Graph-Based Visual-Semantic Entanglement Network for Zero-Shot Image Recognition
相关资料
论文:Graph-Based Visual-Semantic Entanglement Network for Zero-Shot Image Recognition
摘要
零样本学习(Zero-shot learning, ZSL)使用语义属性来连接未见对象的搜索空间。近年来,尽管深度卷积网络为ZSL任务带来了强大的视觉建模能力,但其视觉特征存在严重的模式惯性和缺乏语义关系的表示,导致严重的偏差和歧义。为了解决这一问题,我们提出了一种基于知识图谱的视觉-语义纠缠网络(Graph-based Visual-Semantic Entanglement Network),通过知识图谱将视觉特征进行图建模,并映射到语义属性,该网络包含几个新颖设计:
- 它建立了一个多路径纠缠网络,将卷积神经网络(CNN)和图卷积网络(GCN)相结合,将CNN的视觉特征输入到GCN中以模拟隐含的语义关系,然后GCN将图建模信息反馈到CNN特征;
- 它使用属性词向量作为GCN图语义建模的目标,形成了图建模的自洽回归,以监督GCN学习更个性化的属性关系;
- 它将通过图建模细化的层次化视觉-语义特征融合并补充到视觉嵌入中。
我们的方法在多个代表性的ZSL数据集上超越了现有的最先进方法:AwA2、CUB和SUN,通过促进视觉特征的语义链接建模。
引言
在ZSL任务中,输入图像表示为
x
x
x。由CNN形成的视觉嵌入函数是
θ
(
⋅
)
θ(·)
θ(⋅)。与此分开的是,语义嵌入
φ
(
y
)
φ(y)
φ(y)表示类别
y
y
y的属性分布向量。
F
(
x
,
y
,
W
ϕ
)
=
F
ϕ
(
θ
(
x
)
,
W
ϕ
)
φ
(
y
)
F(x, y, W_ϕ) = F_ϕ(θ(x), W_ϕ)φ(y)
F(x,y,Wϕ)=Fϕ(θ(x),Wϕ)φ(y)是分类的得分函数。视觉嵌入和语义嵌入之间的唯一联系是视觉-语义桥接
F
ϕ
(
⋅
,
W
ϕ
)
F_ϕ(·, W_ϕ)
Fϕ(⋅,Wϕ),通常由几个全连接层(FC)构建。面对具有强烈模式惯性的视觉嵌入
θ
(
⋅
)
θ(·)
θ(⋅),
F
ϕ
(
⋅
,
W
ϕ
)
F_ϕ(·, W_ϕ)
Fϕ(⋅,Wϕ)承受着过度的建模压力,很难逆转预测偏差。尽管潜在属性机制减少了属性惯性引起的偏差,现有的ZSL模型仍然忽略了视觉特征中隐含的语义联系。
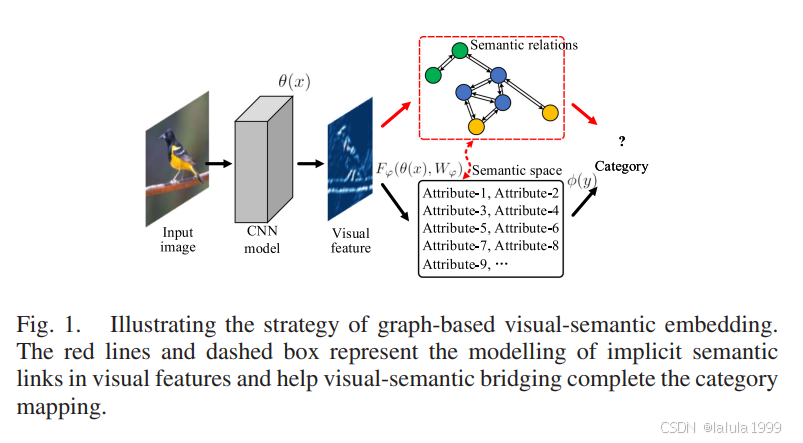
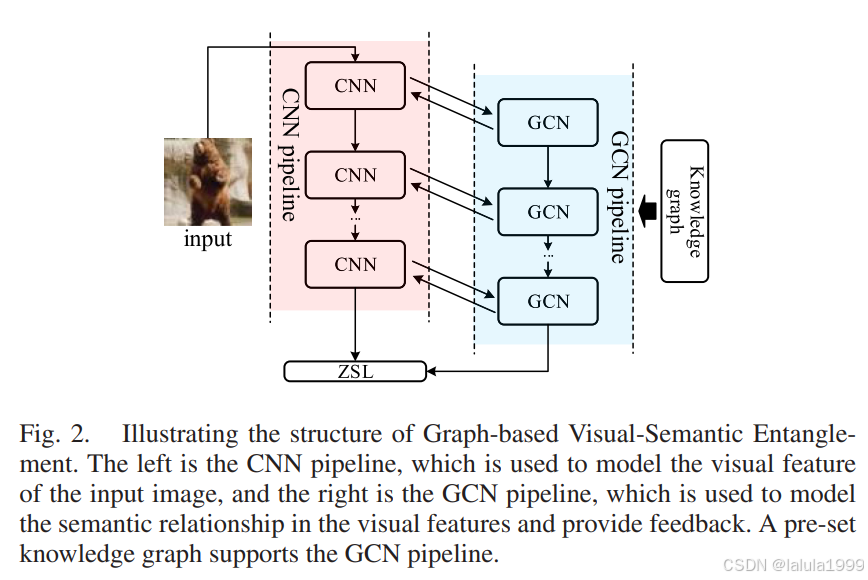
为了解决典型视觉特征缺乏属性内部关系知识的问题,我们必须利用属性连接的知识来补充映射、建模和融合隐含的语义关系,如图1中的红色部分所示。
我们提出了基于知识图谱的视觉-语义纠缠(Graph-based Visual-Semantic Entanglement, GVSE)网络。如图2所示,GVSE网络主要提出了视觉-语义纠缠结构:我们假设应该有一种机制将属性空间中的概念映射到图像表示中的语义表示。
基于属性的图建模可以直接与视觉特征中的语义信息交互。为了利用在语义知识图谱中发现的属性之间的关系,我们构建了具有CNN和图卷积网络(GCN)两个纠缠管道的架构,我们将CNN视觉特征映射到基于属性的知识图谱,然后利用GCN对中间视觉特征的隐含语义关系进行建模,并向CNN提供反馈。GVSE网络还包括一些有效的设计:
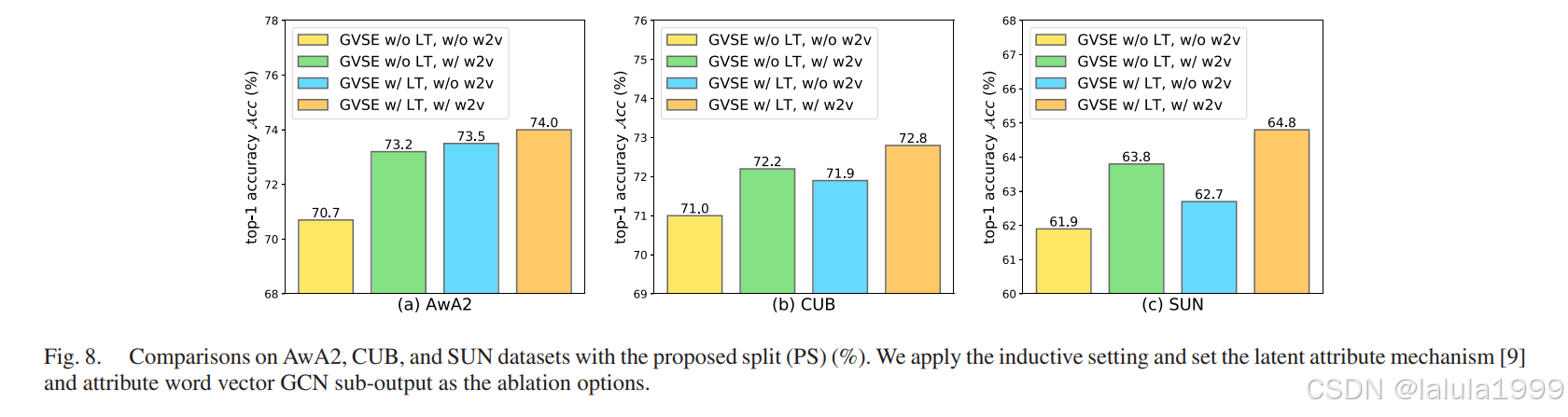
- 为了为模型提供更好的属性关系特征集,我们通过创建属性词向量来实现语义回归,创建了一个自洽的GCN建模系统。
- 为了将这种新语义派生信息整合到经典的ZSL模型中,我们跳过了图建模的视觉特征到视觉嵌入 θ ( x ) θ(x) θ(x)的连接。目的是将图增强的特征融合到视觉嵌入中,并帮助从语义嵌入 φ ( y ) φ(y) φ(y)反向传播损失。
方法
问题公式化和符号说明
零样本学习(ZSL)的任务是这样设定的:
存在一个已知数据集
