B站账号@狼群里的小杨,记得点赞收藏加关注,一键三连哦!
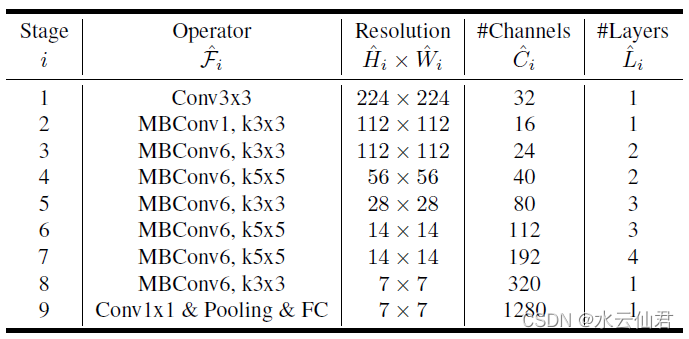
EfficientNet
代码
这是一个用包含40个类别的垃圾数据集做的开放场景实验。训练过程中仅使用24个训练类,测试时使用40个垃圾类别。
garbage数据集下载
首先是训练的代码。
task_garbage.py
'''
@File :task_gabage.py
@Author:cjh
@Date :2022/1/16 14:45
@Desc :
'''
import random
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torch.backends.cudnn as cudnn
import torchvision
import numpy as np
import torchvision.transforms as transforms
from torchvision.transforms import autoaugment
import os
import argparse
import sys
import warnings
warnings.filterwarnings("ignore")
# os.chdir(os.path.dirname('X:/PyCharm/211211-DL-OSR/DL_OSR/model/OpenMax'))
# sys.path.append("../..")
from torch.optim import lr_scheduler
import backbones.cifar10 as models
from datasets import GARBAGE40_Dataset
from utils import adjust_learning_rate, progress_bar, Logger, mkdir_p, Evaluation
from openmax import compute_train_score_and_mavs_and_dists,fit_weibull,openmax
from Modelbuilder import Network
from Plotter import plot_feature
from garbage_transform import Resize, Cutout, RandomErasing
from garbage_loss import LabelSmoothSoftmaxCE, LabelSmoothingLoss, FocalLoss
from checkpoints import efficientnet
# from pytorch_toolbelt import losses as L
parser=argparse.ArgumentParser()
parser.add_argument('--lr',default=0.01,type=float,help='learning rate')
# ./checkpoints/garbage/ResNet/ResNet18.pth
parser.add_argument('--resume',default=None,type=str,metavar='PATH',help='path to load lastest pth')
parser.add_argument('--arch',default='EfficientNet_B5',type=str,help='choosing network')
parser.add_argument('--bs',default=8,type=int,help='batch size')
parser.add_argument('--es',default=40,type=int,help='epoches')
parser.add_argument('--train_class_num',default=24,type=int,help='classes used in training')
parser.add_argument('--test_class_num',default=40,type=int,help='classes used in testing')
parser.add_argument('--includes_all_train_class',default=True,action='store_true',
help='testing uses all known classes')
parser.add_argument('--embed_dim', default=2, type=int, help='embedding feature dimension')
parser.add_argument('--evaluate',default=False,action='store_true',help='evaluating')
parser.add_argument('--weibull_tail', default=20, type=int, help='Classes used in testing')
parser.add_argument('--weibull_alpha', default=5, type=int, help='Classes used in testing')
parser.add_argument('--weibull_threshold', default=0.9, type=float, help='Classes used in testing')
# Parameters for stage plotting
# parser.add_argument('--plot', default=False, action='store_true', help='Plotting the training set.')
# parser.add_argument('--plot_max', default=0, type=int, help='max examples to plot in each class, 0 indicates all.')
# parser.add_argument('--plot_quality', default=200, type=int, help='DPI of plot figure')
args=parser.parse_args()
def main():
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(device)
best_acc = 0 # best test accuracy
start_epoch = 0 # start from epoch 0 or last checkpoint epoch
# checkpoint
args.checkpoint = './checkpoints/garbage/' + args.arch
if not os.path.isdir(args.checkpoint):
mkdir_p(args.checkpoint)
# folder to save figures
args.plotfolder = './checkpoints/garbage/' + args.arch + '/plotter'
if not os.path.isdir(args.plotfolder):
mkdir_p(args.plotfolder)
# Data
print('==> Preparing data..')
picture_size = 256
train_transforms = transforms.Compose([
Resize((int(288 * (256 / 224)), int(288 * (256 / 224)))),
transforms.CenterCrop((picture_size, picture_size)),
transforms.RandomAffine(degrees=0, translate=(0.05, 0.05)),
transforms.RandomVerticalFlip(),
autoaugment.AutoAugment(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
Cutout(probability=0.5, size=64, mean=[0.0, 0.0, 0.0]),
RandomErasing(probability=0.0, mean=[0.485, 0.456, 0.406]),
])
test_transforms = transforms.Compose([
Resize((int(288 * (256 / 224)), int(288 * (256 / 224)))),
transforms.CenterCrop((picture_size, picture_size)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
random.seed(42)
train_classes = random.sample(range(0, 40), args.train_class_num)
test_classes=train_classes+[999]
trainset = GARBAGE40_Dataset(root='../../data/garbage', train=True,
transform=train_transforms,
train_class_num=args.train_class_num, test_class_num=args.test_class_num,
includes_all_train_class=args.includes_all_train_class,
train_classes=train_classes)
testset = GARBAGE40_Dataset(root='../../data/garbage', train=False,
transform=test_transforms,
train_class_num=args.train_class_num, test_class_num=args.test_class_num,
includes_all_train_class=args.includes_all_train_class,
train_classes=train_classes)
# data loader
trainloader = torch.utils.data.DataLoader(trainset, batch_size=args.bs, shuffle=True, num_workers=0)
testloader = torch.utils.data.DataLoader(testset, batch_size=args.bs, shuffle=False, num_workers=0)
#Model
# net=Network(backbone=args.arch,num_classes=args.train_class_num, embed_dim=args.embed_dim)
# fea_dim = net.classifier.in_features
# net = net.to(device)
if args.arch=='ResNet18':
net = torchvision.models.resnet18(pretrained=True).to(device)
model_wight_path = "checkpoints/garbage/ResNet18/best_model.pth"
assert os.path.exists(model_wight_path), "file {} dose not exist.".format(model_wight_path) # 若路径不存在,则打印信息
net.load_state_dict(torch.load(model_wight_path, map_location=device), strict=False)
net.fc = nn.Sequential(
nn.Linear(net.fc.in_features, 256),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(256, args.train_class_num)
)
if args.arch == 'ResNet50':
net = torchvision.models.resnet50(pretrained=True).to(device)
model_wight_path = "checkpoints/garbage/ResNet50/best_model.pth"
assert os.path.exists(model_wight_path), "file {} dose not exist.".format(model_wight_path) # 若路径不存在,则打印信息
net.load_state_dict(torch.load(model_wight_path, map_location=device), strict=False)
net.fc = nn.Sequential(
nn.Linear(net.fc.in_features, 256),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(256, args.train_class_num)
)
if args.arch == 'EfficientNet_B5':
# net = torchvision.models.efficientnet_b5(pretrained=True).to(device)
net = efficientnet.efficientnet_b5().to(device)
# model_wight_path = "checkpoints/garbage/EfficientNet_B5/efficientnetb5.pth"
model_wight_path = "checkpoints/garbage/EfficientNet_B5/best_model.pth"
assert os.path.exists(model_wight_path), "file {} dose not exist.".format(model_wight_path) # 若路径不存在,则打印信息
net.load_state_dict(torch.load(model_wight_path, map_location=device), strict=False)
net.classifier= nn.Sequential(
nn.Dropout(p=0.4, inplace=True),
nn.Linear(2048, args.train_class_num),
)
if args.arch == 'EfficientNet_B7':
# net = torchvision.models.efficientnet_b7(pretrained=True).to(device)
net = efficientnet.efficientnet_b7().to(device)
net.classifier= nn.Sequential(
nn.Dropout(p=0.4, inplace=True),
nn.Linear(2048, args.train_class_num),
)
if args.arch == 'ResNext101_32x16d_wsl':
net = torch.hub.load('facebookresearch/WSL-Images', 'resnext101_32x16d_wsl')
net.fc = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(2048, args.train_class_num)
)
if args.arch == 'Resnext101_32x8d_wsl':
net = torch.hub.load('facebookresearch/WSL-Images', 'resnext101_32x8d_wsl')
net.fc = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(2048, args.train_class_num)
)
if args.arch == 'Resnext50_32x4d':
net = torchvision.models.resnext50_32x4d(pretrained=True).to(device)
net.fc = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(2048, args.train_class_num)
)
# from efficientnet_pytorch import EfficientNet
# model = EfficientNet.from_pretrained('efficientnet-b0')
# model = EfficientNet.from_pretrained(,num_classes=args.train_class_num)
if args.arch == 'EfficientNet_B3':
net = torchvision.models.efficientnet_b3(pretrained=True).to(device)
net.classifier= nn.Sequential(
nn.Linear(1536, 256),
nn.ReLU(),
nn.Dropout(p=0.4),
nn.Linear(256, args.train_class_num),
# nn.Dropout(p=0.4, inplace=True),
# nn.Linear(1024, args.train_class_num),
)
if device == 'cuda':
net = torch.nn.DataParallel(net)
cudnn.benchmark = True
if args.resume!=None:
