激光SLAM总结——LIO-Mapping / LIOM / LINS / LIO-SAM算法解析
激光SLAM总结——LIO-Mapping / LIOM / LINS / LIO-SAM算法解析
在激光SLAM领域,LOAM、Lego-LOAM属于纯激光领域,除此之外还衍生处理视觉激光结合、激光IMU结合,甚至三者结合的算法,视觉激光结合的算法在我之前写的博文激光SLAM总结——VLOAM / LIMO算法解析中有简单总结,本文所介绍的LIO-Mapping / LIOM / LINS / LIO-SAM算法就隶属于激光IMU结合的算法,在发展成熟度上面是要优于视觉激光融合的。
因为我是先学习的视觉SLAM算法,从整体框架上理解,LIOM、LINS类似于MSCKF,后端是基于滤波的方法实现两种传感器的紧耦合,而LIO-Mapping类似于VINS-Mono,后端是基于优化的方法实现两种传感器的紧耦合,LIO-SAM后端是基于因子图实现的多种传感器的紧耦合,对MSCKF和VINS-Mono不了解的同学可以如下参考博客:
VINS-Mono关键知识点总结——前端详解
VINS-Mono关键知识点总结——边缘化marginalization理论和代码详解
VINS-Mono关键知识点总结——预积分和后端优化IMU部分
学习MSCKF笔记——前端、图像金字塔光流、Two Point Ransac
学习MSCKF笔记——四元数基础
学习MSCKF笔记——真实状态、标称状态、误差状态
学习MSCKF笔记——后端、状态预测、状态扩增、状态更新
本篇博客,我对以上算法进行简单总结。
1. LIO-Mapping
LIO-Mapping是2019年发表于ICRA一篇论文,原论文为《Tightly Coupled 3D Lidar Inertial Odometry and Mapping》,主要是借鉴LOAM和VINS-Mono的思想进行联合状态估计,工程层面和VINS-Mono一样,只不过是前端视觉部分换成了Lidar的前端进行特征关联,这是第一篇开源的Lidar-IMU紧耦合SLAM算法,具体介绍如下:
1.1 总体框架
LIO-Mapping总体框架如下:
具体步骤如下:
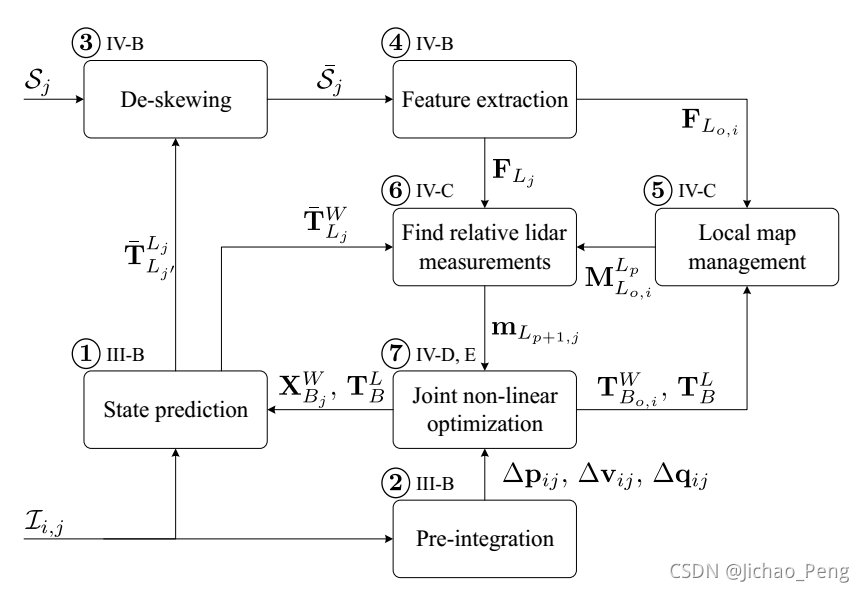
- 在激光雷达数据 S j S_{j} Sj到来之前,IMU原始输入 I i , j \mathcal{I}_{i, j} Ii,j进行积分(State prediction)和预积分(Pre-intergration),积分的目的是为了获得我们需要估计的状态变量 p B i W \mathbf{p}_{B_{i}}^{W} pBiW, v B i W \mathbf{v}_{B_{i}}^{W} vBiW和 q B i W \mathbf{q}_{B_{i}}^{W} qBiW,而预积分的目的是为了获得用于联合优化的 Δ p i j \Delta \mathbf{p}_{i j} Δpij, Δ v i j \Delta \mathbf{v}_{i j} Δvij和 Δ q i j \Delta \mathbf{q}_{i j} Δqij;
- 当系统收到激光雷达数据 S j S_{j} Sj后,对激光雷达进行去畸变操作(De-skewing)获得去畸变点云 S j S_{j} Sj,然后在此基础上对去畸变点云提取激光雷达特征点 F L j \mathbf{F}_{L_{j}} FLj(Feature extraction);
- 在滑动窗口内的激光雷达特征 F L o , i \mathbf{F}_{L_{o, i}} FLo,i根据优化后的位姿 T B o , i W \mathbf{T}_{B_{o, i}}^{W} TBo,iW和 T B L \mathbf{T}_{B}^{L} TBL组成局部地图 M L o , i L p \mathbf{M}_{L_{o, i}}^{L_{p}} MLo,iLp(Local map management),根据预测的位姿实现当前帧激光特征点和局部地图的匹配(FInd relative lidar measurements);
- 最后就是激光雷达观测 m L p + 1 , j \mathbf{m}_{L_{p+1, j}} mLp+1,j以及预积分结果 Δ p i j \Delta \mathbf{p}_{i j} Δpij, Δ v i j \Delta \mathbf{v}_{i j} Δvij和 Δ q i j \Delta \mathbf{q}_{i j} Δqij实现联合优化,优化后的结果用于跟新IMU积分获得的状态变量,避免IMU漂移;
由于激光雷达去畸变及特征提取、预积分、边缘化等操作在VINS-Mono的相关博客中都有详细介绍,因此本篇博客只对LIO-Mapping中较为特殊的滑窗管理和地图注册进行总结
1.2 滑窗管理
LIO-Mapping中滑窗管理示意图如下:
其中,
o
o
o是滑窗中的第一帧Lidar Sweep,
i
i
i是滑窗中最后一帧Lidar Sweep,
j
j
j是当前帧的Lidar Sweep,
p
p
p是滑窗中的Pivot Lidar Sweep,所谓Pivot Lidar Sweep指的就是整个滑窗内帧的位姿都是基于该帧坐标系建立的,随着滑窗移动,Pivot Lidar Sweep也不断变化。
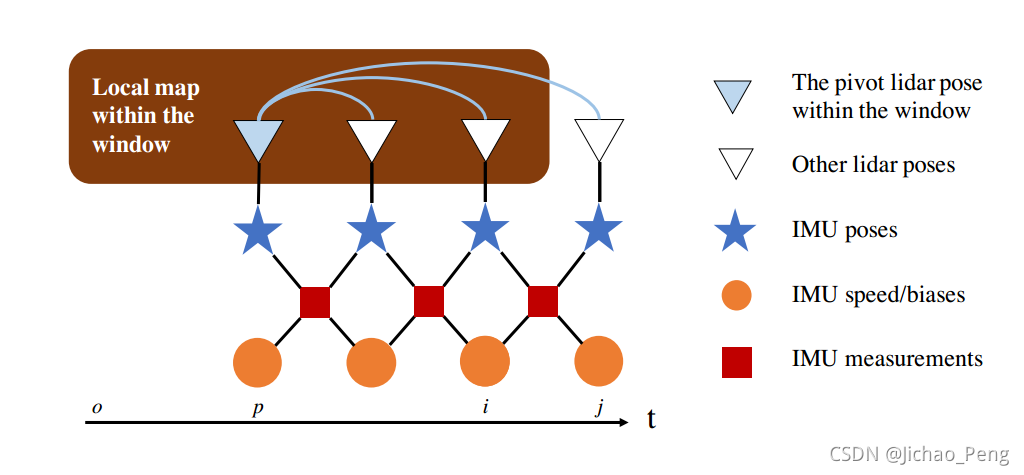
我们将滑窗内的特征点构建为局部地图 M L o , i L p = F L γ L p , γ ∈ { o , … , i } \mathbf{M}_{L_{o}, i}^{L_{p}} = \mathbf{F}_{L_{\gamma}}^{L_{p}}, \gamma \in\{o, \ldots, i\} MLo,iLp=FLγLp,γ∈{o,…,i},然后我们通过KNN算法找到原始特征点 F L α , α ∈ { p + 1 , … , j } \mathbf{F}_{L_{\alpha}}, \alpha \in\{p+1, \ldots, j\} FLα,α∈{p+1,…,j}与局部地图的对应关系并构建点到面的残差,优化过程中会优化窗口中所有帧相对Pivot Lidar Sweep的相对位姿以 T L α L p \mathbf{T}_{L_{\alpha}}^{L_{p}} TLαLp及包括Pivot Lidar Sweep的位姿 T L p W \mathbf{T}_{L_{p}}^{W} TLpW,而其中相对位姿可以表示为: T L α L p = T B L T B p W − 1 T B α W T B L − 1 = [ R L α L p p L α L p 0 1 ] \mathbf{T}_{L_{\alpha}}^{L_{p}}=\mathbf{T}_{B}^{L} \mathbf{T}_{B_{p}}^{W}{ }^{-1} \mathbf{T}_{B_{\alpha}}^{W} \mathbf{T}_{B}^{L-1}=\left[\begin{array}{cc} \mathbf{R}_{L_{\alpha}}^{L_{p}} & \mathbf{p}_{L_{\alpha}}^{L_{p}} \\ \mathbf{0} & 1 \end{array}\right] TLαLp=TBLTBpW−1TBαWTBL−1=[RLαLp0pLαLp1]那么激光雷达的点到面的残差可以表示为: r L ( m , T L p W , T L α W , T B L ) = ω T ( R L α L p x + p L α L p ) + d \mathbf{r}_{\mathcal{L}}\left(m, \mathbf{T}_{L_{p}}^{W}, \mathbf{T}_{L_{\alpha}}^{W}, \mathbf{T}_{B}^{L}\right)=\boldsymbol{\omega}^{T}\left(\mathbf{R}_{L_{\alpha}}^{L_{p}} x+\mathbf{p}_{L_{\alpha}}^{L_{p}}\right)+d rL(m,TLpW,TLαW,TBL)=ωT(RLαLpx+pLαLp)+d结合边缘化残差和预积分残差,整个优化的代码函数为 min X 1 2 { ∥ r P ( X ) ∥ 2 + ∑ m ∈ m L α α ∈ { p + 1 , ⋯ , j } ∥ r L ( m , X ) ∥ C L α m 2 + ∑ β ∈ { p , ⋯ , j − 1 } ∥ r B ( z β + 1 β , X ) ∥ C B β + 1 B β 2 } \begin{array}{c} \min _{\mathbf{X}} \frac{1}{2}\left\{\left\|\mathbf{r}_{\mathcal{P}}(\mathbf{X})\right\|^{2}+\sum_{m \in \mathbf{m}_{L_{\alpha}} \atop \alpha \in\{p+1, \cdots, j\}}\left\|\mathbf{r}_{\mathcal{L}}(m, \mathbf{X})\right\|_{\mathbf{C}_{L_{\alpha}}^{m}}^{2}\right. \\ \left.