决策树算法原理:
决策树算法的基本原理
决策树算法是一种特别简单的机器学习分类算法。在机器学习中,决策树是一个预测模型,其代表的是对象属性与对象之间的一种映射关系。
决策树算法的特点:
决策树算法的优点如下:
1、 决策树易于理解和实现,用户在学习过程中不需要了解过多的背景知识,其能够直接体现数据的特点,只要通过适当的解释,用户能够理解决策树所表达的意义。
2、 速度快,计算量相对较小,且容易转化成分类规则。只要沿着根节点向下一直走到叶子节点,沿途分裂条件是唯一且确定的。
决策树算法的缺点则主要是在处理大样本集时,易出现过拟合现象,降低分类的准确性。
随机森林:
随机森林指的是利用多棵决策树(类似一片森林)对样本进行训练并预测的一种分类器。该分类器最早由 Leo Breiman 和 Adele Culter 提出,并被注册成了商标。在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别数输出的类别的众数而定。这个方法则是结合 Breiman 的"Bootstrap aggregating" 想法和 Ho 的“random subspace method”以建造决策树的集合。
MATLAB 实践:
在MATLAB 中,为方便用户对决策树算法的使用,MATLAB 中针对分类决策树和回归决策树分别封装了两个函数:fitctree 和 fitrtree。由于分类决策树和回归决策树两者具有极大的相似性,因此 fitctree 和 fitrtree 两者的使用方法也基本一致。
分类决策树 fitctree 函数在决策树进行分支时,采用的是 CART 方法。其使用方法为 TREE = fitrtree(TBL,Y),其中,TBL 为样本属性值矩阵,Y 为样本标签。利用 MATLAB 中自带的统计3种鸢尾属样本数据 fisheriris,其属性分别为花萼长度、花萼宽度、花瓣长度、花瓣宽度,标签分别为‘setosa’、‘versicolor’ 和 ‘virginica’。
具体代码如下:
%%CART决策树算法Matlab实现
clear all;
close all;
clc;
load fisheriris %载入样本数据
t = fitctree(meas,species,'PredictorNames',{'SL' 'SW' 'PL' 'PW'})%定义四种属性显示名称
view(t) %在命令行窗口中用文本显示决策树结构
view(t,'Mode','graph') %图形显示决策树结构
运行后显示结果如图:
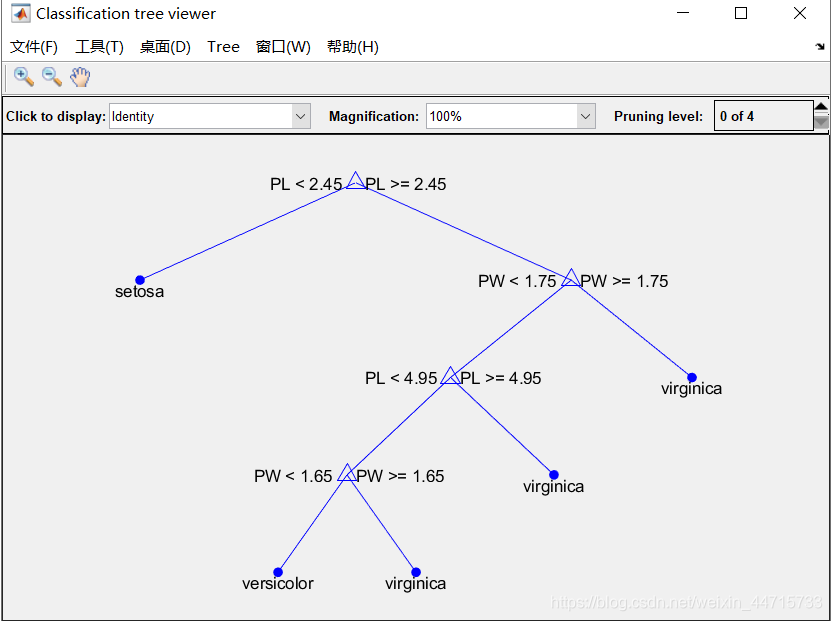
MATLAB 命令行窗口显示结果:
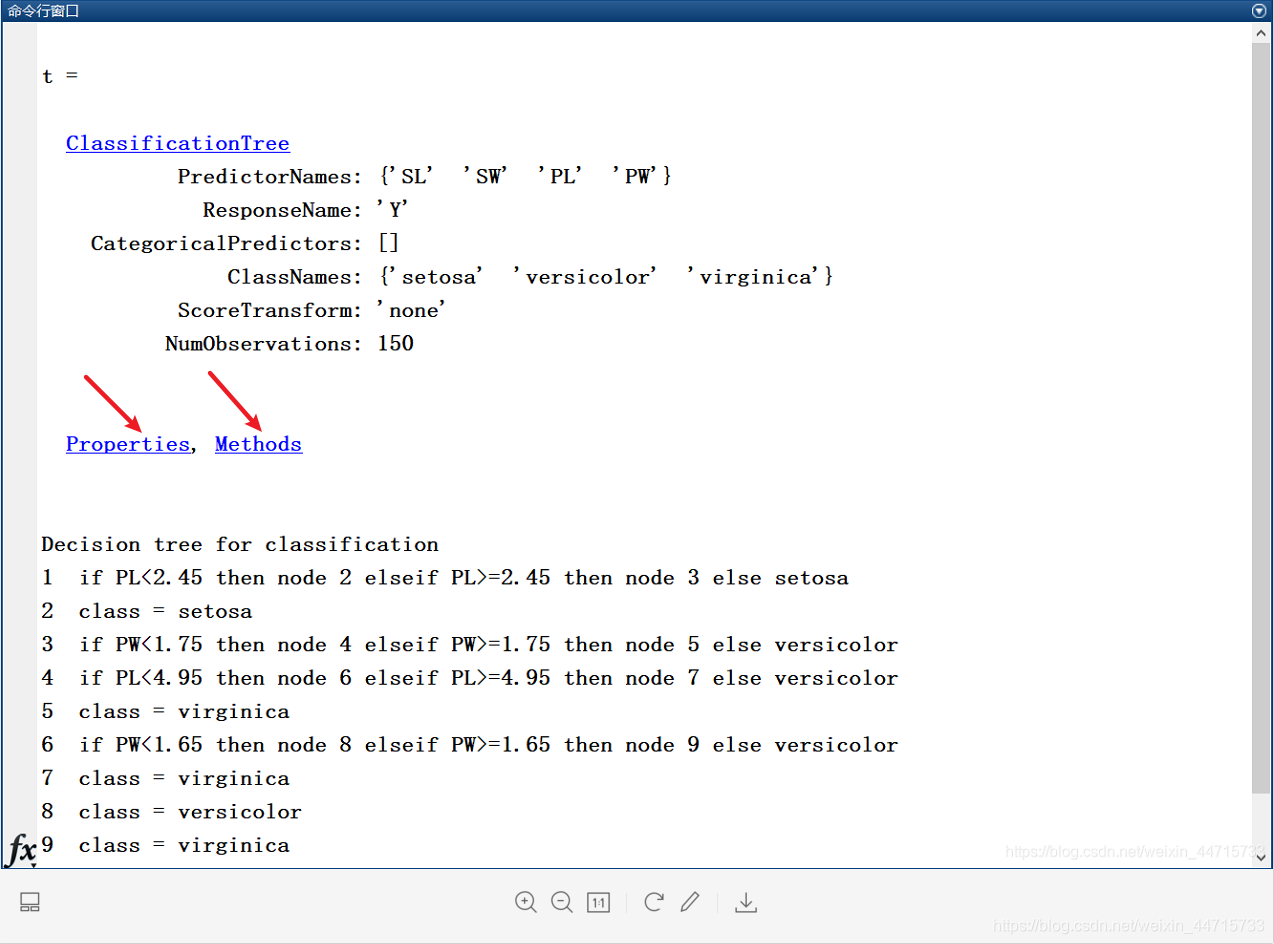
分别单击上述 MATLAB 命令行窗口中的 Properties 和 Methods 超链接,在窗口中分别显示如下所示。单击 Properties 超链接显示的类 Classification Tree 的所有(可理解为生成决策树)属性,是指通过 fitctree 训练得到的树的所有属性,部分属性值可在 fitctree 函数调用时进行定义,如上述程序中的 PredictorNames(描述各属性的名称)等,另外一部分则是对形成的树的具体属性描述,如 NumNodes(描述各属性的名称)等。由于各属性是属于训练成的决策树,因此当需要观测和调用属性值时,可采用 t.XXX 调用,其中 t 表示训练生成的树的名称,XXX 表示属性名称。
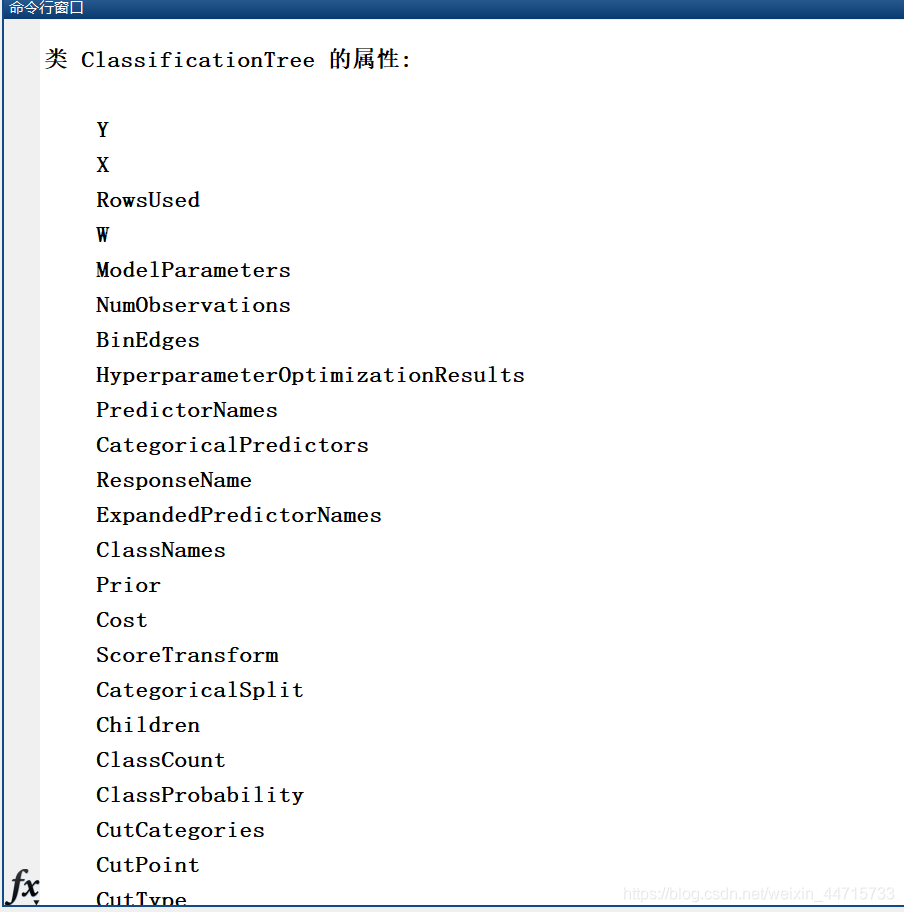
单击 Methods 超链接显示的是类 Classification Tree(可理解为生成的决策树)的操作方法。

