本文首发于公众号【DeepDriving】,欢迎关注。
1. 前言
FastBEV在M2BEV的基础上对视图变换方法做了一些优化,加入BEVDet4D中的时序融合方法,是一个高性能、推理速度快、部署友好的BEV感知算法。
在读FastBEV的论文之前可以先看一下相关的论文:
2. 实现细节
FastBEV模型的总体框架如下图所示,模型以多张不同视角的图像作为输入,输出目标物体的3D检测框(包括速度)。
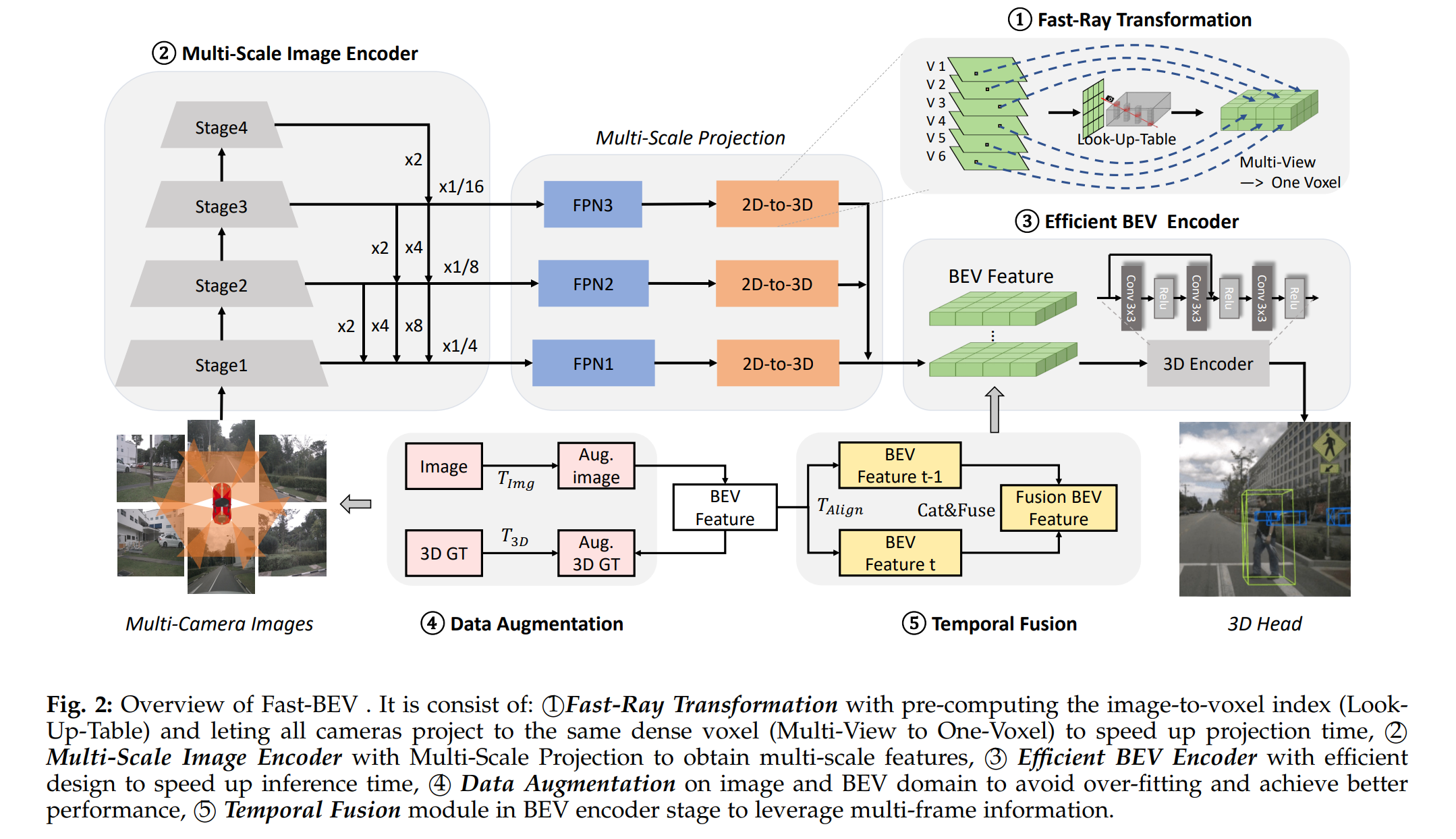
整个模型分为以下几个主要模块:
2.1 Fast-Ray视图变换模块
纯视觉BEV感知算法中最重要的问题就是如何把2D图像特征转换到3D空间中去。当前主流的方法主要有两种,以BEVFormer为代表的算法采用Transformer的注意力机制基于查询的方法去获取三维BEV特征,另一种以BEVDet为代表的算法则通过计算二维特征与预测深度的外积来获得三维BEV特征。
基于注意力机制的方法可以描述为
F b e v ( x , y , z ) = A t t n ( q , k , v ) F_{bev}(x,y,z)=Attn(q,k,v) Fbev(x,y,z)=Attn(q,k,v)
其中
q
⊂
P
x
y
z
q \subset P_{xyz}
q⊂Pxyz,
k
,
v
⊂
F
2
D
(
u
,
v
)
k,v \subset F_{2D}(u,v)
k,v⊂F2D(u,v),
P
x
y
z
P_{xyz}