+\sum_{\beta \in\{p, \cdots, j-1\}}\left\|\mathbf{r}_{\mathcal{B}}\left(z_{\beta+1}^{\beta}, \mathbf{X}\right)\right\|_{\mathbf{C}_{B_{\beta+1}}^{B_{\beta}}}^{2}\right\} \end{array} minX21{∥rP(X)∥2+∑α∈{p+1,⋯,j}m∈mLα∥rL(m,X)∥CLαm2+∑β∈{p,⋯,j−1} rB(zβ+1β,X) CBβ+1Bβ2}其中 r P ( X ) \mathbf{r}_{\mathcal{P}}(\mathbf{X}) rP(X)是边缘化残差, r L ( m , X ) \mathbf{r}_{\mathcal{L}}(m, \mathbf{X}) rL(m,X)为激光雷达残差, r B ( z β + 1 β , X ) \mathbf{r}_{\mathcal{B}}\left(z_{\beta+1}^{\beta}, \mathbf{X}\right) rB(zβ+1β,X)为预积分残差,优化变量为滑窗内的所有帧状态变量以及激光到车体的标定: X = [ X B p W , … , X B j W , T B L ] \mathbf{X}=\left[\mathbf{X}_{B_{p}}^{W}, \ldots, \mathbf{X}_{B_{j}}^{W}, \mathbf{T}_{B}^{L}\right] X=[XBpW,…,XBjW,TBL]其中 X B i W = [ p B i W T v B i W T q B i W T b a i T b g i T ] T \mathbf{X}_{B_{i}}^{W}=[\mathbf{p}_{B_{i}}^{W^{T}} \quad \mathbf{v}_{B_{i}}^{W^{T}} \quad \mathbf{q}_{B_{i}}^{W^{T}}\quad\mathbf{b}_{a_{i}}^{T} \quad \mathbf{b}_{g_{i}}{ }^{T}]^{T} XBiW=[pBiWTvBiWTqBiWTbaiTbgiT]T T B L = [ p B L T q B L T ] T \mathbf{T}_{B}^{L}=\left[\begin{array}{ll} \mathbf{p}_{B}^{L^{T}} & \mathbf{q}_{B}^{L^{T}} \end{array}\right]^{T} TBL=[pBLTqBLT]T
1.3 地图注册
在优化获得位姿后,论文还有一步Refinement with Rotational Constraints的过程,就是将当前帧的激光雷达点对齐到全局地图中去,这也是为什么叫LIO-mapping的原因
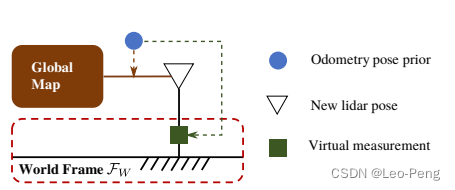
对齐相关的损失函数建立如下: C M = ∑ m ∈ m L ∥ r M ( m , T L W ) ∥ 2 , r M ( m , T ) = ω T ( R x + p ) + d \mathbf{C}_{\mathcal{M}}=\sum_{m \in \mathbf{m}_{L}}\left\|\mathbf{r}_{\mathcal{M}}\left(m, \mathbf{T}_{L}^{W}\right)\right\|^{2},\mathbf{r}_{\mathcal{M}}(m, \mathbf{T})=\boldsymbol{\omega}^{T}(\mathbf{R} \mathbf{x}+\mathbf{p})+d CM=m∈mL∑ rM(m,TLW) 2,rM(m,T)=ωT(Rx+p)+d其中, T L W \mathbf{T}_{L}^{W} TLW为前一步估计出来的激光位姿, m m m是激光测量,我们使用高斯牛顿法对上述损失函数进行求解。 J p C \mathbf{J}_{\mathrm{p}}^{\mathrm{C}} JpC和 J θ C \mathbf{J}_{\mathrm{\theta}}^{\mathrm{C}} JθC为残差相对位置和姿态的雅克比,为了保证地图和重力是对齐的,因此采用SE(2)-Constraint优化,由于Yaw方向姿态有更高的不确定性,而Roll和Pitch相对更加准确,因此通过旋转的雅克比进行修改来限制损失函数: J θ z C = J θ C ⋅ ( R ˘ ) T ⋅ Ω ˘ z \mathbf{J}_{\boldsymbol{\theta}_{z}}^{\mathbf{C}}=\mathbf{J}_{\boldsymbol{\theta}}^{\mathbf{C}} \cdot(\breve{\mathbf{R}})^{T} \cdot \breve{\boldsymbol{\Omega}}_{z} JθzC=JθC⋅(R˘)T⋅Ω˘z Ω ˘ z = [ ϵ x 0 0 0 ϵ y 0 0 0 1 ] \breve{\Omega}_{z}=\left[\begin{array}{ccc} \epsilon_{x} & 0 & 0 \\ 0 & \epsilon_{y} & 0 \\ 0 & 0 & 1 \end{array}\right] Ω˘z= ϵx000ϵy0001 其中, ( ⋅ ) ˘ \breve{(\cdot)} (⋅)˘为上一轮迭代估计的状态变量, Ω ˘ z \breve{\Omega}_{z} Ω˘z是姿态相对与世界坐标系的信息矩阵的近似值, ϵ x , ϵ y \epsilon_{x}, \epsilon_{y} ϵx,ϵy表示在世界系下 x x x和 y y y轴的旋转相对 z z z轴的旋转的information ratio。在优化步骤中通过修改后的 J p C \mathbf{J}_{\mathbf{p}}^{\mathbf{C}} JpC和 J θ z C \mathbf{J}_{\boldsymbol{\theta}_z}^{\mathbf{C}} JθzC计算增量 δ θ z \delta \theta_{z} δθz和 δ p \delta \boldsymbol{p} δp,然后再进行状态更新 p ~ = p ˘ + δ p \tilde{\mathbf{p}}=\breve{\mathbf{p}}+\delta \mathbf{p} p~=p˘+δp q ~ = [ 1 2 δ θ z 1 ] ⊗ q ˘ \tilde{\mathbf{q}}=\left[\begin{array}{c} \frac{1}{2} \delta \boldsymbol{\theta}_{z} \\ 1 \end{array}\right] \otimes \breve{\mathbf{q}} q~=[21δθz1]⊗q˘
1.4 实验结果
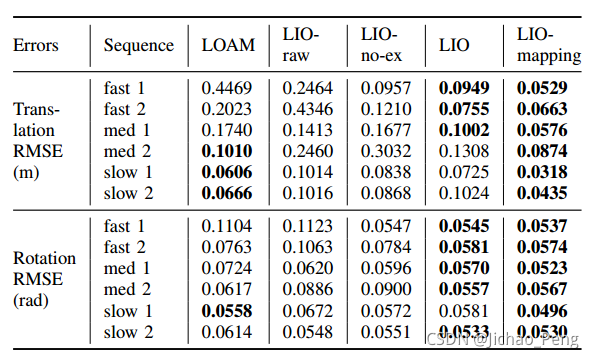
如下是对比和消融实验:
LIO-raw指的是不对激光雷达进行运动补偿的结果,LIO-no-ex值得是没有进行在线外参估计的方法,LIO是带有滑窗优化的方法,LIO-mapping是带有Rotation Constraints的方法,从结果看,LIO-mapping效果确实更好。如下是个模块计算耗时:
由于Odometry和Mapping是在不同的线程中,系统整体上可以做到按照IMU输出进行运行。
2. LIOM
LIOM是2019年发表于IROS的一篇文章,该文章原标题为《A Robust Laser-Inertial Odometry and Mapping Method for Large-Scale Highway Environments》,论文强调要解决的是高速场景的激光定位问题,高速场景的主要挑战在于速度快、缺乏几何特征、运动物体多、回环少等,而本文的主要贡献是分割网络去除动态物体的影响同时引入激光惯性框架进行高速环境下的运动估计,具体如下:
2.1 总体框架
LIOM算法总体框架如下:
如上图所示,算法由四个模块组成,
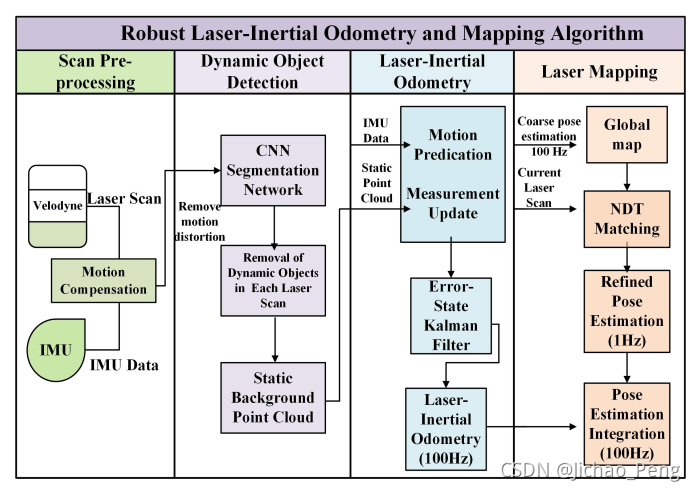
- Scan Pre-process模块负责进行激光点云去畸变操作;
- Dynamic Object Detection模块负责通过语义分割进行动态物体检测;
- Laser-Inertial Odometry模块使用误差状态卡尔曼滤波来融合激光和IMU数据以高频输出位姿估计;
- Laser Mapping模块负责建立全局地图,然后使用当前帧激光点云和全局地图进行匹配来实现定位结果的Refinement。
这里,我们简单回顾下基于误差状态的扩展卡尔曼滤波流程:
2.1 激光点云去畸变
在高速场景下对激光点云去畸变是非常有必要的,其步骤如下:
- 对每一帧的所有激光点都标记时间戳: t curr = t start + ∂ × θ curr θ end ( 1 ) t_{\text {curr }}=t_{\text {start }}+\partial \times \frac{\theta_{\text {curr }}}{\theta_{\text {end }}}(1) tcurr =tstart +∂×θend θcurr (1)其中 ∂ \partial ∂是激光帧的扫描周期
- 找到时间戳 k k k到 k + 1 k+1 k+1的连续IMU测量,其中 k k k取最接近当前激光点时间戳 t curr t_{\text {curr }} tcurr 的IMU测量
