1. 什么是 bug
“Bug” 本意是“昆虫”或“虫子”,现在是指程序或系统中的错误或缺陷,导致其无法按预期执行。这种错误可能是代码中的逻辑错误、输入输出的意外处理、资源分配不当等问题。
1.1 Bug 的历史(了解)
最早被记录的“bug”出现在1947年,涉及一台名叫 Mark II 的计算机。这个“bug”的故事既有趣又具有象征意义,标志着“bug”在计算机历史上作为错误代名词的开端。以下是这个事件的详细背景:
1.1.1 Mark II计算机的背景
Mark II是哈佛大学建造的一台早期继电器式计算机,属于Harvard Mark系列计算机中的一部分。这台机器使用继电器和电磁开关进行运算,相比现代计算机的半导体芯片显得巨大笨重。Mark II的运作过程依赖许多物理电路,因此设备非常庞大,并且经常因为硬件的原因而出现故障。
1.1.2 Grace Hopper的发现
Grace Hopper是美国海军的一名计算机科学家和先驱人物,她在哈佛大学的计算机实验室工作时,领导团队维护和操作Mark II计算机。1947年9月9日,团队在运行Mark II时遇到了一些问题,计算机突然失灵,部分计算无法进行。他们检查了计算机的每个部分,最终发现在其中一个继电器上竟然卡住了一只飞蛾。

1.1.3 故障原因:飞蛾卡在继电器中
继电器是Mark II的核心部件之一,通过通断电流来实现运算指令的执行。然而,由于这只飞蛾的干扰,导致继电器无法正常运转,电流无法顺利通过,计算机也因此出现故障。这只飞蛾成了这台计算机的“第一个bug”,或者说,第一个被发现并记录下来的计算机“bug”。
1.1.4 记录“bug”的诞生
Hopper团队发现飞蛾后,便将其从继电器上移除,并将这次事件详细记录在实验日志上。他们用胶带将这只飞蛾贴在日志页上,并标注道“First actual case of bug being found”(发现实际bug的第一个案例)。这个动作不仅保存了历史证据,还开创了“bug”作为计算机错误的术语。从此,团队成员甚至在日志中用“debugging”来指代清理机器中的错误或故障。
1.1.5 “debugging”一词的推广
虽然在电气工程中“debug”这个词在此之前也曾被使用过,但Grace Hopper的团队正式确立了这个词的含义,使其逐渐推广到计算机和软件领域。之后,随着计算机的发展和普及,软件错误被称为“bug”,而排除这些错误的过程则称为“debugging”。
1.1.6. 历史价值与意义
这只飞蛾的事件不仅在计算机历史中占据了一席之地,还成为了“bug”一词作为故障和错误代名词的根源。至今,这只飞蛾的原始记录仍然保存在史密森尼博物馆里,作为计算机发展史中的一件象征性文物。它提醒着我们早期计算机科学家面对的挑战,也见证了“bug”在技术界的深远影响。
1.2 Bug 的来源
- 程序员疏忽:由于复杂的逻辑或代码编写不严谨,容易引入错误。
- 需求不明确:未理解或实现需求的真正意图,导致功能不符合需求。
- 边界条件未处理:在输入为零、负数、超大数等边界情况下程序可能会出现异常行为。
1.3 解决 Bug 的方法
- 代码复查:通过仔细检查代码或找他人代码审查来发现可能的 bug。
- 单元测试:为代码的各个模块编写测试用例,以确保每个部分都符合预期。
- 使用调试工具:如 GDB 或 Visual Studio 内置调试器,帮助逐步分析代码执行流程。
2. 什么是调试(debug)?