S
=
{
(
x
i
s
,
y
i
s
)
}
i
=
1
N
s
S = \{(x^s_i, y^s_i)\}^{N^s}_{i=1}
S={(xis,yis)}i=1Ns,包含
N
s
N_s
Ns个样本用于训练,其中
x
i
s
x^s_i
xis表示第
i
i
i张图片,
y
i
s
∈
Y
S
y^s_i \in Y^S
yis∈YS是它的类别标签。
另有一个未见过的数据集
U
=
{
(
x
i
u
,
y
i
u
)
}
i
=
1
N
u
U = \{(x^u_i, y^u_i)\}^{N^u}_{i=1}
U={(xiu,yiu)}i=1Nu,形式类似。
已知和未知的类别集合
Y
S
Y^S
YS和
Y
U
Y^U
YU遵循以下约束:
Y
S
∩
Y
U
=
∅
,
Y
S
∪
Y
U
=
Y
Y^S \cap Y^U = \emptyset, Y^S \cup Y^U = Y
YS∩YU=∅,YS∪YU=Y,其中
Y
Y
Y是总类别集合。
Y
S
Y^S
YS和
Y
U
Y^U
YU共享一个语义属性空间:∀
y
i
y_i
yi ∃ < Att1, …, Attm > 作为它们之间的唯一桥梁,且
y
i
∈
Y
y_i \in Y
yi∈Y。Atti指的是属性,通常是一个词或概念,
m
m
m是属性的数量。
传统ZSL的目标是学习一个分类器,其搜索空间为未见过的类别
Y
U
Y^U
YU。对于更具挑战性的广义ZSL(GZSL),预期分类器的搜索空间是
Y
Y
Y。
框架概述
为了实现ZSL的视觉-语义纠缠特征建模目标,必须采取以下步骤:
-
构建语义知识图谱:为GCN的执行构建语义知识图谱。知识图谱提取属性的共现关系。
-
建立视觉-语义双管道网络结构:如图2所示,建立清晰的职责分工的双管道网络结构,CNN负责传统的图像视觉建模,GCN负责视觉特征的语义关系图建模。
-
设计CNN和GCN的纠缠策略:建立CNN视觉建模和GCN语义建模之间的交互功能。GCN接收CNN的视觉特征作为输入,CNN获取GCN的语义信息以进一步优化视觉特征。
-
融合图语义编码和视觉表示:为了进一步加强ZSL桥接的先前特征表示,我们将GCN块中的语义图建模特征合并到最终视觉嵌入中。
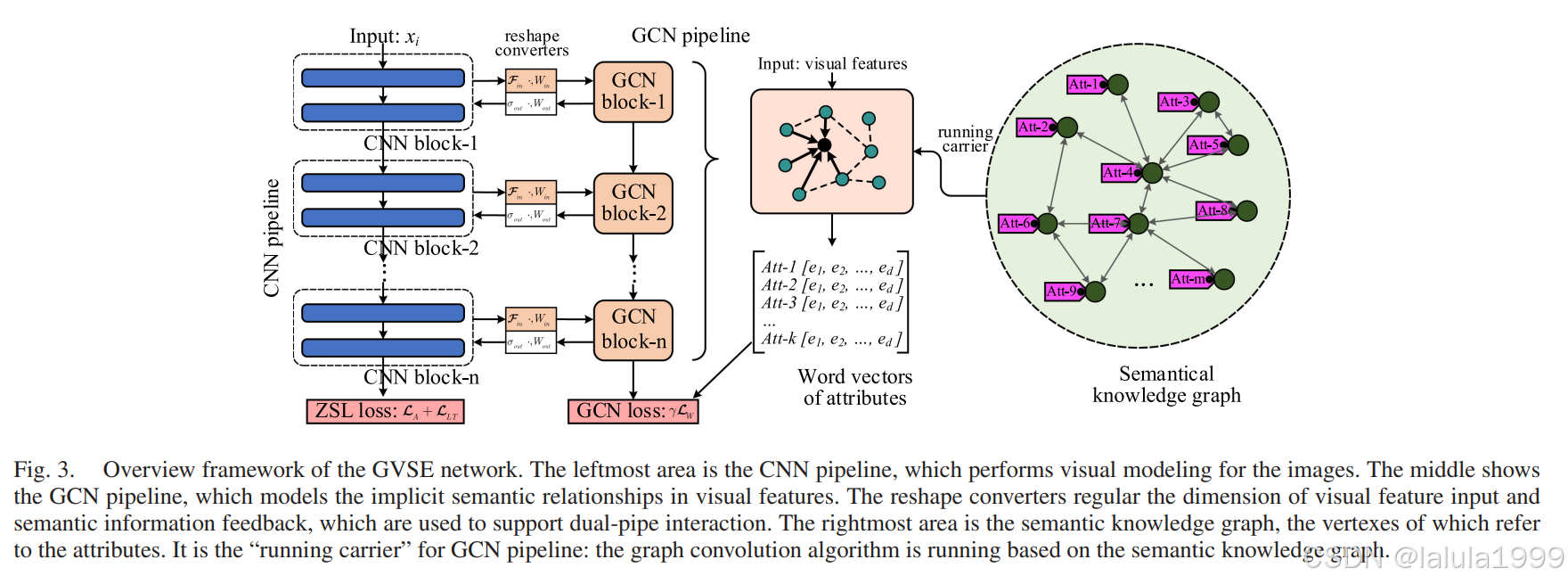
图3展示了GVSE网络的概述框架,它展示了属性的语义知识图谱,CNN视觉建模管道,GCN语义建模管道,双管道的目标输出,以及支持双管道纠缠的交互支持模块。
语义知识图谱
由于GCN需要在预定义的图结构上运行,因此在构建双管道视觉-语义神经网络架构之前,我们首先介绍语义知识图谱的构建策略。这个知识图谱将具有以下特征:
- 视觉特征直接与属性映射。因此,知识图谱预期表示属性的基本关系;
- 知识图谱的建立是离线的且方便;
- 知识图谱的建立可以适用于各种场景,不受适应数据集的本体限制。
共现关系是属性之间基本联系之一。它可以通过统计属性在每个类别中共同出现的次数来获得。我们不使用WordNet作为先验知识图谱,而是基于所有类别的属性共现关系来构建语义知识图谱。具有共现关系的属性在相同类别的视觉表示中有很高概率存在。
知识图谱 G a t t = ( V , E ) G_{att} = (V, E) Gatt=(V,E)包含顶点 V = { v 1 , v 2 , . . . , v m } V = \{v_1, v_2, ..., v_m\} V={v1,v2,...,vm}和它们之间的边 E E E。我们使用对称矩阵来编码边 [ [ l i , j ] ] [[l_{i,j}]] [[li,j]],其中 l i , j = 1 l_{i,j} = 1 li,j=1表示顶点 v i v_i vi和 v j v_j vj之间存在链接,否则不是。我们的构建知识图谱需要属性空间表示明确的概念。在我们的语义知识图谱中,属性用于定义顶点,点互信息(PMI)[51]用于计算属性共现并确定属性顶点之间的连接,如下所示:
