pc端MNIST数据集pytorch模型CNN网络转换为onnx部署树莓派4B和神经棒NCS2(使用openvino2021框架)
前提:openvino在pc和树莓派都配置ok
在PC端pytorch构建CNN 识别手写数字
自动下载mnist数据集 分析 训练
参考开源代码
#main.py
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
#torch.__version__
BATCH_SIZE = 256
EPOCHS = 1 # 总共训练批次
DEVICE = 'cpu' #或‘MRAID’神经棒
# 下载训练集
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=BATCH_SIZE, shuffle=True)
# 下载测试集
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=BATCH_SIZE, shuffle=True)
# 定义卷积神经网络
class ConvNet(nn.Module):
def __init__(self):
super().__init__()
# batch*1*28*28(每次会送入batch个样本,输入通道数1(黑白图像),图像分辨率是28x28)
# 下面的卷积层Conv2d的第一个参数指输入通道数,第二个参数指输出通道数,第三个参数指卷积核的大小
self.conv1 = nn.Conv2d(1, 10, 5) # 输入通道数1,输出通道数10,核的大小5
self.conv2 = nn.Conv2d(10, 20, 3) # 输入通道数10,输出通道数20,核的大小3
# 下面的全连接层Linear的第一个参数指输入通道数,第二个参数指输出通道数
self.fc1 = nn.Linear(20 * 10 * 10, 500) # 输入通道数是2000,输出通道数是500
self.fc2 = nn.Linear(500, 10) # 输入通道数是500,输出通道数是10,即10分类
def forward(self, x):
in_size = x.size(0) # 在本例中in_size=512,也就是BATCH_SIZE的值。输入的x可以看成是512*1*28*28的张量。
out = self.conv1(x) # batch*1*28*28 -> batch*10*24*24(28x28的图像经过一次核为5x5的卷积,输出变为24x24)
out = F.relu(out) # batch*10*24*24(激活函数ReLU不改变形状))
out = F.max_pool2d(out, 2, 2) # batch*10*24*24 -> batch*10*12*12(2*2的池化层会减半)