调试(debug) 是指识别、定位并修复程序 bug 的过程。调试通常包括以下几个步骤:
2.1 调试过程
-
承认错误:调试一个程序,首先是勇于承认出现了问题,很多程序员不愿意承认自己的错误,把问题甩锅给测试、前端等。
-
重现错误:确认 bug 存在并确定其触发条件。例如,确定哪些输入会导致程序崩溃。
-
设置断点:在代码的关键位置设置断点,使程序在这些位置暂停,以便观察变量值和程序状态。
-
分析程序状态:逐步执行代码,观察变量值、内存状态和程序执行流,确定 bug 的根本原因。
-
修复错误:一旦找到 bug 的根源,通过修改代码进行修复。
-
验证修复:重新运行程序,确保修复后的代码不会再产生相同的 bug,并进行回归测试,确保未引入新的问题。
2.2 调试的重要性
调试是软件开发过程中不可或缺的步骤,尤其在 C 语言中,由于其对内存的直接操作更容易出现复杂 bug。有效的调试可以节省开发时间,提高代码质量。
3. Debug 和 Release 模式的区别
在 C 语言开发中,编译器通常提供两种编译模式:Debug 和 Release。

- Debug 模式
- 含有调试信息(如变量名称、函数名等),方便调试。
- 未进行优化,因此变量值等更容易追踪。
- 程序执行效率较低,主要用于开发和测试阶段。