Pxyz是在3D空间中预定义的锚点,
F
2
D
(
u
,
v
)
F_{2D}(u,v)
F2D(u,v)表示从图像中提取的二维特征。在部署过程中,注意力机制的运算操作对某些计算平台可能不太友好,这阻碍了这些方法在实际场景中的应用。
基于深度预测的方法可以描述为
F b e v ( x , y , z ) = P o o l { F 2 D ( u , v ) ⊗ D ( u , v ) } x , y , z F_{bev}(x,y,z)=Pool\left \{ F_{2D}(u,v) \otimes D(u,v) \right \}_{x,y,z} Fbev(x,y,z)=Pool{F2D(u,v)⊗D(u,v)}x,y,z
其中
F
2
D
(
u
,
v
)
F_{2D}(u,v)
F2D(u,v)表示从图像中提取的二维特征,
D
(
u
,
v
)
D(u,v)
D(u,v)表示预测的深度,
⊗
\otimes
⊗表示外积操作,
P
o
o
l
Pool
Pool表示体素池化操作。在CUDA多线程的加持下,这种转换方法大大提高了在GPU平台上的推理速度,但是如果使用更大的分辨率和特征维度则会遇到计算性能瓶颈,在没有推理库支持的情况下很难部署到非GPU平台上。
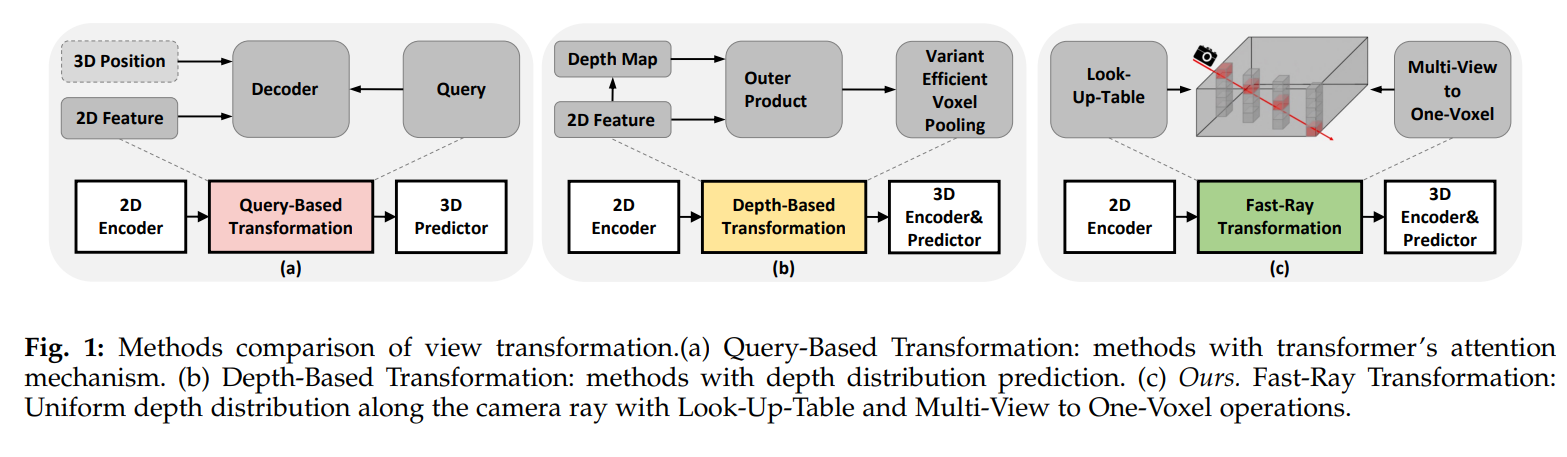