PMI ( v i , v j ) = N log p ( v i , v j ) − log p ( v i ) − log p ( v j ) \text{PMI}(v_i, v_j) = \frac{N}{\log p(v_i, v_j) - \log p(v_i) - \log p(v_j)} PMI(vi,vj)=logp(vi,vj)−logp(vi)−logp(vj)N
其中 PMI ( v i , v j ) \text{PMI}(v_i, v_j) PMI(vi,vj)是属性 v i v_i vi和 v j v_j vj之间的PMI, p ( v ) p(v) p(v)是属性 v v v的出现概率,共现概率 p ( v i , v j ) p(v_i, v_j) p(vi,vj)是具有 v i v_i vi和 v j v_j vj的类别数量与总类别数量的比率。 N N N表示在[0, 1]范围内的归一化函数。图3展示了我们语义知识图谱的构建策略,边是在PMI高于阈值 δ \delta δ的顶点之间建立的,如下所示:
l i , j = { 1 , if PMI ( v i , v j ) > δ 0 , otherwise l_{i,j} = \begin{cases} 1, & \text{if } \text{PMI}(v_i, v_j) > \delta \\ 0, & \text{otherwise} \end{cases} li,j={1,0,if PMI(vi,vj)>δotherwise

双管道网络结构
我们设计的两个建模管道有明确的分工。我们首先定义CNN管道的视觉特征建模如下:
θ ( x i ) = F c o n v ( x i , W θ ) \theta(x_i) = F_{conv}(x_i, W_{\theta}) θ(xi)=Fconv(xi,Wθ)
其中 x i x_i xi指的是输入, θ ( x i ) \theta(x_i) θ(xi)是由CNN管道 F c o n v F_{conv} Fconv建模并提供的视觉嵌入,其参数由 W θ W_{\theta} Wθ指定。在我们的研究中,CNN管道 F c o n v F_{conv} Fconv可以由任何现有的流行CNN主干构成。
CNN管道的目标预测输出是ZSL分类分数 p ( y ∣ x i ) p(y|x_i) p(y∣xi),计算如下:
p ( y ∣ x i ) = F ϕ ( θ ( x i ) , W ϕ ) T ϕ ( y ) p(y|x_i) = F_{\phi}(\theta(x_i), W_{\phi})^T \phi(y) p(y∣xi)=Fϕ(θ(xi),Wϕ)Tϕ(y)
其中 F ϕ : R d v → R m F_{\phi} : \mathbb{R}^{d_v} \rightarrow \mathbb{R}^m Fϕ:Rdv→Rm是属性预测层,参数为 W ϕ ∈ R d v × m W_{\phi} \in \mathbb{R}^{d_v \times m} Wϕ∈Rdv×m, ϕ ( y ) ∈ R m × ∣ Y ∣ \phi(y) \in \mathbb{R}^{m \times |Y|} ϕ(y)∈Rm×∣Y∣表示类别 y y y的属性分布。 d v d_v dv是视觉特征的维度, m m m和 ∣ Y ∣ |Y| ∣Y∣分别指属性和类别的数量。
基于视觉特征中存在隐含的语义联系的前提,我们设计了GCN管道来对视觉特征中的语义关系进行建模。如图3所示,注意我们有来自CNN管道第 l l l块的特征图 X ( l ) = F c o n v [ , l ] ( x i , W θ [ , l ] ) X^{(l)} = F^{[~,l]}_{conv}(x_i, W^{[~,l]}_{\theta}) X(l)=Fconv[ ,l](xi,Wθ[ ,l]),其中 [ , l ] [~, l] [ ,l]表示“从1到 l l l”。我们使用 X ( l ) X^{(l)} X(l)作为相应GCN块 F G ( l ) F^{(l)}_G FG(l)的输入,如下所示:
f G ( l ) = F G ( l ) ( X ( l ) , < G a t t , W G ( l ) > ) f^{(l)}_G = F^{(l)}_G(X^{(l)}, < G_{att}, W^{(l)}_G >) fG(l)=FG(l)(X(l),<Gatt,WG(l)>)
