A Hybrid Attention Mechanism for Weakly-Supervised Temporal Action Localization 论文阅读
文章信息:
发表于:2021AAAI
原文链接:https://ojs.aaai.org/index.php/AAAI/article/view/16256
源码:https://github.com/asrafulashiq/hamnet

Abstract
弱监督时序动作定位是一项具有挑战性的视觉任务,因为训练视频中缺少动作的真实时序位置。在训练过程中仅有视频级别的监督,大多数现有方法依赖于多实例学习(MIL)框架来预测视频中每个动作类别的开始帧和结束帧。然而,现有的基于MIL的方法存在一个主要限制,即只能捕捉到动作的最具区分性的帧,而忽略了活动的完整范围。此外,这些方法无法有效地建模背景活动,而背景活动在定位前景活动中起着重要作用。在本文中,我们提出了一种名为HAM-Net的新框架,该框架具有混合注意力机制,包括时序软注意力、半软注意力和硬注意力,以解决这些问题。我们的时序软注意力模块在分类模块的辅助背景类的引导下,通过为每个视频片段引入“动作性”得分来建模背景活动。此外,我们的时序半软注意力和硬注意力模块为每个视频片段计算两个注意力得分,有助于关注动作的较不具区分性的帧,以捕捉完整的动作边界。我们的方法在THUMOS14数据集上以0.5的IoU阈值至少提高了2.2%的mAP,在ActivityNet1.2数据集上以0.75的IoU阈值至少提高了1.3%的mAP,优于最新的先进方法。
Introduction
时间动作定位是指预测视频中所有动作实例的开始和结束时间的任务。在完全监督的时间动作定位领域已经取得了显著进展(Tran等人,2020;Zhao等人,2017;Chao等人,2018;Lin等人,2018;Xu等人,2020)。然而,在视频数据集中标注所有动作实例的确切时间范围既昂贵又耗时,并且容易出错。相反,弱监督时间动作定位(WTAL)可以极大地简化数据收集和标注的成本。
WTAL(弱监督时间动作定位)的目标是在训练阶段仅给定视频级别的类别标签的情况下,定位并分类视频中的所有动作实例。大多数现有的WTAL方法依赖于多实例学习(MIL)范式(Paul, Roy, 和 Roy-Chowdhury 2018;Liu, Jiang, 和 Wang 2019;Islam 和 Radke 2020)。在这个范式中,视频由多个片段组成;计算片段级别的类分数,通常被称为类激活序列(CAS),然后在时间上进行池化以获得视频级别的类分数。通过设定阈值对片段级别的类分数进行筛选来生成动作提案。然而,这一框架存在一个主要问题:它不一定能捕获动作实例的全部范围。由于训练是为了最小化视频级别的分类损失,网络倾向于对动作中最具区分度的部分预测更高的CAS值,而忽视了区分度较低的部分。例如,一个动作可能由几个子动作组成(Hou, Sukthankar, 和 Shah 2017)。在MIL范式下,可能只会检测到特定的子动作,而忽略动作的其他部分。
图1:现有的多实例学习(MIL)框架不一定能捕捉到动作实例的全部范围。在这个潜水活动的示例中,(a)显示了真实定位,而(b)显示了基于MIL的弱监督时序动作定位(WTAL)框架的预测。MIL框架仅捕捉到潜水活动中最具区分性的部分,而忽略了完整动作的开始和结束部分。
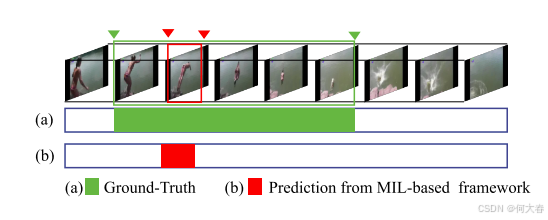