out = self.conv2(out) # batch*10*12*12 -> batch*20*10*10(再卷积一次,核的大小是3)
out = F.relu(out) # batch*20*10*10
out = out.view(in_size, -1) # batch*20*10*10 -> batch*2000(out的第二维是-1,说明是自动推算,本例中第二维是20*10*10)
out = self.fc1(out) # batch*2000 -> batch*500
out = F.relu(out) # batch*500
out = self.fc2(out) # batch*500 -> batch*10
out = F.log_softmax(out, dim=1) # 计算log(softmax(x))
return out
# 训练
def train(model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if (batch_idx + 1) % 30 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
# 测试
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # 将一批的损失相加
pred = output.max(1, keepdim=True)[1] # 找到概率最大的下标
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
if __name__ == '__main__':
model = ConvNet().to(DEVICE)
optimizer = optim.Adam(model.parameters())
for epoch in range(1, EPOCHS + 1):
train(model, DEVICE, train_loader, optimizer, epoch)
test(model, DEVICE, test_loader)
# 保存训练完成后的模型
torch.save(model, './MNIST.pth')
#下面三句来自openvino文档 调用torch中onnx函数进行模型转换
model.eval()
dummy_input = torch.randn(1,1,28,28)
torch.onnx.export(model,(dummy_input),'model.onnx')
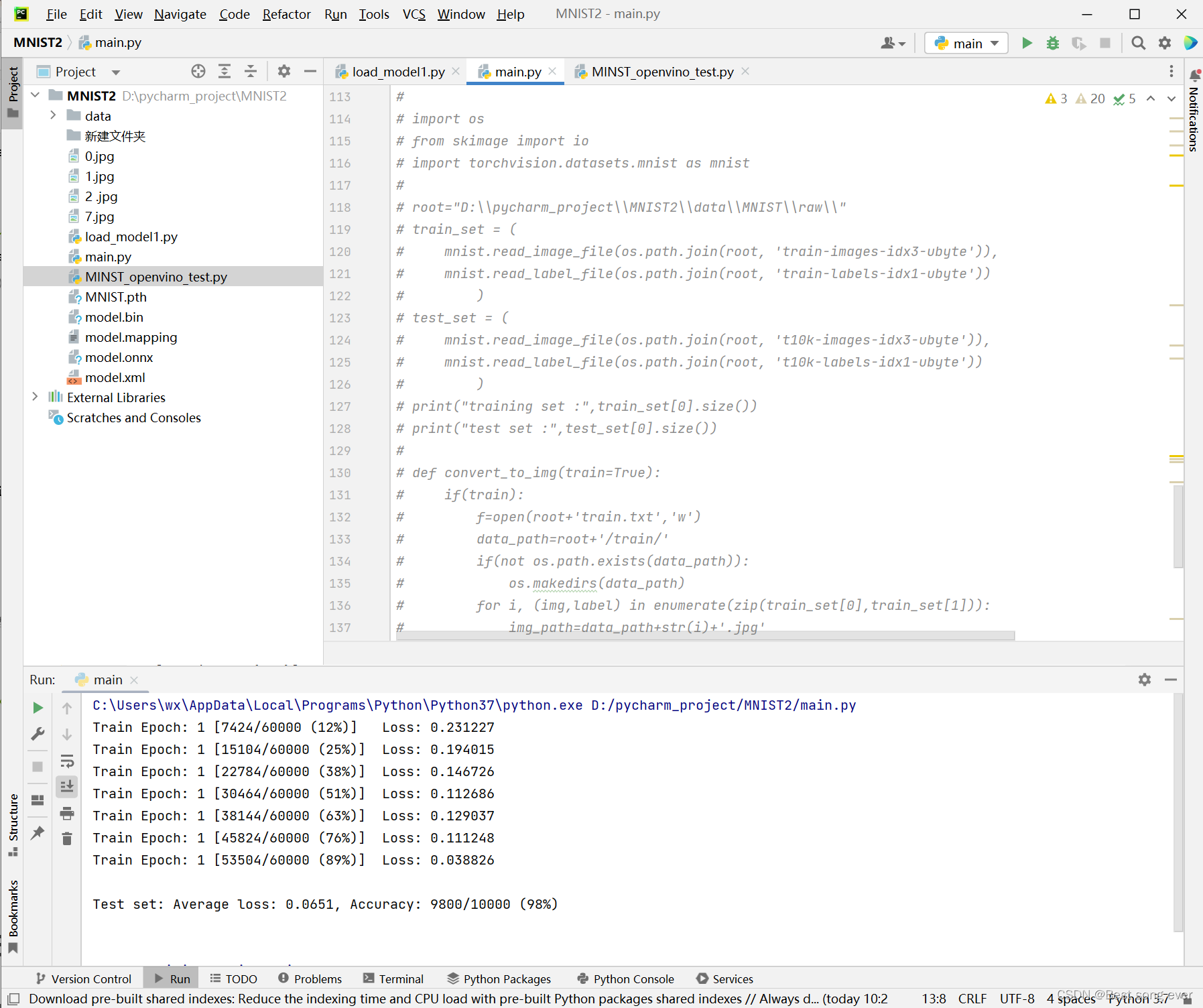
现在应该文件夹下有个.onnx
在PC端转换出mnist中的图片用于测试
注意转换的路径
#load_picture.py
import os