其中 f G ( l ) f^{(l)}_G fG(l)是第 l l l个GCN块的输出, W G ( l ) W^{(l)}_G WG(l)是运行在图 G a t t G_{att} Gatt上的 F G ( l ) F^{(l)}_G FG(l)的参数。符号 < ⋅ , ⋅ > < \cdot, \cdot > <⋅,⋅>必须一起使用。每个GCN块包含2层GCN,其定义在[17]中,如下所示:
H ( i + 1 ) = σ ( D − 1 G a H ( i ) W G ( i ) ) H^{(i+1)} = \sigma(D^{-1}G_a H^{(i)} W^{(i)}_G) H(i+1)=σ(D−1GaH(i)WG(i))
其中
H
(
i
)
H^{(i)}
H(i)和
H
(
i
+
1
)
H^{(i+1)}
H(i+1)分别表示GCN中的任意两层,
D
D
D和
G
a
G_a
Ga是预设知识图谱
G
a
t
t
G_{att}
Gatt的度矩阵和邻接矩阵,
W
G
(
i
)
W^{(i)}_G
WG(i)表示第
i
i
i层GCN的参数,
σ
\sigma
σ是激活函数。在GCN管道中,我们为最初无序的视觉特征
X
(
l
)
X^{(l)}
X(l)赋予明确的属性定义,使得GCN:
F
G
(
l
)
F^{(l)}_G
FG(l)根据图
G
a
t
t
G_{att}
Gatt描述的关系对它们进行建模,从而激活
X
(
l
)
X^{(l)}
X(l)中的隐含语义联系。
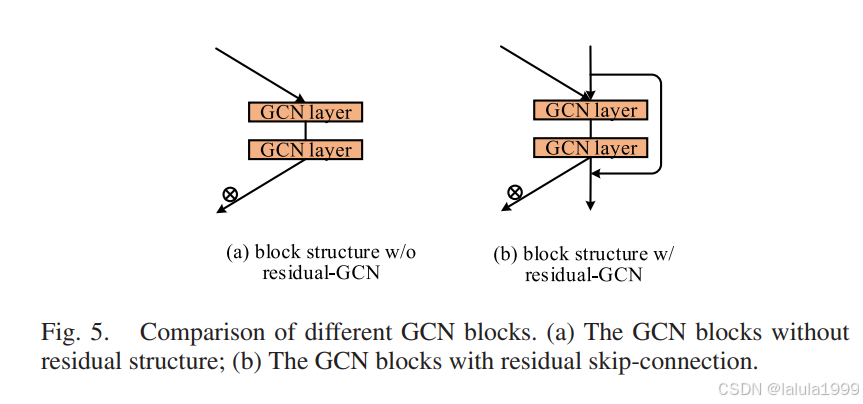
GCN管道将所有GCN块串联起来,为了解决GCN管道上的梯度扩散问题,我们采用了残差GCN结构,如图5(b)所示,如下所示:
f G ( l + 1 ) = F G ( l + 1 ) ( X ( l + 1 ) , f G ( l ) , < G a t t , W G ( l + 1 ) > ) + f G ( l ) f^{(l+1)}_G = F^{(l+1)}_G(X^{(l+1)}, f^{(l)}_G, < G_{att}, W^{(l+1)}_G >) + f^{(l)}_G fG(l+1)=FG(l+1)(X(l+1),fG(l),<Gatt,WG(l+1)>)+fG(l)
由于我们记录GCN管道为 F G F_G FG,其目标输出被设计为类别的属性词向量:
A ( x i ) = F G ( x i , < G a t t , W G > ) A(x_i) = F_G(x_i, < G_{att}, W_G >) A(xi)=FG(xi,<Gatt,WG>)
其中 W G W_G WG是GCN管道的参数,且
A ( x i ) = [ a 1 ( x i ) , a 2 ( x i ) , . . . , a k ( x i ) ] A(x_i) = [a_1(x_i), a_2(x_i), ..., a_k(x_i)] A(xi)=[a1(xi),a2(xi),...,ak(xi)]
这是属性词向量的集合。 a 1 ( x i ) . . . a k ( x i ) a_1(x_i) ... a_k(x_i) a1(xi)...ak(xi)是属性 A t t 1 . . . A t t k Att_1 ... Att_k Att1...Attk的词向量,这些属性属于真实类别 y i y_i yi。
我们如何获得属性词向量
在ZSL数据集中,每个类别都有多个属性,这样我们可以将每个类别 y ∈ Y y \in Y y∈Y视为属性集合{Att1, Att2, …, Attk}的集合,其中 k k k是类别 y y y具有的属性数量,然后我们可以将所有类别 Y Y Y视为语料库。有了这个语料库,我们可以方便地使用现有的语言模型工具[22], [55]训练词嵌入 M e M_e Me。像知识图谱 G a t t G_{att} Gatt一样,词嵌入 M e M_e Me的获取是离线且快速的。我们可以查询任意属性 A t t j Att_j Attj的词向量 a j = [ e 1 j , e 2 j , . . . , e d j ] ∈ R d a_j = [e_{1j}, e_{2j}, ..., e_{dj}] \in \mathbb{R}^d aj=[e1j,e2j,...,edj]∈Rd,其中 d d d是词嵌入的固定维度。
