机器学习-决策树-分类-汽车数据集-fetch_openml python scikit-learn
前言
在这个使用决策树的分类任务中,将使用OpenML提供的汽车数据集来预测给定汽车信息的汽车可接受性。将使用Sklearn ’ fetch_openml '函数加载它。
此次获取的数据的版本是2。在数据集的版本1中,目标类有4个类(unacc, acc, good, vgood),但在第二个版本中,大多数类是Positive§,而其余的是Negative§。如果要查看版本1,可以在下面的单元格中更改版本参数。
以下是有关数据的信息:
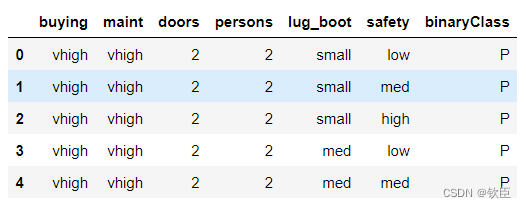
buying:汽车的购买价格(vhigh, high, med, low)
maint:汽车的保养价格(高、中、低)
doors:门的数量(2、3、4、5个以上)
persons:这辆车可以搭载的人数。他们是2岁,4岁,甚至更多。
lug_boot:行李箱行李箱的尺寸(小号,大号,大号)
safety:汽车的估计安全性(低、中、高)
BinaryClass(目标特性):汽车可接受性类。要么是正§要么是负(N)。
1.导入模块
import numpy as np
import pandas as pd
import seaborn as sns
import sklearn
import matplotlib.pyplot as plt
%matplotlib inline
2.加载数据
from sklearn.datasets import fetch_openml
car_data = fetch_openml(name='car', version=2)
car_data = car_data.frame
car_data.head()
3.探索性分析
将数据拆分为训练集和测试集
from sklearn.model_selection import train_test_split
train_data, test_data = train_test_split(car_data, test_size=0.1,random_state=20)
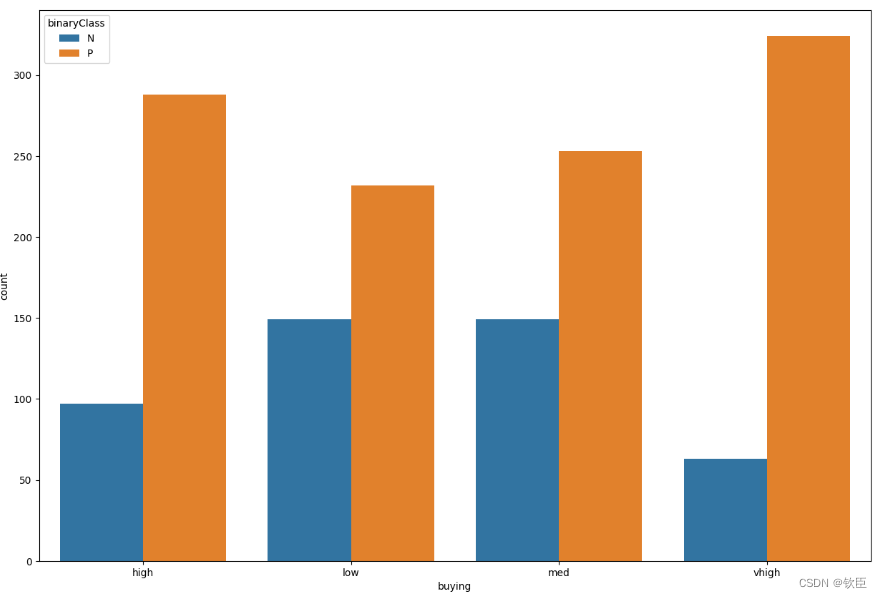
plt.figure(figsize=(15,10))
sns.countplot(data=train_data, x='buying', hue='binaryClass')
4.数据预处理
将数据准备为机器学习模型提供适当的格式。
处理分类特征
决策树不关心特征是否缩放,它们可以处理分类特征。有一个文档注释, sklearn树实现不支持分类特性。
#在处理分类特征之前,创建一个训练输入数据和标签。
car_train = train_data.drop('binaryClass', axis=1)
car_labels = train_data[['binaryClass']]
#创建一个Pipeline来编码训练输入数据中的所有特征。
from sklearn.preprocessing import OrdinalEncoder
from sklearn.pipeline import Pipeline
pipe = Pipeline([('ord_enc', OrdinalEncoder())])
car_train_prepared = pipe.fit_transform(car_train)
再处理标签。标签包含P和N,所以想把它们转换成数字。这里不使用普通编码器,而是使用标签编码器。Sklearn明确地用于对目标特征进行编码。
from sklearn.preprocessing import LabelEncoder
label_enc = LabelEncoder()
car_labels_prepared = label_enc.fit_transform(car_labels)
5.训练并评估决策树分类器
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
tree_clf = DecisionTreeClassifier()
tree_clf.fit(car_train_prepared, car_labels_prepared)
def accuracy(input_data,model,labels):
preds = model.predict(input_data)
acc = accuracy_score(labels,preds)
return acc
def conf_matrix(input_data,model,labels):
preds = model.predict(input_data)
cm = confusion_matrix(labels,preds)
return cm
def class_report(input_data,model,labels):
preds = model.predict(input_data)
report = classification_report(labels,preds)
report = print(report)
return report