from skimage import io
import torchvision.datasets.mnist as mnist
root="D:\\pycharm_project\\MNIST2\\data\\MNIST\\raw\\"
train_set = (
mnist.read_image_file(os.path.join(root, 'train-images-idx3-ubyte')),
mnist.read_label_file(os.path.join(root, 'train-labels-idx1-ubyte'))
)
test_set = (
mnist.read_image_file(os.path.join(root, 't10k-images-idx3-ubyte')),
mnist.read_label_file(os.path.join(root, 't10k-labels-idx1-ubyte'))
)
print("training set :",train_set[0].size())
print("test set :",test_set[0].size())
def convert_to_img(train=True):
if(train):
f=open(root+'train.txt','w')
data_path=root+'/train/'
if(not os.path.exists(data_path)):
os.makedirs(data_path)
for i, (img,label) in enumerate(zip(train_set[0],train_set[1])):
img_path=data_path+str(i)+'.jpg'
io.imsave(img_path,img.numpy())
f.write(img_path+' '+str(label)+'\n')
f.close()
else:
f = open(root + 'test.txt', 'w')
data_path = root + '/test/'
if (not os.path.exists(data_path)):
os.makedirs(data_path)
for i, (img,label) in enumerate(zip(test_set[0],test_set[1])):
img_path = data_path+ str(i) + '.jpg'
io.imsave(img_path, img.numpy())
f.write(img_path + ' ' + str(label) + '\n')
f.close()
convert_to_img(True)#转换训练集
convert_to_img(False)#转换测试集
在\raw\test的文件夹下可以看到所有的图片
