
摘要
作者提出了一种简单而强大的卷积神经网络架构,其推理阶段采用与 VGG 类似的网络体结构,仅由一堆 3x3 卷积和 ReLU 组成,而训练阶段的模型具有多分支拓扑。这种训练阶段和推理阶段架构的解耦通过结构重参数化技术实现,因此我们将该模型命名为 RepVGG。
# 理论介绍
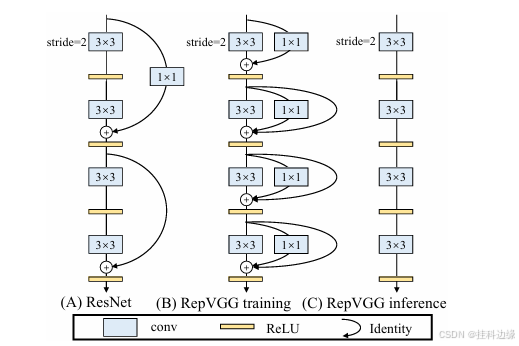
RepConv 通过将多个卷积操作合并成一个卷积操作来优化计算的。首先在训练过程中使用多种操作(如多个卷积层、跳跃连接等)来提高模型的表达能力和训练效果,而在推理时,通过重参数化将这些操作转化为单一的卷积层,从而减少计算量和提高速度。
- 训练阶段:在训练时,使用常规的多分支结构,包含多个卷积层、BN 层以及跳跃连接。这种结构可以使模型在训练过程中具有更高的表达能力,从而提高训练性能。这时,每个卷积层可以通过与不同的卷积核和跳跃连接组合来建模复杂的特征。
- 推理阶段(重参数化):在模型训练完成后,通过一种 重参数化方法,将训练中多层卷积的操作合并成一个单一的卷积操作。例如,多个卷积层和 BN 层的参数被合并成一个单一的卷积核,从而减少了计算量。在推理阶段,RepConv 会将多个卷积层和 BN 层合并成一个 3×3 卷积层 和相应的偏置。通过这种方式,可以避免在推理时需要进行多个卷积操作和大量的内存占用。
下图摘自论文
理论详解可以参考链接:论文地址
代码可在这个链接找到:代码地址
小目标理论
在YOLOv11 中,输入图像的尺寸为 640x640x3,经过 8 倍、16 倍和 32 倍下采样后分别得到 80x80、40x40 以及 20x20 大小的特征图,网络最终在这三个不同尺度的特征图上进行目标检测。在这三个尺度的特征图中,局部感受野最小的是 8 倍下采样特征图,即如果将该特征图映射到原输入图像,则每个网格对应原图 8x8 的区域。对于分辨率较小的目标而言,8 倍下采样得到的特征图感受野仍然偏大,容易丢失某些小目标的位置和细节信息。为了改善目标漏检现状,对 YOLOv8 的 Head 结构进行优化,在原有的三尺度检测头的基础之上,新增一个针对微小目标检测的检测头 ,YOLOv11 原有 P3、P4 和 P5 这 3 个输出层,分别用于检测小、中、大目标,增加 P2 检测层后,网络能在4个不同尺度的特征图上做检测,P2 能检测到最小目标分辨率为 4x4。通过增加小尺度