考虑到之前的视图变换方法都比较耗时,作者基于M2BEV中提出的沿相机光线方向深度是均匀分布的假设,提出了Fast-Ray视图变换方法,这种方法将多视图的2D图像特征沿相机光线投射到3D体素空间中。该方法的优点是,只要知道相机的内外参,就可以很容易地计算出2D到3D的投影关系。由于这个过程中没有使用可学习的参数,因此可以很容易地计算出图像特征点和BEV特征点之间的对应关系矩阵。
针对车载计算平台,作者提出两种优化操作:1)预先计算固定的投影索引,并将它们存储为静态查找表,推理阶段直接根据这个查找表获取2D到3D的投影关系,整个过程非常高效;2)让所有相机都投影到同一个体素上(Multi-View to One-Voxel),而不是每个相机投影到一个单独的体素上,从而避免了代价巨大的体素聚合操作。
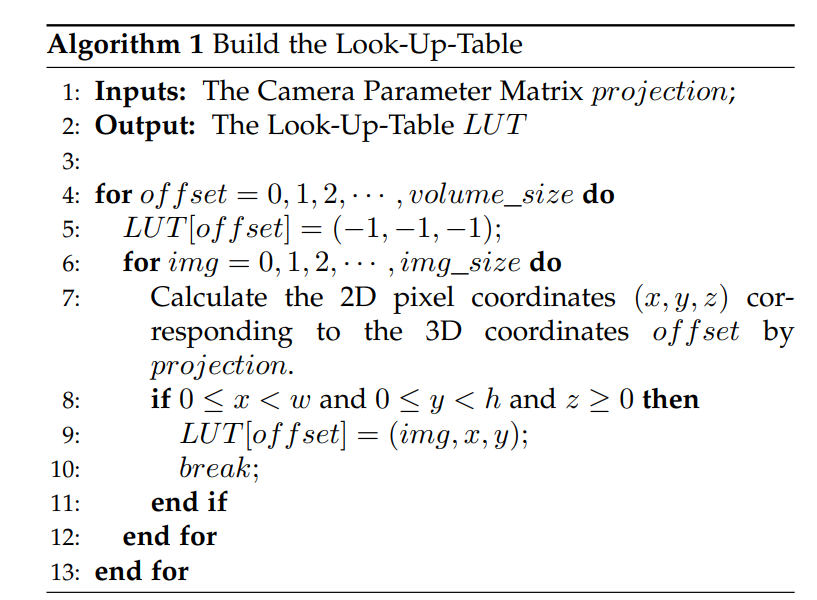
投影索引是从2D图像空间到3D体素空间的映射索引,由于不依赖任何需要学习的参数,对于每帧输入数据来说投影索引都是固定的,因此不需要每次都去计算投影索引而是在初始化的时候计算一次并把结果保存为一个查找表即可。在推理过程中,可以直接通过查询查找表来获取投影索引,这在边缘设备上也是一个非常高效的操作。建立投影索引查找表的过程如下:
由于每个相机的视角有限,每个体素特征都非常稀疏;另外,由于这些体素特征的尺寸巨大,如果把每个相机的特征投影到一个单独的体素上再进行聚合,会产生高昂的计算成本。因此作者提出把所有相机都投影到同一个体素上,避免体素聚合操作。
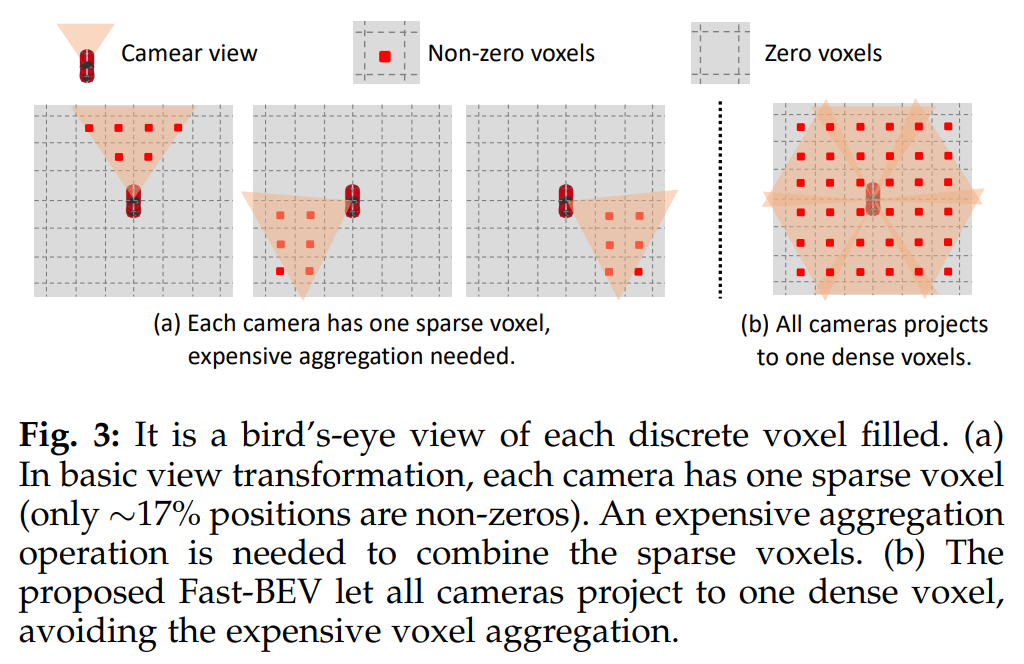
