Consistency Models
本文介绍 Song Yang 大佬提出的 Consistency Models,实现扩散模型一步采样生成,同时支持多步采样以权衡采样质量和生成速度。可通过蒸馏或原生训练两种模式进行训练。
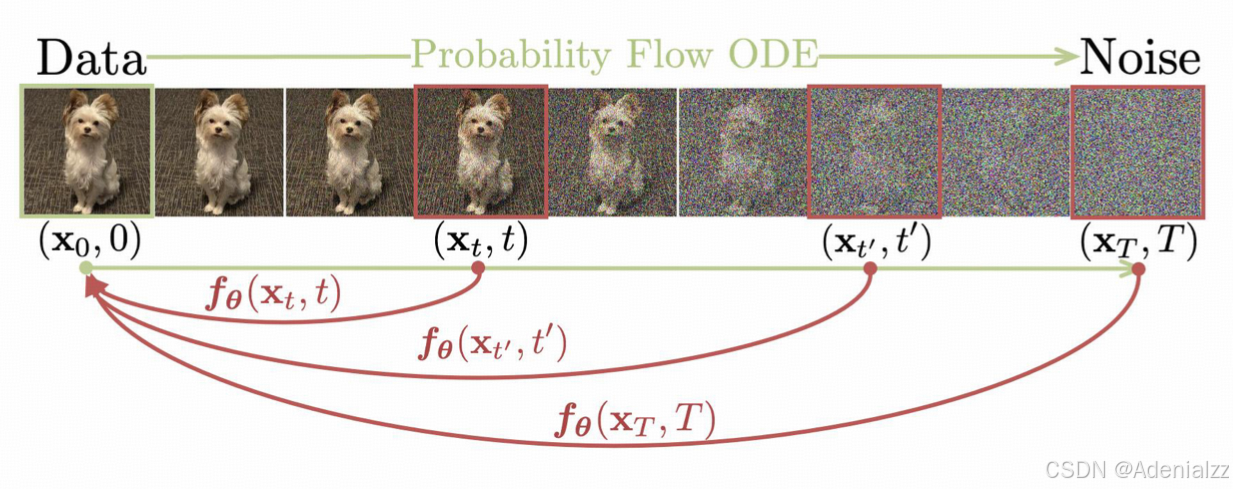
背景知识:扩散模型
Consistency Models 的设计是基于连续时间扩散模型(SDE/ODE、EDM)。扩散模型通过高斯噪声扰动,逐步将数据转变为纯噪声,并通过从纯噪声图逐步去噪来生成新的样本。具体来说,记数据分布为
p
data
(
x
)
p_\text{data}(\mathbf{x})
pdata(x),扩散模型首先使用 Ito SDE 对其进行扰动:
d
x
t
=
μ
(
x
t
,
t
)
d
t
+
σ
(
t
)
d
w
t
d\mathbf{x}_t=\mathbf{\mu}(\mathbf{x}_t,t)dt+\sigma(t)d\mathbf{w}_t
dxt=μ(xt,t)dt+σ(t)dwt
其中
t
∈
[
0
,
T
]
t\in[0,T]
t∈[0,T],
T
>
0
T>0
T>0 是一个常数,
μ
(
⋅
,
⋅
)
\mu(\cdot,\cdot)
μ(⋅,⋅) 和
σ
(
t
)
\sigma(t)
σ(t) 分别是漂移系数和扩散系数,
{
w
t
}
t
∈
[
0
,
T
]
\{\mathbf{w}_t\}_{t\in[0,T]}
{wt}t∈[0,T] 表示标准布朗运动。我们记
x
t
\mathbf{x}_t
xt 的分布为
p
t
(
x
)
p_t(\mathbf{x})
pt(x),从而有
p
0
(
x
)
≡
p
data
(
x
)
p_0(\mathbf{x})\equiv p_\text{data}(\mathbf{x})
p0(x)≡pdata(x)。这个 SDE 有一个很关键的性质,即:存在一个 ODE(称为概率流 ODE,PF ODE),其解轨迹在
t
t
t 时刻的采样也服从同样的
p
t
(
x
)
p_t(\mathbf{x})
pt(x)。该 ODE 的形式为:
d
x
t
=
[
μ
(
x
t
,
t
)
−
1
2
σ
(
t
)
2
∇
log
p
t
(
x
t
)
]
d
t
d\mathbf{x}_t=[\mu(\mathbf{x}_t,t)-\frac{1}{2}\sigma(t)^2\nabla\log p_t(\mathbf{x}_t)]dt
dxt=[μ(xt,t)−21σ(t)2∇logpt(xt)]dt
其中
log
p
t
(
x
)
\log p_t(\mathbf{x})
logpt(x) 是分布
p
t
(
x
)
p_t(\mathbf{x})
pt(x) 的得分函数。因此扩散模型同样也可以看作是基于得分的生成模型。可以看到,在 PF ODE 中,只有得分函数
∇
log
p
t
(
x
)
\nabla\log p_t(\mathbf{x})
∇logpt(x) 是未知的,因此我们只需要训练一个得分模型
s
ϕ
(
x
,
t
)
≈
∇
log
p
t
(
x
)
\mathbf{s_\phi}(\mathbf{x},t)\approx\nabla\log p_t(\mathbf{x})
sϕ(x,t)≈∇logpt(x) 来估计各时刻分布的得分,就可以根据 PF ODE 进行采样生成。