图1展示了一个潜水活动的示例。我们观察到,多实例学习(MIL)框架仅捕捉到整个潜水活动中最具区分性的位置。仅捕捉动作的最具区分性的部分就足以实现较高的视频级别分类准确率,但并不一定能够获得良好的时序定位性能。现有框架的另一个问题是无法有效地建模背景活动,从而导致时序定位预测中包含背景帧。先前的研究表明,背景活动在动作定位中起着重要作用(Lee, Uh, and Byun 2020)。如果不区分背景帧和前景帧,网络可能会包含背景帧以最小化前景分类损失,从而导致许多假阳性定位预测。
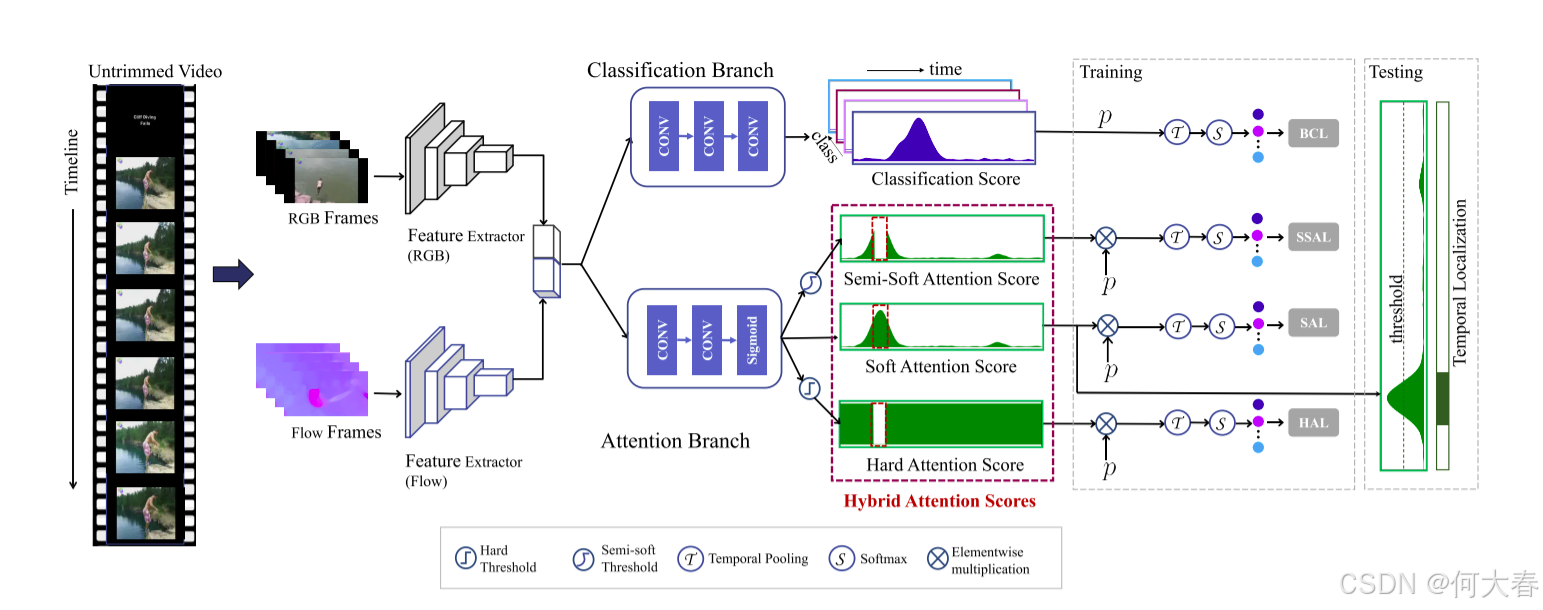
在本文中,我们提出了一种名为HAM-Net的新的弱监督时序动作定位(WTAL)框架,该框架具有混合注意力机制,可以解决上述问题。注意力机制已成功应用于深度学习(Islam et al. 2020;Vaswani et al. 2017;Shi et al. 2020)。如图2所示,HAM-Net产生软注意力、半软注意力和硬注意力,以检测动作实例的完整时序范围并对背景活动进行建模。
我们的框架包括(1)一个分类分支,用于预测包括背景活动在内的所有动作实例的类别激活得分;以及(2)一个注意力分支,用于预测视频片段的“动作性”得分。片段级别的类别激活得分也受到三个片段级别注意力得分的调节,并在时间上进行池化,以生成视频级别的类别得分。
为了捕捉完整的动作实例,我们舍弃视频中更具区分性的部分,而关注较不具区分性的部分。我们通过为视频中的所有片段计算半软注意力得分和硬注意力得分来实现这一点。半软注意力得分通过将软注意力得分大于阈值的片段的得分赋值为零,来舍弃视频中更具区分性的部分,而其他部分的得分与软注意力得分保持不变。由半软注意力引导的视频级别分类得分仅包含前景类别。另一方面,硬注意力得分舍弃视频中更具区分性的部分,并将较不具区分性的部分的注意力得分赋值为1,这确保了由此硬注意力引导的视频级别类别得分同时包含前景和背景类别。半软注意力和硬注意力都鼓励模型学习视频中动作的完整时序边界。
总之,我们的贡献有三方面:
-
我们提出了一种具有混合注意力机制的新颖框架,以对整个动作进行建模;
-
我们提出了一种背景建模策略,该策略使用辅助背景类别引导的注意力得分;
-
我们在THUMOS14(Jiang et al. 2014)和ActivityNet(Caba Heilbron et al. 2015)数据集上均取得了最先进的性能。具体来说,在THUMOS14数据集上,我们在IoU阈值为0.5时的平均精度(mAP)比最先进的方法高出2.2%;在ActivityNet1.2数据集上,我们在IoU阈值为0.75时的平均精度(mAP)比最先进的方法高出1.3%。
-
图2:我们提出的框架HAM-Net的概述。提取RGB帧和光流帧的片段级别特征,并分别输入到具有混合注意力机制的分类分支和注意力分支。计算三种注意力得分:软注意力、半软注意力和硬注意力,它们与片段级别分类得分相乘,以获得注意力引导的类别得分。该网络使用四种注意力引导的损失进行训练:基础分类损失(BCL)、软注意力损失(SAL)、半软注意力损失(SSAL)和硬注意力损失(HAL),以及稀疏损失和引导损失。
Related Work
Action Analysis with Full Supervision