# Load checkpoint.
if os.path.isfile(args.resume):
print('==> Resuming from checkpoint..')
#for cpu load cuda model
checkpoint = torch.load(args.resume,map_location=torch.device('cpu'))
net.load_state_dict({k.replace('module.', ''): v for k, v in checkpoint['net'].items()})
#for gpu load cuda model for cpu load cpu model
# checkpoint = torch.load(args.resume)
# net.load_state_dict(checkpoint['net'])
# best_acc = checkpoint['acc']
# print("BEST_ACCURACY: "+str(best_acc))
start_epoch = checkpoint['epoch']
logger = Logger(os.path.join(args.checkpoint, 'log.txt'), resume=True)
else:
print("=> no checkpoint found at '{}'".format(args.resume))
else:
logger = Logger(os.path.join(args.checkpoint, 'log.txt'))
logger.set_names(['Epoch', 'Learning Rate', 'Train Loss','Train Acc.', 'Test Loss', 'Test Acc.'])
criterion = nn.CrossEntropyLoss()
# criterion = LabelSmoothSoftmaxCE(lb_pos=0.9, lb_neg=5e-3)
# criterion = LabelSmoothingLoss(classes=args.train_class_num, smoothing=0.1)
# criterion = FocalLoss(alpha=0.25)
optimizer = optim.SGD(net.parameters(), lr=args.lr, momentum=0.9, weight_decay=5e-4)
# optimizer = optim.RAdam(net.parameters(),lr=args.lr,betas=(0.9, 0.999), eps=1e-8,weight_decay=5e-4)
# scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, mode='max', factor=0.7, patience=3, verbose=True)
scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.2, patience=2, verbose=False)
scheduler = lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=3, T_mult=2)
scheduler = lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=2, T_mult=2,eta_min = 1e-5)
scheduler = lr_scheduler.StepLR(optimizer, step_size=8, gamma=0.5)
# epoch=0
best_ac=0
if not args.evaluate:
for epoch in range(start_epoch, args.es):
print('\nEpoch: %d Learning rate: %f' % (epoch+1, optimizer.param_groups[0]['lr']))
# adjust_learning_rate(optimizer, epoch, args.lr, step=20)
train_loss, train_acc = train(net, trainloader, optimizer, criterion, device, train_classes)
if epoch == args.es - 1:
save_model(net, None, epoch, os.path.join(args.checkpoint,'last_model.pth'))
test_loss, test_acc = 0, 0
try:
test_loss, test_acc = test(epoch, net, trainloader, testloader, criterion, device, test_classes)
except:
pass
# scheduler.step(test_loss)
scheduler.step(train_loss)
if best_ac<test_acc:
best_ac=test_acc
print("The best Acc: ",best_ac)
# save_model(net, None, epoch, os.path.join(args.checkpoint, 'best_model.pth'))
torch.save(net.state_dict(), os.path.join(args.checkpoint, 'best_model.pth'))
# save_model(net, best_ac, epoch, os.path.join(args.checkpoint, 'best_model.pth'))
#
logger.append([epoch+1, optimizer.param_groups[0]['lr'], train_loss, train_acc, test_loss, test_acc])
# plot_feature(net, trainloader, device, args.plotfolder,train_classes, epoch=epoch,
# plot_class_num=args.train_class_num, maximum=args.plot_max, plot_quality=args.plot_quality)
# if (epoch+1)%20==0:
# try:
# test(epoch, net, trainloader, testloader, criterion, device,test_classes)
# except:
# pass
test(99999, net, trainloader, testloader, criterion, device, test_classes)
# plot_feature(net, testloader, device, args.plotfolder,train_classes, epoch="test",
# plot_class_num=args.train_class_num+1, maximum=args.plot_max, plot_quality=args.plot_quality)
logger.close()
# Training
def train(net,trainloader,optimizer,criterion,device,train_classes):
net.train()
train_loss = 0
correct = 0
total = 0
for batch_idx, (inputs, targets) in enumerate(trainloader):
onehot_targets_index=[train_classes.index(i) for i in targets]
targets=torch.LongTensor(onehot_targets_index)
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad()
outputs = net(inputs)
# onehot_targets=torch.zeros((outputs.shape[0],outputs.shape[1]))
# onehot_targets[range(outputs.shape[0]), onehot_targets_index]=1
loss = criterion(outputs, targets)
# loss = torch.nn.functional.cross_entropy(outputs, targets)
loss.backward()
optimizer.step()
train_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
progress_bar(batch_idx, len(trainloader), 'Loss: %.3f | Acc: %.3f%% (%d/%d)'
% (train_loss/(batch_idx+1), 100.*correct/total, correct, total))
return train_loss/(batch_idx+1), correct/total
def test(epoch, net, trainloader, testloader, criterion, device, test_classes):
net.eval()
test_loss = 0
correct = 0
total = 0
scores, labels = [], []
with torch.no_grad():
for batch_idx, (inputs, targets) in enumerate(testloader):
onehot_targets_index = [test_classes.index(i) for i in targets]
targets = torch.LongTensor(onehot_targets_index)
# image_2 = transforms.RandomAffine(degrees=0, translate=(0.05, 0.05))(inputs).to(device)
# image_3 = transforms.RandomHorizontalFlip()(inputs).to(device)
# image_4 = Cutout(probability=0.5, size=64, mean=[0.0, 0.0, 0.0])(inputs).to(device)
# image_5 = transforms.RandomVerticalFlip()(inputs).to(device)
inputs, targets = inputs.to(device), targets.to(device)
# output1 = net(inputs)
# output2 = net(image_2)
# output3 = net(image_3)
# output4 = net(image_4)
# output5 = net(image_5)
outputs = net(inputs)
# outputs = (output1+output2+output3+output4+output5)/5
# loss = criterion(outputs, targets)
# test_loss += loss.item()
_, predicted = outputs.max(1)
scores.append(outputs)
labels.append(targets)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
progress_bar(batch_idx, len(testloader))
# Get the prdict results.
scores = torch.cat(scores,dim=0).cpu().numpy()
labels = torch.cat(labels,dim=0).cpu().numpy()
scores = np.array(scores)[:, np.newaxis, :]
labels = np.array(labels)
if args.train_class_num != args.test_class_num:
# Fit the weibull distribution from training data.
print("Fittting Weibull distribution...")