- 编译出的文件较大,因为包含了额外的调试信息。
- Release 模式
- 不包含调试信息,减少文件体积。
- 经过编译器优化,执行效率高。
- 用于发布产品,避免用户看到内部调试信息。
- 可能对代码进行了重排或内联优化,因此某些错误在 Release 模式下可能无法重现。
4. VS 调试快捷键
Visual Studio 是常用的开发工具,提供了许多便捷的调试快捷键。以下是一些常用快捷键:
4.1 环境准备
在 Visual Studio 中进行调试之前,需要设置一些环境参数:
-
配置项目属性:确保编译模式选择为
Debug,而不是Release。 -
调试信息生成:检查是否启用了调试符号文件(PDB 文件),以便跟踪代码。
-
优化设置:在
Debug模式下通常禁用优化,以便更准确地观察变量值。

4.2 调试快捷键
- F5:开始调试/继续 - 启动程序并进入调试模式。如果已经在调试中,继续执行程序,直至下一个断点或程序结束。
- Shift + F5:停止调试 - 结束当前调试会话,退出调试模式。
- F9:设置/取消断点 - 在当前行设置或取消断点,程序会在此行暂停执行,方便观察状态。
- F10:逐过程执行 - 逐步执行代码,但不会进入函数内部,而是跳过整个函数。