- 获得IMU在时刻 k k k和 k + 1 k+1 k+1在世界坐标系中的位姿 T k w = [ p x , p y , p z , v x , v y , v z , θ x , θ y , θ z ] T_k^w=\left[p_x, p_y, p_z, v_x, v_y, v_z, \theta_x, \theta_y, \theta_z\right] Tkw=[px,py,pz,vx,vy,vz,θx,θy,θz] T k + 1 w = [ p x , p y , p z , v x , v y , v z , θ x , θ x , θ z ] T_{k+1}^w=\left[p_x, p_y, p_z, v_x, v_y, v_z, \theta_x, \theta_x, \theta_z\right] Tk+1w=[px,py,pz,vx,vy,vz,θx,θx,θz]
- 使用线性插值确定IMU在时刻 t curr t_{\text {curr }} tcurr 在世界坐标系中的位姿: ratio front = t curr − t k t k + 1 − t k \text { ratio }_{\text {front }}=\frac{t_{\text {curr }}-t_k}{t_{k+1}-t_k} ratio front =tk+1−tktcurr −tk ratio back = t k + 1 − t curr t k + 1 − t k \text { ratio }_\text {back }=\frac{t_{k+1}-t_{\text {curr }}}{t_{k+1}-t_k} ratio back =tk+1−tktk+1−tcurr T curr w = T k + 1 w × ratio front + T k w × ratio back T_{\text {curr }}^w=T_{k+1}^w \times \text { ratio }_{\text {front }}+T_k^w \times \text { ratio }_{\text {back }} Tcurr w=Tk+1w× ratio front +Tkw× ratio back
- 通过当前激光点和当前激光帧起始点的位置 P curr w , P start w P_{\text {curr }}^w, P_{\text {start }}^w Pcurr w,Pstart w和速度 V curr w , V start w V_{\text {curr }}^w, V_{\text {start }}^w Vcurr w,Vstart w可以获得在当前激光帧起始点坐标系下的运动扰动 Δ P curr start \Delta P_{\text {curr }}^{\text {start }} ΔPcurr start : Δ P c u r r w = P c u r r w − ( P s t a r t w + V s t a r t w × ∂ × θ curr θ end ) \Delta P_{\mathrm{curr}}^w=P_{\mathrm{curr}}^w-\left(P_{\mathrm{start}}^w+V_{\mathrm{start}}^w \times \partial \times \frac{\theta_{\text {curr }}}{\theta_{\text {end }}}\right) ΔPcurrw=Pcurrw−(Pstartw+Vstartw×∂×θend θcurr ) Δ P curr start = R w start Δ P curr w \Delta P_{\text {curr }}^{\text {start }}=R_w^{\text {start }} \Delta P_{\text {curr }}^w ΔPcurr start =Rwstart ΔPcurr w
- 变换开始点坐标系下的所有激光点,对每个激光点提取他们的运动扰动 Δ P curr siart \Delta P_{\text {curr }}^{\text {siart }} ΔPcurr siart
2.3 误差状态扩展卡尔曼滤波
-
状态变量定义:
在误差状态扩展卡尔曼滤波中要区分真实状态 x x x,标称状态 x ^ \hat{x} x^和误差状态 δ x \boldsymbol{\delta} x δx的区别,他们的关系如下: x = x ^ ⊕ δ x x=\hat{x} \oplus \boldsymbol{\delta} x x=x^⊕δxLIOM中没有对外参进行在线估计(MSCKF中有),因此误差状态变量相对简单,如下: δ x = [ δ v δ p δ θ δ a b δ w b ] \delta x=\left[\begin{array}{c} \delta {v} \\ \delta {p} \\ \delta {\theta} \\ \delta {a}_{b} \\ \delta {w}_{b} \end{array}\right] δx= δvδpδθδabδwb 其中 a b a_b ab 和 w b w_b wb是加速度计和陀螺仪偏置 -
传播过程:
传播过程包含预测状态传播和误差协方差传播,其中预测状态传播基于标称状态通过欧拉积分获得,如下: [ v ^ t + 1 p ^ t + 1 R ^ t + 1 a ^ b ( t + 1 ) w ^ b ( t + 1 ) ] = [ v ^ t + [ R ^ t ( a m − a ^ b ( t ) ) + g ] Δ t p ^ t + v ^ t Δ t + 1 2 [ R ^ t ( a m − a ^ b ( t ) ) + g ] Δ t 2 R ^ t R { ( w m − w ^ b ( t ) ) Δ t } a ^ b ( t ) w ^ b ( t ) ] \left[\begin{array}{c} \hat{v}_{t+1} \\ \hat{p}_{t+1} \\ \hat{R}_{t+1} \\ \hat{a}_{b(t+1)} \\ \hat{w}_{b(t+1)} \end{array}\right]=\left[\begin{array}{c} \hat{v}_{t}+\left[\hat{R}_{t}\left(a_{m}-\hat{a}_{b(t)}\right)+g\right] \Delta t \\ \hat{p}_{t}+\hat{v}_{t} \Delta t+\frac{1}{2}\left[\hat{R}_{t}\left(a_{m}-\hat{a}_{b(t)}\right)+g\right] \Delta t^{2} \\ \hat{R}_{t} R\left\{\left(w_{m}-\hat{w}_{b(t)}\right) \Delta t\right\} \\ \hat{a}_{b(t)} \\ \hat{w}_{b(t)} \end{array}\right] v^t+1p^t+1R^t+1a^b(t+1)w^b(t+1) = v^t+[R^t(am−a^b(t))+g]Δtp^t+v^tΔt+21[R^t(am−a^b(t))+g]Δt2R^tR{(wm−w^b(t))Δt}a^b(t)w^b(t) 误差状态的协方差传播需要根据误差状态变量运动方程线性化后获得,误差状态变量微分方程如下: δ x ˙ = [ δ v ˙ δ p ˙ δ θ ˙ δ a ˙ b δ w ˙ b ] = [ − R ^ [ a m − a ^ b ] × δ θ − R ^ δ a b − η a δ v − [ w m − w ^ b ] × δ θ − δ w b − η w η a η w ] \delta \dot{x}=\left[\begin{array}{c} \delta \dot{v} \\ \delta \dot{p} \\ \delta \dot{\theta} \\ \delta \dot{a}_{b} \\ \delta \dot{w}_{b} \end{array}\right]=\left[\begin{array}{c} -\hat{R}\left[a_{m}-\hat{a}_{b}\right]_{\times} \delta \theta-\hat{R} \delta a_{b}-\eta_{a} \\ \delta v \\ -\left[w_{m}-\hat{w}_{b}\right]_{\times} \delta \theta-\delta w_{b}-\eta_{w} \\ \eta_{a} \\ \eta_{w} \end{array}\right] δx˙= δv˙δp˙δθ˙δa˙bδw˙b = −R^[am−a^b]×δθ−R^δab−ηaδv−[wm−w^b]×δθ−δwb−ηwηaηw 那么误差状态运动学方程可以写为: [ δ v t + 1 δ p t + 1 δ R t + 1 δ a b ( t + 1 ) δ w b ( t + 1 ) ] = [ δ v t + ( − R ^ t [ a m − a ^ b ] × δ θ − R ^ t δ a b ) Δ t + η v δ p t + δ v t Δ t R { − ( w m − w ^ b ) Δ t } δ θ − δ w b Δ t − η θ δ a b ( t ) + η a δ w b ( t ) + η w ] \left[\begin{array}{c} \delta{v}_{t+1} \\ \delta{p}_{t+1} \\ \delta{R}_{t+1} \\ \delta{a}_{b(t+1)} \\ \delta{w}_{b(t+1)} \end{array}\right]=\left[\begin{array}{c} \delta{v}_{t}+(-\hat{R}_{t}\left[a_{m}-\hat{a}_{b}\right]_{\times} \delta \theta-\hat{R}_{t} \delta a_{b}) \Delta t + {\eta}_v \\ \delta{p}_{t}+\delta{v}_{t} \Delta t\\ R\{-(w_{m}-\hat{w}_{b}) \Delta t \} \delta \theta - \delta w_{b} \Delta t - {\eta}_\theta\\ \delta{a}_{b(t)} + \eta_{a} \\ \delta{w}_{b(t)} + \eta_{w} \end{array}\right] δvt+1δpt+1δRt+1δab(t+1)δwb(t+1) = δvt+(−R^t[am−a^b]×δθ−R^tδab)Δt+ηvδpt+δvtΔtR{−(wm−w^b)Δt}δθ−δwbΔt−ηθδab(t)+ηaδwb(t)+ηw 以上运动学方程可以表示为: δ x = F x δ x + F n w , w ∼ N ( 0 , Q ) \delta \mathbf{x}=\mathbf{F}_{\mathbf{x}} \delta \mathbf{x}+\mathbf{F}_{\mathbf{n}} \mathbf{w},\mathbf{w} \sim \mathcal{N}(0, \mathbf{Q}) δx=Fxδx+Fnw,w∼N(0,Q)其中 F x = [ 0 I 3 − R ^ t [ a m − a ^ b ] × Δ t − R ^ t Δ t 0 I 3 I 3 Δ t 0 0 0 0 0 R { − ( w m − w ^ b ) Δ t } ) 0 − I 3 Δ t 0 0 0 I 3 0 0 0 0 0 I 3 ] \mathbf{F}_{\mathbf{x}}=\left[\begin{array}{cccccc} \mathbf{0} & I_{3} & -\hat{R}_{t}\left[a_{m}-\hat{a}_{b}\right]_{\times} \Delta t & -\hat{R}_{t} \Delta t & \mathbf{0}\\ I_{3} & I_{3} \Delta t & \mathbf{0} & \mathbf{0} & \mathbf{0}\\ \mathbf{0} & \mathbf{0} &R\{-(w_{m}-\hat{w}_{b}) \Delta t \} ) & \mathbf{0} & -I_{3}\Delta t \\ \mathbf{0} & \mathbf{0} & \mathbf{0} &I_{3} & \mathbf{0}\\ \mathbf{0} & \mathbf{0} & \mathbf{0} & \mathbf{0} & I_{3} \end{array}\right] Fx= 0I3000I3I3Δt000−R^t[am−a^b]×Δt0R{−(wm−w^b)Δt})00−R^tΔt00I3000−I3Δt0I3 F i = [ I 3 0 0 0 0 0 0 0 0 I 3 0 0 0 0 I 3 0 0 0 0 I 3 ] \mathbf{F}_{\mathbf{i}}=\left[\begin{array}{cccc} I_{3} & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \\ 0 &I_{3} & 0 & 0 \\ 0 & 0 & I_{3} & 0 \\ 0 & 0 & 0 & I_{3} \\ \end{array}\right] Fi= I3000000I300000I300000I3 Q = diag ( Cov ( η v ) , 0 3 , Cov ( η θ ) , Cov ( η g ) , Cov ( η a ) ) \mathbf{Q}=\operatorname{diag}\left(\operatorname{Cov}\left(\boldsymbol{\eta}_v\right), \mathbf{0}_3, \operatorname{Cov}\left(\boldsymbol{\eta}_{\boldsymbol{\theta}}\right), \operatorname{Cov}\left(\boldsymbol{\eta}_g\right), \operatorname{Cov}\left(\boldsymbol{\eta}_a\right)\right) Q=diag(Cov(ηv),03,Cov(ηθ),Cov(ηg),Cov(ηa))误差状态的均值和协方差的预测如下:
δ x pred = F δ x \delta \mathbf{x}_{\text {pred }}=\mathbf{F} \delta \mathbf{x} δxpred =Fδx Σ ˉ t + 1 = F x Σ t F x T + F n Q n F n T \bar{\Sigma}_{t+1}=\mathbf{F}_{x} \Sigma_{t} \mathbf{F}_{x}^{T}+\mathbf{F}_{n} Q_{n} \mathbf{F}_{n}^{T} Σˉt+1=FxΣtFxT+FnQnFnT其中我们并不关心误差状态的均值部分,因为在ESKF的每次更新后误差状态的均值就会被重置,而协方差部分则可以指导整个误差估计的分布情况。 -
更新过程:
观测模型如下: δ y = H δ x = [ 0 I 3 0 0 0 0 0 I 3 0 0 ] δ x \delta y=H \delta x=\left[\begin{array}{ccccc} 0 & I_{3} & 0 & 0 & 0 \\ 0 & 0 & I_{3} & 0 & 0 \end{array}\right] \delta x δy=Hδx=[00I300I30000]δx通过预测过程,我们可以获得一个先验的状态变量及方差 δ x ˉ t + 1 m ∈ R 6 , Σ ˉ t + 1 m ∈ R 6 × 6 \delta \bar{x}_{t+1}^{m} \in \mathbb{R}^{6}, \bar{\Sigma}_{t+1}^{m} \in \mathbb{R}^{6 \times 6} δxˉt+1m∈R6,Σˉt+1m∈R6×6,根据先验的状态变量及方差,基于NDT算法,我们可以获得后验状态变量及方差 δ x t + 1 m ∈ R 6 \delta x_{t+1}^{m} \in \mathbb{R}^{6} δxt+1m∈R6 , Σ t + 1 m ∈ R 6 × 6 \Sigma_{t+1}^{m} \in \mathbb{R}^{6 \times 6} Σt+1m∈R6×6,根据先验和后验的误差,我们就可以计算出观测以及观测误差的大小: C t + 1 m = ( ( Σ t + 1 m ) − 1 − ( Σ ˉ t + 1 m ) − 1 ) − 1 C_{t+1}^{m}=\left((\Sigma_{t+1}^{m})^{-1}-\left(\bar{\Sigma}_{t+1}^{m}\right)^{-1}\right)^{-1} Ct+1m=((Σt+1m)−1−(Σˉt+1m)−1)−1 δ y t + 1 m = ( K m ) − 1 ( δ x t + 1 m − δ x ˉ t + 1 m ) + δ x ˉ t + 1 m \delta y_{t+1}^{m}=\left(K^{m}\right)^{-1}\left(\delta x_{t+1}^{m}-\delta \bar{x}_{t+1}^{m}\right)+\delta \bar{x}_{t+1}^{m} δyt+1m=(Km)−1(δxt+1m−δxˉt+1m)+δxˉt+1m其中 K m = Σ ˉ t + 1 H m T ( H m Σ ˉ t + 1 H m T + C t + 1 m ) − 1 ∈ R 6 × 6 K^{m}=\bar{\Sigma}_{t+1} H^{m T}\left(H^{m} \bar{\Sigma}_{t+1} H^{m T}+C_{t+1}^{m}\right)^{-1} \in \mathbb{R}^{6 \times 6} Km=Σˉt+1HmT(HmΣˉt+1HmT+Ct+1m)−1∈R6×6,这一步称为inversing the kalman filter measurement update,有了观测之后,我们就可以进行正常的卡尔曼更新了,如下: K = Σ ˉ t + 1 H T ( H Σ ˉ t + 1 H T + C t + 1 ) − 1 K=\bar{\Sigma}_{t+1} H^{T}\left(H \bar{\Sigma}_{t+1} H^{T}+C_{t+1}\right)^{-1} K=Σˉt+1HT(HΣˉt+1HT+Ct+1)−1 δ x t + 1 = K ( δ y t + 1 − H δ x ˉ t + 1 ) \delta