深入理解vqvae
TL; DR:通过 vector quantize 技术,训练一个离散的 codebook,实现了图片的离散表征。vqvae 可以实现图片的离散压缩和还原,在图片自回归生成、Stable Diffusion 中,有重要的应用。
从 AE 和 VAE 说起
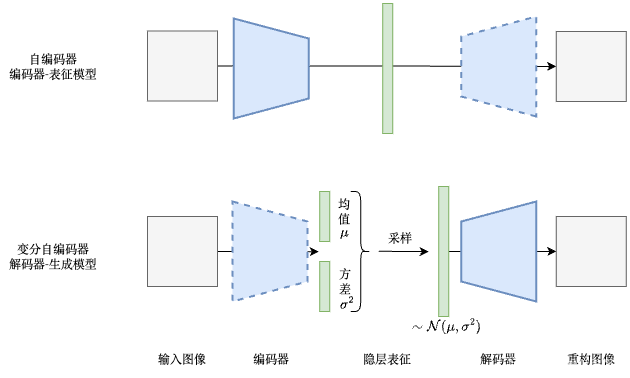
AE(AutoEncoder,自编码器)是非常经典的一种自监督表征学习方法,它由编码器 encoder 和解码器 decoder 构成,编码器提取输入图像的低维特征,解码器根据该特征重构出输入图像,损失函数一般就是原始图像和重构图像间的 L1 / L2 损失。由于解码器需要根据特征重构出输入图像,因此需要编码器提取的特征尽可能包含完整的图像信息,因此训练出的编码器是一个不错的图像特征提取器。在训练完成后,编码器就是一个图像表征模型,而解码器就没有用处了,丢掉即可。
AE 的解码器真的没有任何用处了吗?它能够根据一个任意的特征向量,生成出一张真实图片,明明看起来本身就是一个图像生成模型了呀。但实际上,AE 的解码器只能认识训练时 AE 的编码器提取出的特征,而对于任意采样的特征向量,他是无法生成出图像的。换句话说,AE 训练时,编码器产生的隐层特征的分布我们是不知道的,在采样时,自然无法采样出这种解码器认识的分布的特征,给解码器去生成图片。
其实这也好办,我们约束一下 AE 训练时隐层特征的分布就好了嘛,训练结束后从这个规定的分布中采样出的特征向量,解码器肯定就认得了。VAE(Variational AutoEncoder,VAE)其实就是这么做的,它将隐变量的分布约束为高斯分布。VAE 中,编码器的输出直接就被认为是高斯分布的均值和方差,然后,根据该均值和方差(结合重参数化技巧),从高斯分布中采样一个隐变量,输入到解码器中生成。VAE 训练结束后,解码器就是一个生成模型,我们可以从高斯分布中采样,输入给解码器生成新的图片,反而编码器就没有用处了,丢掉即可。
vqvae:从连续表征到离散表征
我们生活的世界实际上是离散的,而非连续的,量化的思想能上溯到量子力学。
在 NLP 中,通常是先有一个 tokenizer,将自然语言转换成一个个的 token,实际就是一个个的离散的整数索引,接下来有一个 embedding 层,查索引获取对应的词嵌入 embedding,然后再送入到模型中处理。因此对于自然语言来说,数据是由一个个 token 组成,是一种离散的数据模态。
在 CV 中,计算机中的图片硬要说也是离散的数据,因为所有可能得图像像素数量也是有限的,一般对彩色图像最多 256 × 256 × 3 256\times 256\times 3 256×256×3 种。但由于这个数太大,因此一般认为图像是一种连续的数据模态,一般读图进来,再像素归一化之后直接就输入模型中处理。
vqvae 的作者认为离散的数据形式其实是更自然的,由此提出了 vqvae,使用 vector quantize 的方法,将图像编码为离散的表征。
首先,构建一个图像特征的 codebook(码本,原文中称为 Embedding Space),它的作用就类似于 NLP 中的词嵌入 embedding 层。codebook 是一个可学习的 K × D K\times D K×D 的张量,其中 K K K 是表征向量 embedding 的个数, D D D 是 embedding 的维度。对于一张输入图像,CNN 编码器会提取其特征图 z e z_e ze,特征图尺寸为 h × w × D h\times w\times D h×w×D,也就是 h × w h\times w h×w 个 D D D 维的向量。每个向量在 codebook 中找到与其最接近向量的索引,按索引取得最接近向量,得到量化后特征图 z q z_q zq。 z q z_q zq 送入解码器中,输出重构图像。