一般来说,公式 1 中我们选定的的 SDE 形式需要满足在
t
=
T
t=T
t=T 时刻的分布
p
T
(
x
)
p_T(\mathbf{x})
pT(x) 接近于一个便于计算的高斯分布
π
(
x
)
\pi(\mathbf{x})
π(x)。满足这个条件的 SDE 形式有很多,本文中采用的是 EDM 中的 SDE 形式,即
μ
(
x
,
t
)
=
0
\mu(\mathbf{x},t)=0
μ(x,t)=0、
σ
(
t
)
=
2
t
\sigma(t)=\sqrt{2t}
σ(t)=2t。在此形式下,各时刻的分布可表示为数据分布与一个高斯分布的卷积的形式:
p
t
(
x
)
=
p
data
(
x
)
⨂
N
(
0
,
t
2
I
)
p_t(\mathbf{x})=p_\text{data}(\mathbf{x})\bigotimes \mathcal{N}(0,t^2\mathbf{I})
pt(x)=pdata(x)⨂N(0,t2I),其中
⨂
\bigotimes
⨂ 表示卷积操作,
π
(
x
)
\pi(\mathbf{x})
π(x) 服从高斯分布
π
(
x
)
∼
N
(
0
,
T
2
I
)
\pi(\mathbf{x})\sim\mathcal{N}(0,T^2\mathbf{I})
π(x)∼N(0,T2I)。在 EDM 的形式下,PF ODE 为:
d
x
t
d
t
=
−
t
s
ϕ
(
x
t
,
t
)
\frac{d\mathbf{x}_t}{dt}=-t\mathbf{s_\phi}(\mathbf{x}_t,t)
dtdxt=−tsϕ(xt,t)
我们将上式称为 empirical PF ODE。在采样时,我们首先采样最后一个时刻的
x
^
T
∼
π
=
N
(
0
,
T
2
I
)
\hat{\mathbf{x}}_T\sim\pi=\mathcal{N}(0,T^2\mathbf{I})
x^T∼π=N(0,T2I) 来对 empirical PF ODE 进行初始化,然后使用数值 ODE 求解器(如 Euler、Heun 等)按照反向时间来对其进行求解。会得到各时刻解组成的解轨迹
{
x
^
t
}
t
∈
[
0
,
T
]
\{\hat{\mathbf{x}}_t\}_{t\in[0,T]}
{x^t}t∈[0,T]。解轨迹的最后一步
x
^
0
\hat{\mathbf{x}}_0
x^0 就可以认为是大致服从数据分布
p
data
(
x
)
p_\text{data}(\mathbf{x})
pdata(x) 的样本。为了提高数值稳定性,一个常用的技巧是在时间到达一个很小的值
t
=
ϵ
t=\epsilon
t=ϵ 处就停止(而不是达到 0),将
x
^
ϵ
\hat{\mathbf{x}}_\epsilon
x^ϵ 作为最终的生成结果。参考 EDM 中的经验,我们将像素值 rescale 到
[
−
1
,
1
]
[-1,1]
[−1,1] 之间,并设
T
=
80
,
ϵ
=
0.002
T=80,\epsilon=0.002
T=80,ϵ=0.002。
目前,扩散模型应用的主要瓶颈在于采样生成速度。可以看到,使用 ODE 求解器进行采样生成需要多次对得分模型进行计算,这样计算开销很大。现在已经有一些方法,从数值 ODE 求解器加速和蒸馏等方面加速扩散模型采样。然而,目前 ODE 求解器再怎么也需要至少 10 步的模型计算,而大多数蒸馏的方法收集扩散模型生图的大规模数据集。目前只有 Progressive Distillation 没有这个限制,这也是本文对比的主要方法。