复制几张图片复制到主程序下 等等进行检验


PC端使用openvino将模型转成xml和bin
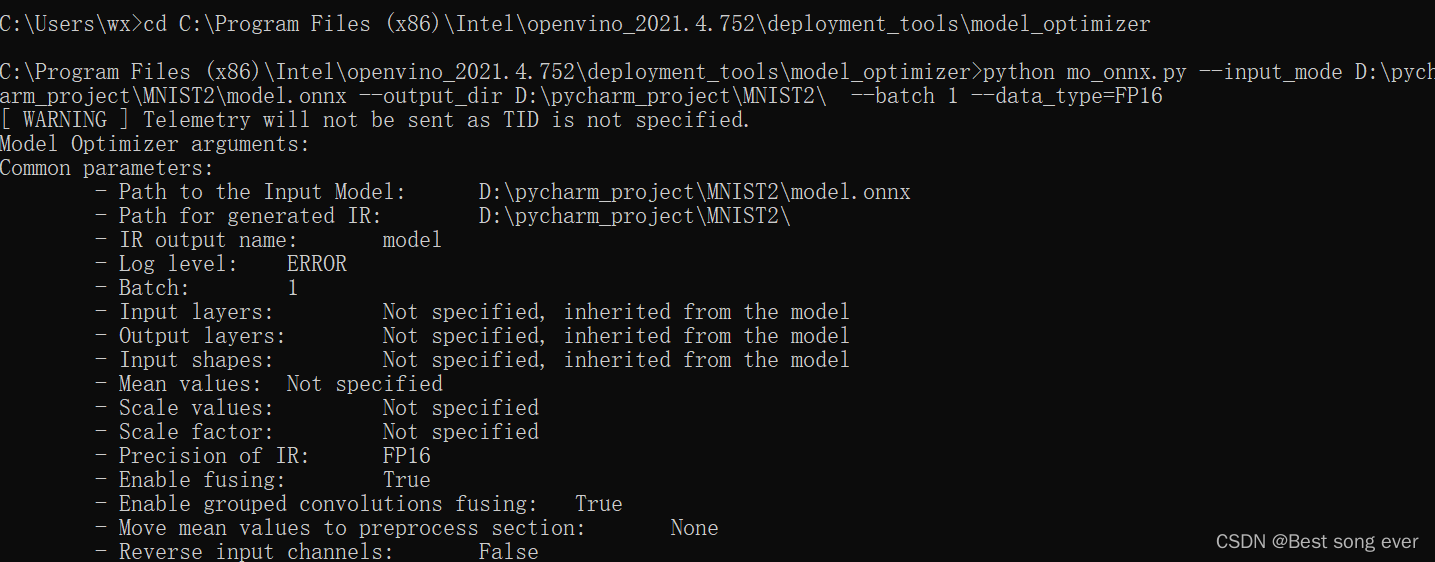
使用cmd窗口
cd 【根据自己openvino位置如下目录】
C:\Program Files (x86)\Intel\openvino_2021.4.752\deployment_tools\model_optimizer
看到mo.py文件
在cmd中输入如下
-input_mode 输入模型地址 是个onnx文件
–output_dir 输出xml和bin文件的地址
–batch 1 好像都是1
–data_type=FP16 是树莓派接收的类型
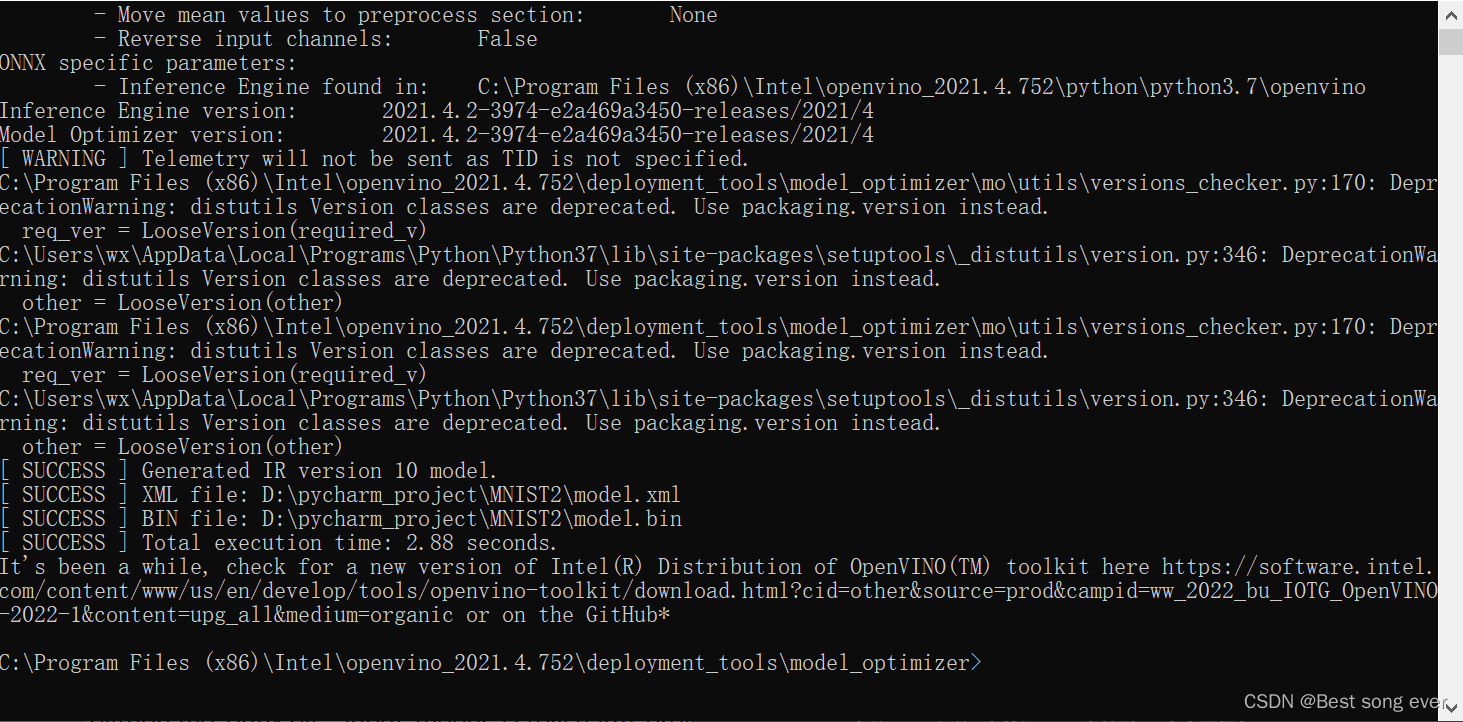
python mo_onnx.py --input_mode D:\pycharm_project\MNIST2\model.onnx --output_dir D:\pycharm_project\MNIST2\ --batch 1 --data_type=FP16
在–output_dir 地址下 看到xml和bin文件 就欧ok
PC端使用openvino将模型进行推理
使用openvino的 iecore引擎进行推理
前面import是用来调试使用的 不影响
没有用到torch框架
下面部分代码参考这个视频 p8
【基于 Python 的 OpenVINO 开发实战教程】 https://www.bilibili.com/video/BV1Xq4y177Sw?p=8&share_source=copy_web&vd_source=439a535f314073204168dbf828e16e2c
如图,视频使用的2020 与本次的2021.4openvino语法有不同 比如inputs不能再使用 具体更改如下
#test_openvino.py
#import torch
#import torch.nn as nn
##from MNIST.pth import *
#import glob
import cv2
#import torch.nn.functional as F
#from torch.autograd import Variable
#from torchvision import datasets, transforms
import numpy as np
import torch
#import torchvision
#from skimage import io, transform
#from MNIST import *
from openvino.inference_engine import IECore,IENetwork
from time import time