- F11:逐语句执行 - 逐行执行代码,包括进入函数内部,详细分析每一步执行情况。
- Ctrl + F5:不调试启动 - 启动程序而不进入调试模式,直接运行程序。
- Ctrl + Shift + F5:重新启动调试 - 停止当前调试并重新开始调试,适用于想要从头开始调试的情况。
5. 监视和内存观察
监视和内存观察是调试过程中的重要工具,帮助开发者深入了解程序的执行状态、上下文环境中的变量的值和内存使用情况。当然,这些观察的前提条件一定是开始调试后观察。
5.1 监视(Watch)
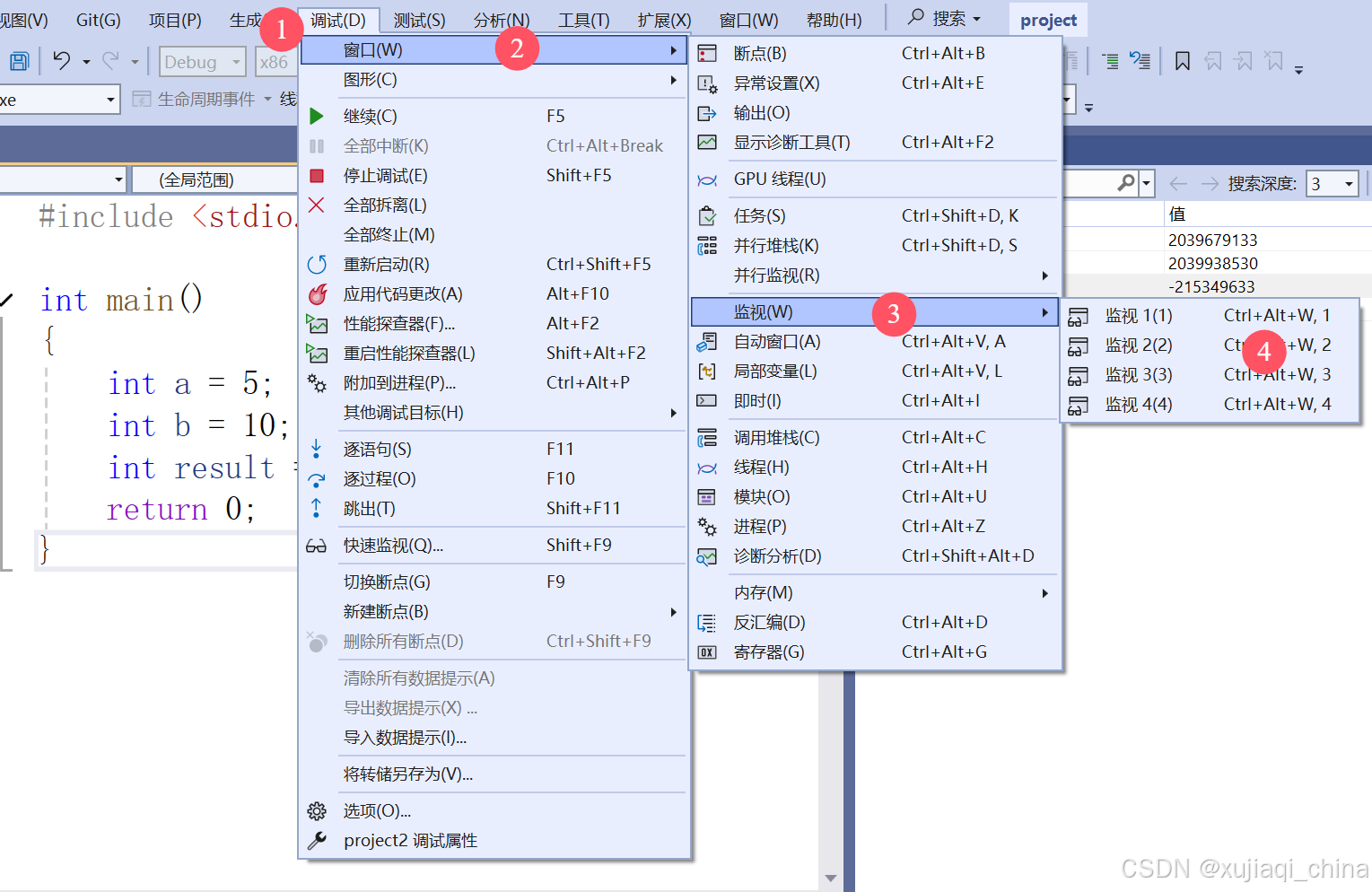
监视窗口允许开发者查看变量的实时值,尤其是在断点位置暂停时,可以观察变量的状态。
- 添加监视:在代码中选中变量,右键选择“添加到监视窗口”。
- 动态更新:监视窗口会动态显示变量的值变化,当代码逐步执行时,变量值会实时更新。
- 观察表达式:不仅可以监视单个变量,还可以监视表达式。例如,可以监视
a + b的值,方便计算和判断。
示例:
int a = 5;
int b = 10;
int result = a + b; // 可以监视 result 的值来确认是否正确计算
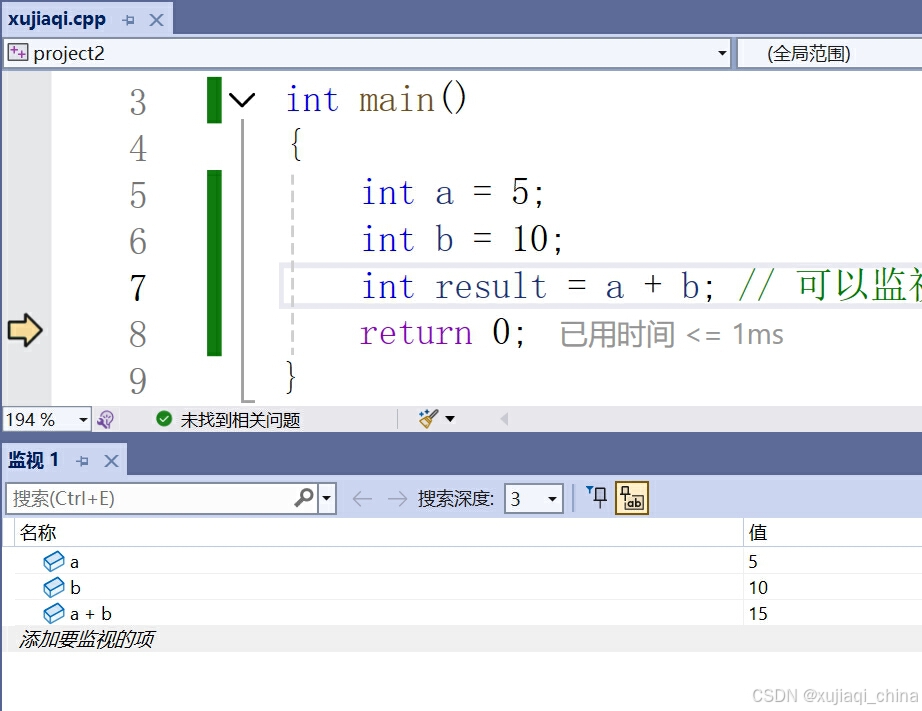