我们之所以将GCN管道的目标输出设置为上述形式,是因为:
- 作为一个基于词汇共现的模型,词向量可以与上述语义知识图谱 G a t t G_{att} Gatt形成自洽的回归;
- 语义知识图谱 G a t t G_{att} Gatt仅提供了基于平均强属性共现的初始属性关系信息。GCN管道需要在词嵌入监督下学习更个性化的属性关系。
CNN和GCN的纠缠策略
仅构建CNN管道 F c o n v F_{conv} Fconv和GCN管道 F G F_G FG是不够的。我们基于以下动机设计了它们之间的纠缠策略:
- CNN和GCN管道的建模过程需要交互和同步;
- 层次化的视觉特征需要接收有关语义关系建模的信息。本节详细介绍了从两个方向(CNN到GCN和GCN到CNN)的双管道纠缠策略。
对于CNN到GCN,我们已经描述了使用CNN块的特征图 X ( l ) X^{(l)} X(l)作为GCN块的输入。然而, X ( l ) X^{(l)} X(l)的形状可能不适合GCN输入,因此我们需要首先重塑 X ( l ) X^{(l)} X(l),如下所示:
X ( l ) = F i n ( l ) ( X ( l ) , W i n ( l ) ) X^{(l)} = F^{(l)}_{in}(X^{(l)}, W^{(l)}_{in}) X(l)=Fin(l)(X(l),Win(l))
此外,从第二个GCN块 F G ( 2 ) F_G^{(2)} FG(2)开始,使用连接操作 ⋄ \diamond ⋄将特征图 X ( l ) X^{(l)} X(l)和前一个GCN块的输出 f G ( l − 1 ) f_G^{(l-1)} fG(l−1)合并作为输入。因此,我们可以更新方程5和7为:
f G ( l ) = { F G ( l ) ( X ( l ) , < G a t t , W G ( l ) > ) , if l = 1 F G ( l ) ( X ( l ) ⋄ F s q ( f G ( l − 1 ) ) , < G a t t , W G ( l ) > ) + f G ( l − 1 ) , if l ≥ 2 f_G^{(l)} = \begin{cases} F_G^{(l)}(X^{(l)}, < G_{att}, W_G^{(l)} >), & \text{if } l = 1 \\ F_G^{(l)}(X^{(l)} \diamond F_{sq}(f_G^{(l-1)}), < G_{att}, W_G^{(l)} >) + f_G^{(l-1)}, & \text{if } l \geq 2 \end{cases} fG(l)={FG(l)(X(l),<Gatt,WG(l)>),FG(l)(X(l)⋄Fsq(fG(l−1)),<Gatt,WG(l)>)+fG(l−1),if l=1if l≥2
其中 F s q F_{sq} Fsq是压缩函数,它将 f G ( l − 1 ) f_G^{(l-1)} fG(l−1)的维度降低到 d d d以方便使用,它节省了 F G ( l ) F_G^{(l)} FG(l)的计算。
对于GCN到CNN,我们应用门控机制将GCN管道的语义关系建模信息反馈到CNN管道的视觉特征中,如下所示:
X ~ ( l ) = σ o u t ( f G ( l ) , W o u t ( l ) ⊗ X ( l ) ) \tilde{X}^{(l)} = \sigma_{out}(f_G^{(l)}, W_{out}^{(l)} \otimes X^{(l)}) X~(l)=σout(fG(l),Wout(l)⊗X(l))