x_{t+1}=K\left(\delta y_{t+1}-H \delta \bar{x}_{t+1}\right) δxt+1=K(δyt+1−Hδxˉt+1) Σ t + 1 = ( I 15 − K H ) Σ ˉ t + 1 \Sigma_{t+1}=\left(I_{15}-K H\right) \bar{\Sigma}_{t+1} Σt+1=(I15−KH)Σˉt+1最后进行误差矫正即可,如下: [ v ^ t + 1 p ^ t + 1 R ^ t + 1 a ^ b ( t + 1 ) w ^ b ( t + 1 ) ] = [ v ^ t + δ v t + 1 p ^ t + δ p t + 1 R ^ t ⋅ R ( δ θ t + 1 ) a ^ b t + δ a b ( t + 1 ) w ^ b t + δ w b ( t + 1 ) ] \left[\begin{array}{c} \hat{v}_{t+1} \\ \hat{p}_{t+1} \\ \hat{R}_{t+1} \\ \hat{a}_{b(t+1)} \\ \hat{w}_{b(t+1)} \end{array}\right]=\left[\begin{array}{c} \hat{v}_{t}+\delta v_{t+1} \\ \hat{p}_{t}+\delta p_{t+1} \\ \hat{R}_{t} \cdot R\left(\delta \theta_{t+1}\right) \\ \hat{a}_{b t}+\delta a_{b(t+1)} \\ \hat{w}_{b t}+\delta w_{b(t+1)} \end{array}\right] v^t+1p^t+1R^t+1a^b(t+1)w^b(t+1) = v^t+δvt+1p^t+δpt+1R^t⋅R(δθt+1)a^bt+δab(t+1)w^bt+δwb(t+1) 关于上述inversing the kalman filter measurement update我其实不太理解,为什么NDT算法获得后验状态变量和卡尔曼更新中观测需要通过一个新的卡尔曼增益进行转换?如果有读者对这部分有更加深入的理解可以评论补充
2.2 实验结果
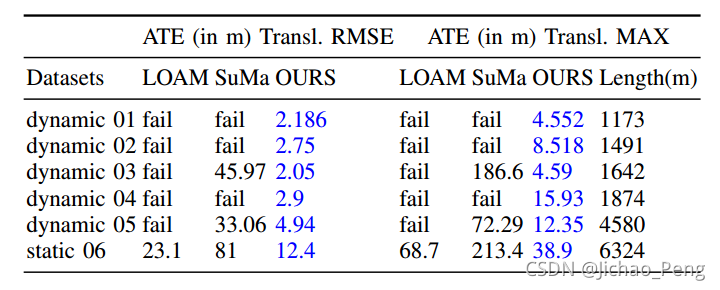
在论文中,作者在高速公路数据集上对比了LIOM,LOAM和SuMa三种算法的结果,LIOM的鲁棒性明显提高,如下所示:
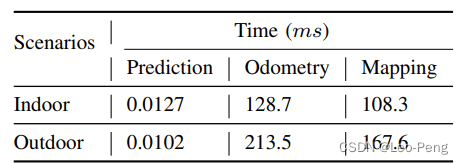
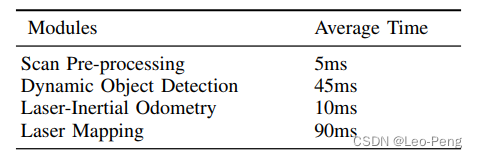
各个模块耗时如下:
和LIO-Mapping对比,基于滤波的Odometry和Mapping都会有明显的速度优势
3 . LINS
LINS是2020年发表于ICRA上的一篇文章,原论文名称为《LINS: A Lidar-Inertial State Estimator for Robust and Efficient Navigation》,该论文的主要特点在于使用了基于误差状态的迭代扩展卡尔曼滤波,并且以机器人中心重新定义了状态变量,论文还和LIO-Mapping进行了对比,在精度相同的情况下取得了更高的效率。
3.1 总体框架
算法总体框架如下:
算法整体框架也是非常清晰明了,Feature Extraction Module主要用于提取激光雷达特征点,Lidar-inertial Odometry Module就是通过卡尔曼滤波融合激光雷达特征点和IMU,Mapping Module主要利用全局地图来Refine里程计的结果。Feature Extraction Module主要参考的LOAM和Lego-LOAM算法,这里我们主要总结其中核心的基于误差状态的迭代卡尔曼滤波。
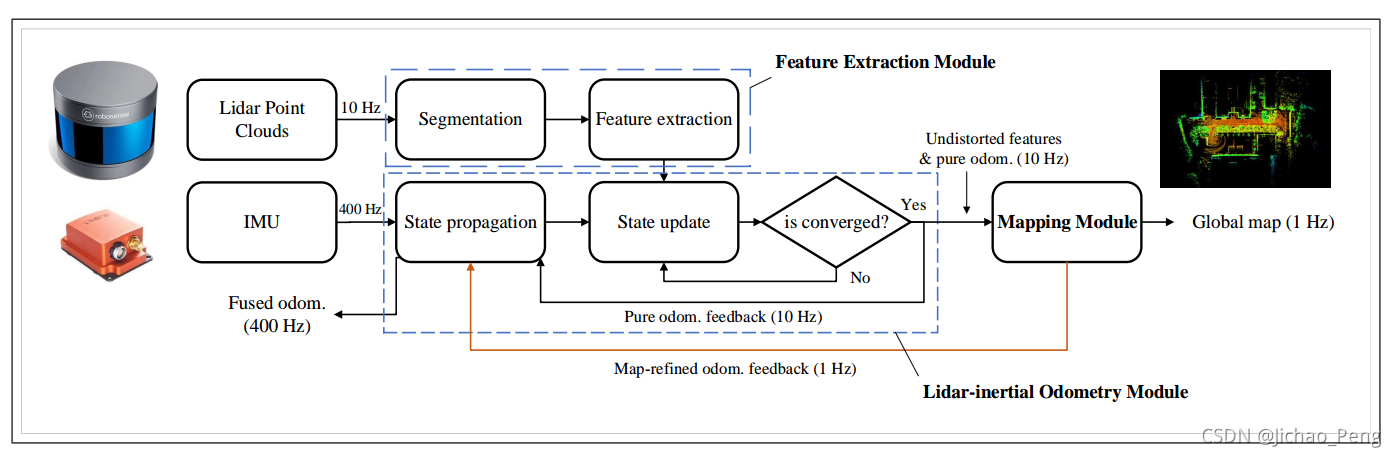
3.2 误差状态扩展卡尔曼滤波
LINS中的误差状态扩展卡尔曼滤波的特点主要是:
- 以机器人中心定义的状态变量,避免了在线性化过程中不断增大的不确定性;
- 使用迭代扩展卡尔曼滤波,以取得更高的精度;
下面具体展开,在LIOM算法中,所有状态变量都是建立在世界坐标系下,并对其进行拓展卡尔曼滤波,这样由于线性化导致的误差是在不断累积的,但是在LINS,状态变量定义如下:
x
w
b
k
:
=
[
p
w
b
k
,
q
w
b
k
]
\mathbf{x}_{w}^{b_{k}}:=\left[\mathbf{p}_{w}^{b_{k}}, \mathbf{q}_{w}^{b_{k}}\right]
xwbk:=[pwbk,qwbk]
x
b
k
+
1
b
k
:
=
[
p
b
k
+
1
b
k
,
v
b
k
+
1
b
k
,
q
b
k
+
1
b
k
,
b
a
,
b
g
,
g
b
k
]
\mathbf{x}_{b_{k+1}}^{b_{k}}:=\left[\mathbf{p}_{b_{k+1}}^{b_{k}}, \mathbf{v}_{b_{k+1}}^{b_{k}}, \mathbf{q}_{b_{k+1}}^{b_{k}}, \mathbf{b}_{a}, \mathbf{b}_{g}, \mathbf{g}^{b_{k}}\right]
xbk+1bk:=[pbk+1bk,vbk+1bk,qbk+1bk,ba,bg,gbk]其中
p
b
k
+
1
b
k
\mathbf{p}_{b_{k+1}}^{b_{k}}
pbk+1bk和
q
b
k
+
1
b
k
\mathbf{q}_{b_{k+1}}^{b_{k}}
qbk+1bk为世界系相对于
b
k
b_{k}
bk帧坐标系的旋转和平移,
p
b
k
+
1
b
k
\mathbf{p}_{b_{k+1}}^{b_{k}}
pbk+1bk和
q
b
k
+
1
b
k
\mathbf{q}_{b_{k+1}}^{b_{k}}
qbk+1bk从
b
k
+
1
b_{k+1}
bk+1帧到
b
k
b_{k}
bk帧的旋转平移变化在
b
k
b_{k}
bk帧下的表达,
v
b
k
+
1
b
k
\mathbf{v}_{b_{k+1}}^{b_{k}}
vbk+1bk在
g
b
k
+
1
b
k
\mathbf{g}_{b_{k+1}}^{b_{k}}
gbk+1bk为在
b
k
b_{k}
bk帧下的速度和重力加速度,所谓“以机器人中心定义状态变量”指的就是参与迭代扩展卡尔曼滤波是
x
b
k
+
1
b
k
\mathbf{x}_{b_{k+1}}^{b_{k}}
xbk+1bk,而
x
w
b
k
\mathbf{x}_{w}^{b_{k}}
xwbk是根据
x
b
k
+
1
b
k
\mathbf{x}_{b_{k+1}}^{b_{k}}
xbk+1bk的滤波结果进行更新,本身不参与滤波,因此可以避免线性化过程误差的累计。
x
b
k
+
1
b
k
\mathbf{x}_{b_{k+1}}^{b_{k}}
xbk+1bk的误差状态变量定义如下
δ
x
:
=
[
δ
p
,
δ
v
,
δ
θ
,
δ
b
a
,
δ
b
g
,
δ
g
]
\boldsymbol{\delta} \mathbf{x}:=\left[\boldsymbol{\delta} \mathbf{p}, \delta \mathbf{v}, \delta \theta, \delta \mathbf{b}_{a}, \delta \mathbf{b}_{g}, \delta \mathbf{g}\right]
δx:=[δp,δv,δθ,δba,δbg,δg]误差状态
δ
x
\delta \mathbf{x}
δx、标称状态
−
x
b
k
+
1
b
k
{ }^{-} \mathbf{x}_{b_{k+1}}^{b_{k}}
−xbk+1bk与真实状态
x
b
k
+
1
b
k
\mathbf{x}_{b_{k+1}}^{b_{k}}
xbk+1bk关系如下
x
b
k
+
1
b
k
=
−
x
b
k
+
1
b
k
田
δ
x
=
[
−
p
b
k
+
1
b
k
+
δ
p
−
v
b
k
+
1
b
k
+
δ
v
−
q
b
k
+
1
b
k
⊗
exp
(
δ
θ
)
−
b
a
+
δ
b
a
−
b
g
+
δ
b
g
−
g
b
k
+
δ
g
]
\mathbf{x}_{b_{k+1}}^{b_{k}}={ }^{-} \mathbf{x}_{b_{k+1}}^{b_{k}} \text { 田 } \boldsymbol{\delta} \mathbf{x}=\left[\begin{array}{c} { }^{-} \mathbf{p}_{b_{k+1}}^{b_{k}}+\delta \mathbf{p} \\ { }^{-} \mathbf{v}_{b_{k+1}}^{b_{k}}+\boldsymbol{\delta} \mathbf{v} \\ { }^{-} \mathbf{q}_{b_{k+1}}^{b_{k}} \otimes \exp (\boldsymbol{\delta} \theta) \\ { }^{-} {\mathbf{b}}_{a}+\boldsymbol{\delta} \mathbf{b}_{a} \\ { }^{-} \mathbf{b}_{g}+\boldsymbol{\delta} \mathbf{b}_{g} \\ { }^{-} \mathbf{g}^{b_{k}}+\boldsymbol{\delta} \mathbf{g} \end{array}\right]