用Fast-Ray视图变换方法把多个视角的2D图像特征投影到同一3D体素中的过程如下。对于多个视图存在重叠区域的情况,作者直接采用第一个遇到的视图以提高构建查找表的速度。

Fast-Ray视图变换方法在GPU上的耗时可以忽略不计,而其在CPU上的速度则远远领先于其他方案,非常方便部署。
2.2 多尺度图像编码器
在2D目标检测任务中我们知道,多尺度图像特征融合可以带来一定的性能提升。作者利用Fast-Ray视图变换带来的速度优势,设计出一种多尺度的BEV感知范式,期望从多尺度信息中获得性能优势。在FastBEV中,图像编码器通过3层FPN结构获取多尺度图像特征输出。
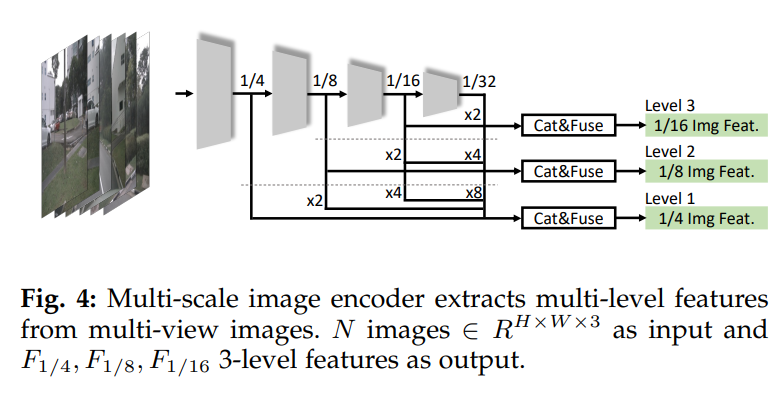
对于输入的N张维度为
H
×
W
×
3
H \times W \times 3
H×W×3的图像,首先用一个主干网络(ResNet等)为每张输入图像提取出4种尺度的特征
F
1
,
F
2
,
F
3
,
F
4
F_{1},F_{2},F_{3},F_{4}
F1,F2,F3,F4,它们的尺寸可表示为
H
2
i
+
1
×
W
2
i
+
1
×
C
\frac{H}{2^{i+1}} \times \frac{W}{2^{i+1}} \times C
2i+1H×2i+1W×C。图像编码器的输出部分使用3层多尺度FPN结构,FPN的每一层通过1x1卷积去融合前面层的输出特征,这些特征在融合前会上采样到同一尺度。FPN模块最终输出3个尺度的图像特征,分别为
F
1
/
4
,
F
1
/
8
,
F
1
/
16
