Abstract
无监督视觉表示学习因对比学习的最新成就而受到计算机视觉领域的广泛关注。现有的大多数对比学习框架采用实例区分作为预设任务,将每个实例视为一个不同的类。然而,这种方法不可避免地会导致类别冲突问题,从而损害所学习表示的质量。基于这一观察,我们引入了一种弱监督对比学习框架(WCL)来解决这一问题。具体而言,我们提出的框架基于两个投影头,其中一个执行常规的实例区分任务。另一个投影头将使用基于图的方法来探索相似样本并生成弱标签,然后基于弱标签执行监督对比学习任务,以拉近相似图像的距离。我们进一步引入了一种基于K近邻的多裁剪策略来扩展正样本的数量。大量实验证明,WCL提高了不同数据集上自监督表示的质量。值得注意的是,我们在半监督学习中获得了新的最先进结果。使用仅1%和10%的标记样本,WCL在ImageNet上使用ResNet50分别达到了65%和72%的Top-1准确率,这甚至比使用ResNet101的SimCLRv2还要高。
1. Introduction

图1. 类别冲突问题的一个例子。典型的实例区分方法会将第一列和第三列视为负对,因为它们是不同的实例。然而,第一列和第三列的语义信息非常相似,将它们视为正对会更加合理。
现代深度卷积神经网络在各种计算机视觉数据集[11, 15, 30]和边缘设备[45, 36, 44, 35]上展示了出色的性能。然而,大多数成功的方法都是在监督方式下训练的;它们通常需要大量的标注数据,而这些数据非常难以收集。同时,数据标注的质量会显著影响性能。最近,自监督学习展示了其优越性,并在计算机视觉的无监督和半监督学习中取得了令人瞩目的成果(例如[6, 7, 19, 8, 9, 5, 18, 50])。这些方法无需标签即可学习通用的视觉表示,并在线性分类和迁移到不同任务或数据集时表现良好。值得注意的是,近期自监督表示学习框架的大部分基于对比学习的理念。
一种典型的基于对比学习的方法采用噪声对比估计(NCE)[27] 来执行非参数实例区分[41] 作为预设任务,它鼓励同一图像的两个增强视图在嵌入空间上靠近,但将所有其他图像分开。最近的大多数研究主要通过改进正样本的图像增强和负样本的探索来提高对比学习的性能。然而,基于实例区分的方法不可避免地会引发类别冲突问题,这意味着即使是非常相似的实例,它们仍然需要被分开,如图1所示。这种实例相似性往往会损害表示的质量[1]。因此,识别并利用这些相似实例在学习表示的性能中起着关键作用。
