G:\Bigdata\25.iceberg
第3章 与 Hive集成
3.1 环境准备
1)Hive与Iceberg的版本对应关系如下
| Hive 版本 |
官方推荐Hive版本 |
Iceberg 版本 |
| 2.x |
2.3.8 |
0.8.0-incubating – 1.1.0 |
| 3.x |
3.1.2 |
0.10.0 – 1.1.0 |
Iceberg与Hive 2和Hive 3.1.2/3的集成,支持以下特性:
- 创建表
- 删除表
- 读取表
- 插入表(INSERT into)
更多功能需要Hive 4.x(目前alpha版本)才能支持。
2) 上传jar包,拷贝到Hive的auxlib目录中
mkdir auxlib
cp iceberg-hive-runtime-1.1.0.jar /opt/module/hive/auxlib
cp libfb303-0.9.3.jar /opt/module/hive/auxlib
3) 修改hive-site.xml,添加配置项
<property>
<name>iceberg.engine.hive.enabled</name>
<value>true</value>
</property>
<property>
<name>hive.aux.jars.path</name>
<value>/opt/module/hive/auxlib</value>
</property>
使用TEZ引擎注意事项:
(1)使用Hive版本>=3.1.2,需要TEZ版本>=0.10.1
(2)指定tez更新配置:
<property>
<name>tez.mrreader.config.update.properties</name>
<value>hive.io.file.readcolumn.names,hive.io.file.readcolumn.ids</value>
</property>
(3)从Iceberg 0.11.0开始,如果Hive使用Tez引擎,需要关闭向量化执行:
<property>
<name>hive.vectorized.execution.enabled</name>
<value>false</value>
</property>
4)启动HMS服务
5)启动 Hadoop
3.2 创建和管理 Catalog
Iceberg支持多种不同的Catalog类型,例如:Hive、Hadoop、亚马逊的AWS Glue和自定义Catalog。
根据不同配置,分为三种情况:
- 没有设置iceberg.catalog,默认使用HiveCatalog
| 配置项 |
说明 |
| iceberg.catalog.<catalog_name>.type |
Catalog的类型: hive, hadoop, 如果使用自定义Catalog,则不设置 |
| iceberg.catalog.<catalog_name>.catalog-impl |
Catalog的实现类, 如果上面的type没有设置,则此参数必须设置 |
| iceberg.catalog.<catalog_name>.<key> |
Catalog的其他配置项 |
- 设置了 iceberg.catalog的类型,使用指定的Catalog类型,如下表格:
- 设置 iceberg.catalog=location_based_table,直接通过指定的根路径来加载Iceberg表
3.1.1 默认使用 HiveCatalog
CREATE TABLE iceberg_test1 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler';
INSERT INTO iceberg_test1 values(1);
查看HDFS可以发现,表目录在默认的hive仓库路径下。
3.1.2 指定 Catalog 类型
1)使用 HiveCatalog
set iceberg.catalog.iceberg_hive.type=hive;
set iceberg.catalog.iceberg_hive.uri=thrift://hadoop1:9083;
set iceberg.catalog.iceberg_hive.clients=10;
set iceberg.catalog.iceberg_hive.warehouse=hdfs://hadoop1:8020/warehouse/iceberg-hive;
CREATE TABLE iceberg_test2 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
TBLPROPERTIES('iceberg.catalog'='iceberg_hive');
INSERT INTO iceberg_test2 values(1);
describe formatted iceberg_test2;
2)使用 HadoopCatalog
set iceberg.catalog.iceberg_hadoop.type=hadoop;
set iceberg.catalog.iceberg_hadoop.warehouse=hdfs://hadoop1:8020/warehouse/iceberg-hadoop;
CREATE TABLE iceberg_test3 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://hadoop1:8020/warehouse/iceberg-hadoop/default/iceberg_test3'
TBLPROPERTIES('iceberg.catalog'='iceberg_hadoop');
INSERT INTO iceberg_test3 values(1);
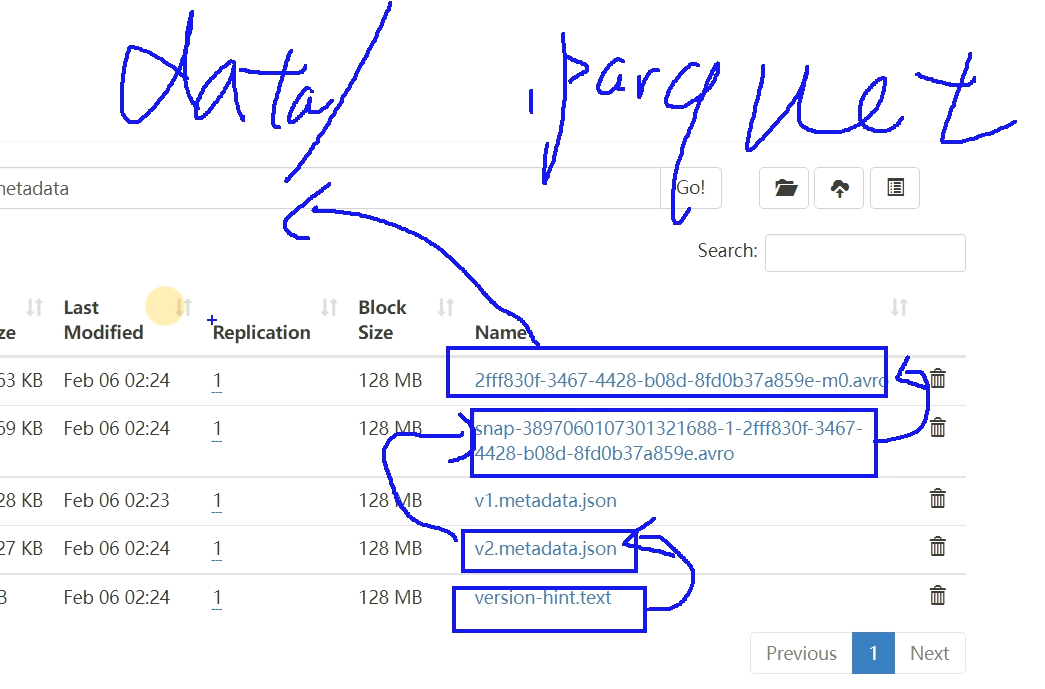
3.1.3 指定路径加载
如果HDFS中已经存在iceberg格式表,我们可以通过在Hive中创建Icerberg格式表指定对应的location路径映射数据。
