
v
v
v相邻的节点中采样的集合。
σ
\sigma
σ表示通过LeakyReLU激活。
W
(
ℓ
)
W^{(\ell)}
W(ℓ)是第
ℓ
\ell
ℓ层的权重。
采样使用随机游走[23]进行。我们以节点
v
v
v作为起点,根据边移动。在每个相邻节点处计算随机游走的访问次数,并使所有相邻节点的访问次数归一化,以获得考虑节点在图结构中重要性的命中率。在采样时,根据它们的命中率选择节点。我们遵循Nayak等人[13],并在实验中使用2层GCN。实际上,由于图卷积的计算复杂度与每层采样对象的数量的乘积成正比,所以在不减少样本数量的情况下很难增加层数。
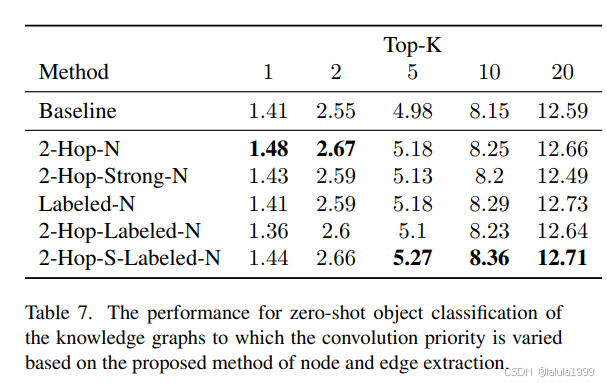
从ConceptNet中提取数据
2跳节点选择
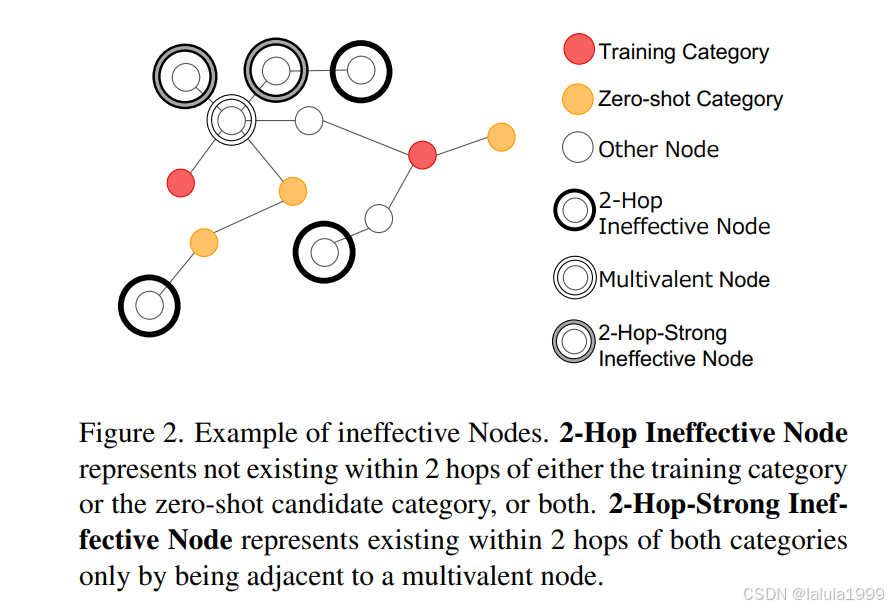
在通过从邻近节点执行图卷积来获得知识图谱中的预测分类器的操作中,预测分类器反映了与卷积层数相同跳数的节点信息。因此,当考虑2层GCN时,从类别获得的预测分类器是基于存在于2跳范围内的类别的特征构建的。因此,仅使用存在于任何训练类别的2跳范围内的节点信息进行训练,并且仅使用存在于任何零样本对象分类候选类别的2跳范围内的节点信息进行分类器预测。从这一点出发,我们假设只有存在于两个训练类别和任何候选类别的2跳范围内的节点才有助于零样本对象分类的学习。
图2对此进行了说明。红色节点是训练类别,黄色节点是零样本候选类别。被黑色圆圈包围的节点不存在于训练类别或候选类别的2跳范围内,或两者都不在。这些节点可能对类别的输出产生负面影响,因此去除它们预计会提高零样本对象分类的性能。此外,即使节点存在于训练和候选类别的2跳范围内,它也可能不有助于分类器的预测。大规模知识图谱包含许多连接到许多节点和边的多价节点。具体来说,在我们实验设置中最多头的节点有超过10,000条边。因此,我们认为像图2中灰色圆圈包围的节点那样,仅通过与多头节点相邻而存在于两个类别的2跳范围内的节点,会稀释多头节点的信息。因此,去除这样的节点也可能提高零样本对象分类的性能。这些方法去除了像/c/en/giant cockroach/n/wn/animal这样的噪声节点,它只有与训练类别/c/en/cockroach相连的边。尽管这种方法在零样本学习中明确设置了零样本候选类别,但由于ConceptNet包含许多除名词以外的单词和概念,自然地从候选类别中排除这样的节点,并仅针对存在可视觉识别对象的类别是合理的。
标记边选择
在ConceptNet中,边有标签,指示关系类型。许多关系标签,如(红狼,SimilerTo,东部狼),直接指示类别的图像特征的相似性,而其他标签,如(西装,AtLocation,衣柜),则间接指示类别的图像特征的相似性,因为可以通过衣柜追溯西装与其他服装之间的关系。
另一方面,有一些标签可能会损害图像特征的相似性。例如,标记为Antonym的边连接具有相反含义的节点,如(下降,Antonym,拾取),因此不能期望通过边间接连接的类别之间有图像特征的相似性。因此,通过从图中去除这样的边,我们可以期望通过选择更相关的类别进行训练和分类器预测来提高零样本对象分类的性能。
在这项研究中,我们移除了带有标签Antonym、Distinctfrom、NotCapableof、NotDesires、NotHasProperty的边,考虑到标签的含义和连接目标。
数据移除或优先级变更
在使用上述方法提取数据时,有两种可能的方法:
- 从知识图中移除不必要的节点;
- 保留知识图中的节点,但通过降低这些节点的优先级来改变图卷积中的信息。
在这项研究中,我们采用了后一种方法,通过将无效节点的命中率乘以0.01,从而降低它们的优先级,使得其他节点和边被优先选择。我们还构建了通过改变基于上述提出的节点和边提取方法的卷积优先级的图,来测量零样本对象分类的性能:2Hop-N、2-Hop-Strong-N、Labeled-N、2-Hop-Labeled-N、2Hop-S-Labeled-N。
实验