由于基于深度学习的模型具有较强的表征能力,以及大规模数据集(Jiang et al. 2014;Caba Heilbron et al. 2015;Sigurdsson et al. 2016;Gu et al. 2018;Kay et al. 2017)的可用性,视频动作识别领域取得了显著进展。为了设计运动线索,双流网络(Simonyan and Zisserman 2014)将光流(Horn and Schunck 1981)作为与RGB帧分开的单独流纳入其中。3D卷积网络已经证明了对视频具有更好的表征能力(Carreira and Zisserman 2017;Tran et al. 2015, 2020)。对于全监督时序动作定位,最近的一些方法采用了两阶段策略(Tran et al. 2020;Zhao et al. 2017;Chao et al. 2018;Lin et al. 2018)。
Weakly Supervised Temporal Action Localization
就现有的弱监督时序动作定位(WTAL)方法而言,UntrimmedNets(Wang et al. 2017)引入了一个分类模块来预测每个片段的分类得分,以及一个选择模块来选择相关的视频片段。除此之外,STPN(Nguyen et al. 2018)增加了稀疏损失和特定类别的提议。AutoLoc(Shou et al. 2018)引入了外内对比损失来有效预测时序边界。W-TALC(Paul, Roy, and Roy-Chowdhury 2018)和Islam and Radke(Islam and Radke 2020)纳入了距离度量学习策略。
MAAN(Yuan et al. 2019)提出了一种新颖的边际平均聚合模块和潜在判别概率,以减少最显著区域与其他区域之间的差异。TSM(Yu et al. 2019)将每个动作实例建模为多阶段过程,以有效表征动作实例。WSGN(Fernando, Tan, and Bilen 2020)根据局部和全局统计信息为每个帧预测分配权重。DGAM(Shi et al. 2020)使用条件变分自动编码器(VAE)来分离注意力帧、动作帧和非动作帧。CleanNet(Liu et al. 2019)引入了一个动作提议评估器,该评估器利用片段中的时间对比度提供伪监督。3C-Net(Narayan et al. 2019)采用了三个损失项来确保可分离性、增强可判别性并描绘相邻动作序列。此外,BaS-Net(Lee, Uh, and Byun 2020)和Nguyen等人(Nguyen, Ramanan, and Fowlkes 2019)通过引入辅助背景类别来建模背景活动。然而,这些方法都没有明确解决对整个动作实例进行建模的问题。
为了建模动作的完整性,Hide-and-Seek(Singh and Lee 2017)隐藏了视频的一部分以发现其他相关部分,而Liu等人(Liu, Jiang, and Wang 2019)提出了一个多分支网络,其中每个分支预测不同的动作部分。我们的方法与之有着相似的动机,但不同之处在于,我们隐藏的是视频中最具判别性的部分,而不是随机部分。
Proposed Method
Problem Formulation
假设训练视频
V
V
V包含从
n
c
n_{c}
nc个活动类别中选择的活动实例。视频中某个特定活动可能出现多次。仅提供视频级别的
活动实例。将视频级别的活动实例表示为
y
∈
{
0
,
1
}
n
c
\mathbf{y}\in\{0,1\}^{n_c}
y∈{0,1}nc,其中,只有当视频中至少有一个第