令人惊讶的是,在对比学习中,类别冲突问题似乎没有受到太多关注。据我们所知,几乎没有努力去识别相似样本。AdpCLR [49] 在嵌入空间中找到最接近的K个样本,并将这些样本视为正样本。然而,在训练的早期阶段,模型无法有效地从图像中提取语义信息;因此,该方法需要使用SimCLR [6] 进行一段时间的预训练,然后切换到AdpCLR以获得最佳性能。FNCancel [23] 提出了类似的想法,但采用了完全不同的方法来找到最相似的K个实例;具体而言,对于每个样本,它生成一个支持集,其中包含同一图像的不同增强视图,然后使用均值或最大聚合策略计算支持集中增强视图之间的余弦相似度分数,最终识别出最相似的K个样本。然而,在他们的实验中,最佳支持集大小是8,这需要8次额外的前向传递来生成嵌入向量。显然,这些方法有两个缺点。首先,它们都非常耗时。其次,最接近的 K K K个样本的结果可能不是互惠的,即 x i x_i xi是 x j x_j xj的 K K K个最接近样本,但 x j x_j xj可能不是 x i x_i xi的 K K K个最接近样本。在这种情况下, x j x_j xj会将 x i x_i xi视为正样本,但 x i x_i xi会将 x j x_j xj视为负样本,这将导致一些冲突。
在本文中,我们将实例相似性视为表示学习中的内在弱监督,并提出了一种弱监督对比学习框架(WCL)以相应地解决类别冲突问题。在WCL中,假设相似的实例相较于其他实例具有相同的弱标签,并且期望具有相同弱标签的实例聚集在一起。为了确定弱标签,我们将每批实例建模为一个最近邻图;弱标签因此通过图的每个连通分量确定,并且是互惠的。此外,我们还可以通过基于KNN的多裁剪策略扩展图以传播弱标签,这样每个弱标签可以有更多的正样本。通过这种方式,具有相同弱标签的相似实例可以通过监督对比学习任务[25]拉近距离。然而,由于挖掘出的实例相似性可能存在噪声且不完全可靠,实际上,我们采用了一个双头框架,其中一个处理这个弱监督任务,另一个执行常规的实例区分任务。大量实验表明,我们提出的方法在不同设置和各种数据集上的有效性。
我们的贡献可概括如下:
- 我们提出了一种基于双头的框架来解决类别冲突问题,一个头侧重于实例区分,另一个头用于吸引相似样本。