ie = IECore()
for device in ie.available_devices:
print(device)
DEVICE = 'CPU'#'MYRIAD'#这里在PC端是cpu 神经棒也行
model_xml = 'model.xml'#给自己PC的xml文件所在地址
#'/Downloads/test2/main.xml'#树莓派文件地址先搁在这里
model_bin = 'model.bin'
#'/Downloads/test2/main.bin'
image_file = '7.jpg'#这里是把上面的几个图用于测试 图片改名为7.jpg
#'/Downloads/test2/9.png'
#读取IR模型文件
net = ie.read_network(model=model_xml, weights=model_bin)
#准备输入输出张量
print("Preparing input blobs")
input_blob = next(iter(net.input_info))#2021openvino这里有变化
out_blob = next(iter(net.outputs))
net.batch_size = 1
#载入模型到AI推断计算设备
print("Loading IR to the plugin...")
exec_net = ie.load_network(network=net, num_requests=1, device_name=DEVICE)
#读入图片
print('read picture')
n, c, h, w = net.input_info[input_blob].input_data.shape
print(n,c,h,w)
image1 = cv2.imread(image_file,0)
print(type(image1))
#执行推理
image = cv2.resize(image1, (w, h))
start = time()
res = exec_net.infer(inputs={input_blob:image})
end = time()
print("Infer Time:{}s".format((end-start)))
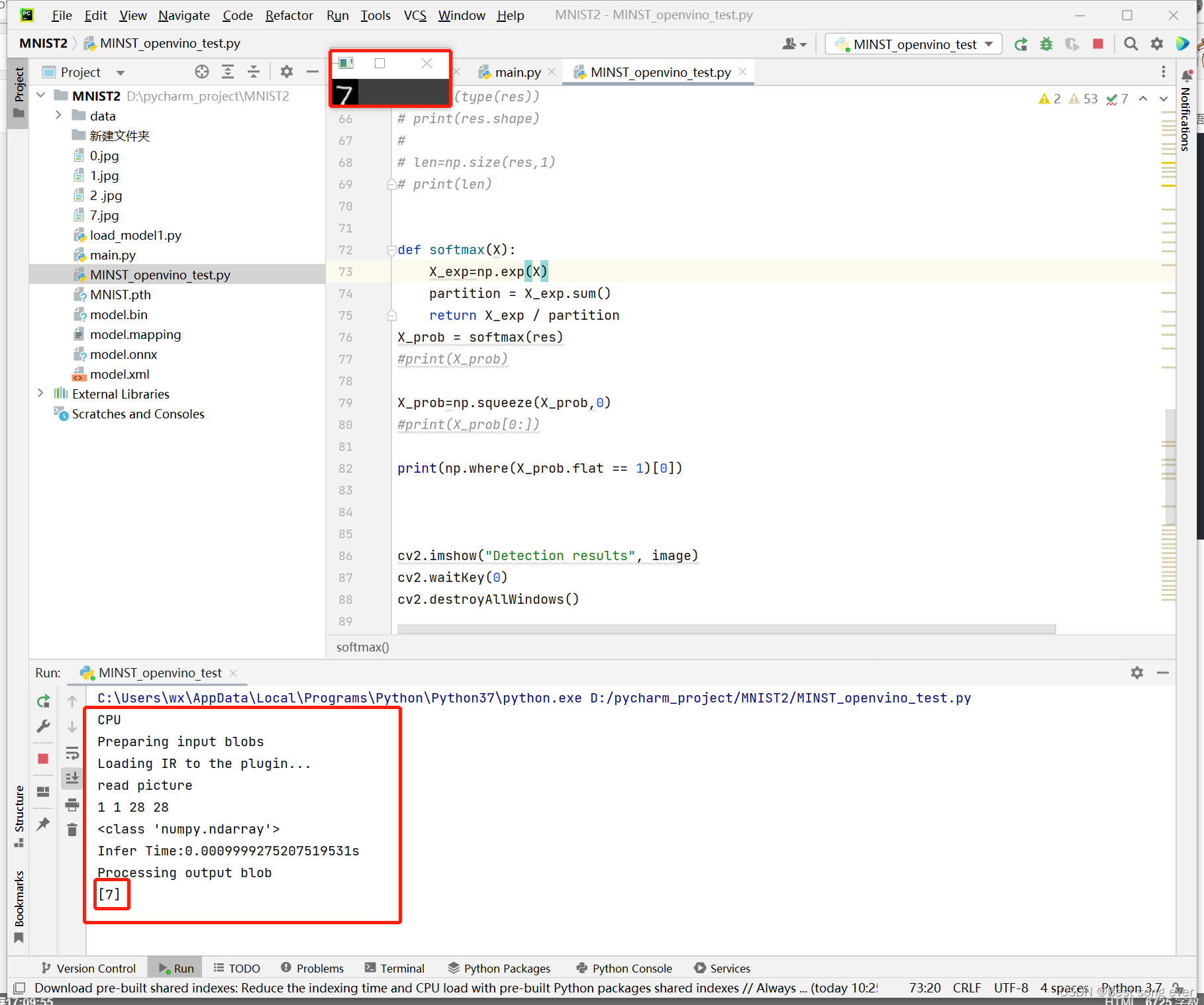
#显示结果
print("Processing output blob")
res = res[out_blob]
# torch.Tensor(res)#这些是用于测试的
# print(res)
# print(type(res))
# print(res.shape)
#
# len=np.size(res,1)
# print(len)
#用softmax进行数值归一化
def softmax(X):