j
j
j类活动的实例时,
y
j
=
1
y_j=1
yj=1,如果没有第
j
j
j类活动的实例,则
y
j
=
0
y_j=0
yj=0。请注意,既未提供视频中活动实例的频率,也未提供其顺序。我们的目标是创建一个模型,该模型仅使用视频级别的活动类别进行训练,并在评估期间预测活动实例的时间位置,即对于测试视频,它输出一组元组
(
t
s
,
t
c
,
ψ
,
c
)
(t_s,t_c,\psi,c)
(ts,tc,ψ,c),其中
t
v
t_v
tv和
t
c
t_c
tc是活动的开始帧和结束帧,
c
c
c是活动标签,
ψ
\psi
ψ是活动得分。
Snippet-Level Classification
在我们提出的 HAM-Net 中,如图 2 所示,对于每个视频,我们首先将其分割成不重叠的片段,以提取片段级特征。使用片段级表示而非帧级表示允许我们使用现有的 3D 卷积特征提取器,这些提取器可以有效地建模视频中的时间依赖性。按照动作识别的双流策略(Carreira and Zisserman 2017; Feichtenhofer, Pinz, and Zisserman 2016),我们分别为 RGB 和光流流提取片段级特征,分别表示为 x i R G B ∈ R D \mathbf{x}_i^{\mathrm{RGB}} \in \mathbb{R}^D xiRGB∈RD 和 x i F l o w ∈ R D \mathbf{x}_i^{\mathrm{Flow}} \in \mathbb{R}^D xiFlow∈RD。我们将两个流的特征连接起来,得到第 i i i 个片段的完整片段特征 x i ∈ R 2 D \mathbf{x}_i \in \mathbb{R}^{2D} xi∈R2D,从而得到一个包含外观和运动线索的片段特征的高级表示。
为了确定视频中所有活动的时间位置,我们从分类分支计算片段级分类得分,该分类分支是一个卷积神经网络,输出通常称为类别激活序列(CAS)的类别对数值(Shou et al. 2018)。我们将第
i
i
i 个片段的所有类别的片段级 CAS 表示为
s
i
∈
R
c
+
1
\mathbf{s}_i \in \mathbb{R}^{c+1}
si∈Rc+1。这里,第
c
+
1
c+1
c+1 类是背景类。由于我们只有视频级别的类别得分作为真实标签,我们需要将片段级别的得分
s
i
\mathbf{s}_i
si 汇总为视频级别的类别得分。文献中有几种汇总策略可以将片段级别得分汇总为视频级别得分。在我们的设置中,我们采用 top-k 策略(Islam and Radke 2020;Paul, Roy, 和 Roy-Chowdhury 2018)。具体来说,时间汇总是通过从时间维度中聚合每个类别的 top-k 值来完成的:
接下来,我们通过沿着类维度应用softmax操作来计算视频级别的类分数:
其中, j = 1, 2, . . . , c + 1.
基本分类损失计算为真实视频级分类分数
y
y
y与预测分数
p
p
p之间的交叉熵损失:
请注意,每个未经剪辑的视频都包含一些没有发生动作的背景部分。这些背景部分在分类分支中被建模为一个单独的类别。因此,真实标签背景类
y
c
+
1
=
1
y_{c+1} = 1
yc+1=1 在公式 3 中。该方法的一个主要问题是没有负样本供背景类使用,模型无法仅通过优化正样本来学习背景活动。为了解决这个问题,我们在注意力分支中提出了一种混合注意力机制,以进一步探索每个片段的“动作性”得分。

