DBSCAN与两种常用聚类算法
我们知道比较常用的两种聚类算法(k-means聚类和系统聚类)的分类依据是距离,不同于二者,DBSCAN算法(Density-based spatial clustering of applications with noise)是根据密度进行分类的算法
DBSCAN的分类方法
- 两个指标选择:选定一个半径值
r和一个minpoints - 随机选择一个点作为起始点
- 开始做如下试探
- 若起始点半径为
r内的点个数 ≥minpoints则该点为当前分类中的核心点 - 若起始点半径为
r内的点个数 <minpoints,但该点处于其它核心点半径r内,则该点为当前分类中的边界点 - 不属于上述两者的点则对于当前类而言是噪音,不属于当前类!
- 若起始点半径为
- 依次选择起始点半径
r内的点作为起始点,重复3-4步扩张当前类。 - 直到当前类中所有点都被试探,则随机选取一个未被试探过的点回到第三步。直到所有数据点都被试探过为止
何时选用DBSCAN
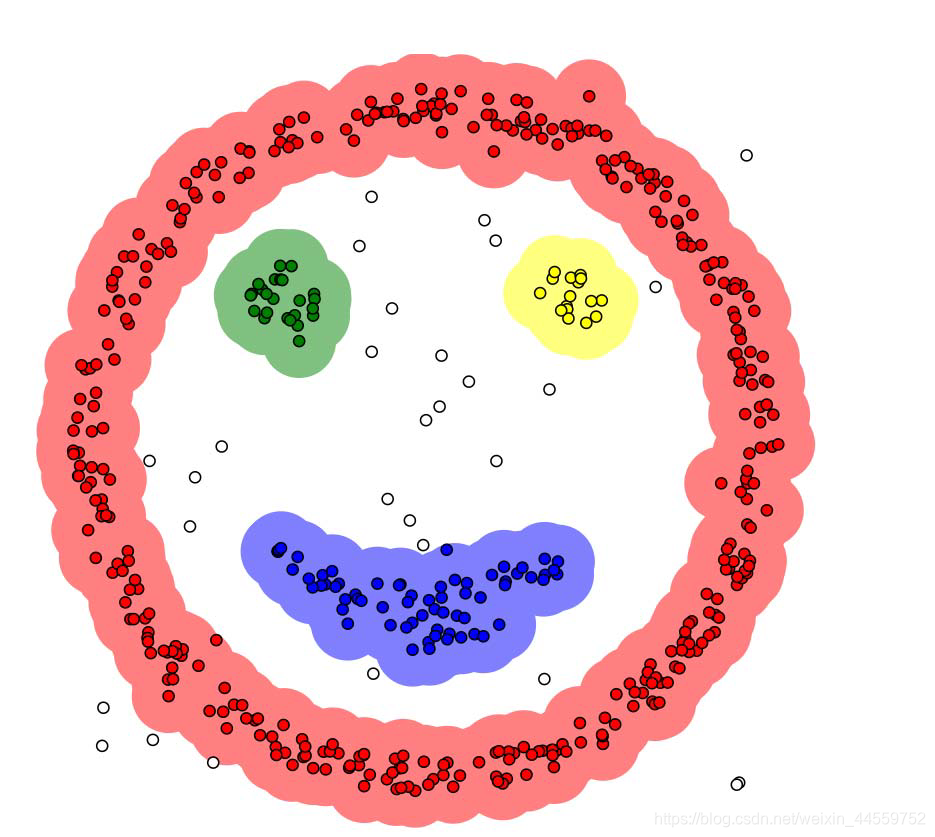
绘制出数据散点图,如果散点图呈现出明显的某种图案时推荐选用这类算法。如下
但当手上数据的散点图分布比较平均,则使用k-means聚类或者系统聚类效果会好一些。
DBSCAN的优缺点
优点:
- 基于密度进行,能处理任意形状任意大小的簇
- 可发现异常点(聚类结束以后未被分入任何类的噪音点)
- 与k-means比较不需要划分聚类个数
缺点
- 对输入参数
r和minpoints非常敏感 - 数据密度分布均匀的时候效果很差(即数据散点图绘制出来没啥形状的情况下DBSCAN的效果不咋地)
- 数据量大的时候计算密度单元的计算复杂度很大