5.2 内存观察(Memory)
如果监视窗口看的不够仔细,也是可以观察变量在内存中的存储情况,内存窗口允许开发者直接查看程序的内存状态,还是在【调试】->【窗口】->【内存】,这在处理指针和数组时特别有用。
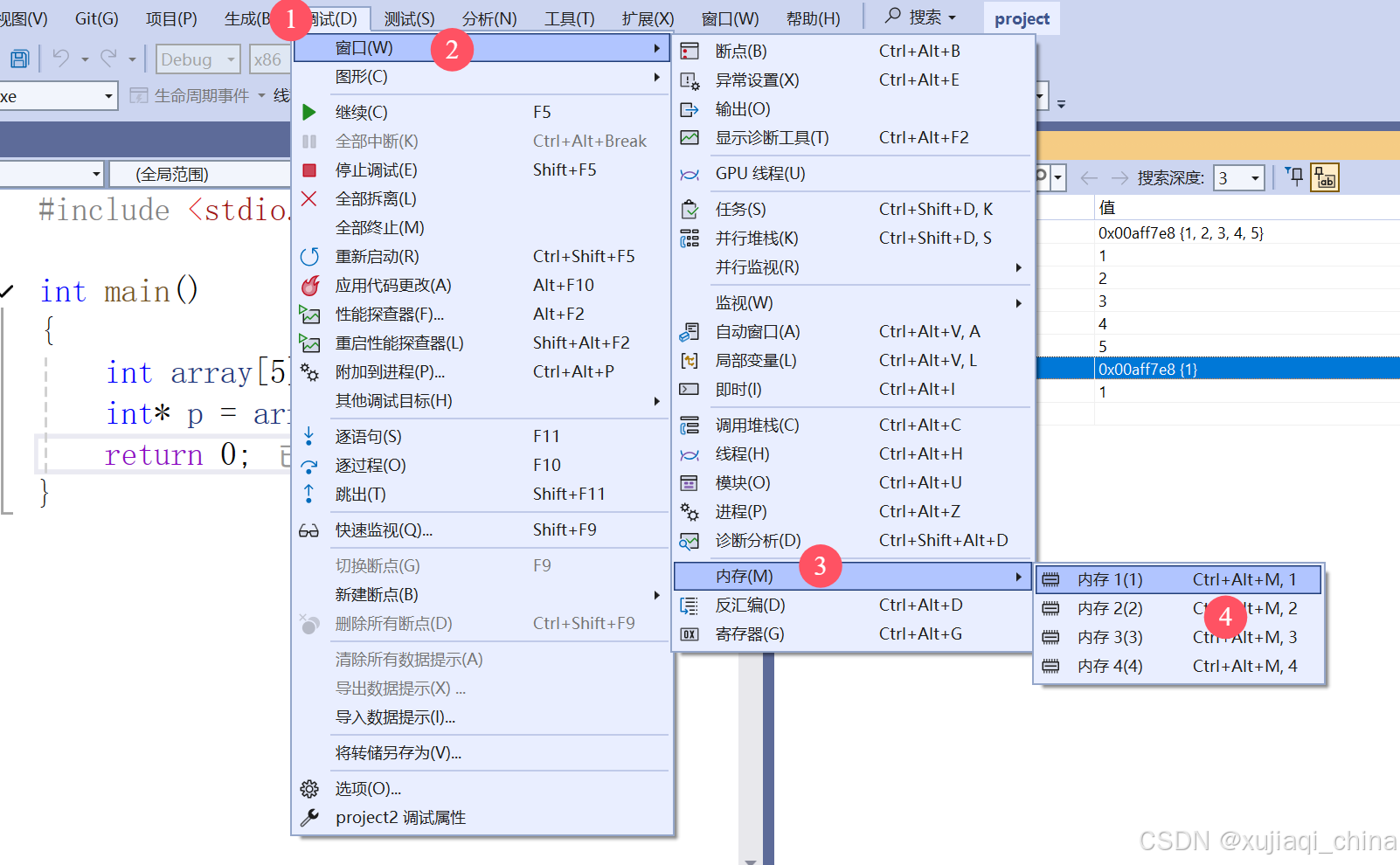
- 内存地址:在内存窗口中可以查看特定地址的内存内容,方便检查指针或数组访问的正确性。要在地址栏输入:
arr,&num,&c,这类地址,就能观察到该地址处的数据。 - 字节表示:内存窗口会以十六进制显示内存内容,也可以转换为字符、整数等格式。
- 指针监视:对于指针类型变量,可以直接查看其指向的内存区域,判断是否存在空指针或非法访问。
示例:
int array[5] = {1, 2, 3, 4, 5};
int *p = array;
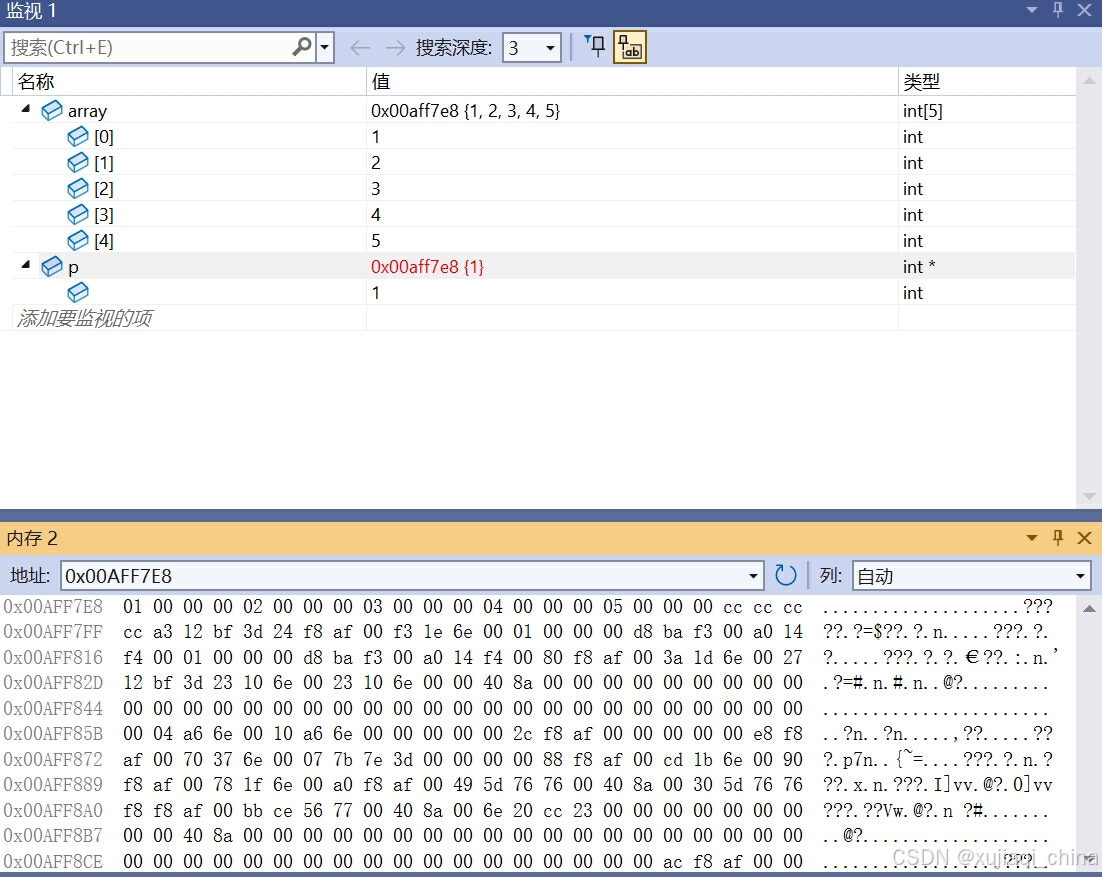
通过内存窗口可以观察 p 指针的值以及它所指向的 array 数组的内存内容,确保没有越界访问。
6. 调试案例
在VS2022、X86、Debug 的环境下,编译器不做任何优化执行以下代码
#include <stdio.h>
int main()
{
int i = 0;