CREATE EXTERNAL TABLE iceberg_test4 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://hadoop1:8020/warehouse/iceberg-hadoop/default/iceberg_test3'
TBLPROPERTIES ('iceberg.catalog'='location_based_table');
3.3 基本操作
3.3.1 创建表
1)创建外部表
CREATE EXTERNAL TABLE iceberg_create1 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler';
describe formatted iceberg_create1;
2)创建内部表
CREATE TABLE iceberg_create2 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler';
describe formatted iceberg_create2;
3)创建分区表
CREATE EXTERNAL TABLE iceberg_create3 (id int,name string)
PARTITIONED BY (age int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler';
describe formatted iceberg_create3;
Hive语法创建分区表,不会在HMS中创建分区,而是将分区数据转换为Iceberg标识分区。这种情况下不能使用Iceberg的分区转换,例如:days(timestamp),如果想要使用Iceberg格式表的分区转换标识分区,需要使用Spark或者Flink引擎创建表。
3.3.2 修改表
只支持HiveCatalog表修改表属性,Iceberg表属性和Hive表属性存储在HMS中是同步的。
ALTER TABLE iceberg_create1 SET TBLPROPERTIES('external.table.purge'='FALSE');
external.table.purge 如果为true的话,在删除外部表的时候会删除数据,默认为true,为了安全起见修改为false.
3.3.3 插入表
支持标准单表INSERT INTO操作
INSERT INTO iceberg_create2 VALUES (1);
INSERT INTO iceberg_create1 select * from iceberg_create2;
在HIVE 3.x中,INSERT OVERWRITE虽然能执行,但其实是追加。
3.3.4 删除表
DROP TABLE iceberg_create1;
第4章 与 Spark SQL集成
4.1 环境准备
4.1.1 安装 Spark
1)Spark与Iceberg的版本对应关系如下
| Spark 版本 |
Iceberg 版本 |
| 2.4 |
0.7.0-incubating – 1.1.0 |
| 3.0 |
0.9.0 – 1.0.0 |
| 3.1 |
0.12.0 – 1.1.0 |
| 3.2 |
0.13.0 – 1.1.0 |
| 3.3 |
0.14.0 – 1.1.0 |
2)上传并解压Spark安装包
tar -zxvf spark-3.3.1-bin-hadoop3.tgz -C /opt/module/
mv /opt/module/spark-3.3.1-bin-hadoop3 /opt/module/spark-3.3.1
3)配置环境变量
sudo vim /etc/profile.d/my_env.sh
export SPARK_HOME=/opt/module/spark-3.3.1
export PATH=$PATH:$SPARK_HOME/bin
source /etc/profile.d/my_env.sh
4)拷贝iceberg的jar包到Spark的jars目录
cp /opt/software/iceberg/iceberg-spark-runtime-3.3_2.12-1.1.0.jar /opt/module/spark-3.3.1/jars
4.1.2 启动 Hadoop
(略)
4.2 Spark 配置 Catalog
Spark中支持两种Catalog的设置:hive和hadoop,Hive Catalog就是Iceberg表存储使用Hive默认的数据路径,Hadoop Catalog需要指定Iceberg格式表存储路径。
vim spark-defaults.conf
4.2.1 Hive Catalog
spark.sql.catalog.hive_prod = org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.hive_prod.type = hive
spark.sql.catalog.hive_prod.uri = thrift://hadoop1:9083
use hive_prod.db;
use hive_prod.default;
4.2.2 Hadoop Catalog
spark.sql.catalog.hadoop_prod = org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.hadoop_prod.type = hadoop
spark.sql.catalog.hadoop_prod.warehouse = hdfs://hadoop1:8020/warehouse/spark-iceberg
use hadoop_prod.db;
比如: use hadoop_prod.default;
在 Spark SQL 中,如果您还没有创建任何数据库(
db_name),您不能直接使用USE hadoop_prod.db_name;命令,因为该数据库尚不存在。创建数据库和表的步骤
启动 Spark SQL CLI:
首先,按您之前的方式启动 Spark SQL CLI:
spark-sql --conf spark.sql.catalog.hadoop_prod=org.apache.iceberg.spark.SparkCatalog \ --conf spark.sql.catalog.hadoop_prod.type=hadoop \ --conf spark.sql.catalog.hadoop_prod.warehouse=hdfs://hadoop1:8020/warehouse/spark-iceberg创建数据库:
在 Spark SQL CLI 中,您可以使用
CREATE DATABASE命令来创建一个新的数据库。例如,创建一个名为db_name的数据库:CREATE DATABASE hadoop_prod.db_name;使用数据库:
一旦创建了数据库,您就可以使用
USE命令切换到这个数据库:USE hadoop_prod.db_name;创建表:
在选择了数据库后,您可以创建表。例如:
CREATE TABLE table_name ( id INT, name STRING ) USING iceberg;插入和查询数据:
您现在可以插入数据并查询表:
INSERT INTO table_name VALUES (1, 'Alice'), (2, 'Bob'); SELECT * FROM table_name;完整示例
以下是您在 Spark SQL CLI 中的完整操作流程:
-- 创建数据库 CREATE DATABASE hadoop_prod.db_name; -- 使用数据库 USE hadoop_prod.db_name; -- 创建表 CREATE TABLE table_name ( id INT, name STRING ) USING iceberg; -- 插入数据 INSERT INTO table_name VALUES (1, 'Alice'), (2, 'Bob'); -- 查询数据 SELECT * FROM table_name;注意事项
- 确保在执行
CREATE DATABASE和其他 SQL 命令时,您已经在 Spark SQL CLI 中,并且连接到正确的 Iceberg catalog。- 如果您在创建数据库或表时遇到权限问题,请确保您有足够的权限在指定的 HDFS 路径下创建相应的目录和文件。
-- 创建数据库
CREATE DATABASE hadoop_prod.db_name;-- 使用数据库
USE hadoop_prod.db_name;-- 确认当前数据库
SELECT current_database(); -- 应返回 hadoop_prod.db_name-- 创建表
CREATE TABLE table_name (
id INT,
name STRING
) USING iceberg;-- 列出当前数据库的表
SHOW TABLES; -- 应显示 table_name
4.3 SQL 操作
4.3.1 创建表
use hadoop_prod;
create database default;
use default;
CREATE TABLE hadoop_prod.default.sample1 (
id bigint COMMENT 'unique id',
data string)
USING iceberg
- PARTITIONED BY (partition-expressions) :配置分区
- LOCATION '(fully-qualified-uri)' :指定表路径
- COMMENT 'table documentation' :配置表备注
- TBLPROPERTIES ('key'='value', ...) :配置表属性
表属性:Configuration - Apache Iceberg™
对Iceberg表的每次更改都会生成一个新的元数据文件(json文件)以提供原子性。默认情况下,旧元数据文件作为历史文件保存不会删除。
如果要自动清除元数据文件,在表属性中设置write.metadata.delete-after-commit.enabled=true。这将保留一些元数据文件(直到write.metadata.previous-versions-max),并在每个新创建的元数据文件之后删除旧的元数据文件。
1)创建分区表
(1)分区表
CREATE TABLE hadoop_prod.default.sample2 (
id bigint,
data string,
category string)
USING iceberg
PARTITIONED BY (category)
(2)创建隐藏分区表
CREATE TABLE hadoop_prod.default.sample3 (
id bigint,
data string,
category string,
ts timestamp)
USING iceberg
PARTITIONED BY (bucket(16, id), days(ts), category)
支持的转换有:
- years(ts):按年划分
- months(ts):按月划分
- days(ts)或date(ts):等效于dateint分区
- hours(ts)或date_hour(ts):等效于dateint和hour分区
- bucket(N, col):按哈希值划分mod N个桶
- truncate(L, col):按截断为L的值划分
字符串被截断为给定的长度
整型和长型截断为bin: truncate(10, i)生成分区0,10,20,30,…
2)使用 CTAS 语法建表
CREATE TABLE hadoop_prod.default.sample4
USING iceberg
AS SELECT * from hadoop_prod.default.sample3
不指定分区就是无分区,需要重新指定分区、表属性:
CREATE TABLE hadoop_prod.default.sample5
USING iceberg
PARTITIONED BY (bucket(8, id), hours(ts), category)
TBLPROPERTIES ('key'='value')
AS SELECT * from hadoop_prod.default.sample3
3)使用 Replace table