xbk+1bk=−xbk+1bk 田 δx=
−pbk+1bk+δp−vbk+1bk+δv−qbk+1bk⊗exp(δθ)−ba+δba−bg+δbg−gbk+δg
误差状态的线性连续时间运动模型如下:
δ
x
˙
(
t
)
=
F
t
δ
x
(
t
)
+
G
t
w
\delta \dot{\mathbf{x}}(t)=\mathbf{F}_{t} \delta \mathbf{x}(t)+\mathbf{G}_{t} \mathbf{w}
δx˙(t)=Ftδx(t)+Gtw其中噪声项
w
=
[
n
a
T
,
n
g
T
,
n
b
a
T
,
n
b
g
T
]
T
\mathbf{w}=\left[\mathbf{n}_{a}^{T}, \mathbf{n}_{g}^{T}, \mathbf{n}_{b_{a}}^{T}, \mathbf{n}_{b_{g}}^{T}\right]^{T}
w=[naT,ngT,nbaT,nbgT]T,系数矩阵分别为:
F
t
=
[
0
I
0
0
0
0
0
0
−
R
t
b
k
[
a
^
t
]
×
−
R
t
b
k
0
0
0
0
−
[
ω
^
t
]
×
0
−
I
3
−
I
3
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
]
\mathbf{F}_{t}=\left[\begin{array}{cccccc} 0 & \mathbf{I} & 0 & 0 & 0 & 0 \\ 0 & 0 & -\mathbf{R}_{t}^{b_{k}}\left[\hat{\mathbf{a}}_{t}\right]_{\times} & -\mathbf{R}_{t}^{b_{k}} & 0 & 0 \\ 0 & 0 & -\left[\hat{\omega}_{t}\right]_{\times} & 0 & -\mathbf{I}_{3} & -\mathbf{I}_{3} \\ 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 \end{array}\right]
Ft=
000000I000000−Rtbk[a^t]×−[ω^t]×0000−Rtbk000000−I300000−I3000
G
t
=
[
0
0
0
0
−
R
t
b
k
0
0
0
0
−
I
3
0
0
0
0
I
3
0
0
0
0
I
3
0
0
0
0
]
\mathbf{G}_{t}=\left[\begin{array}{cccc} 0 & 0 & 0 & 0 \\ -\mathbf{R}_{t}^{b_{k}} & 0 & 0 & 0 \\ 0 & -\mathbf{I}_{3} & 0 & 0 \\ 0 & 0 & \mathbf{I}_{3} & 0 \\ 0 & 0 & 0 & \mathbf{I}_{3} \\ 0 & 0 & 0 & 0 \end{array}\right]
Gt=
0−Rtbk000000−I3000000I3000000I30
其中
a
^
t
=
a
m
t
−
b
a
\hat{\mathbf{a}}_{t}=\mathbf{a}_{m_{t}}-\mathbf{b}_{a}
a^t=amt−ba,
ω
^
t
=
ω
m
t
−
b
g
\hat{\omega}_{t}=\omega_{m_{t}}-\mathbf{b}_{g}
ω^t=ωmt−bg,接下来是对运动模型进行离散化,如下:
δ
x
t
τ
=
(
I
+
F
t
τ
Δ
t
)
δ
x
t
τ
−
1
\delta \mathbf{x}_{t_{\tau}}=\left(\mathbf{I}+\mathbf{F}_{t_{\tau}} \Delta t\right) \delta \mathbf{x}_{t_{\tau-1}}
δxtτ=(I+FtτΔt)δxtτ−1状态变量方差递推如下:
P
t
τ
=
(
I
+
F
t
τ
Δ
t
)
P
t
τ
−
1
(
I
+
F
t
τ
Δ
t
)
T
+
(
G
t
τ
Δ
t
)
Q
(
G
t
τ
Δ
t
)
T
\mathbf{P}_{t_{\tau}}=\left(\mathbf{I}+\mathbf{F}_{t_{\tau}} \Delta t\right) \mathbf{P}_{t_{\tau-1}}\left(\mathbf{I}+\mathbf{F}_{t_{\tau}} \Delta t\right)^{T}+\left(\mathbf{G}_{t \tau} \Delta t\right) \mathbf{Q}\left(\mathbf{G}_{t_{\tau}} \Delta t\right)^{T}
Ptτ=(I+FtτΔt)Ptτ−1(I+FtτΔt)T+(GtτΔt)Q(GtτΔt)T其中
Δ
t
=
t
τ
−
t
τ
−
1
\Delta t=t_{\tau}-t_{\tau-1}
Δt=tτ−tτ−1,而
t
τ
t_{\tau}
tτ和
t
τ
−
1
t_{\tau-1}
tτ−1分别是IMU的连续两个时刻,
Q
\mathbf{Q}
Q是噪声
w
\mathbf{w}
w的矩阵表达。
在此基础上就可以对状态变量进行卡尔曼更新,在迭代卡尔曼滤波中,状态更新类似于优化问题,需要考虑构建一个残差,然后类似于优化一样在每一次迭代中取得不同的更新量,在LIOM中,设计的优化残差为 min δ x ∥ δ x ∥ ( P k ) − 1 + ∥ f ( − x b k + 1 b k 田 δ x ) ∥ ( J k M k J k T ) − 1 \min _{\delta \mathbf{x}}\|\delta \mathbf{x}\|_{\left(\mathbf{P}_{k}\right)^{-1}}+\| f\left({ }^{-} \mathbf{x}_{b_{k+1}}^{b_{k}} \text { 田 } \boldsymbol{\delta} \mathbf{x}\right) \|_{\left(\mathbf{J}_{k} \mathbf{M}_{\mathbf{k}} \mathbf{J}_{k}^{T}\right)^{-1}} δxmin∥δx∥(Pk)−1+∥f(−xbk+1bk 田 δx)∥(JkMkJkT)−1从中看出优化目标是使得误差状态最小同时观察误差最小,其中 ∥ ⋅ ∥ \|\cdot\| ∥⋅∥为 M M M范数, J k \mathbf{J}_{k} Jk为函数 f ( ⋅ ) f(\cdot) f(⋅)相对测量噪声的的雅克比,而 M k \mathbf{M}_{k} Mk为测量噪声矩阵,函数 f ( ⋅ ) f(\cdot) f(⋅)为 f i ( x b k + 1 b k ) = { ∣ ( p ^ i l k − p a l k ) × ( p ^ i l k − p b I k ) ∣ ∣ p a l k − p b l k ∣ if p i l k + 1 ∈ F e ∣ ( p ^ i k − p a l ) T ( ( p a k − p b k ) × ( p a l − p c l ) ) ∣ ∣ ( p a l k − p b l k ) × ( p a l k − p c l c ) ∣ if p i l k + 1 ∈ F p f_{i}\left(\mathbf{x}_{b_{k+1}}^{b_{k}}\right)=\left\{\begin{array}{cl} \frac{\left|\left(\hat{\mathbf{p}}_{i}^{l_{k}}-\mathbf{p}_{a}^{l_{k}}\right) \times\left(\hat{\mathbf{p}}_{i}^{l_{k}}-\mathbf{p}_{b}^{I_{k}}\right)\right|}{\left|\mathbf{p}_{a}^{l_{k}}-\mathbf{p}_{b}^{l_{k}}\right|} & \text { if } \mathbf{p}_{i}^{l_{k+1}} \in \mathbb{F}_{e} \\ \frac{\left|\left(\hat{\mathbf{p}}_{i}^{k}-\mathbf{p}_{a}^{l}\right)^{T}\left(\left(\mathbf{p}_{a}^{k}-\mathbf{p}_{b}^{k}\right) \times\left(\mathbf{p}_{a}^{l}-\mathbf{p}_{c}^{l}\right)\right)\right|}{\left|\left(\mathbf{p}_{a}^{l_{k}}-\mathbf{p}_{b}^{l_{k}}\right) \times\left(\mathbf{p}_{a}^{l_{k}}-\mathbf{p}_{c}^{l_{c}}\right)\right|} & \text { if } \mathbf{p}_{i}^{l_{k+1}} \in \mathbb{F}_{p} \end{array}\right. fi(xbk+1bk)=⎩ ⎨ ⎧ palk−pblk (p^ilk−palk)×(p^ilk−pbIk) (palk−pblk)×(palk−pclc) (p^ik−pal)T((pak−pbk)×(pal−pcl)) if pilk+1∈Fe if pilk+1∈Fp其中 p ^ i l k \hat{\mathbf{p}}_{i}^{l_{k}} p^ilk是 p i l k + 1 \mathbf{p}_{i}^{l_{k+1}} pilk+1通过状态变量变换到当前帧的特征点,如下: p ^ i l k = R l b T ( R b k + 1 b k ( R l b p i l k + 1 + p l b ) + p b k + 1 b k − p l b ) \hat{\mathbf{p}}_{i}^{l_{k}}=\mathbf{R}_{l}^{b^{T}}\left(\mathbf{R}_{b_{k+1}}^{b_{k}}\left(\mathbf{R}_{l}^{b} \mathbf{p}_{i}^{l_{k+1}}+\mathbf{p}_{l}^{b}\right)+\mathbf{p}_{b_{k+1}}^{b_{k}}-\mathbf{p}_{l}^{b}\right) p^ilk=RlbT(Rbk+1bk(Rlbpilk+1+plb)+pbk+1bk−plb)如果熟悉LOAM或者Lego-LOAM算法的同学应该知道,这个就是LOAM或者Lego-LOAM算法中求解位姿构建的点到线和点到面的残差,在此就不再赘述。