X_exp=np.exp(X)
partition = X_exp.sum()
return X_exp / partition
X_prob = softmax(res)
#print(X_prob)
X_prob=np.squeeze(X_prob,0)
#print(X_prob[0:])
print(np.where(X_prob.flat == 1)[0])
cv2.imshow("Detection results", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
树莓派使用openvino将模型进行测试
把测试图片 xml bin 和一个载入程序传到树莓派
插上神经棒
进入文件夹 用python3 运行.py文件
这.py文件和上面的差不多
#import torch
#import torch.nn as nn
#from MNIST.pth import *
#import glob
import cv2
#import torch.nn.functional as F
#from torch.autograd import Variable
#from torchvision import datasets, transforms
import numpy as np
#import torchvision
#from skimage import io, transform
#from MNIST import *
from openvino.inference_engine import IECore,IENetwork
from time import time
ie = IECore()
for device in ie.available_devices:
print(device)
DEVICE = 'MYRIAD'#这里是神经棒
model_xml = 'model.xml'#文件地址要对
#'/Downloads/test2/main.xml'
model_bin = 'model.bin'
#'/Downloads/test2/main.bin'
image_file = '7.jpg'
#'/Downloads/test2/9.png'
#读取IR模型文件
net = ie.read_network(model=model_xml, weights=model_bin)
#准备输入输出张量
print("Preparing input blobs")
input_blob = next(iter(net.input_info))
out_blob = next(iter(net.outputs))
net.batch_size = 1
#载入模型到AI推断计算设备
print("Loading IR to the plugin...")