F_{1/4},F_{1/8},F_{1/16}
F1/4,F1/8,F1/16。
从多个视角的图像中分别提取了3个尺度的图像特征
F
=
{
R
N
×
H
i
×
W
i
×
C
∣
i
∈
[
4
,
8
,
16
]
}
F=\left \{R^{N \times \frac{H}{i} \times \frac{W}{i} \times C}\mid i \in [4,8,16] \right \}
F={RN×iH×iW×C∣i∈[4,8,16]}后,把它们通过Fast-Ray视图变换方法映射到3D空间得到多尺度的BEV特征
V
=
{
R
X
i
×
Y
i
×
Z
×
C
∣
X
i
,
Y
i
∈
[
200
,
150
,
100
]
}
V=\left \{ R^{X_{i} \times Y_{i} \times Z \times C}\mid X_{i},Y_{i} \in [200,150,100] \right \}
V={RXi×Yi×Z×C∣Xi,Yi∈[200,150,100]}。
2.3 高效的BEV编码器
作者采用3个维度缩减操作设计了一个高效的BEV编码器。
第一个操作是通过一个与M2BEV中一样的"Spatial to Channel(S2C)"操作把体素特征张量
V
V
V的维度从
X
×
Y
×
Z
×
C
X \times Y \times Z \times C
X×Y×Z×C变换为
X
×
Y
×
(
Z
C
)
X \times Y \times (ZC)