其中,权重 W o u t ( l ) W_{out}^{(l)} Wout(l)用于将图建模信息 f G ( l ) f_G^{(l)} fG(l)的维度与特征图 X ( l ) X^{(l)} X(l)对齐,其作用类似于 W i n ( l ) W_{in}^{(l)} Win(l)。 σ o u t \sigma_{out} σout是激活函数,其输出值在[0, 1]范围内,操作 ⊗ \otimes ⊗是逐元素乘法, X ~ ( l ) \tilde{X}^{(l)} X~(l)是新的视觉特征图,将继续输入到后续的CNN管道中,如下所示: F c o n v [ l + 1 , ) ( X ~ ( l ) , W θ [ l + 1 , ) ) F_{conv}^{[l+1,~)}(\tilde{X}^{(l)}, W_{\theta}^{[l+1,~)}) Fconv[l+1, )(X~(l),Wθ[l+1, )),其中 [ l + 1 , ) [l + 1, ~) [l+1, )表示“从 l + 1 l + 1 l+1到最后”。
所提出的GVSE网络的纠缠策略如图3所示,它使GVSE网络的双管道结构除了各自的精确建模功能外,还得到了充分的交互。我们的策略与基于注意力方法的其他ZSL模型[3], [16], [31], [56]有以下不同之处:1. 利用图建模优化视觉隐含语义信息;2. CNN的各层特征将获得优化和反馈。
GCN语义图建模在每个CNN层的动机是,我们认为各个CNN块的视觉特征包含隐含的语义关系信息,对每个CNN块的语义关系进行建模支持将视觉-语义建模整合到整个CNN管道中,从而为语义丰富的ZSL视觉嵌入提供完整的优化。换句话说,我们的语义图建模视觉特征不会被压缩到一个块中。它将均匀分布在层次结构中,共享语义建模压力并获取层次化的视觉-语义信息。
将层次化语义特征整合到视觉嵌入中
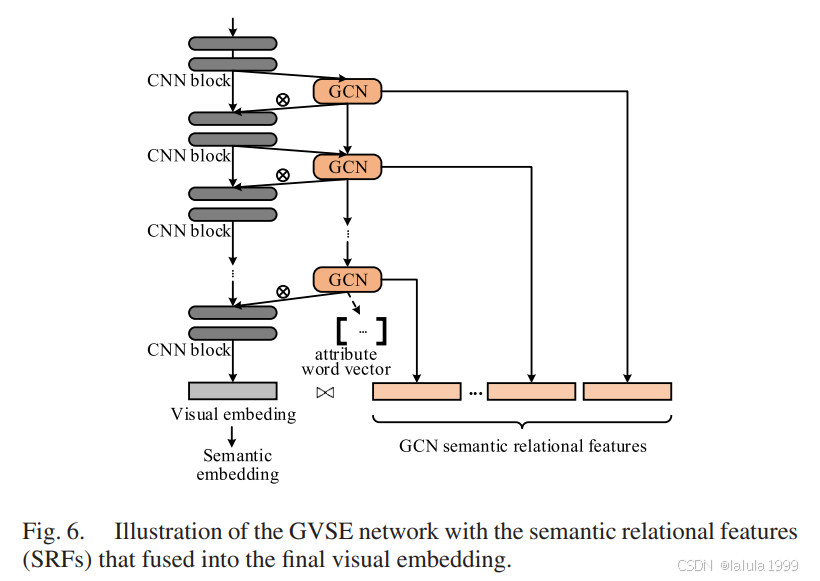
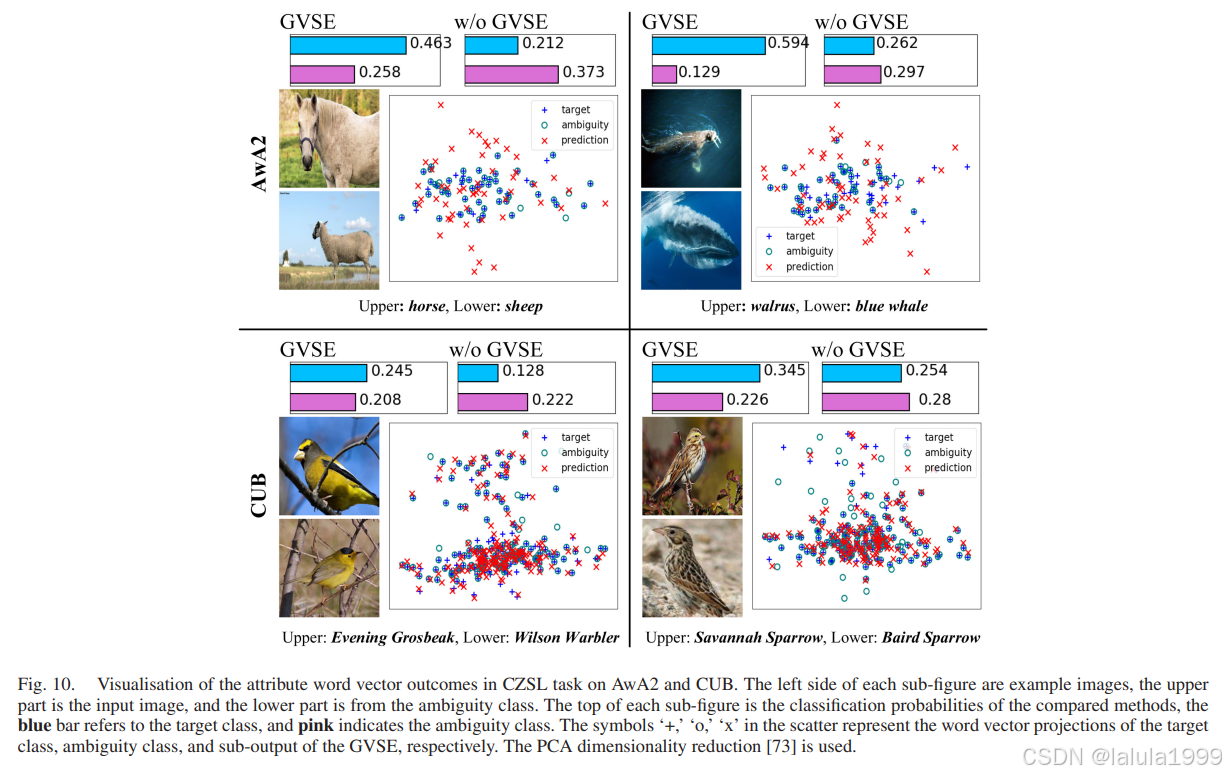
为了进一步加强最终的视觉嵌入,我们执行了最后一步。如图6所示,受金字塔结构[57]的启发,我们将来自GCN管道的语义特征合并到最终视觉嵌入 θ ( x ) \theta(x) θ(x)中,即语义关系特征(SRF)。它的优点是:1. 帮助损失函数反向传播到GCN块;2. 为潜在属性[9], [16]提供更多语义信息。
注意,最终的视觉嵌入是通过全局平均池化集中的:
θ ( x i ) = 1 R × C ∑ r = 1 R ∑ c = 1 C F c o n v [ ] ( x i , W θ ) [ r , c ] \theta(x_i) = \frac{1}{R \times C} \sum_{r=1}^{R} \sum_{c=1}^{C} F_{conv}^{[~]}(x_i, W_{\theta})[r, c] θ(xi)=R×C1∑r=1R∑c=1CFconv[ ](xi,Wθ)[r,c]
其中 F c o n v [ ] F_{conv}^{[~]} Fconv[ ]是CNN管道全局池化前的F部分,(R × C)是CNN管道最终特征图的形状, F c o n v [ ] ( x i , W θ ) [ r , c ] F_{conv}^{[~]}(x_i, W_{\theta})[r, c] Fconv[ ](xi,Wθ)[r,c]表示CNN特征图上第 r r r行第 c c c列的信号。
整合的视觉嵌入 θ ( x ) + \theta(x)^+ θ(x)+如下所示:
θ ( x ) + = θ ( x ) ⋄ f ^ G ( 1 ) ⋄ f ^ G ( 2 ) ⋄ . . . ⋄ f ^ G ( L ) \theta(x)^+ = \theta(x) \diamond \hat{f}_G^{(1)} \diamond \hat{f}_G^{(2)} \diamond ... \diamond \hat{f}_G^{(L)} θ(x)+=θ(x)⋄f^G(1)⋄f^G(2)⋄...⋄f^G(L)
其中
f ^ G ( i ) = 1 k ∑ v = 1 k F s q ( f G ( i ) [ v ] ) \hat{f}_G^{(i)} = \frac{1}{k} \sum_{v=1}^{k} F_{sq}(f_G^{(i)}[v]) f^G(i)=k1∑v=1kFsq(fG(i)[v])