- 我们提出了一种简单的基于图的方法,无需参数即可自适应地找到相似样本。
- 我们引入了一种基于K近邻的多裁剪策略,这种策略比标准的多裁剪策略能够提供更多样化的信息。
- 实验结果表明,WCL为基于对比学习的方法建立了新的最先进性能。使用仅1%和10%的标记样本,WCL在ImageNet上使用ResNet50分别达到了65%和72%的Top-1准确率。值得注意的是,这一结果甚至高于使用ResNet101的SimCLRv2。
2. Related Work
Self-Supervised Learning. 早期的自监督学习工作主要集中在设计不同的预设任务。例如,预测一对图像块的相对偏移[12]、解决拼图游戏[33]、为灰度图像着色[48]、图像修补[14]、预测旋转角度[16]、无监督深度聚类[4]和图像重建[2, 17, 13, 3, 28]。虽然这些方法已显示其有效性,但它们所学习的表示缺乏通用性。
Contrastive Learning. 对比学习 [27, 21, 41, 40] 已成为自监督学习领域中最成功的方法之一。如前所述,最近的大多数工作主要集中在正样本的增强和负样本的探索。例如,SimCLR [6] 提出了数据增强的组合,如灰度化、随机裁剪、颜色抖动和高斯模糊,以使模型对这些变换具有鲁棒性。InfoMin [37] 进一步引入了“InfoMin 原则”,该原则建议好的增强策略应该减少正样本对之间的互信息,同时保持与下游任务相关的信息不变。为了探索负样本的使用,InstDisc [41] 提出了一个存储数据集中所有图像表示的记忆库。MoCo [19, 8] 通过使用动量对比机制增加负样本的数量,该机制迫使查询编码器从缓慢进展的关键编码器中学习表示,并维护一个长队列以提供大量负样本。
Contrastive Learning Without Negatives.与典型的对比学习框架不同,BYOL [18] 可以在没有负样本的情况下学习高质量的视觉表示。具体而言,它训练一个在线网络去预测同一图像在不同增强视图下的目标网络表示,并在在线编码器之上使用一个额外的预测网络来避免模型崩溃。SimSiam [9] 扩展了BYOL,进一步探索了对比学习中的孪生结构。令人惊讶的是,SimSiam 即使在没有目标网络和大批量的情况下也能防止模型崩溃;尽管线性评估结果低于BYOL,但在下游任务中表现更好。
3. Method