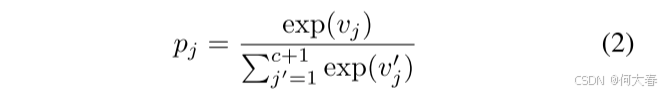

A Hybrid Attention Mechanism for Weak Supervision
为了从视频中抑制背景类别,我们结合了一个注意力模块,以区分前景和背景动作,这遵循了几篇弱监督动作检测论文中的背景建模策略(Nguyen, Ramanan, 和 Fowlkes 2019;Lee, Uh, 和 Byun 2020;Liu 等人 2019)。目标是对每个片段预测一个注意力得分,在没有活动实例(即背景活动)的帧中得分较低,在其他区域则得分较高。尽管分类分支可以预测片段中背景动作的概率,但一个独立的注意力模块在区分前景和背景类别方面更有效,原因有几点。首先,视频中的大多数动作发生在运动线索强烈的区域;注意力分支最初仅从运动特征就能检测到背景区域。其次,对于网络来说,学习两类(前景与背景)比在弱监督下学习大量的类别要容易得多。
Soft Attention Score
注意力模块的输入是片段级特征
x
i
x_i
xi,它返回单个前景注意力得分
a
i
a_i
ai:
其中,
a
i
∈
[
0
,
1
]
a_i\in[0,1]
ai∈[0,1],
g
(
⋅
;
Θ
)
g(\cdot;\Theta)
g(⋅;Θ) 是一个带有参数
Θ
\Theta
Θ 的函数,由两个时间卷积层和一个sigmoid激活层组成。
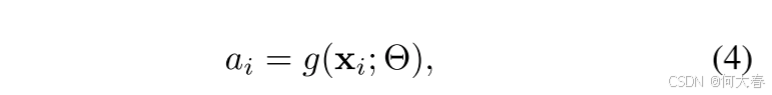
为了给背景类创建负样本,我们将每个类别
j
j
j 的片段级类别对数(即 CAS)
s
i
(
j
)
s_i(j)
si(j) 与第
i
i
i 个片段的片段级注意力得分
a
i
a_i
ai 相乘,得到注意力引导的片段级类别得分
s
i
attn
(
j
)
=
s
i
(
j
)
⊗
a
i
s_i^{\text{attn}}(j) = s_i(j) \otimes a_i
siattn(j)=si(j)⊗ai,其中
⊗
\otimes
⊗ 是按元素相乘的操作。
s
attn
s^{\text{attn}}
sattn 作为一组没有任何背景活动的片段,可以视为背景类的负样本。按照公式 1 和 2,我们得到类别标签
j
j
j 的视频级注意力引导类别得分
p
j
attn
p_j^{\text{attn}}
pjattn:
其中,
j
=
1
,
2
,
…
,
c
+
1
j = 1, 2, \ldots, c + 1
j=1,2,…,c+1。注意,
p
j
attn
p_j^{\text{attn}}
pjattn 不包含任何背景类,因为背景类已经被注意力得分
a
i
a_i
ai 抑制。根据
p
j
attn
p_j^{\text{attn}}
pjattn,我们计算软注意力引导损失(SAL)函数,
这里,
y
j
f
y^f_j
yjf只包含前景活动,即背景类
y
c
+
1
f
=
0
y^f_{c+1} = 0
yc+1f=0,因为注意得分抑制了背景活动。

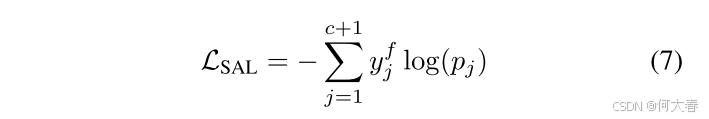
Semi-Soft Attention Score
给定第i个片段的片段级类分数
s
i
s_i
si和软注意分数
a
i
a_i
ai,我们通过将软注意
a
i
a_i
ai的阈值设为特定值
γ
∈
[
0
,
1
]