X×Y×(ZC),然后用2D卷积提取特征,从而避免在模型中使用笨重而低效的3D卷积。
由于通过多尺度投影获得的BEV特征是不同尺度的,因此作者首先在X和Y维度上将多尺度BEV特征上采样到同一个尺度(比如200x200),然后分别用一个多尺度串联融合(MSCF)和多帧串联融合(MFCF)将多尺度多帧的特征进行融合,目的是把它们从高参数量的特征变换为低参数量的特征,从而减少BEV编码器的耗时。
F u s e ( V i ∣ V i ∈ R X i × Y i × ( Z C F s c a l e s T f r a m e s ) ) ⇒ V i ∣ V i ∈ R X i × Y i × C M S C F & M F C F , i ∈ 3 − l e v e l Fuse(V_{i}\mid V_{i} \in R^{X_{i} \times Y_{i} \times (ZCF_{scales}T_{frames})})\Rightarrow V_{i}\mid V_{i} \in R^{X_{i} \times Y_{i} \times C_{MSCF\&MFCF}},i \in 3-level Fuse(Vi∣Vi∈RXi×Yi×(ZCFscalesTframes))⇒Vi∣Vi∈RXi×Yi×CMSCF&MFCF,i∈3−level
作者通过实验发现,在BEV编码器中使用更多的网络层和更大尺寸的3D体素分辨率并不能显著提高模型的性能,但是耗时会随之迅速增加。因此作者减少了编码器中残差块的数量且只使用较小的体素分辨率。