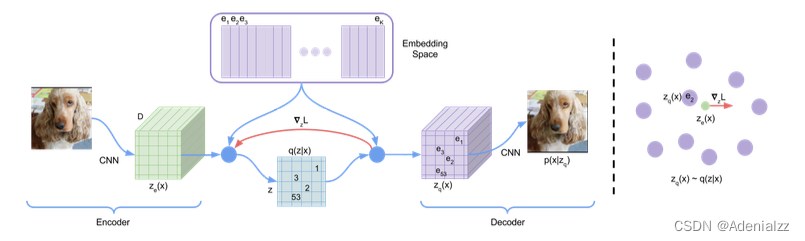
这里有一个问题,就是取码本里取最接近的向量,是一个 argmin 操作,是没法传导梯度的。这里作者使用了一种类似 straight-through estimator 的方法来处理,在反向传播时跳过这一步,直接将 z q z_q zq 的梯度复制给 z e z_e ze 。如上图所示,前向传播时,正常计算 codebook 中与 z e z_e ze 最近邻的的向量,得到 z q z_q zq 送到解码器,而在反向传播时,直接将 z q z_q zq 的梯度 ∇ z L \nabla_zL ∇zL 复制给 z e z_e ze 。由于 z q z_q zq 和 z e z_e ze 的维度是一样的,都是 D D D,因此这样复制过来的梯度可以指导 encoder 的参数更新。
在整个过程中,可训练的参数共包括三部分:编码器、码本、解码器,驱动这三部分训练的损失函数是怎么设计的呢?首先,与 ae、vae 一样,vqvae 有一项重构损失 log p ( x ∣ z q ( x ) ) \log p(x|z_q(x)) logp(x∣zq(x)) 来优化编码器和解码器。但是由于使用了梯度停止技术,这一项重构损失是无法优化 codebook 的。作者这里使用了 vector quantization 技术来优化 codebook,具体来说,就是最小化码本向量与解码器输出向量的 L2 距离 ∣ ∣ sg [ z e ( x ) ] − e ∣ ∣ 2 2 ||\text{sg}[z_e(x)]-e||_2^2 ∣∣sg[ze(x)]−e∣∣22 。另外,由于这里相当于只是在更新 codebook 里的向量,因此也可以试着使用 EMA 技术来动量更新。最后为了保证 encoder 提取出的隐变量与 codebook 中的向量尽可能接近,需要使得 codebook 与编码器的训练速度尽量一致,因此这里还加了一个正则项来约束编码器的参数更新 ∣ ∣ z e ( x ) − sg [ e ] ∣ ∣ 2 2 ||z_e(x)-\text{sg}[e]||_2^2 ∣∣ze(x)−sg[e]∣∣22,称为 commitment loss。
综上,vqvae 整体的损失函数为:
L
=
L
reconstruction
+
L
embedding
+
β
L
commitment
=
log
p
(
x
∣
∣
z
q
(
x
)
)
+
∣
∣
sg
[
z
e
(
x
)
−
e
∣
∣
2
2
+
β
∣
∣
z
e
(
x
)
−
sg
[
e
]
∣
∣
2
2
\begin{align} L&=L_{\text{reconstruction}}+L_{\text{embedding}}+\beta L_{\text{commitment}} \\ &=\log p(x||z_q(x))+||\text{sg}[z_e(x)-e||_2^2+\beta||z_e(x)-\text{sg}[e]||_2^2 \end{align}
L=Lreconstruction+Lembedding+βLcommitment=logp(x∣∣zq(x))+∣∣sg[ze(x)−e∣∣22+β∣∣ze(x)−sg[e]∣∣22
其中,第一项 reconstruction loss 用于优化 encoder 和 decoder,第二项 embedding loss 用于优化码本,第三项 commitment loss 相当于是个正则项,约束 encoder 的训练。
上面的
sg
\text{sg}
sg 是梯度停止(stop gradient),其计算在前向传播时不变,在反向传播时偏导数为 0。这在代码实现时也很好操作,以 pytorch 为例,
sg
[
x
]
\text{sg}[x]