\gamma\in[0,1]
γ∈[0,1]]来计算半软注意分数。
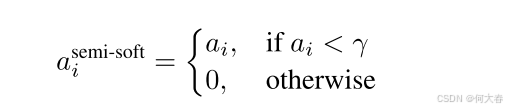
注意,半软注意力
a
i
s
e
m
i
−
s
o
f
t
a_i^\mathrm{semi-soft}
aisemi−soft 会同时丢弃最具判别力的区域,并且只关注前景片段;因此,半软注意力引导的视频级类别得分将只包含前景活动。这种设计有助于更好地建模背景,正如消融研究部分所讨论的那样。将与半软注意力相关的视频级类别得分表示为
p
j
s
e
m
i
−
s
o
f
t
p_j^\mathrm{semi-soft}
pjsemi−soft,其中
j
=
1
,
2
,
…
,
c
+
1
j=1,2,\ldots,c+1
j=1,2,…,c+1。我们计算半软注意力损失:
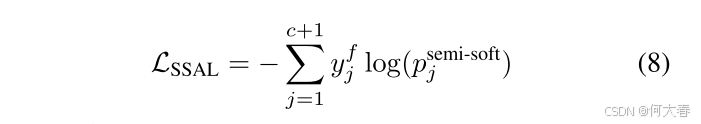
其中 y f y^f yf是不包含背景活动的真实标签,即 y c + 1 f = 0 y_{c+1}^f=0 yc+1f=0,因为半软注意力在抑制背景片段的同时也会去除最具辨别力的区域。
Hard Attention Score
与半软注意相比,硬注意得分的计算方法为
使用硬注意力得分,我们通过将它们与原始片段级对数
s
i
(
j
)
s_i(j)
si(j) 相乘并按照公式 1 和公式 2 对得分进行时间汇总,得到另一组视频级类别得分。我们计算硬注意力损失:
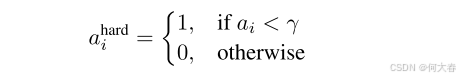
其中
y
y
y是具有背景活动的真实标签,即
y
c
+
1
=
1
y_{c+1} = 1
yc+1=1,因为硬注意不会抑制背景片段,相反,它只会去除视频中更具歧视性的区域。
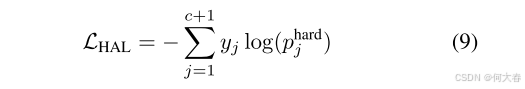
Loss Functions
最后,我们使用以下联合损失函数来训练我们提出的HAM-Net:
其中,
L
s
p
a
r
s
e
是稀疏损失,
L
g
u
i
d
e
是引导损失,
λ
0
,
λ
1
,
λ
2
,
λ
3
,
α
,
和
β
是超参数。
\begin{aligned} &\text{其中,}\mathcal{L}_\mathrm{sparse}\text{是稀疏损失,}\mathcal{L}_\mathrm{guide}\text{是引导损失,}\lambda_0, \lambda_1, \lambda_2, \lambda_3, \alpha,\text{和}\beta\text{是超参数。}\end{aligned}
其中,Lsparse是稀疏损失,Lguide是引导损失,λ0,λ1,λ2,λ3,α,和β是超参数。
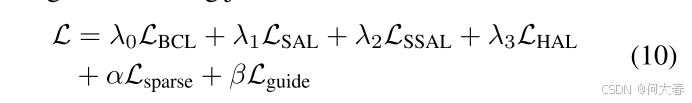
稀疏损失 L s p a r s e \mathcal{L}_\mathrm{sparse} Lsparse 基于以下假设:一个动作可以从视频片段的稀疏子集中识别出来 (Nguyen et al. 2018)。稀疏损失是通过软注意力得分的 L1 范数计算得到的:
关于引导损失
L
g
u
i
d
e
\mathcal{L}_\mathrm{guide}
Lguide,我们将软注意力得分
a
i
a_i
ai 视为每个片段的二元分类得分,其中只有两个类别,前景和背景,它们的概率分别由
a
i
a_i
ai 和
1
−
a
i