通过上述方式,可以大大降低BEV编码器的耗时,同时对模型精度没有影响。
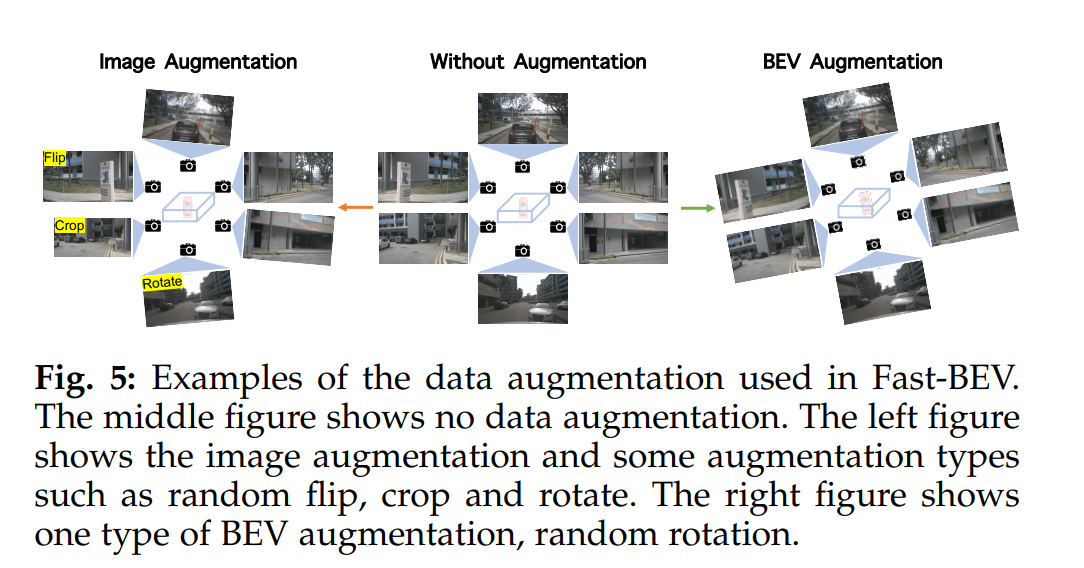
2.4 数据增强
如果不使用数据增强,模型在训练后期会发生严重的过拟合问题,因此作者采用与BEVDet一样的数据增强策略,在图像和BEV空间都使用了随机翻转、旋转、裁剪等数据增强操作。
2.5 时序融合
在真实的自动驾驶场景中,输入数据在时间上是连续的,并且在时间维度上具有丰富的互补信息。例如,在当前帧处部分遮挡的行人可能在过去几帧中完全可见。因此,作者引入时序特征融合模块,采用BEVDet4D中的方法去融合历史帧的特征。
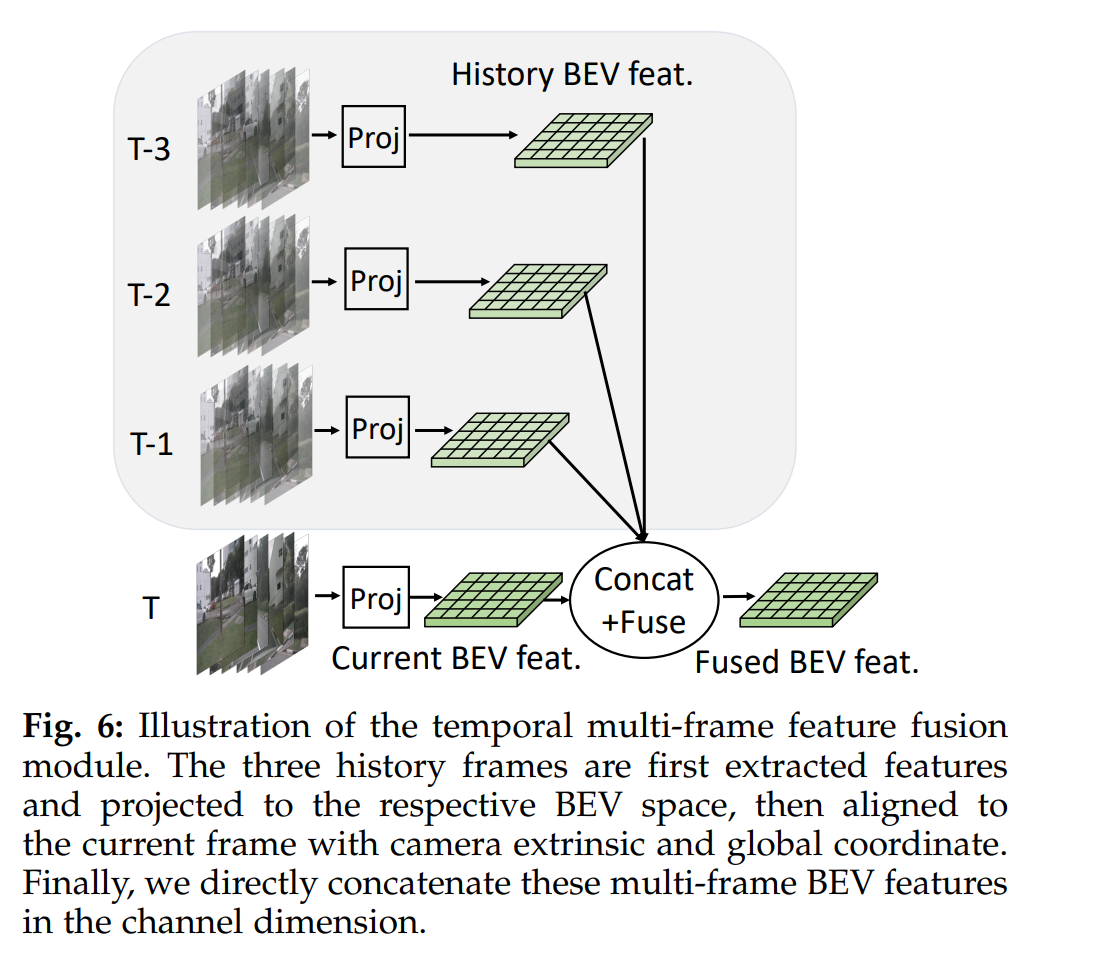
时序融合可以看作是帧级的特征增强操作,在一定范围内使用更长的时间序列可以带来更多的性能提升。作者使用3个历史关键帧对当前帧进行采样,每个关键帧的时间间隔为0.5秒,多帧特征对齐方法与BEVDet4D的一样。BEVDet4D只使用了一帧历史帧,作者认为这不足以利用历史信息,因此使用了3帧历史帧。在得到4帧对齐后的BEV特征后,把它们串联到一起送入BEV编码器去提取特征。
2.6 检测头
作者采用PointPillars的检测头实现3D目标检测任务,参数设置于M2BEV中的一样,本文不再重复。
3. 参考资料
- 《Fast-BEV: A Fast and Strong Bird’s-Eye View Perception Baseline》