_, mavs, dists = compute_train_score_and_mavs_and_dists(args.train_class_num, trainloader, device, net, test_classes)
categories = list(range(0, args.train_class_num))
weibull_model = fit_weibull(mavs, dists, categories, args.weibull_tail, "euclidean")
pred_softmax, pred_softmax_threshold, pred_openmax = [], [], []
score_softmax, score_openmax = [], []
for score in scores:
so, ss = openmax(weibull_model, categories, score,
0.5, args.weibull_alpha, "euclidean")
# print(f"so {so} \n ss {ss}")# openmax_prob, softmax_prob
pred_softmax.append(np.argmax(ss))
pred_softmax_threshold.append(np.argmax(ss) if np.max(ss) >= args.weibull_threshold else args.train_class_num)
pred_openmax.append(np.argmax(so) if np.max(so) >= args.weibull_threshold else args.train_class_num)
score_softmax.append(ss)
score_openmax.append(so)
print("Evaluation...")
# test_loss += criterion(torch.Tensor(score_softmax), torch.from_numpy(labels))
test_loss += criterion(torch.Tensor(score_openmax), torch.from_numpy(labels))
eval_softmax = Evaluation(pred_softmax, labels, score_softmax)
eval_softmax_threshold = Evaluation(pred_softmax_threshold, labels, score_softmax)
eval_openmax = Evaluation(pred_openmax, labels, score_openmax)
torch.save(eval_softmax, os.path.join(args.checkpoint, 'eval_softmax.pkl'))
torch.save(eval_softmax_threshold, os.path.join(args.checkpoint, 'eval_softmax_threshold.pkl'))
torch.save(eval_openmax, os.path.join(args.checkpoint, 'eval_openmax.pkl'))
print(f"Softmax accuracy is %.3f" % (eval_softmax.accuracy))
print(f"Softmax F1 is %.3f" % (eval_softmax.f1_measure))
print(f"Softmax f1_macro is %.3f" % (eval_softmax.f1_macro))
print(f"Softmax f1_macro_weighted is %.3f" % (eval_softmax.f1_macro_weighted))
print(f"Softmax area_under_roc is %.3f" % (eval_softmax.area_under_roc))
print(f"_________________________________________")
print(f"SoftmaxThreshold accuracy is %.3f" % (eval_softmax_threshold.accuracy))
print(f"SoftmaxThreshold F1 is %.3f" % (eval_softmax_threshold.f1_measure))
print(f"SoftmaxThreshold f1_macro is %.3f" % (eval_softmax_threshold.f1_macro))
print(f"SoftmaxThreshold f1_macro_weighted is %.3f" % (eval_softmax_threshold.f1_macro_weighted))
print(f"SoftmaxThreshold area_under_roc is %.3f" % (eval_softmax_threshold.area_under_roc))
print(f"_________________________________________")
print(f"OpenMax accuracy is %.3f" % (eval_openmax.accuracy))
print(f"OpenMax F1 is %.3f" % (eval_openmax.f1_measure))
print(f"OpenMax f1_macro is %.3f" % (eval_openmax.f1_macro))
print(f"OpenMax f1_macro_weighted is %.3f" % (eval_openmax.f1_macro_weighted))
print(f"OpenMax area_under_roc is %.3f" % (eval_openmax.area_under_roc))
print(f"_________________________________________")
with open(os.path.join(args.checkpoint, "garbage.csv"),"ab") as f:
np.savetxt(f,np.array([epoch]))
np.savetxt(f, np.array([eval_softmax.f1_measure, eval_softmax.f1_macro,
eval_softmax.f1_macro_weighted,
eval_softmax.area_under_roc]).reshape(1, 4),
fmt='%.4f')
np.savetxt(f, np.array([eval_softmax_threshold.f1_measure,
eval_softmax_threshold.f1_macro,
eval_softmax_threshold.f1_macro_weighted,
eval_softmax_threshold.area_under_roc
]).reshape(1, 4),
fmt='%.4f')
np.savetxt(f, eval_softmax_threshold.confusion_matrix, fmt='%d')
np.savetxt(f, np.array([eval_openmax.f1_measure, eval_openmax.f1_macro,
eval_openmax.f1_macro_weighted,
eval_openmax.area_under_roc]).reshape(1, 4),
fmt='%.4f')
np.savetxt(f, eval_openmax.confusion_matrix, fmt='%d')
else:
def softmax(x):
e_x = np.exp(x - np.max(x))
return e_x / e_x.sum()
pred_softmax,score_softmax=[],[]
for score in scores:
softmax_prob = softmax(np.array(score.ravel()))
pred_softmax.append(np.argmax(softmax_prob))
score_softmax.append(softmax_prob)
eval_softmax = Evaluation(pred_softmax, labels, score_softmax)
print(f"Softmax accuracy is %.3f" % (eval_softmax.accuracy))
print(f"Softmax F1 is %.3f" % (eval_softmax.f1_measure))
print(f"Softmax f1_macro is %.3f" % (eval_softmax.f1_macro))
print(f"Softmax f1_macro_weighted is %.3f" % (eval_softmax.f1_macro_weighted))
print(f"Softmax area_under_roc is %.3f" % (eval_softmax.area_under_roc))
print(f"_________________________________________")
with open(os.path.join(args.checkpoint, "garbage_closed.csv"),"ab") as f:
np.savetxt(f,np.array([epoch]))
np.savetxt(f, np.array([eval_softmax.f1_measure, eval_softmax.f1_macro,
eval_softmax.f1_macro_weighted,
eval_softmax.area_under_roc]).reshape(1, 4),
fmt='%.4f')
np.savetxt(f, eval_softmax.confusion_matrix, fmt='%d')
return test_loss/(batch_idx+1), correct/total
def save_model(net, acc, epoch, path):
print('Saving..')
state = {
'net': net.state_dict(),
'testacc': acc,
'epoch': epoch,
}
# torch.save(state, path)
torch.save(net.state_dict(), path)
if __name__=="__main__":
main()
efficientnet.py
'''
python3.7
-*- coding: UTF-8 -*-
@Project -> File :pythonProject -> efficientNet
@IDE :PyCharm
@Author :YangShouWei
@USER:
@Date :2022/3/15 21:41:59
@LastEditor:
'''
import math
import copy
from functools import partial
from collections import OrderedDict
from typing import Optional, Callable
import torch
from torch import nn
from torch import Tensor
from torch.nn import functional as F
def _make_divisible(ch, divisior=8, min_ch=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
"""
if min_ch is None:
min_ch = divisior
new_ch = max(min_ch, int(ch + divisior / 2) // divisior * divisior)
# Make sure that round down does not go down by more than 10%
if new_ch < 0.9 * ch:
new_ch += divisior
return new_ch
def drop_path(x, drop_prob: float = 0., training:bool = False):
"""
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
This function is taken from the rwightman
"""
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensor, not just 2D ConvNets
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() #binarize
output = x.div(keep_prob) * random_tensor
return output
class DropPath(nn.Module):
"""
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"""
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
class ConvBNActivation(nn.Sequential):
def __init__(self,
in_planes: int,
out_planes:int,
kernel_size : int = 3,
stride: int = 1,
groups: int = 1,
norm_layer: Optional[Callable[..., nn.Module]] = None,
activation_layer:Optional[Callable[..., nn.Module]] = None):
padding = (kernel_size - 1) // 2
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if activation_layer is None:
activation_layer = nn.SiLU
super(ConvBNActivation, self).__init__(nn.Conv2d(in_channels=in_planes,
out_channels=out_planes,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=False),
norm_layer(out_planes),
activation_layer())
class SqueezeExcitation(nn.Module):
def __init__(self,
input_c:int, # block input channel
expand_c:int, # block expand channel
squeeze_factor:int = 4):
super(SqueezeExcitation, self).__init__()
squeeze_c = input_c // squeeze_factor
self.fc1 = nn.Conv2d(expand_c,squeeze_c, 1)
self.ac1 = nn.SiLU()
self.fc2 = nn.Conv2d(squeeze_c, expand_c, 1)
self.ac2 = nn.Sigmoid()
def forward(self, x:Tensor):
scale = F.adaptive_avg_pool2d(x, output_size=(1, 1))
scale = self.fc1(scale)
scale = self.ac1(scale)
scale = self.fc2(scale)
scale = self.ac2(scale)
return scale * x
class InvertedResidualConfig:
#kernel_size, in_channel, out_channel, exp_ratio, strides, use_SE, drop_connect_rate
def __init__(self,
kernel: int,
input_c: int,
out_c: int,
expanded_ratio: int, # 1 or 6
stride: int, # 1 or 2
use_se: bool, # True
drop_rate: float,
index: str, #1a, 2a, 2b, ...