1 - a_i
1−ai 捕捉。因此,
1
−
a
i
1 - a_i
1−ai 可以被视为第
i
i
i 个片段包含背景活动的概率。另一方面,背景类别也由类别激活对数
s
i
(
⋅
)
∈
R
c
+
1
s_i(\cdot) \in \mathbb{R}^{c+1}
si(⋅)∈Rc+1 捕捉。为了引导背景类别激活遵循背景注意力,我们首先计算特定片段是背景活动的概率,
然后加上引导损失,使得背景类概率与背景关注的绝对差值最小:
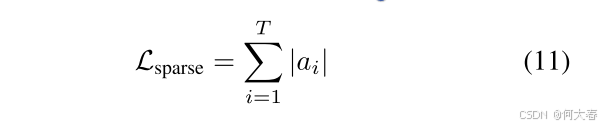
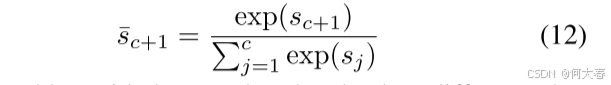
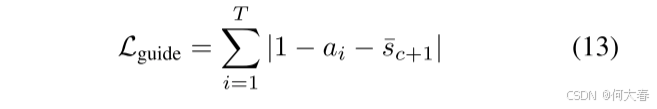
Temporal Action Localization
对于时间定位,我们首先丢弃视频级别类别得分小于特定阈值(在我们的实验中设置为0.1)的类别。对于剩余的类别,我们通过对所有片段 i i i 的软注意力得分 a i a_i ai 进行阈值处理,丢弃背景片段,并通过选择剩余片段的一维连通组件来获得类无关的动作提议。将候选动作位置记为 { ( t s , t e , ψ , c ) } \{(t_s, t_e, \psi, c)\} {(ts,te,ψ,c)},其中 t s t_s ts 是开始时间, t e t_e te 是结束时间, ψ \psi ψ 是类别 c c c 的分类得分。我们按照 AutoLoc(Shou et al. 2018)的外部-内部得分计算分类得分。注意,在计算类别特定得分时,我们使用注意力引导的类别对数 s attn c s_{\text{attn}}^c sattnc,
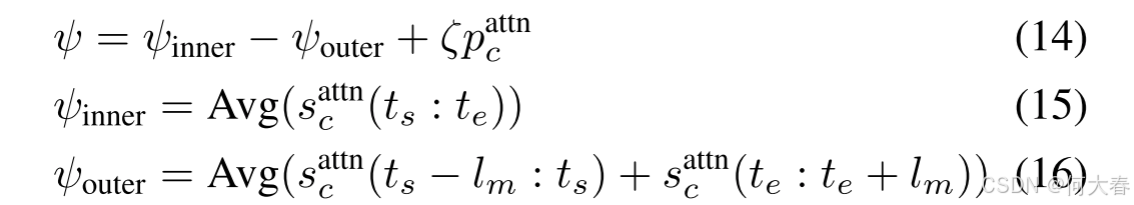
其中, ζ \zeta ζ 是超参数, l m = ( t e − t s ) / 4 l_m = (t_e - t_s) / 4 lm=(te−ts)/4, p c attn p_c^\text{attn} pcattn 是类别 c c c 的视频级得分, s c a t t n ( ⋅ ) s_c^\mathrm{attn}(\cdot) scattn(⋅) 是类别 c c c 的片段级类别对数。我们应用不同的阈值来获取动作提议,并使用非极大值抑制去除重叠的片段。
Experiments
Experimental Settings
Datasets
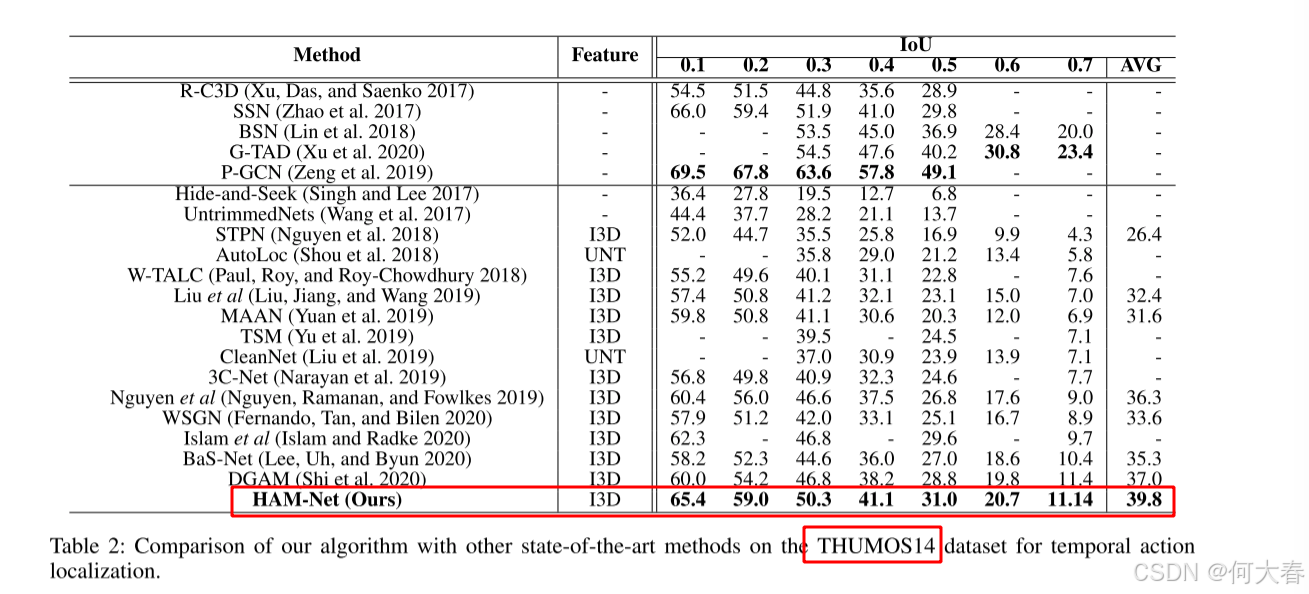
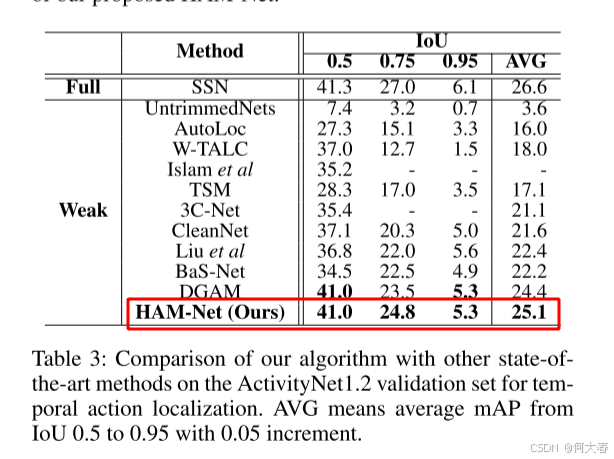
我们在两个流行的动作定位数据集上评估了我们的方法:THUMOS14 (Jiang et al. 2014) 和 ActivityNet1.2 (Caba Heilbron et al. 2015)。THUMOS14 包含 200 个用于训练的验证视频和 213 个用于测试的测试视频,涵盖 20 个动作类别。这个数据集具有挑战性,每个视频大约包含 15.5 个活动片段和 71% 的背景活动。ActivityNet1.2 数据集包含 4,819 个用于训练的视频和 2,382 个用于测试的视频,涵盖 200 个动作类别。每个视频大约包含 1.5 个活动实例(稀疏程度是 THUMOS14 的 10 倍)和 36% 的背景活动。
Evaluation Metrics