这是用于汇聚GCN输出的属性词向量, k k k是属性数量。 F s q F_{sq} Fsq是一个压缩函数,用于减少GCN输出的宽度。
优化细节和ZSL预测
本研究中的GVSE网络为ZSL提供了更强大的语义关系表示特征,这适用于各种ZSL框架。由于我们在第三节中介绍了GVSE网络的双管道前馈特征建模方法,在这一部分中,我们简要描述了使用GVSE网络进行ZSL预测的方法和GVSE特征的优化方法。
我们从归纳和演绎这两种ZSL设置中引入了ZSL预测和优化的执行。所提出的GVSE网络使用反向传播(BP)算法[58]进行优化,损失函数指示了详细的优化策略。
A. 归纳ZSL设置
由于方程4制定了ZSL预测的分数函数,我们选择具有最大分数的标签作为:
y i ∗ = arg max y ∈ Y p ( y ∣ x i ) = arg max y ∈ Y ϕ ( x i ) T ϕ ( y ) y^*_i = \arg\max_{y \in Y} p(y|x_i) = \arg\max_{y \in Y} \phi(x_i)^T \phi(y) yi∗=argmaxy∈Yp(y∣xi)=argmaxy∈Yϕ(xi)Tϕ(y)
其中 ϕ ( x i ) = F ϕ ( θ ( x i ) + , W ϕ ) \phi(x_i) = F_{\phi}(\theta(x_i)^+, W_{\phi}) ϕ(xi)=Fϕ(θ(xi)+,Wϕ)指的是目标属性的视觉-语义投影。
我们还引入了潜在属性(LA)[9], [16]来补充人工定义的属性空间的不完美。这种机制需要计算所有类别的潜在属性原型,对于已知类别: ϕ l a t ( y s ) = 1 N ∑ ϕ l a t ( x i ) \phi_{lat}(y_s) = \frac{1}{N} \sum \phi_{lat}(x_i) ϕlat(ys)=N1∑ϕlat(xi),其中 ϕ l a t ( x i ) \phi_{lat}(x_i) ϕlat(xi)表示特定于潜在属性的区分特征,由[9]详细说明。对于未知类别,原型可以从岭回归中获得:
β u y = arg min y ∈ Y S ∥ ϕ ( y u ) − ∑ y ∈ Y S β u y ϕ ( y ) ∥ 2 2 + ∥ β u y ∥ 2 2 \beta_{u_y} = \arg\min_{y \in Y_S} \| \phi(y_u) - \sum_{y \in Y_S} \beta_{u_y} \phi(y) \|^2_2 + \| \beta_{u_y} \|^2_2 βuy=argminy∈YS∥ϕ(yu)−∑y∈YSβuyϕ(y)∥22+∥βuy∥22
ϕ l a t ( y u ) = ∑ y ∈ Y S β u y ϕ l a t ( y ) \phi_{lat}(y_u) = \sum_{y \in Y_S} \beta_{u_y} \phi_{lat}(y) ϕlat(yu)=∑y∈YSβuyϕlat(y)
然后,ZSL预测执行如下:
y i ∗ = arg max y ∈ Y ( ϕ ( x i ) T ϕ ( y ) + ϕ l a t ( x i ) T ϕ l a t ( y ) ) y^*_i = \arg\max_{y \in Y} (\phi(x_i)^T \phi(y) + \phi_{lat}(x_i)^T \phi_{lat}(y)) yi∗=argmaxy∈Y(ϕ(xi)Tϕ(y)+ϕlat(xi)Tϕlat(y))
由于我们有了上述ZSL预测过程,损失函数设置如下,我们使用softmax交叉熵损失来优化视觉-语义桥接,如下所示:
L A = − 1 N ∑ i = 1 N log e ϕ ( x i ) T ϕ ( y i ) ∑ y ∈ Y S e ϕ ( x i ) T ϕ ( y ) L_A = -\frac{1}{N} \sum_{i=1}^N \log \frac{e^{\phi(x_i)^T \phi(y_i)}}{\sum_{y \in Y_S} e^{\phi(x_i)^T \phi(y)}} LA=−N1∑i=1Nlog∑y∈YSeϕ(xi)Tϕ(y)eϕ(xi)Tϕ(yi)