在本节中,我们将首先回顾对比学习的基础工作并讨论其局限性。然后,我们将介绍我们提出的弱监督对比学习框架(WCL),该框架在进行实例区分的同时自动挖掘相似样本。之后,我们还将解释算法和实现细节。
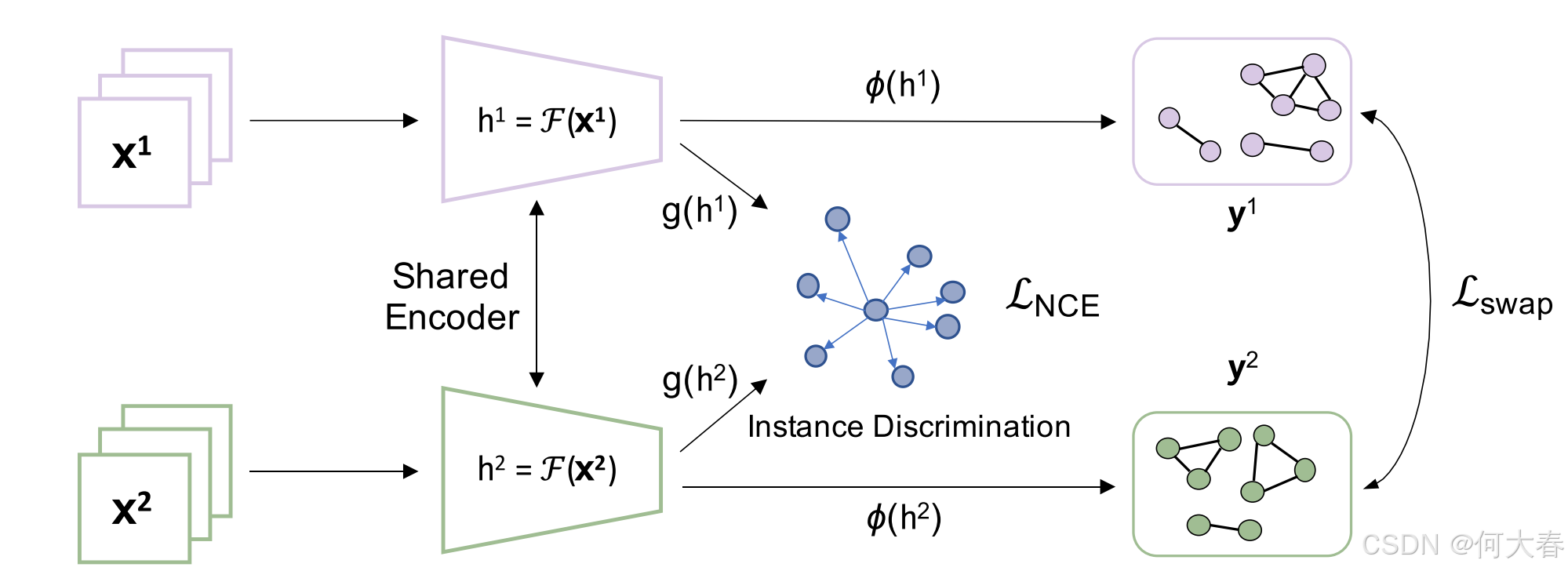
图 2. 我们提出的方法的整体框架。我们采用了一个基于双头结构( g g g 和 ϕ \phi ϕ)。第一个头 g g g 将执行常规的实例区分任务。第二个头 ϕ \phi ϕ 将基于连通组件标记过程生成弱标签,然后利用该弱标签执行监督对比学习任务。详细信息请参见第 3 节。
3.1. Revisiting Contrastive Learning
典型的对比学习方法采用噪声对比估计(NCE)目标来区分数据集中不同的实例。具体来说,NCE目标鼓励相同实例的不同增强在潜在空间中靠近,同时推开不同实例的增强。按照SimCLR的设置,随机应用增强函数的组合 T ( ⋅ ) T(\cdot) T(⋅) 来获得相同实例的两种不同视图,可以表示为 { x 1 } i = 1 N = T ( x , θ 1 ) \left\{\mathbf{x}^1\right\}_{i=1}^N=T(\mathbf{x},\theta_1) {x1}i=1N=T(x,θ1) 和 { x 2 } i = 1 N = T ( x , θ 2 ) \left\{\mathbf{x}^2\right\}_{i=1}^N=T(\mathbf{x},\theta_2) {x2}i=1N=T(x,θ2),其中 θ \theta θ 是 T T T 的随机种子。然后,一个基于卷积神经网络的编码器 F ( ⋅ ) \mathcal{F}(\cdot) F(⋅) 将从不同的增强中提取信息,可以表示为 { h 1 } = F ( { x 1 } i = 1 N ) \{\mathbf{h}^1\}=\mathcal{F}(\{\mathbf{x}^1\}_{i=1}^N) {h1}=F({x1}i=1N) 和 { h 2 } = F ( { x 2 } i = 1 N ) \{\mathbf{h}^2\}=\mathcal{F}(\{\mathbf{x}^2\} _{i=1}^N) {h2}=F({x2}i=1N)。最后,一个非线性投影头 z = g ( h ) z=g(\mathbf{h}) z=g(h) 将表示 h h h 映射到应用NCE目标的空间。如果我们将 ( z i , z j ) (\mathbf{z}_i,\mathbf{z}_j) (zi,zj) 表示为一个正对,则NCE目标可以表示为:
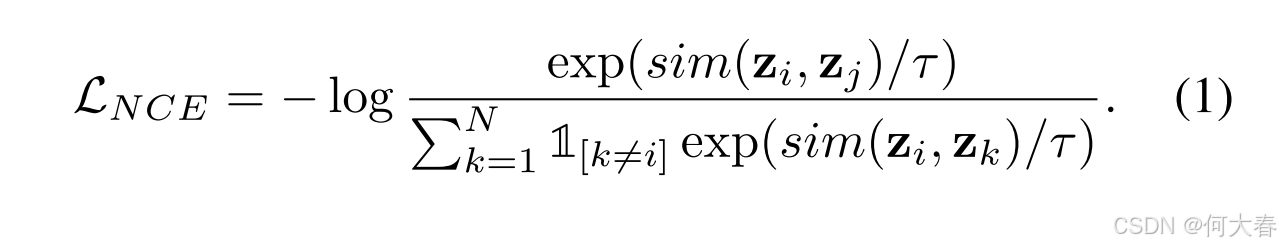
3.2. Instance Similarities as Weak Supervision
基于实例区分的方法已经在无监督预训练中表现出令人鼓舞的性能。然而,这种解决方案忽略了不同图像之间的关系,因为只有来自同一图像的增强才会被视为同一类。受到之前工作的启发,我们可以利用嵌入向量来探索不同图像之间的关系。具体而言,我们将基于嵌入向量生成一个弱标签,然后将其用作监督信号,在嵌入空间中吸引相似的样本。然而,直接使用弱监督会导致两个问题。首先,“实例区分”和“相似样本吸引”之间存在天然的冲突,因为前者想要推开所有不同的实例,而后者想要拉近相似样本。其次,弱标签中可能存在噪声,尤其是在训练的早期阶段。仅仅基于弱标签吸引相似样本会减缓模型的收敛速度。
Two-head framework.为了解决这些问题,我们提出了一个辅助投影头 ϕ(·)。在这种情况下,主要投影头 g(·) 将继续执行常规的实例区分任务,专注于实例级别的信息;辅助投影头与 g(·) 具有相同的结构,将探索相似样本并生成弱标签,作为吸引相似样本的监督信号。通过这两个具有不同职责的投影头,我们可以进一步将编码器
F
\mathcal{F}
F 提取的特征转换到不同的嵌入空间,从而解决冲突。此外,即使弱标签存在一些噪声,主要投影头也能确保模型的收敛。从辅助投影头提取的信息可以表示为:
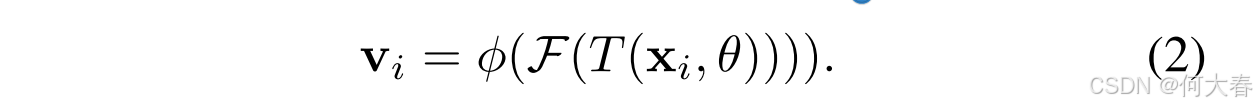
假设我们已经基于 v 获得了一个弱标签
y
∈
R
N
×
N
\mathbf{y}\in\mathbb{R}^{N\times N}
y∈RN×N,该标签表示样本对是否相似(即
y
i
j
=
1
\mathbf{y}_{ij}=1
yij=1 表示
x
i
\mathbf{x}_i
xi 和
x
j
\mathbf{x}_j
xj 是相似的)。不同于通过增强自然形成正样本对的 Eq. (1),我们可以利用标签
y
i
j
\mathbf{y}_{ij}