对于属性和方法的具体含义及使用方法,可通过 help XXX 查询,XXX 为属性或方法名。下面介绍决策树的剪枝方法(Prune)和观测方法(View)的基本使用方法。
语法如下:
t2 = prune(t1, 'level', levelvalue)
t2 = purne(t1, 'nodes', nodes)
view(t2, 'Mode', 'graph')
其中,t1 表示原决策树,t2 表示剪枝后的新决策树,‘level’ 表示按照层进行剪枝,levelvalue 表示剪掉的层数。‘nodes’ 表示按照借点剪枝,nodes 表示剪掉该结点后的所有枝。view(t2,‘Model’,‘graph’)表示以图形化方式显示 t2 决策树。
针对上述的决策树,进行剪枝。在 MATLAB 命令行窗口中输入:
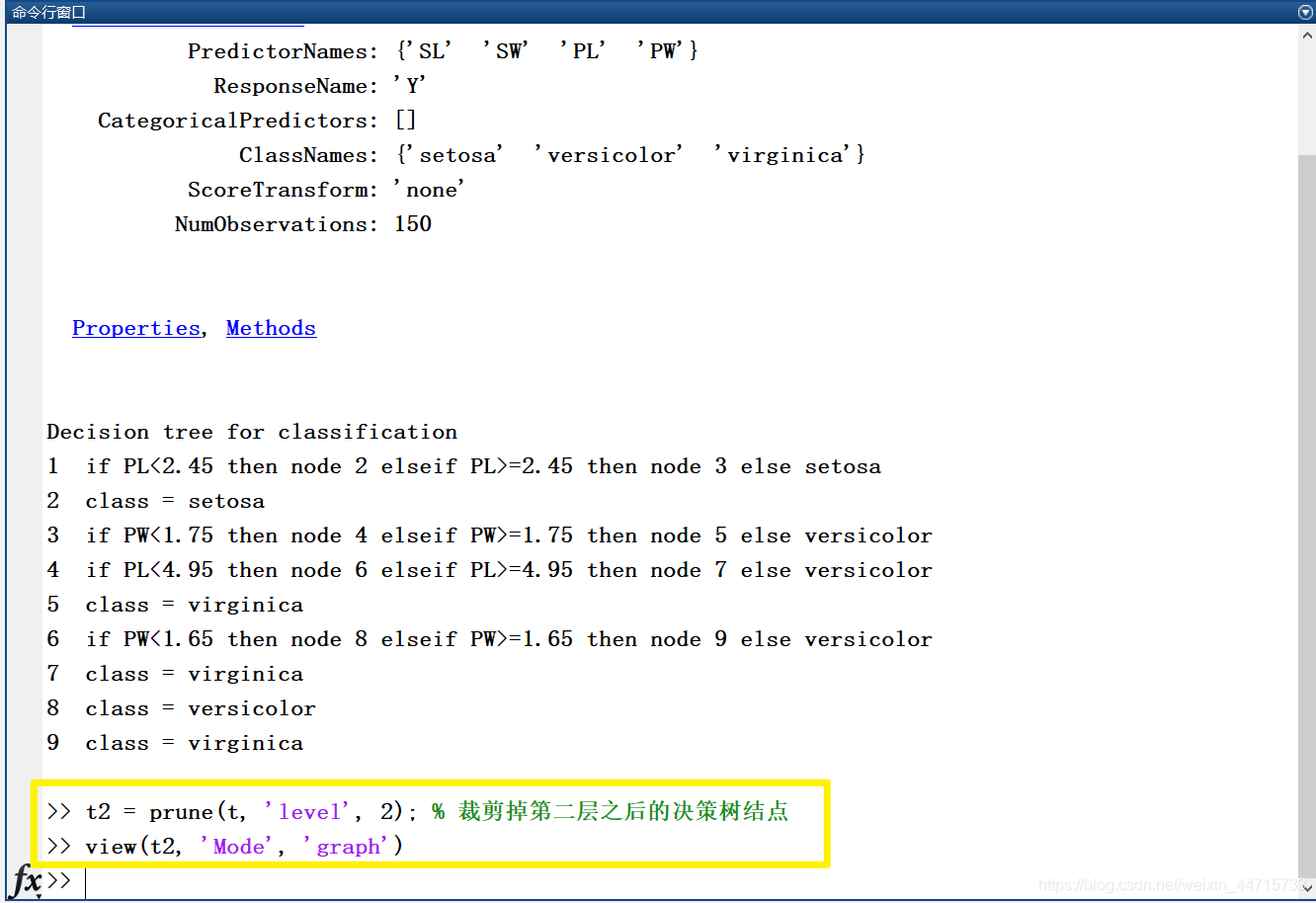
经过裁剪后的决策树如下图所示:
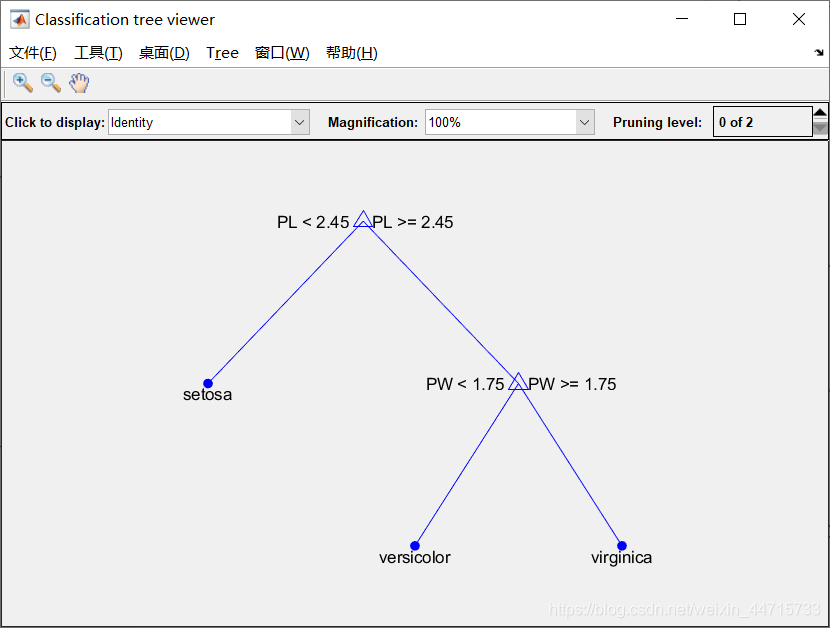
经过上诉对决策树的剪枝等操作后,就形成了一个具有使用价值的决策树,在 MATLAB 命令行窗口中输入:

运行后输出结果如下:

上图表示通过决策树分类后,属性值为[1 0.2 0.4 2] 的鸢尾属植物 setosa。