通过求解残差,我们可以获得迭代更新公式: K k , j = P k H k , j T ( H k , j P k H k , j T + J k , j M k J k , j T ) − 1 \mathbf{K}_{k, j}=\mathbf{P}_{k} \mathbf{H}_{k, j}^{T}\left(\mathbf{H}_{k, j} \mathbf{P}_{k} \mathbf{H}_{k, j}^{T}+\mathbf{J}_{k, j} \mathbf{M}_{k} \mathbf{J}_{k, j}^{T}\right)^{-1} Kk,j=PkHk,jT(Hk,jPkHk,jT+Jk,jMkJk,jT)−1 Δ x j = K k , j ( H k , j δ x j − f ( − x b k + 1 b k 田 δ x j ) ) \Delta \mathbf{x}_{j}=\mathbf{K}_{k, j}\left(\mathbf{H}_{k, j} \boldsymbol{\delta} \mathbf{x}_{j}-f\left({ }^{-} \mathbf{x}_{b_{k+1}}^{b_{k}} \text { 田 } \delta \mathbf{x}_{j}\right)\right) Δxj=Kk,j(Hk,jδxj−f(−xbk+1bk 田 δxj)) δ x j + 1 = δ x j + Δ x j \delta \mathbf{x}_{j+1}=\delta \mathbf{x}_{j}+\Delta \mathbf{x}_{j} δxj+1=δxj+Δxj其中 H k , j \mathbf{H}_{k, j} Hk,j为 f ( − x b k + 1 b k 田 δ x j ) f\left(-\mathbf{x}_{b_{k+1}}^{b_{k}} \text { 田 } \boldsymbol{\delta} \mathbf{x}_{j}\right) f(−xbk+1bk 田 δxj)相对 δ x j \delta \mathbf{x}_{j} δxj的雅克比,在这一步中特征点的残差参与到了卡尔曼滤波的过程中,因此本文是一种紧耦合方法。在每次迭代过程中,算法都会寻找新的匹配边界点和面点,并计算新的 H k , j \mathbf{H}_{k, j} Hk,j、 J k , j \mathbf{J}_{k, j} Jk,j和 K k , j \mathbf{K}_{k, j} Kk,j,当 f ( x b k + 1 b k ) f\left(\mathbf{x}_{b_{k+1}}^{b_{k}}\right) f(xbk+1bk)小于一定阈值或者达到n次迭代后,我们就可以更新状态变量的残差: P k + 1 = ( I − K k , n H k , n ) P k ( I − K k , n H k , n ) T + K k , n M k K k , n T \mathbf{P}_{k+1}=\left(\mathbf{I}-\mathbf{K}_{k, n} \mathbf{H}_{k, n}\right) \mathbf{P}_{k}\left(\mathbf{I}-\mathbf{K}_{k, n} \mathbf{H}_{k, n}\right)^{T}+\mathbf{K}_{k, n} \mathbf{M}_{k} \mathbf{K}_{k, n}^{T} Pk+1=(I−Kk,nHk,n)Pk(I−Kk,nHk,n)T+Kk,nMkKk,nT最后,我们初始化下一阶段 x b k + 2 b k + 1 \mathbf{x}_{b_{k+2}}^{b_{k+1}} xbk+2bk+1为: [ 0 3 , v b k + 1 b k + 1 , q 0 , b a , b g , g b k + 1 ] \left[\mathbf{0}_{3}, \mathbf{v}_{b_{k+1}}^{b_{k+1}}, \mathbf{q}_{0}, \mathbf{b}_{a}, \mathbf{b}_{g}, \mathbf{g}^{b_{k+1}}\right] [03,vbk+1bk+1,q0,ba,bg,gbk+1]其中, q 0 \mathbf{q}_{0} q0为单位旋转, v b k + 1 b k + 1 = R b k b k + 1 v b k + 1 b k \mathbf{v}_{b_{k+1}}^{b_{k+1}}=\mathbf{R}_{b_{k}}^{b_{k+1}} \mathbf{v}_{b_{k+1}}^{b_{k}} vbk+1bk+1=Rbkbk+1vbk+1bk, g b k + 1 = R b k b k + 1 g b k \mathbf{g}^{b_{k+1}}=\mathbf{R}_{b_{k}}^{b_{k+1}} \mathbf{g}^{b_{k}} gbk+1=Rbkbk+1gbk
当获得 x b k + 1 b k \mathbf{x}_{b_{k+1}}^{b_{k}} xbk+1bk后我们就可以更新世界系相对于 b k + 1 b_{k+1} bk+1帧坐标系的旋转和平移,其实也就是 b k + 1 b_{k+1} bk+1帧在世界系下的位姿: x w b k + 1 = [ p w b k + 1 q w b k + 1 ] = [ R b k b k + 1 ( p w b k − p b k + 1 b k ) q b k b k + 1 ⊗ q w b k ] \mathbf{x}_{w}^{b_{k+1}}=\left[\begin{array}{l} \mathbf{p}_{w}^{b_{k+1}} \\ \mathbf{q}_{w}^{b_{k+1}} \end{array}\right]=\left[\begin{array}{c} \mathbf{R}_{b_{k}}^{b_{k+1}}\left(\mathbf{p}_{w}^{b_{k}}-\mathbf{p}_{b_{k+1}}^{b_{k}}\right) \\ \mathbf{q}_{b_{k}}^{b_{k+1}} \otimes \mathbf{q}_{w}^{b_{k}} \end{array}\right] xwbk+1=[pwbk+1qwbk+1]=[Rbkbk+1(pwbk−pbk+1bk)qbkbk+1⊗qwbk]
3.3 实验结果
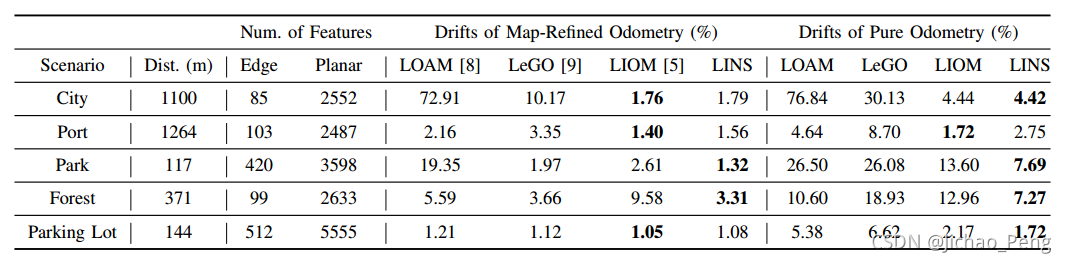
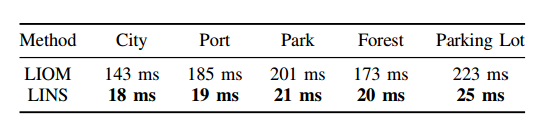
LINS的实验结果如下:
注意这里的LIOM指的是《Tightly Coupled 3D Lidar Inertial Odometry and Mapping》中提出的基于优化的方法,从上表中可以看出,LINS精度和LIOM是相当的,但是在下表计算时间的对比中,LINS的优势就非常明显(注意这里对比的LIOM指的是《Tightly Coupled 3D Lidar Inertial Odometry and Mapping》这篇文章)。
在LIOM中最耗时的部分是需要2D约束维护一个Local Map并且基于MAP Estimation通过 Scan to Map的匹配进行状态变量求解,而LINS使用了迭代卡尔曼滤波替代了MAP Estimation,相当于降低了优化问题的维度,并且使用的是Scan to Scan的匹配,因此速度得到了较大的提升。
这里我们可以来简单理一下LIOM、LINS和MSCKF中滤波状态的区别:
三者相同点都是误差状态,都是根据IMU进行运动方程进行预测,根据激光后者视觉观测进行更新,不同点是LIOM是最基本的误差状态扩展卡尔曼滤波,状态变量中直接包括最终要估计的位姿,而LINS在滤波的状态变量中不包括最终要估计的位姿,而是前后帧相对运动结果,在MSCKF中的状态变量中除了IMU当前时刻的位姿还包括历史的相机状态,IMU相关的状态变量方差在预测过程中预测,而相机相关的状态变量的方差在扩增时预测,因此这三者是各有不同的。