yij 来指示
x
i
\mathbf{x}_i
xi 和
x
j
\mathbf{x}_j
xj 是否可以生成正样本对。通过在 Eq. (1) 中引入指示符
1
y
i
j
=
1
1_{\mathbf{y}_{ij}=1}
1yij=1,我们实现了监督对比损失【25】。
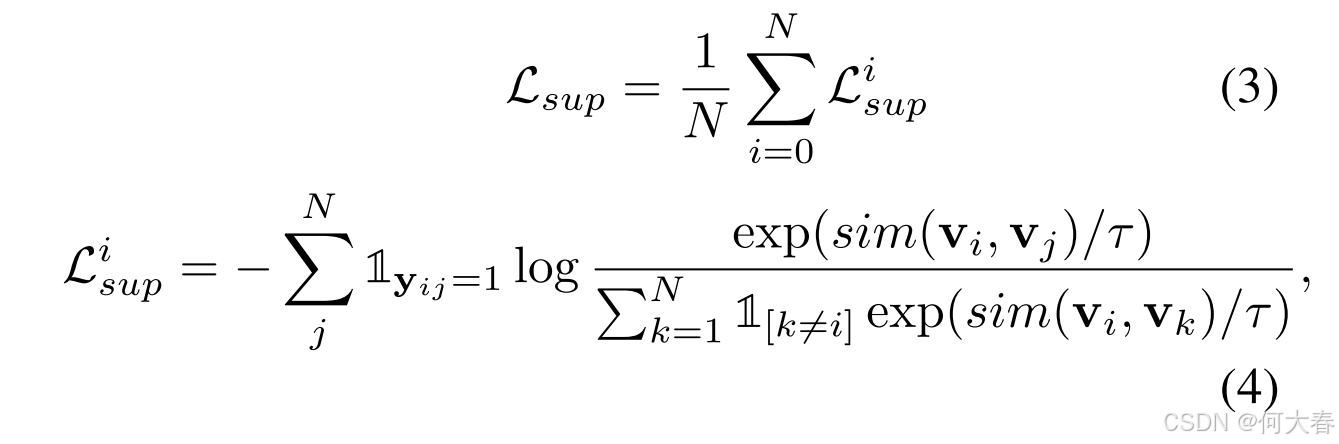
这已被证明比传统的监督交叉熵损失更有效。
3.3. Weak Label Generation
在本节中,我们将详细说明如何为小批量样本生成弱标签。总体思路可以总结为两点:首先,对于每个样本,最近的样本可以被视为相似样本。其次,如果 ( x i x_i xi, x j x_j xj) 和 ( x j x_j xj, x k x_k xk) 是两对相似样本,那么我们可以认为 x i x_i xi 和 x k x_k xk 也是相似的。
假设我们使用辅助投影头 ϕ \phi ϕ 将一批样本映射为 N N N 个嵌入 V = { v 1 , v 2 , . . . , v N } V=\{\mathbf{v}_1,\mathbf{v}_2,...,\mathbf{v}_N\} V={v1,v2,...,vN}。然后,对于每个样本 v i \mathbf{v}_i vi,通过计算余弦相似度得出最接近的样本 v j \mathbf{v}_j vj。现在,我们可以定义一个邻接矩阵:
在这里,我们用
k
i
1
k_i^1
ki1 表示
v
i
\mathbf{v}_i
vi 的最近邻样本。基本上,方程 (5) 将生成一个稀疏且对称的 1-最近邻图,其中每个顶点都与其最接近的样本相连。为了找到所有相似的样本,我们可以将这个问题转换为一个连通分量标记 (CCL) 过程;也就是说,对于每个样本,我们希望根据 1-最近邻图找到所有可达的样本。这是一个传统的图问题,可以通过著名的 Hoshen-Kopelman 算法 [22](也称为双遍算法)轻松解决。我们定义一个无向图
G
=
(
V
,
E
)
G=(V,E)
G=(V,E),其中
V
V
V 是从
ϕ
\phi
ϕ 映射得到的嵌入向量,边
E
E
E 连接顶点
A
(
i
,
j
)
=
1
A(i,j)=1
A(i,j)=1。该算法采用了包含三个操作的并查集数据结构:makeSet、union 和 find(见算法
