一、数据标注
1、下载标注工具X-Anylabeling
github地址:https://github.com/CVHub520/X-AnyLabeling
直接下载源码,根据Readme.md配置环境即可
下载并配置环境后
windows cmd打开终端
# 进入文件夹目录
cd D:\AI\X-AnyLabeling-main
python anylabeling/app.py
直接按p打开绘制旋转矩形框即可,zxcv可以调整角度
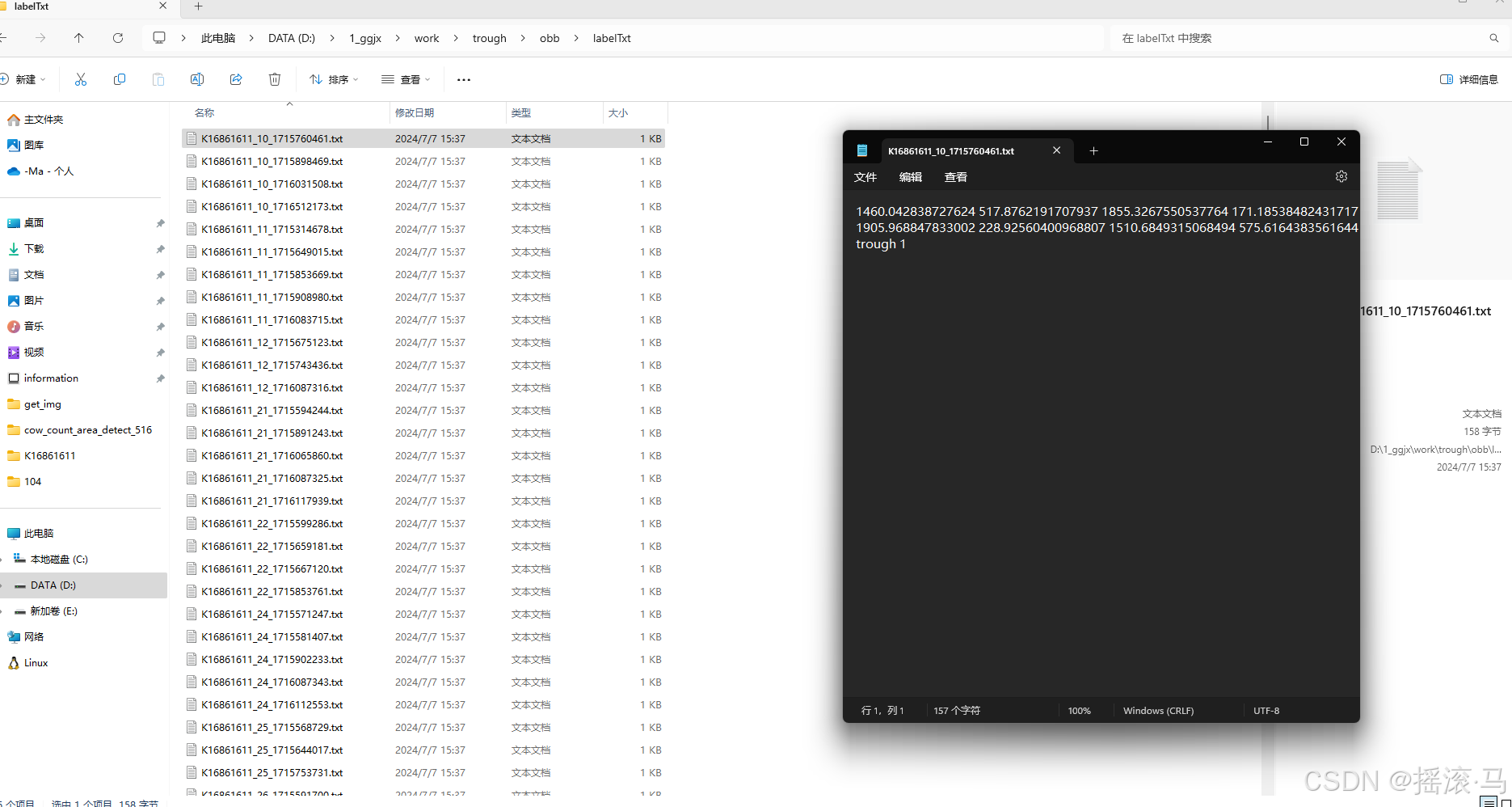
注意标注完后导出的格式为DOTA

导出结果如下图所示
二、yolov8源码下载
yolov8源码:GitHub - ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONNX > OpenVINO > CoreML > TFLite
模型:OBB - Ultralytics YOLO Docs
三、数据预处理
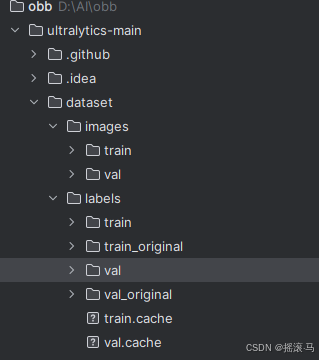
如上图所示,首先你要创建dataset/images及下面两个子目录文件,同理dataset/labels和后缀带有original的文件夹都要手动创建
1、划分数据集
import random
import os
import shutil
def split_dataset(source_images_dir, source_labels_dir, train_images_dir, train_labels_dir, val_images_dir, val_labels_dir, val_ratio=0.2):
# 创建目标文件夹
os.makedirs(train_images_dir, exist_ok=True)
os.makedirs(train_labels_dir, exist_ok=True)
os.makedirs(val_images_dir, exist_ok=True)
os.makedirs(val_labels_dir, exist_ok=True)
# 获取图像文件列表
image_files = os.listdir(source_images_dir)
# 计算验证集的大小
val_size = int(len(image_files) * val_ratio)
# 随机选择验证集的图像文件
val_images = set(random.sample(image_files, val_size))
# 复制图像和标签文件到相应的目标文件夹
for image_file in image_files:
image_path = os.path.join(source_images_dir, image_file)
label_file = image_file.replace('.jpg', '.txt') # 假设标签文件与图像文件同名,不同后缀
label_path = os.path.join(source_labels_dir, label_file)
if image_file in val_images:
shutil.copy(image_path, os.path.join(val_images_dir, image_file))
shutil.copy(label_path, os.path.join(val_labels_dir, label_file))
else:
shutil.copy(image_path, os.path.join(train_images_dir, image_file))
shutil.copy(label_path, os.path.join(train_labels_dir, label_file))
# 调用函数来划分数据集
split_dataset(r'C:\Users\Yaogun-Ma\Desktop\trough\obb\JPEGImages', r'C:\Users\Yaogun-Ma\Desktop\trough\obb\labelTxt', r'C:\Users\Yaogun-Ma\Desktop\trough\obb\images\train', r'C:\Users\Yaogun-Ma\Desktop\trough\obb\labels\train_original', r'C:\Users\Yaogun-Ma\Desktop\trough\obb\images\val', r'C:\Users\Yaogun-Ma\Desktop\trough\obb\labels\val_original', val_ratio=0.2)