4. LIO-SAM
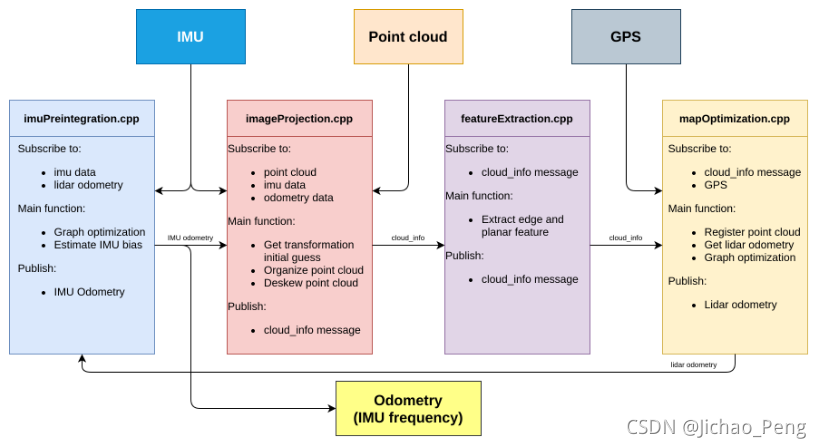
4.1 总体框架
LIO-SAM总体框如下图所示
从图中可以看出来,IMU数据除了用来构建IMU预积分因子之外,还用来进行激光雷达去畸变操作,在IMU预积分完成后,在将IMU将里程计作为先验用来获取激光里程计,激光里程计除了进行Scan-to-Map的匹配之外,还构建一个包括激光雷达因子、GPS因子和回环因子的因子图,用来优化地图和激光里程计的结果,优化后的激光里程计的结果再传递回IMU预积分节点,构建IMU预积分因子图,包括激光里程计因子、IMU预分因子和IMU测量Bias的因子,在论文中给出的因子图如下(看起来是一个,实现起来其实是两个):
因子图中包括IMU预积分因子、激光雷达里程计因子、GPS因子、回环因子。而我们要估计的状态变量为:
x
=
[
R
T
,
p
T
,
v
T
,
b
T
]
T
\mathbf{x}=\left[\mathbf{R}^{\mathbf{T}}, \mathbf{p}^{\mathbf{T}}, \mathbf{v}^{\mathbf{T}}, \mathbf{b}^{\mathbf{T}}\right]^{\mathbf{T}}
x=[RT,pT,vT,bT]T整个优化过程是建立在用于增量平滑的Bayers Tree上的,关于因子图基础知识、Bayers Tree、以及LIO-SAM中关于因子图构建的部分代码我都总结在GTSAM Tutorial学习笔记,下面我仅仅对LIO-SAM中各个因子的基本原理进行介绍。
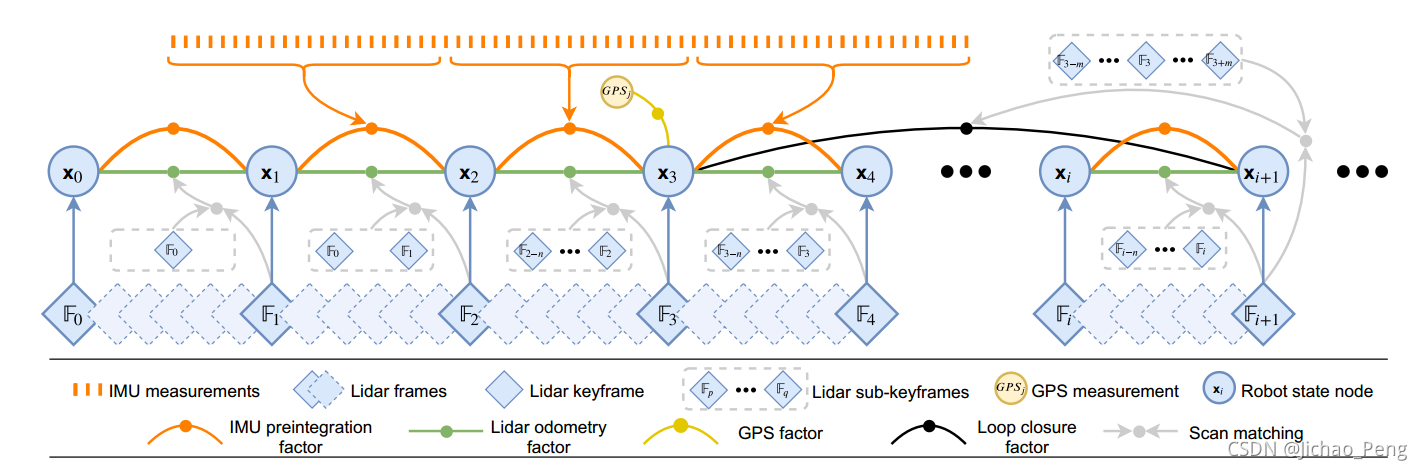
4.2 因子图构建
在LIO-SAM的因子图中一个有四种因子,我们分别介绍
IMU预积分因子:
IMU从时刻
t
t
t积分到
t
+
Δ
t
t+\Delta t
t+Δt的公式为
v
t
+
Δ
t
=
v
t
+
g
Δ
t
+
R
t
(
a
^
t
−
b
t
a
−
n
t
a
)
Δ
t
\mathbf{v}_{t+\Delta t}=\mathbf{v}_{t}+\mathbf{g} \Delta t+\mathbf{R}_{t}\left(\hat{\mathbf{a}}_{t}-\mathbf{b}_{t}^{\mathbf{a}}-\mathbf{n}_{t}^{\mathbf{a}}\right) \Delta t
vt+Δt=vt+gΔt+Rt(a^t−bta−nta)Δt
p
t
+
Δ
t
=
p
t
+
v
t
Δ
t
+
1
2
g
Δ
t
2
+
1
2
R
t
(
a
^
t
−
b
t
a
−
n
t
a
)
Δ
t
2
\begin{aligned} \mathbf{p}_{t+\Delta t}=\mathbf{p}_{t} &+\mathbf{v}_{t} \Delta t+\frac{1}{2} \mathbf{g} \Delta t^{2}+\frac{1}{2} \mathbf{R}_{t}\left(\hat{\mathbf{a}}_{t}-\mathbf{b}_{t}^{\mathbf{a}}-\mathbf{n}_{t}^{\mathbf{a}}\right) \Delta t^{2} \end{aligned}
pt+Δt=pt+vtΔt+21gΔt2+21Rt(a^t−bta−nta)Δt2
R
t
+
Δ
t
=
R
t
exp
(
(
ω
^
t
−
b
t
ω
−
n
t
ω
)
Δ
t
)
\mathbf{R}_{t+\Delta t}=\mathbf{R}_{t} \exp \left(\left(\hat{\boldsymbol{\omega}}_{t}-\mathbf{b}_{t}^{\boldsymbol{\omega}}-\mathbf{n}_{t}^{\boldsymbol{\omega}}\right) \Delta t\right)
Rt+Δt=Rtexp((ω^t−btω−ntω)Δt)其中
ω
^
t
=
ω
t
+
b
t
ω
+
n
t
ω
\hat{\boldsymbol{\omega}}_{t}=\boldsymbol{\omega}_{t}+\mathbf{b}_{t}^{\omega}+\mathbf{n}_{t}^{\omega}
ω^t=ωt+btω+ntω
a
^
t
=
R
t
B
W
(
a
t
−
g
)
+
b
t
a
+
n
t
a
\hat{\mathbf{a}}_{t}=\mathbf{R}_{t}^{\mathrm{BW}}\left(\mathbf{a}_{t}-\mathbf{g}\right)+\mathbf{b}_{t}^{\mathrm{a}}+\mathbf{n}_{t}^{\mathrm{a}}
a^t=RtBW(at−g)+bta+nta
R
t
=
R
t
W
B
=
R
t
B
W
⊤
\mathbf{R}_{t}=\mathbf{R}_{t}^{\mathbf{W B}}=\mathbf{R}_{t}^{\mathbf{B} W^{\top}}
Rt=RtWB=RtBW⊤其中预积分测量值为:
Δ
v
i
j
=
R
i
⊤
(
v
j
−
v
i
−
g
Δ
t
i
j
)
\Delta \mathbf{v}_{i j}=\mathbf{R}_{i}^{\top}\left(\mathbf{v}_{j}-\mathbf{v}_{i}-\mathbf{g} \Delta t_{i j}\right)
Δvij=Ri⊤(vj−vi−gΔtij)
Δ
p
i
j
=
R
i
⊤
(
p
j
−
p
i
−
v
i
Δ
t
i
j
−
1
2
g
Δ
t
i
j
2
)
\Delta \mathbf{p}_{i j}=\mathbf{R}_{i}^{\top}\left(\mathbf{p}_{j}-\mathbf{p}_{i}-\mathbf{v}_{i} \Delta t_{i j}-\frac{1}{2} \mathbf{g} \Delta t_{i j}^{2}\right)
Δpij=Ri⊤(pj−pi−viΔtij−21gΔtij2)
Δ
R
i
j
=
R
i
⊤
R
j
\Delta \mathbf{R}_{i j}=\mathbf{R}_{i}^{\top} \mathbf{R}_{j}
ΔRij=Ri⊤Rj从公式可以看出来,LIO-SAM中定义的预积分和我们在LIOM和VINS-Mono中定义预积分结果都不太一样,因为在LIO-SAM的代码实现中是直接是用GTSAM中自带的预积分类实现的,这个类中具体怎么实现预积分的还有待考证,除此之外,IMU Bias因子作为除IMU预积分因子之外单独的一部分参与联合优化。
激光里程计因子
激光里程计和LOAM的原理基本一样,但是区别是LIO-SAM中的构建了关键帧,地图也是利用关键中的特征点构建的局部地图
M
i
=
{
M
i
e
,
M
i
p
}
\mathbf{M}_{i}=\left\{\mathbf{M}_{i}^{e}, \mathbf{M}_{i}^{p}\right\}
Mi={Mie,Mip}其中
M
i
e
=
′
F
i
e
∪
′
F
i
−
1
e
∪
…
∪
′
F
i
−
n
e
\mathbf{M}_{i}^{e}={ }^{\prime} \mathrm{F}_{i}^{e} \cup^{\prime} \mathrm{F}_{i-1}^{e} \cup \ldots \cup^{\prime} \mathrm{F}_{i-n}^{e}
Mie=′Fie∪′Fi−1e∪…∪′Fi−ne
M
i
p
=
′
F
i
p
∪
′
F
i
−
1
p
∪
…
∪
′
F
i
−
n
p
\mathbf{M}_{i}^{p}={ }^{\prime} \mathrm{F}_{i}^{p} \cup^{\prime} \mathrm{F}_{i-1}^{p} \cup \ldots \cup^{\prime} \mathrm{F}_{i-n}^{p}
Mip=′Fip∪′Fi−1p∪…∪′Fi−np然后是利用Scan-to-Map的原理进行计算的
GPS因子
当接收到GPS测量后,我们首先变换它们到笛卡尔坐标系中。当一个新的位姿节点被插入到因子图后,我们关联GPS因子到该位姿节点中去。具体地,我们线性插值GPS的时间戳,得到对应最新位姿节点的GPS位置。
由于在GPS信号一直存在的时候,持续添加GPS因子没有意义。因为漂移很缓慢。所以在实际操作过程中,我们只添加GPS因子当位姿估计协方差矩阵变得很大的时候。
这一部分原理介绍还是很简单的,因为因子图的构建基于GTSAM本来就很简介,LIO-SAM不太一样的地方其实是一种“半紧耦合”是解决方案,先获得IMU里程计和激光雷达里程计,然后通过因子图的方式将两者结合起来,没那么紧的融合方式效果也很好
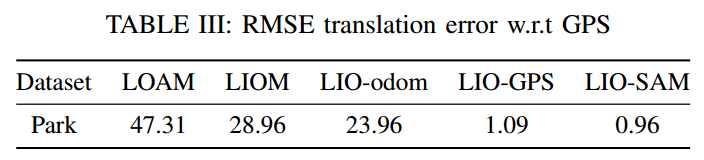
4.3 实验结果
LIO-SAM的实验结果是非常惊艳的,如下图所示:
以及RMSE结果的对比如下:
耗时对比如下:

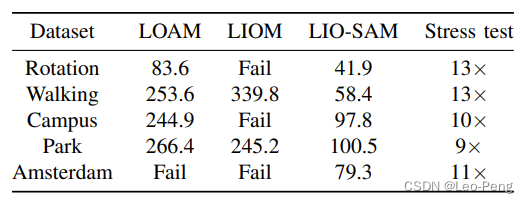
但是我在别人的博客里看到有同学提到,算法在自己平台上实现效果不是很好,算法我还没有自己跑起来过,之后有时间再测评下。
以上就是所有内容,有问题欢迎交流!
此外,对其他SLAM算法感兴趣的同学可以看考我的博客SLAM算法总结——经典SLAM算法框架总结