width_coefficient:float):
self.input_c = self.adjust_channels(input_c, width_coefficient)
self.kernel = kernel
self.expanded_c = self.input_c * expanded_ratio
self.out_c =self.adjust_channels(out_c, width_coefficient)
self.use_se = use_se
self.stride = stride
self.drop_rate = drop_rate
self.index = index
@staticmethod # 静态方法
def adjust_channels(channels: int, width_coefficient: float):
return _make_divisible(channels * width_coefficient, 8) # 通道数乘以倍率因子然后取最接近8的倍数的数
class InvertedResidual(nn.Module):
def __init__(self,
cnf:InvertedResidualConfig,
norm_layer: Callable[..., nn.Module]):
super(InvertedResidual, self).__init__()
if cnf.stride not in [1, 2]:
raise ValueError("illegal stride value")
self.use_res_connect = (cnf.stride == 1 and cnf.input_c == cnf.out_c) # 判断是否使用残差连接
layers = OrderedDict()
activation_layer = nn.SiLU
# expand
if cnf.expanded_c != cnf.input_c:
layers.update({"expand_conv": ConvBNActivation(cnf.input_c,
cnf.expanded_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=activation_layer)})
# depthwise
layers.update({"dwconv":ConvBNActivation(cnf.expanded_c,
cnf.expanded_c,
kernel_size=cnf.kernel,
stride=cnf.stride,
groups=cnf.expanded_c,
norm_layer=norm_layer,
activation_layer=activation_layer)})
if cnf.use_se:
layers.update({"se": SqueezeExcitation(cnf.input_c,
cnf.expanded_c)})
#project
layers.update({"project_conv": ConvBNActivation(cnf.expanded_c,
cnf.out_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=nn.Identity)}) # identity表示不做任何处理
self.block = nn.Sequential(layers)
self.out_channels = cnf.out_c
self.is_strided = cnf.stride > 1
#只有在使用shortcut连接时才使用dropout层
if self.use_res_connect and cnf.drop_rate > 0:
self.dropout = DropPath(cnf.drop_rate)
else:
self.dropout = nn.Identity()
def forward(self, x:Tensor) -> Tensor:
result = self.block(x)
result = self.dropout(result)
if self.use_res_connect:
result += x
return result
class EfficientNet(nn.Module):
def __init__(self,
width_coefficient: float,
depth_coefficient: float,
num_classes: int = 1000,
dropout_rate: float = 0.2,
drop_connect_rate: float = 0.2,
block: Optional[Callable[..., nn.Module]] = None,
norm_layer :Optional[Callable[..., nn.Module]] = None):
super(EfficientNet, self).__init__()
# kernel_size, in_channel, out_channel, exp_ratio, strides, use_SE, drop_connect_rate, repeats
deafault_cnf = [[3, 32, 16, 1, 1, True, drop_connect_rate, 1],
[3, 16, 24, 6, 2, True, drop_connect_rate, 2],
[5, 24, 40, 6, 2, True, drop_connect_rate, 2],
[3, 40, 80, 6, 2, True, drop_connect_rate, 3],
[5, 80, 112, 6, 1, True, drop_connect_rate, 3],
[5, 112, 192, 6, 2, True, drop_connect_rate, 4],
[3, 192, 320, 6, 1, True, drop_connect_rate, 1],]
def round_repeats(repeats):
"""Round number of repeats based on depth multiplier."""
return int(math.ceil(depth_coefficient * repeats))
if block is None:
block = InvertedResidual
if norm_layer is None:
norm_layer = partial(nn.BatchNorm2d, eps=1e-3, momentum=0.1)
adjust_channels = partial(InvertedResidualConfig.adjust_channels,
width_coefficient=width_coefficient)
#bneck inverted_residual_setting
bneck_conf = partial(InvertedResidualConfig, width_coefficient=width_coefficient)
b = 0
num_blocks = float(sum(round_repeats(i[-1]) for i in deafault_cnf))
inverted_residual_setting = []
for stage, args in enumerate(deafault_cnf):
cnf = copy.copy(args)
for i in range(round_repeats(cnf.pop(-1))):
if i > 0:
# stride equal 1 expcept first cnf
cnf[-3] = 1 #strides
cnf[1] = cnf[2] # input_channel equal output_channel
cnf[-1] = args[-2] * b / num_blocks # update dropout ratio
index = str(stage + 1) + chr(i + 97) # 1a, 2a, 2b
inverted_residual_setting.append(bneck_conf(*cnf, index))
b += 1
#create layers
layers = OrderedDict()
# first conv
layers.update({'stem_conv': ConvBNActivation(in_planes=3,
out_planes=adjust_channels(32),
kernel_size=3,
stride=2,
norm_layer=norm_layer)})
# building inverted residual blocks
for cnf in inverted_residual_setting:
layers.update({cnf.index: block(cnf, norm_layer)})
# build top
last_conv_input_c = inverted_residual_setting[-1].out_c
last_conv_output_c = adjust_channels(1280)
layers.update({"top": ConvBNActivation(in_planes=last_conv_input_c,
out_planes=last_conv_output_c,
kernel_size=1,
norm_layer=norm_layer
)})
self.features = nn.Sequential(layers)
self.avgpool = nn.AdaptiveAvgPool2d(1)
classifier = []
if dropout_rate > 0:
classifier.append(nn.Dropout(p=dropout_rate, inplace=True))
classifier.append(nn.Linear(last_conv_output_c, num_classes))
self.classifier = nn.Sequential(*classifier)
# initial weights
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out")
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def _forward_impl(self, x:Tensor):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def forward(self, x:Tensor) -> Tensor:
return self._forward_impl(x)
def efficientnet_b0(num_classes=1000):
return EfficientNet(width_coefficient=1.0, depth_coefficient=1.1, dropout_rate=0.2, num_classes=num_classes)
def efficientnet_b1(num_classes=1000):
return EfficientNet(width_coefficient=1.0, depth_coefficient=1.1, dropout_rate=0.2, num_classes=num_classes)
def efficientnet_b2(num_classes=1000):
return EfficientNet(width_coefficient=1.1, depth_coefficient=1.2, dropout_rate=0.3, num_classes=num_classes)
def efficientnet_b3(num_classes=1000):
return EfficientNet(width_coefficient=1.2, depth_coefficient=1.4, dropout_rate=0.3, num_classes=num_classes)
def efficientnet_b4(num_classes=1000):
return EfficientNet(width_coefficient=1.4, depth_coefficient=1.8, dropout_rate=0.4, num_classes=num_classes)
def efficientnet_b5(num_classes=1000):
return EfficientNet(width_coefficient=1.6, depth_coefficient=2.2, dropout_rate=0.4, num_classes=num_classes)
def efficientnet_b6(num_classes=1000):
return EfficientNet(width_coefficient=1.8, depth_coefficient=2.6, dropout_rate=0.5, num_classes=num_classes)
def efficientnet_b7(num_classes=1000):
return EfficientNet(width_coefficient=2.0, depth_coefficient=3.1, dropout_rate=0.5, num_classes=num_classes)
Openmax.py
import numpy as np
import scipy.spatial.distance as spd
import torch
import libmr
def calc_distance(query_score, mcv, eu_weight, distance_type='eucos'):
if distance_type == 'eucos':
query_distance = spd.euclidean(mcv, query_score) * eu_weight + \
spd.cosine(mcv, query_score)
elif distance_type == 'euclidean':
query_distance = spd.euclidean(mcv, query_score)
elif distance_type == 'cosine':
query_distance = spd.cosine(mcv, query_score)
else:
print("distance type not known: enter either of eucos, euclidean or cosine")
return query_distance
def fit_weibull(means, dists, categories, tailsize=20, distance_type='eucos'):
"""
Input:
means (C, channel, C)
dists (N_c, channel, C) * C
Output:
weibull_model : Perform EVT based analysis using tails of distances and save
weibull model parameters for re-adjusting softmax scores
"""
weibull_model = {}
for mean, dist, category_name in zip(means, dists, categories):
weibull_model[category_name] = {}
weibull_model[category_name]['distances_{}'.format(distance_type)] = dist[distance_type]
weibull_model[category_name]['mean_vec'] = mean
weibull_model[category_name]['weibull_model'] = []
for channel in range(mean.shape[0]):
mr = libmr.MR()
tailtofit = np.sort(dist[distance_type][channel, :])[-tailsize:]
mr.fit_high(tailtofit, len(tailtofit))
weibull_model[category_name]['weibull_model'].append(mr)
return weibull_model
def query_weibull(category_name, weibull_model, distance_type='eucos'):
return [weibull_model[category_name]['mean_vec'],
weibull_model[category_name]['distances_{}'.format(distance_type)],
weibull_model[category_name]['weibull_model']]
def compute_openmax_prob(scores, scores_u):
prob_scores, prob_unknowns = [], []
for s, su in zip(scores, scores_u):
channel_scores = np.exp(s)
channel_unknown = np.exp(np.sum(su))
total_denom = np.sum(channel_scores) + channel_unknown
prob_scores.append(channel_scores / total_denom)
prob_unknowns.append(channel_unknown / total_denom)
# Take channel mean
scores = np.mean(prob_scores, axis=0)
unknowns = np.mean(prob_unknowns, axis=0)
modified_scores = scores.tolist() + [unknowns]
return modified_scores
def softmax(x):
e_x = np.exp(x - np.max(x))
return e_x / e_x.sum()
def openmax(weibull_model, categories, input_score, eu_weight, alpha=10, distance_type='eucos'):
"""Re-calibrate scores via OpenMax layer
Output:
openmax probability and softmax probability
"""
nb_classes = len(categories)
ranked_list = input_score.argsort().ravel()[::-1][:alpha]
alpha_weights = [((alpha + 1) - i) / float(alpha) for i in range(1, alpha + 1)]
omega = np.zeros(nb_classes)
omega[ranked_list] = alpha_weights
scores, scores_u = [], []
for channel, input_score_channel in enumerate(input_score):
score_channel, score_channel_u = [], []
for c, category_name in enumerate(categories):
mav, dist, model = query_weibull(category_name, weibull_model, distance_type)
channel_dist = calc_distance(input_score_channel, mav[channel], eu_weight, distance_type)
wscore = model[channel].w_score(channel_dist)
modified_score = input_score_channel[c] * (1 - wscore * omega[c])#v^i(x)=v(x)*(1-welbull *(alpha-i)/alpha)
score_channel.append(modified_score)
score_channel_u.append(input_score_channel[c] - modified_score)#v^0(x)=sum(vi(x)*(1-wi(x)))
scores.append(score_channel)
scores_u.append(score_channel_u)
scores = np.asarray(scores)
scores_u = np.asarray(scores_u)
openmax_prob = np.array(compute_openmax_prob(scores, scores_u))
softmax_prob = softmax(np.array(input_score.ravel()))
return openmax_prob, softmax_prob
def compute_channel_distances(mavs, features, eu_weight=0.5):
"""
Input:
mavs (channel, C)
features: (N, channel, C)
Output:
channel_distances: dict of distance distribution from MAV for each channel.
"""
eucos_dists, eu_dists, cos_dists = [], [], []
for channel, mcv in enumerate(mavs): # Compute channel specific distances
eu_dists.append([spd.euclidean(mcv, feat[channel]) for feat in features])
cos_dists.append([spd.cosine(mcv, feat[channel]) for feat in features])
eucos_dists.append([spd.euclidean(mcv, feat[channel]) * eu_weight +
spd.cosine(mcv, feat[channel]) for feat in features])
return {'eucos': np.array(eucos_dists), 'cosine': np.array(cos_dists), 'euclidean': np.array(eu_dists)}
def compute_train_score_and_mavs_and_dists(train_class_num,trainloader, device, net, test_classes):
scores = [[] for _ in range(train_class_num)]
with torch.no_grad():
for batch_idx, (inputs, targets) in enumerate(trainloader):
onehot_targets_index = [test_classes.index(i) for i in targets]
targets = torch.LongTensor(onehot_targets_index)
inputs, targets = inputs.to(device), targets.to(device)
# this must cause error for cifar10
outputs = net(inputs)
for score, t in zip(outputs, targets):
# print(f"torch.argmax(score) is {torch.argmax(score)}, t is {t}")
if torch.argmax(score) == t:
scores[t].append(score.unsqueeze(dim=0).unsqueeze(dim=0))
scores = [torch.cat(x).cpu().numpy() for x in scores] # (N_c, 1, C) * C
mavs = np.array([np.mean(x, axis=0) for x in scores]) # (C, 1, C)
dists = [compute_channel_distances(mcv, score) for mcv, score in zip(mavs, scores)]
return scores, mavs, dists
evaluation.py
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix, f1_score, \
classification_report, precision_recall_fscore_support, roc_auc_score
from sklearn.preprocessing import OneHotEncoder
# import sklearn.metrics.ConfusionMatrixDisplay
class Evaluation(object):
"""Evaluation class based on python list"""
def __init__(self, predict, label,prediction_scores = None):
self.predict = predict
self.label = label
self.prediction_scores = prediction_scores
self.accuracy = self._accuracy()
self.f1_measure = self._f1_measure()
self.f1_macro = self._f1_macro()
self.f1_macro_weighted = self._f1_macro_weighted()
self.precision, self.recall = self._precision_recall(average='micro')
self.precision_macro, self.recall_macro = self._precision_recall(average='macro')
self.precision_weighted, self.recall_weighted = self._precision_recall(average='weighted')
self.confusion_matrix = self._confusion_matrix()
if self.prediction_scores is not None:
self.area_under_roc = self._area_under_roc(prediction_scores)
pass
def _accuracy(self) -> float:
"""
Returns the accuracy score of the labels and predictions.
:return: float
"""
assert len(self.predict) == len(self.label)
correct = (np.array(self.predict) == np.array(self.label)).sum()
return float(correct)/float(len(self.predict))
def _f1_measure(self) -> float:
"""
Returns the F1-measure with a micro average of the labels and predictions.
:return: float
"""
assert len(self.predict) == len(self.label)
return f1_score(self.label, self.predict, average='micro')
def _f1_macro(self) -> float:
"""
Returns the F1-measure with a macro average of the labels and predictions.
:return: float
"""
assert len(self.predict) == len(self.label)
return f1_score(self.label, self.predict, average='macro')
def _f1_macro_weighted(self) -> float:
"""
Returns the F1-measure with a weighted macro average of the labels and predictions.
:return: float
"""
assert len(self.predict) == len(self.label)
return f1_score(self.label, self.predict, average='weighted')
def _precision_recall(self, average) -> (float, float):
"""
Returns the precision and recall scores for the label and predictions. Observes the average type.