1
\color{red}1
1 的定义)。基本上,它首先为
V
V
V 中的每个
v
\mathbf{v}
v 创建一个单例集合,然后遍历
E
E
E 中的每条边,通过边合并不同的集合;最后,它返回属于每个顶点的集合。回到我们提出的想法,我们将把同一集合中的样本视为相似的样本。现在,弱标签可以定义为:
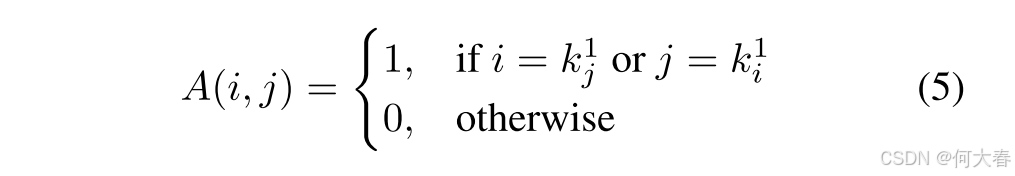
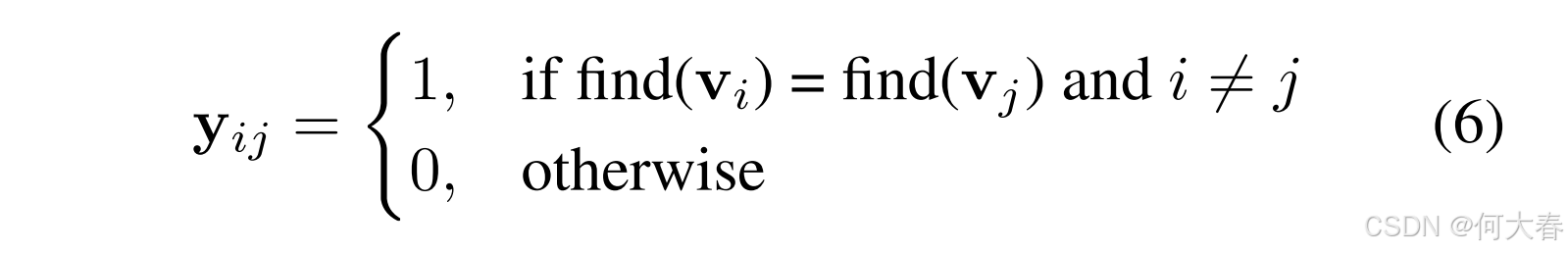
这种弱标签生成方法具有若干优点:
- 这是一个无参数的过程,所以我们不需要任何超参数优化。
- 基于无向图和连通分支的定义,弱标签总是互逆的。(既 y i j y_{ij} yij = y j i y_{ji} yji)
- 这是一个确定性的过程;最终结果不依赖于任何初始状态。

弱标签将被用作辅助投影头 ϕ \phi ϕ 的监督信号。然而,如果 v i \mathbf{v}_i vi 和 v j \mathbf{v}_j vj 在同一个集合中,则 s i m ( v i , v j ) sim(\mathbf{v}_i, \mathbf{v}_j) sim(vi,vj) 很可能是一个很大的数值。根据方程 (4),直接使用弱标签会导致 L s u p \mathcal{L}_{sup} Lsup 非常小,这不利于模型的优化。为了解决这个问题,我们可以简单地交换弱标签,以监督同一批次样本的不同增强版本。具体地,我们从两种增强中提取嵌入 V 1 \mathbf{V}^1 V1 和 V 2 \mathbf{V}^2 V2,并基于此生成相应的弱标签 y 1 \mathbf{y}^1 y1 和 y 2 \mathbf{y}^2 y2。然后, y 1 \mathbf{y}^1 y1 将作为 V 2 \mathbf{V}^2 V2 的监督信号,反之亦然。交换版本的方程 (3) 可以写作:
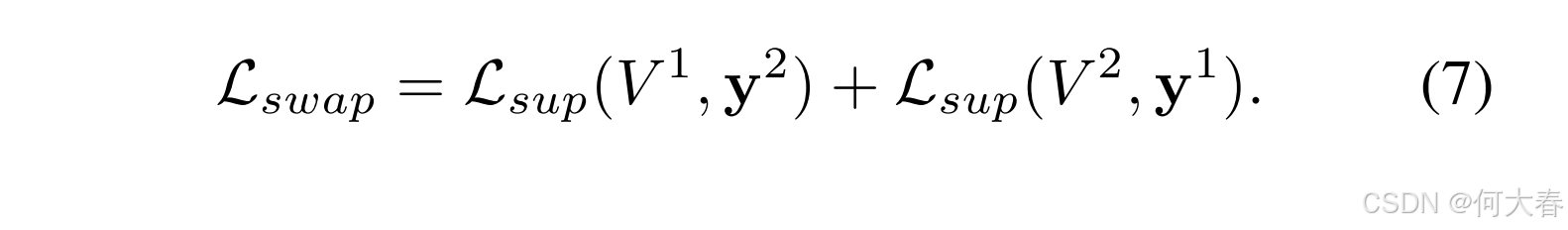
3.4. Label Propagation with Multi-Crops