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
for(i=0; i<=12; i++)
{
arr[i] = 0;
printf("hehe\n");
}
return 0;
}
6.1 内存布局
-
通过调试我们知道了
arr数组和变量i在栈区的分布。arr数组占用了连续的内存空间,从低地址到高地址排列,共有 10 个元素(索引 0 到 9)。 -
紧邻
arr数组高地址的地方存放的是变量i。这意味着,i和arr[10]的地址相邻,arr[10]实际上指向了变量i的内存位置。
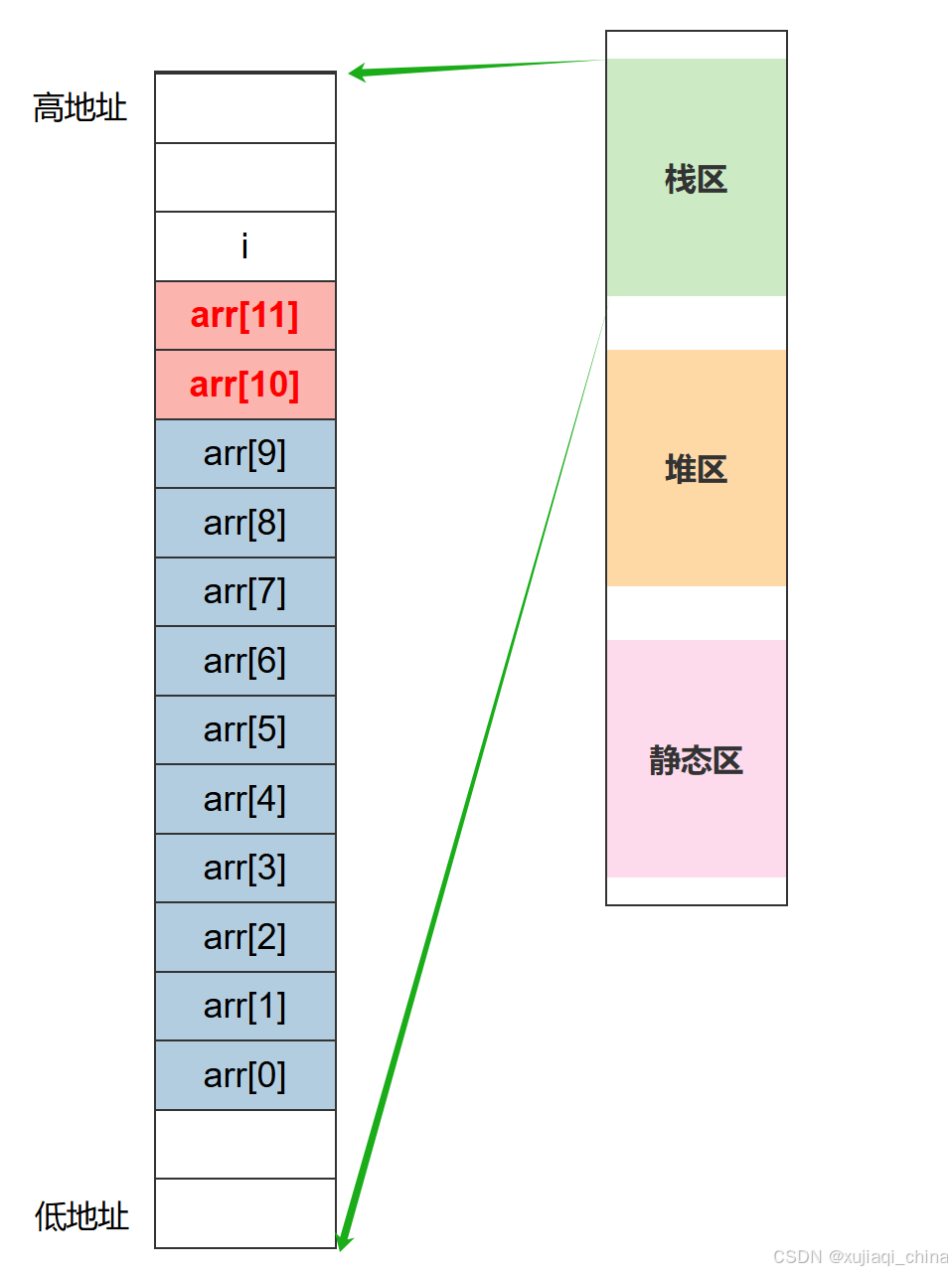
6.2 越界访问导致的死循环
- 由于
for循环条件为i <= 12,因此在循环中i的值会从0一直增加到12。这意味着,当i >= 10时,会访问arr[10]、arr[11]、arr[12]等越界元素。 - 当访问
arr[10]时,由于arr[10]的内存位置和变量i的内存位置重叠,因此arr[10] = 0实际上修改了变量i的值为0。 - 这样一来,
i每次在循环中被设置为0,因此无法正常递增。循环条件i <= 12始终为真,导致程序进入了死循环。
6.3 详细过程
- 在每次循环开始时,