Consistency Models
本文提出的 Consistency Model,从设计上就支持单步生成,同时也支持多步采样,使得我们能够在采样速度和生成质量上进行灵活权衡。CM 有两种训练模式:蒸馏模式和原生训练模式。在蒸馏模式中,CM 可以对一个预训练的扩散模型进行知识蒸馏,得到一个单步采样器,对比其他蒸馏加速采样的方法,生图质量大大提升,并且还可以进行 zeroshot 图像编辑。在原生训练模式中,不需要先有一个预训练的扩散模型,直接从头训练 CM,这样 CM 相当于是一类全新的生成模型。
以下,我们将从定义、参数化、采样、图像编辑三个方面介绍 Consistency Model,下一章介绍 Consistency Model 的两种训练模式。
定义
给定一个 PF ODE 的解轨迹 { x t } t ∈ [ ϵ , T ] \{\mathbf{x}_t\}_{t\in[\epsilon,T]} {xt}t∈[ϵ,T],我们定义一个一致性函数 f : ( x t , t ) → x ϵ f:(\mathbf{x}_t,t)\rightarrow \mathbf{x}_\epsilon f:(xt,t)→xϵ。一致性函数有一个重要的性质:自一致性,即对于同一个 PF ODE 解轨迹中的任意的输入参数对 ( x t , t ) (\mathbf{x}_t,t) (xt,t),其输出是一致的。自一致性可表示为:对于所有的 t , t ′ ∈ [ ϵ , T ] t,t'\in[\epsilon,T] t,t′∈[ϵ,T],都有 f ( x t , t ) = f ( x t ′ , t ′ ) f(\mathbf{x}_t,t)=f(\mathbf{x}_{t'},t') f(xt,t)=f(xt′,t′)。我们的 Consistency Model f θ f_\theta fθ 就是要通过学习出自一致性,来拟合这个一致性函数 f f f。
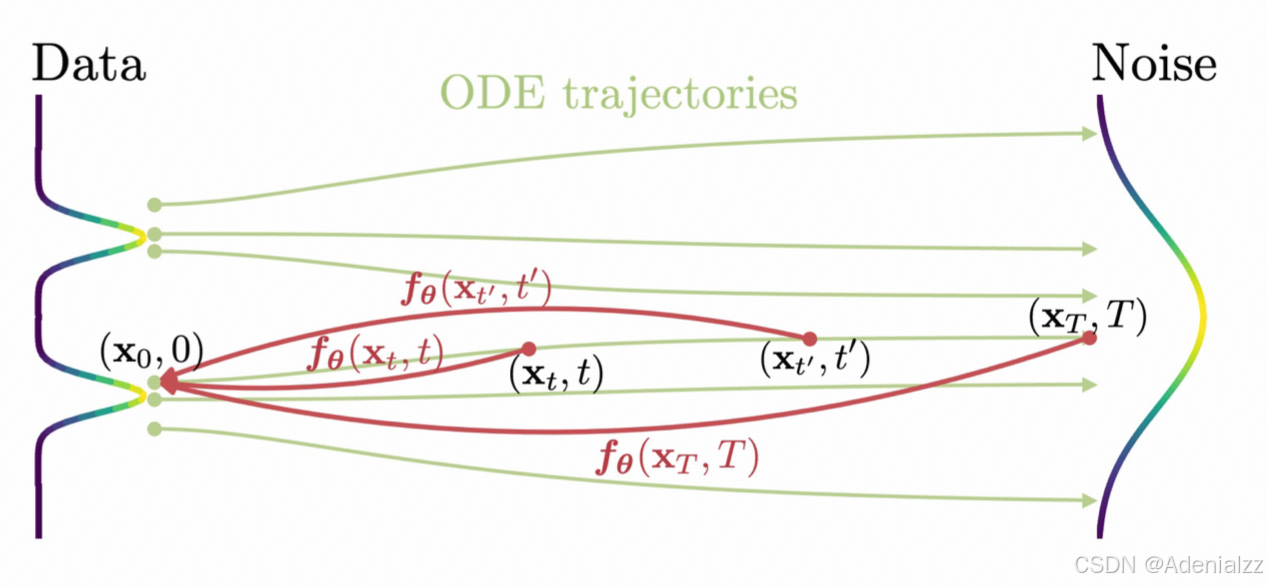
参数化
满足自一致性的一致性函数,一定有一个边界条件: f ( x ϵ , ϵ ) = x ϵ f(\mathbf{x}_\epsilon,\epsilon)=\mathbf{x}_\epsilon f(xϵ,ϵ)=xϵ,即不管输入是什么, f ( ⋅ , ϵ ) f(\mathbf{\cdot,\epsilon}) f(⋅,ϵ) 是一个恒等映射。所有的一致性函数都需要满足这个边界条件,这是 CM 成功训练的关键,也是 CM 在结构上的一种限制。对于基于神经网络的 CM,我们讨论两种满足边界条件的形式。假设我们有一个输入输出的维度相同的、无任何限制的神经网络 F θ ( x , t ) F_\theta(\mathbf{x},t) Fθ(x,t)。
第一种满足边界条件的形式是直接将 CM 参数化为:
f
θ
(
x
,
t
)
=
{
x
t
=
ϵ
F
θ
(
x
,
t
)
t
∈
(
ϵ
,
T
)
f_\theta(\mathbf{x},t)= \begin{cases} \mathbf{x}\quad &t=\epsilon \\ F_\theta(\mathbf{x},t)&t\in(\epsilon,T) \end{cases}