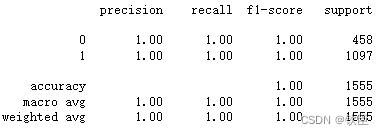
accuracy(car_train_prepared, tree_clf, car_labels_prepared) #1.0
可以看出决策树对数据集分类后过拟合。
class_report(car_train_prepared, tree_clf, car_labels_prepared)
6.改进决策树
避免过拟合的一种方法是减少树的最大深度,由超参数“max_depth”设置。类似地,可以尝试使用’ max ‘项减少所有超参数,同时增加’ min_ '项参数。
此外,将“class_weight”设置为“balanced”,因为该数据集是不平衡的。通过将其设置为平衡,模型将根据所有类别中可用样本的数量自动调整类别权重。
这里使用GridSearch来查找这些超参数的最佳值。
import warnings
warnings.filterwarnings('ignore')
from sklearn.model_selection import GridSearchCV
params_grid = {'max_leaf_nodes': list(range(0, 10)),
'min_samples_split': [0,1,2, 3, 4],
'min_samples_leaf': [0,1,2, 3, 4],
'max_depth':[0,1,2,3,4,5],
'max_features':[0,1,2,3,4,5],
'max_leaf_nodes':[0,1,2,3,4,5]}
grid_search = GridSearchCV(DecisionTreeClassifier(random_state=42, class_weight='balanced'), params_grid, verbose=1, cv=3, refit=True)
grid_search.fit(car_train_prepared, car_labels_prepared)
tree_best = grid_search.best_estimator_
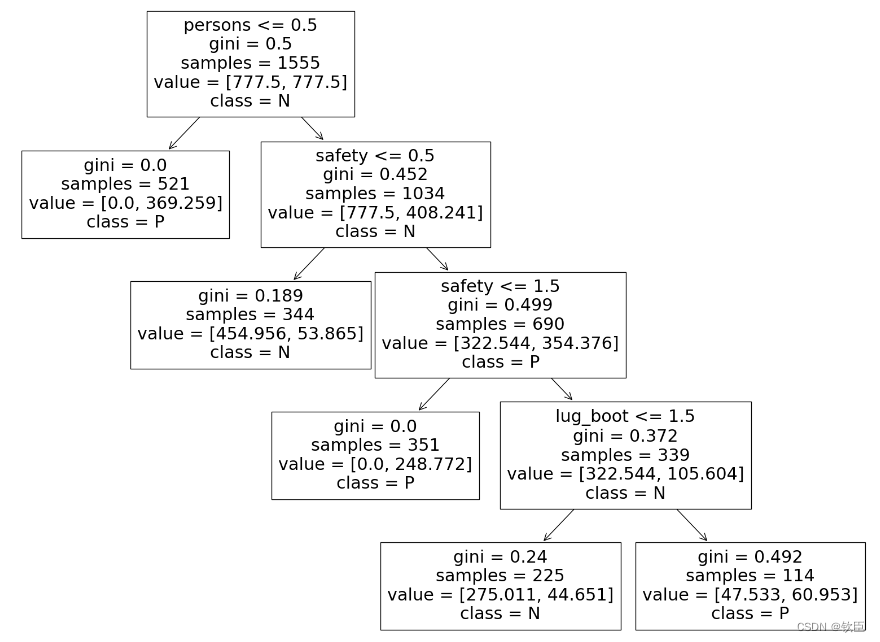
from sklearn.tree import plot_tree
plt.figure(figsize=(20,15))
plot_tree(tree_best, feature_names=car_train.columns, class_names=['N','P']);
accuracy(car_train_prepared, tree_best, car_labels_prepared) #0.8926045016077171
conf_matrix(car_train_prepared, tree_best, car_labels_prepared)
在混淆矩阵中,每一行代表一个实际的类,每一列代表预测的类。
因此,从上面的结果来看:
- 430个阴性例子(N)被正确预测为阴性(“真阴性”)。
- 28个阴性例子(N)被错误地归类为阳性例子,而它们实际上是阴性的(“假阳性”)。
- 139个正面例子被错误地归类为负面(N),而实际上它们是正面§(“假阴性”)。
- 958例被正确归类为正例(“真阳性”)。
class_report(car_train_prepared, tree_best, car_labels_prepared)
结果好多了。通过将类权重设置为“平衡”并找到超参数的最佳值,能够改进模型。
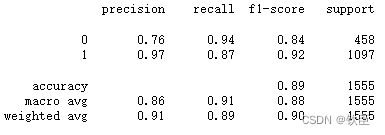
负类的例子比正类的少,可以在分类报告的“support”中看到它们。但模型能够以76%的准确率正确识别它们,并且能够以97%的准确率识别正例,而不会过度拟合,这就是精确性。
关于precision /Recall/F1分数的几点注意事项:
- 精度是模型正确预测正例的精度。
- 召回率是模型正确识别的正面例子的比率。
- F1分数是准确率和召回率的调和平均值。
7.在测试集上评估模型
只有在改进了模型之后,才能把它提供给测试集。如果试图在训练时向模型显示测试集,可能会导致潜在的泄漏,从而产生误导性的预测。
同样,这里将应用与训练集相同的处理函数。
car_test = test_data.drop('binaryClass', axis=1)
car_test_labels = test_data['binaryClass']
car_test_prepared = pipe.transform(car_test)
car_test_labels_prepared = label_enc.transform(car_test_labels)
accuracy(car_test_prepared, tree_best, car_test_labels_prepared)#0.8554913294797688
class_report(car_test_prepared, tree_best, car_test_labels_prepared)
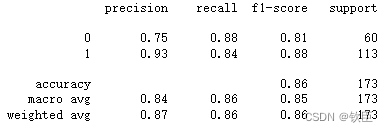
8.总结
决策树的学习到此结束,已经学习了如何构建和如何正则化(或处理过拟合)决策树分类器。