:param average: string, [None (default), ‘micro’, ‘macro’, ‘samples’, ‘weighted’].
For explanations of each type of average see the documentation for
`sklearn.metrics.precision_recall_fscore_support`
:return: float, float: representing the precision and recall scores respectively
"""
assert len(self.predict) == len(self.label)
precision, recall, _, _ = precision_recall_fscore_support(self.label, self.predict, average=average)
return precision, recall
def _area_under_roc(self, prediction_scores: np.array = None, multi_class='ovo') -> float:
"""
Area Under Receiver Operating Characteristic Curve
:param prediction_scores: array-like of shape (n_samples, n_classes). The multi-class ROC curve requires
prediction scores for each class. If not specified, will generate its own prediction scores that assume
100% confidence in selected prediction.
:param multi_class: {'ovo', 'ovr'}, default='ovo'
'ovo' computes the average AUC of all possible pairwise combinations of classes.
'ovr' Computes the AUC of each class against the rest.
:return: float representing the area under the ROC curve
"""
label, predict = self.label, self.predict
one_hot_encoder = OneHotEncoder(sparse=False, handle_unknown='ignore')
one_hot_encoder.fit(np.array(label).reshape(-1, 1))
true_scores = one_hot_encoder.transform(np.array(label).reshape(-1, 1))
if prediction_scores is None:
prediction_scores = one_hot_encoder.transform(np.array(predict).reshape(-1, 1))
# assert prediction_scores.shape == true_scores.shape
# return roc_auc_score(true_scores, prediction_scores, multi_class=multi_class)
return roc_auc_score(true_scores, prediction_scores)
def _confusion_matrix(self, normalize=None) -> np.array:
"""
Returns the confusion matrix corresponding to the labels and predictions.
:param normalize: {‘true’, ‘pred’, ‘all’}, default=None.
Normalizes confusion matrix over the true (rows), predicted (columns) conditions or all the population.
If None, confusion matrix will not be normalized.
:return:
"""
assert len(self.predict) == len(self.label)
# return confusion_matrix(self.label, self.predict, normalize=normalize)
return confusion_matrix(self.label, self.predict)
def plot_confusion_matrix(self, labels: [str] = None, normalize=None, ax=None, savepath=None) -> None:
"""
:param labels: [str]: label names
:param normalize: {‘true’, ‘pred’, ‘all’}, default=None.
Normalizes confusion matrix over the true (rows), predicted (columns) conditions or all the population.
If None, confusion matrix will not be normalized.
:param ax: matplotlib.pyplot axes to draw the confusion matrix on. Will generate new figure/axes if None.
:return:
"""
conf_matrix = self._confusion_matrix(normalize) # Evaluate the confusion matrix
# display = ConfusionMatrixDisplay(conf_matrix, display_labels=labels) # Generate the confusion matrix display
# Formatting for the plot
if labels:
xticks_rotation = 'vertical'
else:
xticks_rotation = 'horizontal'
# display.plot(include_values=True, cmap=plt.cm.get_cmap('Blues'), xticks_rotation=xticks_rotation, ax=ax)
if savepath is None:
plt.show()
else:
plt.savefig(savepath, bbox_inches='tight', dpi=200)
plt.close()
if __name__ == '__main__':
predict = [1, 2, 3, 4, 5, 3, 3, 2, 2, 5, 6, 6, 4, 3, 2, 4, 5, 6, 6, 3, 2]
label = [2, 5, 3, 4, 5, 3, 2, 2, 4, 6, 6, 6, 3, 3, 2, 5, 5, 6, 6, 3, 3]
eval = Evaluation(predict, label)
print('Accuracy:', f"%.3f" % eval.accuracy)
print('F1-measure:', f'{eval.f1_measure:.3f}')
print('F1-macro:', f'{eval.f1_macro:.3f}')
print('F1-macro (weighted):', f'{eval.f1_macro_weighted:.3f}')
print('precision:', f'{eval.precision:.3f}')
print('precision (macro):', f'{eval.precision_macro:.3f}')
print('precision (weighted):', f'{eval.precision_weighted:.3f}')
print('recall:', f'{eval.recall:.3f}')
print('recall (macro):', f'{eval.recall_macro:.3f}')
print('recall (weighted):', f'{eval.recall_weighted:.3f}')
# Generate "random prediction score" to test feeding in prediction score from NN
test_one_hot_encoder = OneHotEncoder(sparse=False, handle_unknown='ignore')
test_one_hot_encoder.fit(np.array(label).reshape(-1, 1))
rand_prediction_scores = 2 * test_one_hot_encoder.transform(np.array(predict).reshape(-1, 1)) # One hot
rand_prediction_scores += np.random.rand(*rand_prediction_scores.shape)
# rand_prediction_scores /= rand_prediction_scores.sum(axis=1)[:, None]
# print('Area under ROC curve (with 100% confidence in prediction):', f'{eval.area_under_roc():.3f}')
# print('Area under ROC curve (variable probability across classes):',
# f'{eval.area_under_roc(prediction_scores=rand_prediction_scores):.3f}')
# print(eval.confusion_matrix)
label_names = ["bird","bog","perople","horse","cat", "unknown"]
eval.plot_confusion_matrix(normalize="true",labels=label_names)
# print("运行到这了")
print(classification_report(label, predict, digits=3))
cifarutils.py
'''Some helper functions for PyTorch, including:
- get_mean_and_std: calculate the mean and std value of dataset.
- msr_init: net parameter initialization.
- progress_bar: progress bar mimic xlua.progress.
'''
import os
import sys
import time
import errno
import shutil
import torch
import torch.nn as nn
import torch.nn.init as init
import torchvision.utils as vutils
__all__=["get_mean_and_std","progress_bar","format_time",
'adjust_learning_rate', 'AverageMeter','Logger','mkdir_p', 'save_binary_img', 'save_model']
def get_mean_and_std(dataset):
'''Compute the mean and std value of dataset.'''
dataloader = torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=True, num_workers=2)
mean = torch.zeros(3)
std = torch.zeros(3)
print('==> Computing mean and std..')
for inputs, targets in dataloader:
for i in range(3):
mean[i] += inputs[:,i,:,:].mean()
std[i] += inputs[:,i,:,:].std()
mean.div_(len(dataset))
std.div_(len(dataset))
return mean, std
def init_params(net):
'''Init layer parameters.'''
for m in net.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal(m.weight, mode='fan_out')
if m.bias:
init.constant(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant(m.weight, 1)
init.constant(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal(m.weight, std=1e-3)
if m.bias:
init.constant(m.bias, 0)
# _, term_width = os.popen('stty size', 'r').read().split()
# term_width = int(term_width)
TOTAL_BAR_LENGTH = 65.
last_time = time.time()
begin_time = last_time
def progress_bar(current, total, msg=None):
global last_time, begin_time
if current == 0:
begin_time = time.time() # Reset for new bar.
cur_len = int(TOTAL_BAR_LENGTH*current/total)
rest_len = int(TOTAL_BAR_LENGTH - cur_len) - 1
sys.stdout.write(' [')
for i in range(cur_len):
sys.stdout.write('=')
sys.stdout.write('>')
for i in range(rest_len):
sys.stdout.write('.')