为了评估,我们使用标准协议并报告在不同交并比 (IoU) 阈值下的平均精度 (mAP)。使用 ActivityNet (Caba Heilbron et al. 2015) 提供的评估代码来计算评估指标。
Implementation Details
对于特征提取,我们将视频流采样成无重叠的16帧块,适用于RGB和光流流。光流流使用TV-L1算法(Wedel et al. 2008)创建。我们使用在Kinetics数据集(Kay et al. 2017)上预训练的I3D网络(Carreira and Zisserman 2017)提取RGB和光流特征,并将它们连接起来以获得2048维的片段级特征。在训练过程中,我们随机采样500个THUMOS14片段和80个ActivityNet片段,而在评估过程中,我们取所有片段。分类分支设计为两个卷积核大小为3的时间卷积层,每个层后跟一个LeakyReLU激活层,以及一个最终的线性全连接层用于预测类别对数。注意力分支由两个卷积核大小为3的时间卷积层组成,后接一个sigmoid层以预测0到1之间的注意力得分。
我们使用 Adam (Kingma and Ba 2015) 优化器,学习率为 0.00001,并对 THUMOS14 训练 100 个周期,对 ActivityNet 训练 20 个周期。对于 THUMOS14,我们设置 λ 0 = λ 1 = 0.8 , λ 2 = λ 3 = 0.2 , α = β = 0.8 , γ = 0.2 \lambda_0 = \lambda_1 = 0.8, \lambda_2 = \lambda_3 = 0.2, \alpha = \beta = 0.8, \gamma = 0.2 λ0=λ1=0.8,λ2=λ3=0.2,α=β=0.8,γ=0.2, 以及用于 top-k 时间池化的 k = 50 k = 50 k=50。对于 ActivityNet,我们设置 α = 0.5 , β = 0.1 , λ 0 = λ 1 = λ 2 = λ 3 = 0.5 \alpha = 0.5, \beta = 0.1, \lambda_0 = \lambda_1 = \lambda_2 = \lambda_3 = 0.5 α=0.5,β=0.1,λ0=λ1=λ2=λ3=0.5, 以及 k = 4 k = 4 k=4, 并应用额外的平均池化来后处理最终的 CAS。所有超参数均通过网格搜索确定。对于动作定位,我们将阈值从 0.1 到 0.9,步长为 0.05,并执行非极大值抑制以移除重叠的片段。
Conclusion
我们提出了一种名为 HAM-Net 的新框架,用于从仅有的视频级监督中学习时间动作定位。我们引入了一种混合注意机制,包括软注意、半软注意和硬注意,分别用于区分背景帧和前景帧,以及捕捉视频中动作的完整时间边界。我们进行了广泛的分析,以展示我们方法的有效性。我们的方法在 THUMOS14 和 ActivityNet1.2 数据集上均达到了最新的性能水平。
阅读总结
这个硬注意力,和软注意力相比,就是把最具判别性的片段给抹去了,把不是很有判别性的片段给拉高了,认为这些片段存在背景标签,但这这为啥叫去除了视频中更具有歧视性的区域呢?

和20年AAAI的那篇Background Suppression Network for Weakly-Supervised Temporal Action Localization一样,都是因为背景类没有负样本,通过注意力弄了一个背景类的负样本。