修改为自己的路径即可,其中C:\Users\Yaogun-Ma\Desktop\trough\obb\JPEGImages和C:\Users\Yaogun-Ma\Desktop\trough\obb\labelTxt是我标注的数据集路径,其它的都是自己经过上一步创建的路径
2、DOTA数据转为yolov8-obb所训练的格式
from ultralytics.data.converter import convert_dota_to_yolo_obb
convert_dota_to_yolo_obb(r'D:\AI\obb\ultralytics-main\dataset')
路径改为自己刚刚创建的路径即可
运行结果如下

最后就会在我们之前划分数据的路径中的labels文件夹创建了train和val这两个文件了
四、训练
1、修改yaml文件
在路径ultralytics-main/ultralytics/cfg/datasets下新建一个mydata.yaml文件
# Ultralytics YOLO 🚀, AGPL-3.0 license
# DOTA 1.0 dataset https://captain-whu.github.io/DOTA/index.html for object detection in aerial images by Wuhan University
# Documentation: https://docs.ultralytics.com/datasets/obb/dota-v2/
# Example usage: yolo train model=yolov8n-obb.pt data=DOTAv1.yaml
# parent
# ├── ultralytics
# └── datasets
# └── dota1 ← downloads here (2GB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: D:\AI\obb\ultralytics-main\dataset # dataset root dir
train: images/train # train images (relative to 'path') 1411 images
val: images/val # val images (relative to 'path') 458 images
test: images/test # test images (optional) 937 images
# Classes for DOTA 1.0
names:
0: trough
把代码复制进去,修改自己的路径和类别即可
2、开始train
from ultralytics import YOLO
def main():
model = YOLO(r'D:\AI\obb\ultralytics-main\ultralytics\cfg\models\v8\yolov8-obb.yaml').load(r'D:\AI\obb\ultralytics-main\yolov8n-obb.pt') # build from YAML and transfer weights
model.train(data='./ultralytics/cfg/datasets/mydata.yaml', epochs=100, imgsz=1024, batch=4, workers=0)
if __name__ == '__main__':
main()修改自己的预训练权重路径和其它路径,再运行上面的代码即可
3、测试
from ultralytics import YOLO
# Load a model
# model = YOLO("yolov8n-obb.pt") # load an official model
model = YOLO(r"D:\AI\obb\ultralytics-main\runs\obb\train3\weights\best.pt") # load a custom model
# Predict with the model
results = model(r"D:\AI\obb\ultralytics-main\dataset\images\train", save=True) # predict on an image修改自己训练后的权重路径、测试数据路即可