sys.stdout.write(']')
cur_time = time.time()
step_time = cur_time - last_time
last_time = cur_time
tot_time = cur_time - begin_time
L = []
L.append(' Step: %s' % format_time(step_time))
L.append(' | Tot: %s' % format_time(tot_time))
if msg:
L.append(' | ' + msg)
msg = ''.join(L)
sys.stdout.write(msg)
# for i in range(term_width-int(TOTAL_BAR_LENGTH)-len(msg)-3):
# sys.stdout.write(' ')
# Go back to the center of the bar.
# for i in range(term_width-int(TOTAL_BAR_LENGTH/2)+2):
# sys.stdout.write('\b')
sys.stdout.write(' %d/%d ' % (current+1, total))
if current < total-1:
sys.stdout.write('\r')
else:
sys.stdout.write('\n')
sys.stdout.flush()
def format_time(seconds):
days = int(seconds / 3600/24)
seconds = seconds - days*3600*24
hours = int(seconds / 3600)
seconds = seconds - hours*3600
minutes = int(seconds / 60)
seconds = seconds - minutes*60
secondsf = int(seconds)
seconds = seconds - secondsf
millis = int(seconds*1000)
f = ''
i = 1
if days > 0:
f += str(days) + 'D'
i += 1
if hours > 0 and i <= 2:
f += str(hours) + 'h'
i += 1
if minutes > 0 and i <= 2:
f += str(minutes) + 'm'
i += 1
if secondsf > 0 and i <= 2:
f += str(secondsf) + 's'
i += 1
if millis > 0 and i <= 2:
f += str(millis) + 'ms'
i += 1
if f == '':
f = '0ms'
return f
def write_record(file_path,str):
if not os.path.exists(file_path):
# os.makedirs(file_path)
os.system(r"touch {}".format(file_path))
f = open(file_path, 'a')
f.write(str)
f.close()
def count_parameters(model,all=True):
# If all= Flase, we only return the trainable parameters; tested
return sum(p.numel() for p in model.parameters() if p.requires_grad or all)
def adjust_learning_rate(optimizer, epoch, lr,factor=0.1, step=30):
"""Sets the learning rate to the initial LR decayed by factor every step epochs"""
lr = lr * (factor ** (epoch // step))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
class ProgressMeter(object):
def __init__(self, num_batches, meters, prefix=""):
self.batch_fmtstr = self._get_batch_fmtstr(num_batches)
self.meters = meters
self.prefix = prefix
def display(self, batch):
entries = [self.prefix + self.batch_fmtstr.format(batch)]
entries += [str(meter) for meter in self.meters]
print('\t'.join(entries))
def _get_batch_fmtstr(self, num_batches):
num_digits = len(str(num_batches // 1))
fmt = '{:' + str(num_digits) + 'd}'
return '[' + fmt + '/' + fmt.format(num_batches) + ']'
def accuracy(output, target, topk=(1,)):
"""Computes the accuracy over the k top predictions for the specified values of k"""
with torch.no_grad():
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].view(-1).float().sum(0, keepdim=True)
res.append(correct_k.mul_(100.0 / batch_size))
return res
def save_checkpoint(state, is_best, netName):
torch.save(state, './checkpoint/ckpt_imagenet32_' + netName + '_last.t7')
if is_best:
shutil.copyfile('./checkpoint/ckpt_imagenet32_' + netName + '_last.t7',
'./checkpoint/ckpt_imagenet32_' + netName + '_best.t7')
class AverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self, name, fmt=':f'):
self.name = name
self.fmt = fmt
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def __str__(self):
fmtstr = '{name} {val' + self.fmt + '} ({avg' + self.fmt + '})'
return fmtstr.format(**self.__dict__)
class Logger(object):
'''Save training process to log file with simple plot function.'''
def __init__(self, fpath, title=None, resume=False):
self.file = None
self.resume = resume
self.title = '' if title == None else title
if fpath is not None:
if resume:
self.file = open(fpath, 'r')
name = self.file.readline()
self.names = name.rstrip().split('\t')
self.numbers = {}
for _, name in enumerate(self.names):
self.numbers[name] = []
for numbers in self.file:
numbers = numbers.rstrip().split('\t')
for i in range(0, len(numbers)):
self.numbers[self.names[i]].append(numbers[i])
self.file.close()
self.file = open(fpath, 'a')
else:
self.file = open(fpath, 'w')
def set_names(self, names):
if self.resume:
pass
# initialize numbers as empty list
self.numbers = {}
self.names = names
for _, name in enumerate(self.names):
self.file.write(name)
self.file.write('\t')
self.numbers[name] = []
self.file.write('\n')
self.file.flush()
def append(self, numbers):
assert len(self.names) == len(numbers), 'Numbers do not match names'
for index, num in enumerate(numbers):
self.file.write("{0:.6f}".format(num))
self.file.write('\t')
self.numbers[self.names[index]].append(num)
self.file.write('\n')
self.file.flush()
def close(self):
if self.file is not None:
self.file.close()
def mkdir_p(path):
'''make dir if not exist'''
try:
os.makedirs(path)
except OSError as exc: # Python >2.5
if exc.errno == errno.EEXIST and os.path.isdir(path):
pass
else:
raise
def save_model(net, optimizer, epoch, path, **kwargs):
state = {
'net': net.state_dict(),
'optimizer': optimizer.state_dict(),
'epoch': epoch
}
for key, value in kwargs.items():
state[key] = value
torch.save(state, path)
def save_binary_img(tensor, file_path="./val.png", nrow=8, binary=False):
# tensor [b,1,w,h]
predicted = tensor
if binary:
predicted = torch.sigmoid(tensor) > 0.5
vutils.save_image(predicted.float(), file_path,nrow=nrow)
garbage.py
'''
@File :garbage.py
@Author:cjh
@Date :2022/1/16 15:09
@Desc :
'''
import pickle
import torch.nn.functional as F
import torch
import torch.nn as nn
from torch.autograd import Variable
import torchvision.models as models
from torchvision import transforms, utils
from torch.utils.data import Dataset, DataLoader
from PIL import Image
import numpy as np
import torch.optim as optim
import os
import random
import cv2
from torchvision.datasets.vision import VisionDataset
unknown_class_index=999
class GARBAGE40_Dataset(VisionDataset):
training_file='/train.txt'
validating_file='/validate.txt'
testing_file='/test.txt'
classes = ['0','1','2','3','4','5','6','7','8','9',
'10','11','12','13','14','15','16','17','18','19',
'20','21','22','23','24','25','26','27','28','29',
'30', '31', '32', '33', '34', '35', '36', '37', '38', '39']
# def get_root(self):
# return os.getcwd()
def __init__(self, root, train=True, transform=None, target_transform=None,
train_class_num=24, test_class_num=40, includes_all_train_class=True,train_classes=None):
super(GARBAGE40_Dataset, self).__init__(root,transform=transform,
target_transform=target_transform)
self.train=train
if self.train:
data_file=self.training_file
else:
data_file=self.testing_file
self.ori_data,self.ori_targets=[],[]
self.init_data(txt=root+data_file)
self.ori_data, self.ori_targets=np.array(self.ori_data),np.array(self.ori_targets)
self._update_open_set(train_class_num, test_class_num, includes_all_train_class,train_classes)
def _update_open_set(self, train_class_num=24, test_class_num=40, includes_all_train_class=False,train_classes=None):
assert train_class_num > 0 and train_class_num <= 40 # not include 10 to ensure openness.
if includes_all_train_class:
assert test_class_num >= train_class_num # not include equal to ensure openness.
class_list = list(range(len(self.classes))) #[0...39]
# train_classes = list(range(train_class_num))#[0...23]
if includes_all_train_class:
rnd = np.random.RandomState(42)
# unknown_list = list(range(train_class_num, 10))
unknown_list=[idx for idx in range(40) if idx not in train_classes]
test_classes = rnd.choice(unknown_list, test_class_num - train_class_num, replace=False).tolist() # 从unknown_list中随机选择(40-24)=16个项
test_classes = train_classes + test_classes
else:
rnd = np.random.RandomState(42)
test_classes = rnd.choice(class_list, test_class_num, replace=False).tolist()
# Update self.classes
selected_elements = [self.classes[index] for index in train_classes]
selected_elements.append(str(unknown_class_index) + '-unknown')
self.classes = selected_elements
# self.classes = test_classes
# update self.class_to_idx
# Ignore: due to the class_to_idx property
# self.class_to_idx = {_class: i for i, _class in enumerate(self.classes)}
# Processing data
if self.train:
indexes = [i for i, x in enumerate(self.ori_targets) if x in train_classes]
self.data = self.ori_data[indexes]
self.targets = [self.ori_targets[i]for i in indexes]
print(f"\tTraining data includes {train_class_num} classes, {len(self.targets)} samples.")
else:
indexes = [i for i, x in enumerate(self.ori_targets) if x in test_classes]
self.data = self.ori_data[indexes]
temp_test_classes = [x for x in test_classes if x not in train_classes]
train_and_test_calsses = train_classes + temp_test_classes
self.targets = [self.ori_targets[i] for i in indexes]
for i in range(0, len(self.ori_targets)):
if self.targets[i] in temp_test_classes:
self.targets[i] = unknown_class_index
print(f"\tTesting data includes {train_class_num + 1} classes (Original {test_class_num} classes),"
f" {len(self.targets)} samples.")