sg[x] 操作就是 x.detach() 。
简单总结一下,vqvae 的 encoder 是一个图像表征模型,不同于一般的图像表征模型对图像提取一个特征向量,vqvae 是提取出一张特征图(多个特征向量的二维排布),相当于是将一张像素空间的大图压缩为了一张隐空间的小图。而 vqvae 的 decoder 则可以将一张隐空间的小图解码为像素空间的大图。也就是说,vqvae 相当于是一个负责图片离散压缩和还原的模型。在扩散模型时代,这是不是听起来有点熟悉?没错,大名鼎鼎的 Stable Diffusion 就是使用一个类似 vqvae 的 encoder 将图像压缩到隐空间,进行扩散生成,再用 decoder 将结果解码为真实图像。
图像生成:auto-regressive + vqvae
上节提到,vqvae 是一个负责图片离散压缩和还原的模型,但还有一个问题,怎么利用它来进行图像生成呢?我们之前介绍 vae 时提到,通过将中间层的隐变量分布约束为高斯分布,训练结束后我们可以自行从高斯分布中采样,输入到 decoder 中,生成新的图像。但 vqvae 实际没约束这件事情,应该从什么分布中进行采样生成呢?
实际上,vqvae 自己确实不能实现图像生成。那我们费那么大劲儿把连续表征改为离散表征究竟有什么用呢?想一下,我们之前提到,AE 的解码器之所以不好做生成,就是因为隐层特征分布太自由,可能的方差太大,无法采样。对于这个问题,VAE 是通过强行将隐层特征的分布规定为高斯分布来解决。而在 vqvae 中,我们将原本接近无限的采样可能,约束为了有限的 codebook 中的几千个 code,这样解码器处理的隐层特征分布也是很有限的,方差也得到了约束。相比于完全自由采样,在 codebook 中采样生成就会容易得多。
再联系 NLP 中 tokenizer 和词表 vocab 的概念,有了离散的 vqvae 和 codebook 之后,我们就能做自回归式的生成了(类似 GPT 那样)!在图像生成领域,之前也有自回归式生成的方法,比较知名的是PixelCNN,按照从左上到右下的顺序生成图像的像素值。这听起来成本就很高,现在图片怎么也要上百万像素,所有可能的像素数也多达 256 × 256 × 3 256\times 256\times 3 256×256×3 种,一个一个地生成像素效率也太低了。但有了 vqvae,我们就可以在隐空间特征图上进行自回归生成,空间分辨率一般为 64 × 64 64\times 64 64×64 ,码本中可能的向量数也只有几千个。生成隐空间特征图之后,再用 vqvae 的 decoder 将其解码为像素空间的真实图片即可。生成效率和生成结果质量都大幅提升。
一个典型的 auto-regressive + vqvae 的图像生成系统的训练和采样有以下步骤:
- 训练 vqvae,包括 encoder、decoder 和 codebook;
- 基于固定参数的 vqvae,训练自回归模型(如 PixelCNN)
- 在生成时,先自回归采样一个隐空间特征图,再用 vqvae decoder 将其解码为像素空间的真实图片
总结
vqvae 首次在 cv 领域提出使用 vector quantize 来构建一个离散的 codebook,与其后续的 vqgan 等工作,被认为是 ”图片的 tokenizer“。将图片编码为 token,就能与 NLP token 的形式统一起来,一起在多模态 transformer 模型中进行训练。另外,vqvae encoder 将真实图片压缩为低维特征图, decoder 将低维特征图解码为真实图片的能力,在 ldm 中也大有用武之地,可以极大地降低训练/推理成本,提升生成结果的质量。已经成为扩散生成模型的主流。综上所述,在 transformer、diffusion 的时代,vqvae 的影响和意义极其深远。