i的值会递增,然后在arr[i] = 0;中被覆盖为0。 - 这相当于每次循环都重新将
i设置为0,使得for循环条件永远成立,导致无限输出"hehe"。
6.4 总结
- 死循环的原因在于数组越界访问覆盖了变量
i的值,使得i的值始终无法增大。 - 修改循环条件为
i < 10,即可避免越界访问,防止覆盖i的值,解决死循环问题。
7. 小练习
求1!+2!+3!+4!+...10! 的和,请看下面的代码:
#include <stdio.h>
//写一个代码求n的阶乘
int main()
{
int n = 0;
scanf("%d", &n);
int i = 1;
int ret = 1;
for(i=1; i<=n; i++)
{
ret *= i;
}
printf("%d\n", ret);
return 0;
}
int main()
{
int n = 0;
int i = 1;
int sum = 0;
for(n=1; n<=10; n++)
{
for(i=1; i<=n; i++)
{
ret *= i;
}
sum += ret;
}
printf("%d\n", sum);
return 0;
}
调试找一下问题。
8. 编程常见错误归类
在 C 语言中,错误通常分为以下几类:
8.1 编译型错误
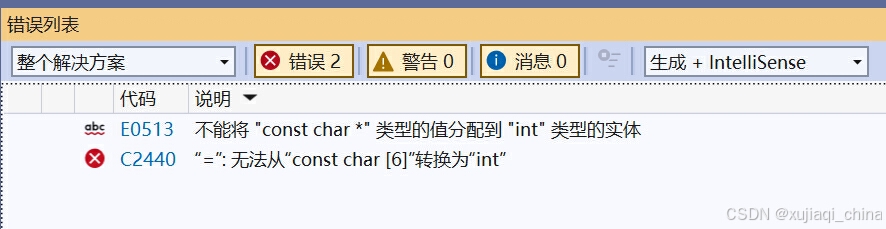
编译型错误是编译器在代码编译阶段检测到的错误。常见的编译型错误包括:
- 语法错误:如漏写分号、括号不匹配等。
- 数据类型不匹配:如将
int类型变量赋值给char变量。 - 函数声明不匹配:调用未声明或参数类型不符的函数。
示例:
int a = 5;
a = "hello"; // 错误,字符串不能赋值给整数变量
8.2 链接型错误
链接型错误通常出现在编译阶段之后,由于未正确链接外部函数或库导致的错误。常见的链接错误包括:
- 未定义的引用:如调用了未定义的函数。
- 重复定义:多个文件中重复定义了同名变量或函数。
示例:
extern int myFunction(); // 声明了一个外部函数,但未定义,可能导致链接错误
8.3 运行时错误
运行时错误是程序在执行时遇到的问题。常见的运行时错误包括:
- 空指针引用:访问了空指针指向的内存。
- 数组越界:访问了数组边界之外的内存。
- 除零错误:整数除以零会导致异常。
示例:
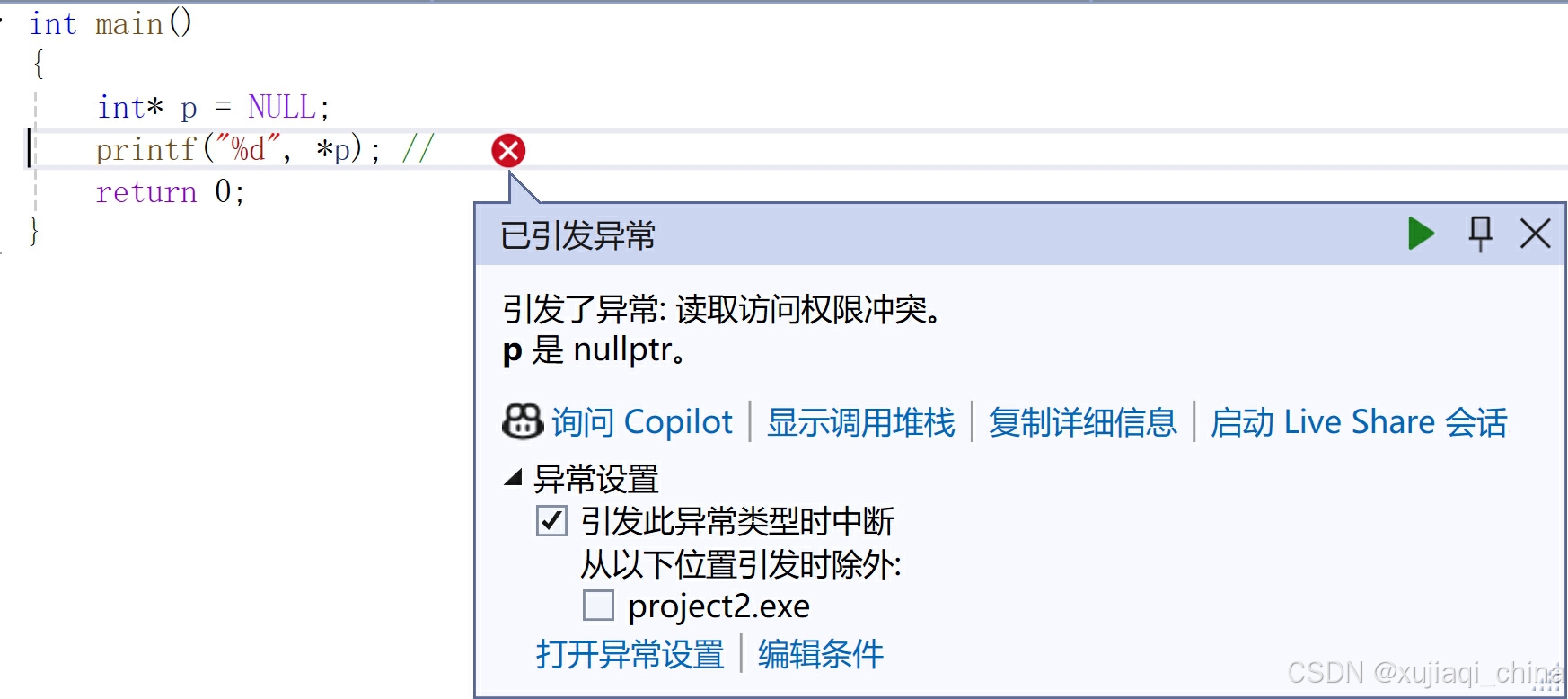
int *p = NULL;
printf("%d", *p); // 错误,空指针访问会导致运行时错误
—完—