fθ(x,t)={xFθ(x,t)t=ϵt∈(ϵ,T)
第二种参数化的形式是使用跳跃连接(skip connections):
f
θ
(
x
,
t
)
=
c
skip
(
t
)
x
+
c
out
F
θ
(
x
,
t
)
f_\theta(\mathbf{x},t)=c_\text{skip}(t)\mathbf{x}+c_\text{out}F_\theta(\mathbf{x},t)
fθ(x,t)=cskip(t)x+coutFθ(x,t)
其中
c
skip
(
t
)
c_\text{skip}(t)
cskip(t) 和
c
out
(
t
)
c_\text{out}(t)
cout(t) 都是可微函数,且有
c
skip
(
ϵ
)
=
1
,
c
out
(
ϵ
)
=
0
c_\text{skip}(\epsilon)=1,\quad c_\text{out}(\epsilon)=0
cskip(ϵ)=1,cout(ϵ)=0。这样,也能满足边界条件。我们注意到,第二种 CM 的参数化形式与 EDM、eDiff-i 等扩散模型的形式非常像,有许多可以借鉴的模型结构。因此我们选择第二种参数化形式。
采样
当一致性模型 f θ ( ⋅ , ⋅ ) f_\theta(\cdot,\cdot) fθ(⋅,⋅) 训练完成之后,我们就可以进行采样生成样本。只需先从初始化分布中采样一个 x ^ T ∼ N ( 0 , T 2 I ) \hat{\mathbf{x}}_T\sim\mathcal{N}(0,T^2\mathbf{I}) x^T∼N(0,T2I) ,然后可以使用一致性模型直接得到生成结果 x ^ ϵ = f θ ( x ^ T , T ) \hat{\mathbf{x}}_\epsilon=f_\theta(\hat{\mathbf{x}}_T,T) x^ϵ=fθ(x^T,T)。这仅需要一次 Consistency Model 的前向推理过程。同时,我们也可以选择执行多次推理,交替进行去噪和噪声注入,来实现多步生成。
具体来说,多步采样的过程如以下算法 1 所示。首先使用 CM 根据 x ^ T \hat{\mathbf{x}}_T x^T 一步生成,初始化一个预测的数据样本 x \mathbf{x} x,然后将这个 x \mathbf{x} x 加噪成中间步 τ n \tau_n τn 的噪声图,然后再用 CM 对这一步的噪声图进行一步生成,得到新的预测数据样本 x \mathbf{x} x。然后不断重复交替进行加噪、去噪的过程共 N N N 次,得到最终 N N N 步的生成结果。

通过多步生成,我们可以提高提升生成结果的质量。这样,我们就能灵活地在采样速度和样本质量之间进行权衡。
这里有一个示意图,将 CM 多步采样的过程清楚地展示了出来。图片来源:Consistency is All You Need。

蒸馏训练 CM
我们首先介绍第一种训练 CM 的方法:对一个预训练的得分模型
s
ϕ
(
x
,
t
)
\mathbf{s_\phi}(\mathbf{x},t)
sϕ(x,t) 进行蒸馏。我们还是围绕公式 3 中的 empirical PF ODE 展开讨论,将时间区间
[
ϵ
,
T
]
[\epsilon,T]
[ϵ,T] 离散化为
N
−
1
N-1
N−1 个子区间,边界分别为
t
1
=