由于随机裁剪图像之间的比较在对比学习中扮演着关键角色,许多先前的工作[10]指出,增加裁剪或视图的数量可以显著提高表示质量。SwAV [5] 引入了一种多裁剪策略,每个批次中添加了 K 个额外的低分辨率裁剪。使用低分辨率图像可以大大降低计算成本。然而,来自同一图像的多个裁剪可能会有许多重叠区域。在这种情况下,更多的裁剪可能不会提供额外的有效信息。为了解决这个问题,我们提出了一种基于 K 最近邻(K-NN)的多裁剪策略。具体而言,我们将为每个批次存储特征 h 1 \mathbf{h}_1 h1,然后在每个 epoch 结束时使用这些特征根据余弦相似度找到 K 个最接近的样本。最后,我们将在下一个 epoch 中使用这 K 个最接近图像的低分辨率裁剪。如果我们在 K-NN 多裁剪上应用 L s w a p \mathcal{L}_{swap} Lswap,那么正样本的数量可以扩展到 K 倍。需要注意的是,K-NN 的结果在训练初期可能不可靠;因此,我们应该先使用标准的多裁剪策略对模型进行预热,经过一定数量的 epoch 后再切换到我们的 K-NN 多裁剪策略以获得更好的性能(详细信息见我们的实验部分)。如果我们使用 L c N C E \mathcal{L}_{cNCE} LcNCE 和 L c s w a p \mathcal{L}_{cswap} Lcswap 分别表示多裁剪图像的对比损失和交换损失,那么我们弱监督对比学习框架的整体训练目标可以表示为:
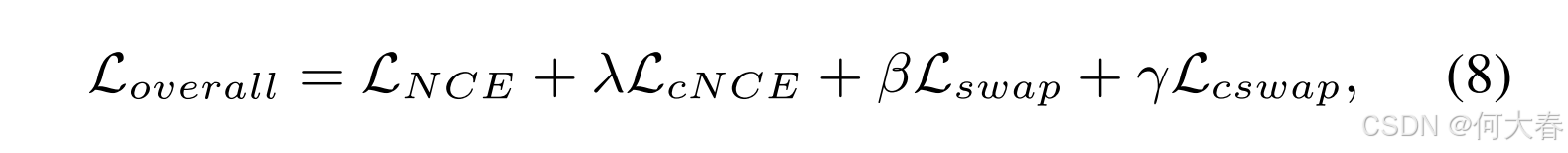

其中λ、β和γ是超参数。在我们的实现中,我们简单地取λ = 1,β = 0.5和γ = 0.5。请参阅算法2中的更多细节。
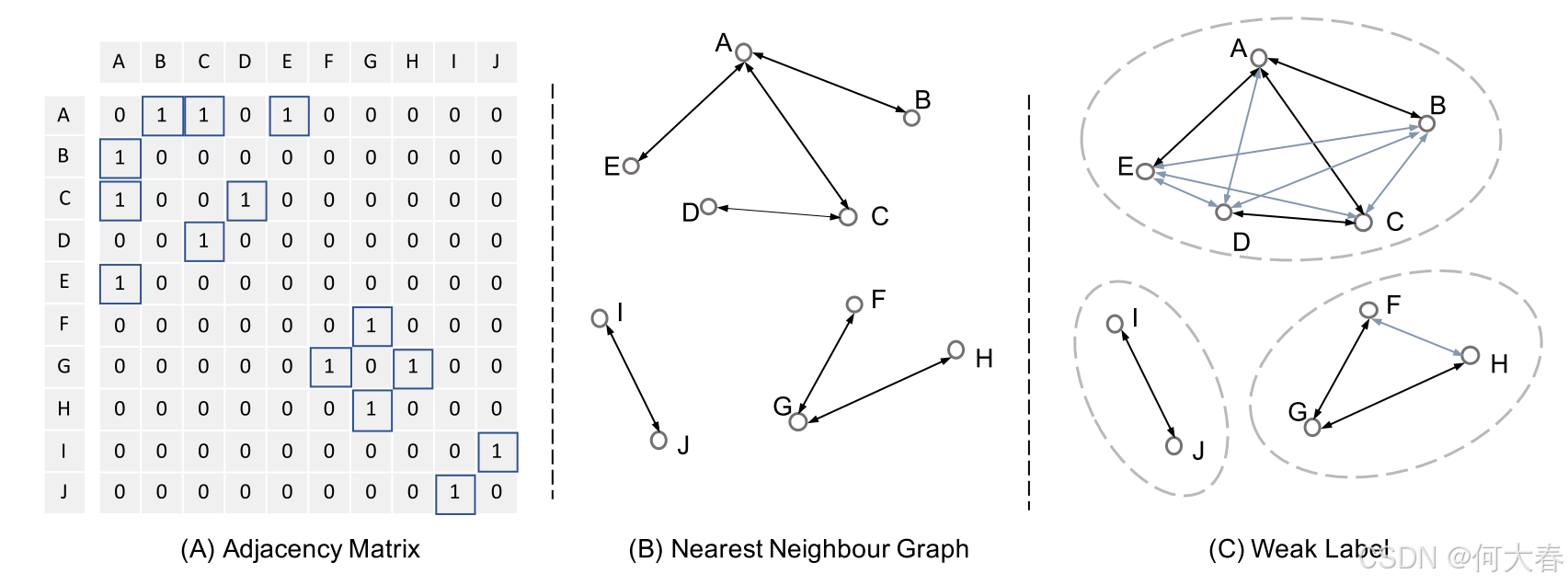
图3.弱标签的生成过程。
4. Experimental Results
结果不看了吧,我也看不明白。
5. Conclusion
在这项工作中,我们提出了一个弱监督对比学习框架,该框架由两个投影头组成,其中一个专注于实例区分任务,另一个头采用连通组件标记过程生成弱标签,然后通过将弱标签交换到不同的增强中来执行监督对比学习任务。最后,我们引入了一种基于 K-NN 的多裁剪策略,该策略具有更多有效信息并将正样本的数量扩大到 K 倍。在 CIFAR-10、CIFAR-100 和 ImageNet-100 上的实验表明了每个组件的有效性。半监督学习和迁移学习的结果证明了无监督表示学习的最新性能。
阅读总结
不同实例之间的相似性挖掘感觉还是可以借鉴一下的。