对于区分特征 ϕ l a t \phi_{lat} ϕlat,我们遵循[9], [16]中的相同策略,使用三元组损失[62]来扩大类间距离并减少类内距离:
L L T = 1 N ∑ i = 1 N [ ∥ ϕ l a t ( x i ) − ϕ l a t ( x j ) ∥ 2 − ∥ ϕ l a t ( x i ) − ϕ l a t ( x r ) ∥ 2 + α ] + L_{LT} = \frac{1}{N} \sum_{i=1}^N [ \|\phi_{lat}(x_i) - \phi_{lat}(x_j)\|^2 - \|\phi_{lat}(x_i) - \phi_{lat}(x_r)\|^2 + \alpha ]_+ LLT=N1∑i=1N[∥ϕlat(xi)−ϕlat(xj)∥2−∥ϕlat(xi)−ϕlat(xr)∥2+α]+
其中 x i , x j , x_i, x_j, xi,xj,和 x r x_r xr分别代表三元组中的锚点、正样本和负样本, [ ⋅ ] + [·]_+ [⋅]+等同于 max ( 0 , ⋅ ) \max(0, ·) max(0,⋅), α \alpha α是三元组损失的边界,在所有实验中为1.0。
由于方程8中我们使用属性词向量作为GCN管道 F G F_G FG的目标输出,均方误差被用作该分支的损失,如下所示:
L W = 1 N ∑ i = 1 N ∑ v = 1 k i ( F s q ( f G ( L ) ( x i ) [ v ] ) − a v ( y i ) ) 2 L_{W} = \frac{1}{N} \sum_{i=1}^N \sum_{v=1}^{k_i} \left( F_{sq}(f_G^{(L)}(x_i)[v]) - a_v(y_i) \right)^2 LW=N1∑i=1N∑v=1ki(Fsq(fG(L)(xi)[v])−av(yi))2
其中 f G ( L ) f_G^{(L)} fG(L)表示来自最后一个GCN块的输出特征, k i k_i ki是属于类别 y i y_i yi的属性数量。
完整的损失函数如下:
L = L A + L L T + γ L W L = L_A + L_{LT} + \gamma L_W L=LA+LLT+γLW
B. 演绎ZSL设置
我们也将在GVSE网络中学习到的关系增强特征应用于三个演绎ZSL框架:1. 准全监督学习(QFSL)[7];2. 自适应(SA)[16];3. 基于Wasserstein距离的视觉结构约束(WDVSc)[15]。这些演绎ZSL方法都向模型开放对未见过数据的访问,从而缓解了“领域偏移”现象。
其中,SA方法需要与LA机制[9]一起执行;它吸收了未见过类别的信息,并进行了几次离线迭代,以更新原型 ϕ l a t ( y u ) \phi_{lat}(y_u) ϕlat(yu)和未见过类别的属性分布 ϕ ( y u ) \phi(y_u) ϕ(yu)。
另外两种演绎ZSL方法没有与LA机制一起使用。在QFSL中,在损失函数中增加了一个偏置项 L B = 1 N u ∑ i = 1 N u ( − log ( ∑ y ∈ Y U p ( y ∣ x i ) ) ) L_B = \frac{1}{N_u} \sum_{i=1}^{N_u} (-\log(\sum_{y \in Y_U} p(y| x_i))) LB=Nu1∑i=1Nu(−log(∑y∈YUp(y∣xi))),以鼓励模型输出未见过类别的分类结果。
在WDVSc中,使用Wasserstein距离[63]来校正语义演绎空间中未见类别的聚类中心的位置。它通过计算特征分布与类别聚类中心之间的距离来确定分类结果。
这些演绎ZSL方法中的特殊设计预测和优化不会影响GVSE网络对关系增强视觉嵌入 θ ( x ) + \theta(x)^+ θ(x)+的建模。它们的详细实现在原始研究[7], [15], [16]中有描述。
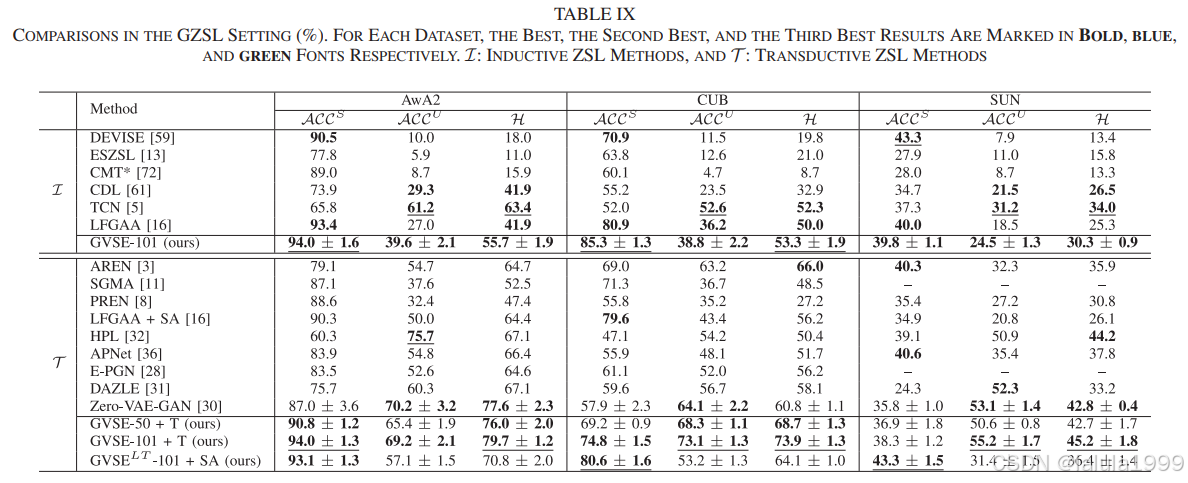
实验