exec_net = ie.load_network(network=net, num_requests=1, device_name=DEVICE)
#读入图片
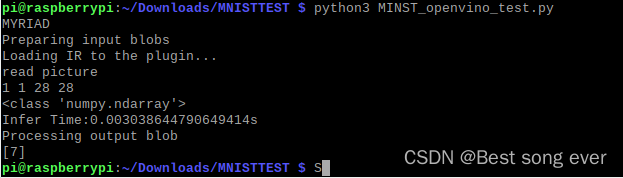
print('read picture')
n, c, h, w = net.input_info[input_blob].input_data.shape
print(n,c,h,w)
image1 = cv2.imread(image_file,0)
print(type(image1))
#执行推理
image = cv2.resize(image1, (w, h))
start = time()
res = exec_net.infer(inputs={input_blob:image})
end = time()
print("Infer Time:{}s".format((end-start)))
print("Processing output blob")
res = res[out_blob]
def softmax(x):
x=np.exp(x)
p=x.sum()
return x/p
x=softmax(res)
x=np.squeeze(x,0)
print(np.where(x.flat == 1)[0])
cv2.imshow("Detection results", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
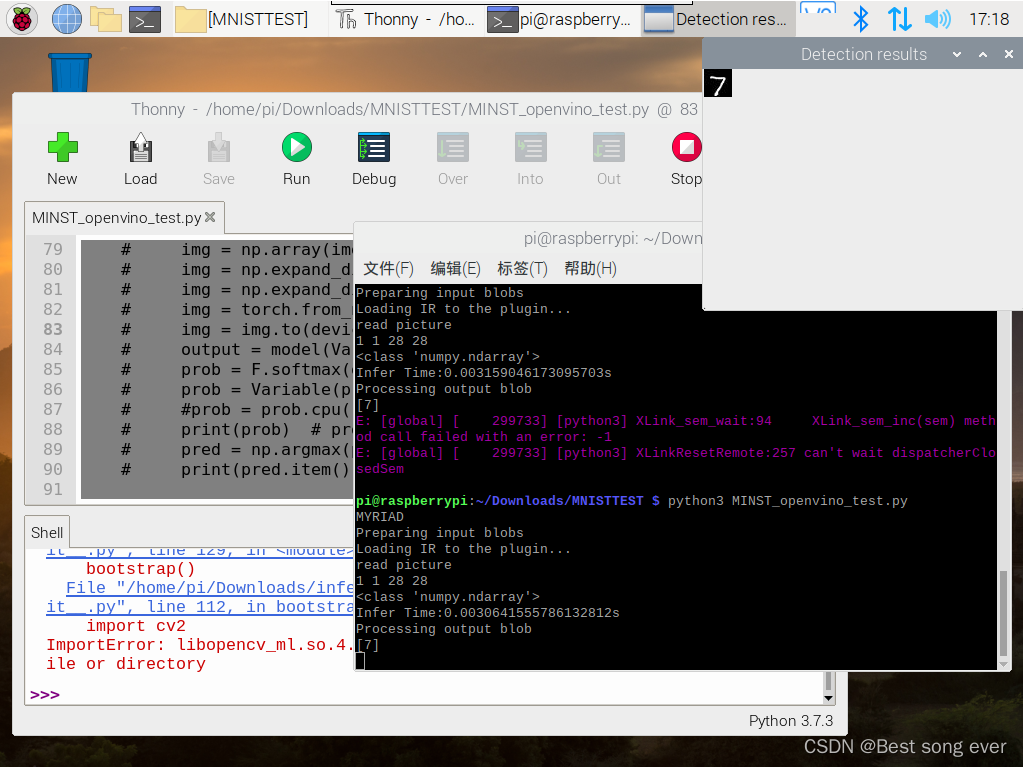
得到结果
这个py不能在内置的Thonny里面run
openvino配置时候没有这个
所以要在命令行里运行
https://www.intel.com/content/www/us/en/developer/tools/openvino-toolkit/download.html
694569236