ϵ
<
t
2
<
⋯
<
t
N
=
T
t_1=\epsilon<t_2<\dots<t_N=T
t1=ϵ<t2<⋯<tN=T。在实现中,我们参考 EDM 中的公式来确定区间边界
t
i
=
(
ϵ
1
/
ρ
+
i
−
1
N
−
1
(
T
1
/
ρ
−
ϵ
1
−
ρ
)
)
ρ
t_i=(\epsilon^{1/\rho}+\frac{i-1}{N-1}(T^{1/\rho}-\epsilon^{1-\rho}))^\rho
ti=(ϵ1/ρ+N−1i−1(T1/ρ−ϵ1−ρ))ρ,其中
ρ
=
7
\rho=7
ρ=7。当
N
N
N 足够大时,我们就可以通过执行数值 ODE 求解器的一个离散步,来根据
x
t
n
+
1
\mathbf{x}_{t_{n+1}}
xtn+1 得到
x
t
n
\mathbf{x}_{t_n}
xtn 的精确估计值。我们记该估计值为
x
^
t
n
ϕ
\hat{\mathbf{x}}_{t_n}^\phi
x^tnϕ,具体定义为:
x
^
t
n
ϕ
:
=
x
t
n
+
1
+
(
t
n
−
t
n
+
1
)
Φ
(
x
t
n
+
1
,
t
n
+
1
;
ϕ
)
\hat{\mathbf{x}}_{t_n}^\phi:=\mathbf{x}_{t_{n+1}}+(t_n-t_{n+1})\Phi(\mathbf{x}_{t_{n+1}},t_{n+1};\phi)
x^tnϕ:=xtn+1+(tn−tn+1)Φ(xtn+1,tn+1;ϕ)
其中
Φ
(
…
;
ϕ
)
\Phi(\dots;\phi)
Φ(…;ϕ) 表示对 empirical PF ODE 执行一步 ODE 求解器的更新方程。比如说当使用 Euler 求解器时,有
Φ
(
x
,
t
;
ϕ
)
=
−
t
s
ϕ
(
x
,
t
)
\Phi(\mathbf{x},t;\phi)=-t\mathbf{s_\phi}(\mathbf{x},t)
Φ(x,t;ϕ)=−tsϕ(x,t),对应于以下更新公式:
x
^
t
n
ϕ
:
=
x
t
n
+
1
−
(
t
n
−
t
n
+
1
)
t
n
+
1
s
ϕ
(
x
t
n
+
1
,
t
n
+
1
)
\hat{\mathbf{x}}_{t_n}^\phi:=\mathbf{x}_{t_{n+1}}-(t_n-t_{n+1})t_{n+1}\mathbf{s_\phi}(\mathbf{x}_{t_{n+1}},t_{n+1})
x^tnϕ:=xtn+1−(tn−tn+1)tn+1sϕ(xtn+1,tn+1)
简单起见,我们这里先只考虑单步的 ODE 求解器。这里其实就相当于是离散扩散模型根据
x
t
+
1
\mathbf{x}_{t+1}
xt+1 进行单步去噪得到上一时间步
x
t
\mathbf{x}_{t}
xt 的过程。
根据公式 2 PF ODE 与公式 1 SDE 之间的联系,我们可以通过先采样
x
∼
p
data
\mathbf{x}\sim p_\text{data}
x∼pdata,然后向
x
\mathbf{x}
x 中添加高斯噪声的方式,来采样出 ODE 轨迹。具体来说,给定一个数据样本
x
\mathbf{x}
x,根据 SDE 的转移密度
N
(
x
,
t
n
+
1
2
I
)
\mathcal{N}(\mathbf{x},t^2_{n+1}\mathbf{I})