CTR=train_class_num
CTU=len(temp_test_classes)
CTA = CTR+CTU
self.openness = 1-np.sqrt(2*CTR/(CTR+CTA))
print(f"\tDuring testing, openness is {self.openness}.")
# 定义读取文件的格式
def loader(self,fn):
path = self.root+'/'.join(fn[1:].split("/"))
return Image.open(path).convert('RGB')
def init_data(self,txt):
fh = open(txt, 'r')
for line in fh: # 迭代该列表 #按行循环txt文本中的内
line = line.strip('\n')
line = line.rstrip('\n') # 删除 本行string 字符串末尾的指定字符
words = line.split() # 用split将该行分割成列表 split的默认参数是空格
self.ori_data.append(words[0])
self.ori_targets.append(int(words[1]))
def __getitem__(self, index):
"""
Args:
index (int): Index
Returns:
tuple: (image, target) where target is index of the target class.
"""
fn, target = self.data[index],int(self.targets[index])
img = self.loader(fn) # 按照路径读取图片
if self.transform is not None:
img = self.transform(img) # 数据标签转换为Tensor
if self.target_transform is not None:
target = self.target_transform(target)
return img, target
def __len__(self):
return len(self.data)
if __name__=="__main__":
import time
start1 = time.perf_counter()
# train_transforms = transforms.Compose([
# transforms.Resize(224),
# transforms.RandomResizedCrop(224, scale=(0.8, 1.0)),
# transforms.RandomHorizontalFlip(0.5),
# transforms.RandomRotation(10),
# transforms.ToTensor(),
# transforms.Normalize([0.5071, 0.4865, 0.4409], [0.2673, 0.2564, 0.2762]),
# ])
# test_transforms = transforms.Compose([
# transforms.Resize(224),
# transforms.RandomResizedCrop(224, scale=(0.8, 1.0)),
# transforms.RandomHorizontalFlip(0.5),
# transforms.RandomRotation(10),
# transforms.ToTensor(),
# transforms.Normalize([0.5071, 0.4865, 0.4409], [0.2673, 0.2564, 0.2762]),
# ])
train_transforms = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(256),
transforms.RandomAffine(degrees=0, translate=(0.05, 0.05)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
test_transforms = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(256),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
train_class_num=24
random.seed(42)
train_classes = random.sample(range(0, 40), train_class_num)
trainset = GARBAGE40_Dataset(root='../data/garbage', train=True,
transform=test_transforms,
train_class_num=train_class_num, test_class_num=40,
includes_all_train_class=True, train_classes=train_classes)
# testset=GARBAGE40_Dataset(root='../data/garbage', train=False,
# transform=test_transforms,
# train_class_num=40, test_class_num=40,
# includes_all_train_class=True,train_classes=train_classes)
trainloader=torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=4)
# testloader = torch.utils.data.DataLoader(testset, batch_size=128, shuffle=False, num_workers=4)
for i, (data, target) in enumerate(trainloader):
print()
end1 = time.perf_counter()
print("final is in : %s Seconds " % (end1 - start1))
garbage_transform.py
'''
@File :garbage_transform.py
@Author:cjh
@Date :2022/2/8 12:38
@Desc :
'''
import random
import math
import torch
from PIL import Image, ImageOps, ImageFilter
from torchvision import transforms
class Resize(object):
def __init__(self, size, interpolation=Image.BILINEAR):
self.size = size
self.interpolation = interpolation
def __call__(self, img):
# padding
ratio = self.size[0] / self.size[1]
w, h = img.size
if w / h < ratio:
t = int(h * ratio)
w_padding = (t - w) // 2
img = img.crop((-w_padding, 0, w+w_padding, h))
else:
t = int(w / ratio)
h_padding = (t - h) // 2
img = img.crop((0, -h_padding, w, h+h_padding))
img = img.resize(self.size, self.interpolation)
return img
class RandomRotate(object):
def __init__(self, degree, p=0.5):
self.degree = degree
self.p = p
def __call__(self, img):
if random.random() < self.p:
rotate_degree = random.uniform(-1*self.degree, self.degree)
img = img.rotate(rotate_degree, Image.BILINEAR)
return img
class RandomGaussianBlur(object):
def __init__(self, p=0.5):
self.p = p
def __call__(self, img):
if random.random() < self.p:
img = img.filter(ImageFilter.GaussianBlur(
radius=random.random()))
return img
class Cutout(object):
def __init__(self, probability=0.5, size=64, mean=[0.4914, 0.4822, 0.4465]):
self.probability = probability
self.mean = mean
self.size = size
def __call__(self, img):
if random.uniform(0, 1) > self.probability:
return img
h = self.size
w = self.size
for attempt in range(100):
area = img.size()[1] * img.size()[2]
if w < img.size()[2] and h < img.size()[1]:
x1 = random.randint(0, img.size()[1] - h)
y1 = random.randint(0, img.size()[2] - w)
if img.size()[0] == 3:
img[0, x1:x1 + h, y1:y1 + w] = self.mean[0]
img[1, x1:x1 + h, y1:y1 + w] = self.mean[1]
img[2, x1:x1 + h, y1:y1 + w] = self.mean[2]
else:
img[0, x1:x1 + h, y1:y1 + w] = self.mean[0]
return img
return img
class RandomErasing(object):
""" Randomly selects a rectangle region in an image and erases its pixels.
'Random Erasing Data Augmentation' by Zhong et al.
See https://arxiv.org/pdf/1708.04896.pdf
Args:
probability: The probability that the Random Erasing operation will be performed.
sl: Minimum proportion of erased area against input image.
sh: Maximum proportion of erased area against input image.
r1: Minimum aspect ratio of erased area.
mean: Erasing value.
"""
def __init__(self, probability=0.5, sl=0.02, sh=0.4, r1=0.3, mean=[0.4914, 0.4822, 0.4465]):
self.probability = probability
self.mean = mean
self.sl = sl
self.sh = sh
self.r1 = r1
def __call__(self, img):
if random.uniform(0, 1) > self.probability:
return img
for attempt in range(100):
area = img.size()[1] * img.size()[2]
target_area = random.uniform(self.sl, self.sh) * area
aspect_ratio = random.uniform(self.r1, 1 / self.r1)
h = int(round(math.sqrt(target_area * aspect_ratio)))
w = int(round(math.sqrt(target_area / aspect_ratio)))
if w < img.size()[2] and h < img.size()[1]:
x1 = random.randint(0, img.size()[1] - h)
y1 = random.randint(0, img.size()[2] - w)
if img.size()[0] == 3:
img[0, x1:x1 + h, y1:y1 + w] = self.mean[0]
img[1, x1:x1 + h, y1:y1 + w] = self.mean[1]
img[2, x1:x1 + h, y1:y1 + w] = self.mean[2]
else:
img[0, x1:x1 + h, y1:y1 + w] = self.mean[0]
return img
return img