N(x,tn+12I) 采样出
x
t
n
+
1
\mathbf{x}_{t_{n+1}}
xtn+1,然后使用 ODE 求解器的一步更新公式,计算出前一时刻的
x
^
t
n
ϕ
\hat{\mathbf{x}}_{t_n}^\phi
x^tnϕ,从而我们就能得到相邻时刻的数据点的 pair 对
(
x
^
t
n
ϕ
,
x
t
n
+
1
)
(\hat{\mathbf{x}}^\phi_{t_n},\mathbf{x}_{t_{n+1}})
(x^tnϕ,xtn+1)。然后,我们就可以以最小化这个相邻时间步 pair 对一致性输出的差异为训练目标,训练 CM。具体来说,通过蒸馏的方式训练 CM 的 consistency distillation 损失定义为:
L
C
D
N
(
θ
,
θ
−
;
ϕ
)
:
=
E
[
λ
(
t
n
)
d
(
f
θ
(
x
t
n
+
1
,
t
n
+
1
)
,
f
θ
−
(
x
^
t
n
ϕ
,
t
n
)
)
]
\mathcal{L}_{CD}^N(\theta,\theta^-;\phi):=\mathbb{E}[\lambda(t_n)d(f_\theta(\mathbf{x}_{t_{n+1}},t_{n+1}),f_{\theta^-}(\hat{\mathbf{x}}^\phi_{t_n},t_n))]
LCDN(θ,θ−;ϕ):=E[λ(tn)d(fθ(xtn+1,tn+1),fθ−(x^tnϕ,tn))]
这里的期望是关于
x
∼
p
data
,
n
∼
U
[
1
,
N
−
1
]
,
x
t
n
+
1
∼
N
(
x
;
t
n
+
1
2
I
)
\mathbf{x}\sim p_\text{data},n\sim\mathcal{U}[1,N-1],\mathbf{x}_{t_{n+1}}\sim\mathcal{N}(\mathbf{x};t^2_{n+1}\mathbf{I})
x∼pdata,n∼U[1,N−1],xtn+1∼N(x;tn+12I)。其中
λ
(
⋅
)
∈
R
+
\lambda(\cdot)\in\mathbb{R}^+
λ(⋅)∈R+ 是正值加权函数,一般取恒等加权函数
λ
(
t
n
)
=
1
\lambda(t_n)=1
λ(tn)=1 即可。,
d
(
⋅
,
⋅
)
d(\cdot,\cdot)
d(⋅,⋅) 是某种距离度量,文中实验了 L1、L2 和 LPIPS 三种距离。使用随机梯度下降优化 CM 的参数
θ
\theta
θ,并使用 EMA 来更新参数
θ
−
\theta^-
θ−,EMA 更新公式为:
θ
−
←
stopgrad
(
μ
θ
−
+
(
1
−
μ
)
θ
)
\theta^-\leftarrow\text{stopgrad}(\mu\theta^-+(1-\mu)\theta)
θ−←stopgrad(μθ−+(1−μ)θ)
其中
θ
−
\theta^-
θ− 是优化过程中滑动平均值的上一步,
0
≤
μ
<
1
0\le\mu<1
0≤μ<1。
原生训练 CM
原生训练 CM 时,我们不需要预训练的扩散模型
s
ϕ
(
x
,
t
)
\mathbf{s_\phi}(\mathbf{x},t)
sϕ(x,t) 来估计分布得分
∇
log
p
t
(
x
t
)
\nabla\log p_t(\mathbf{x}_t)
∇logpt(xt) 了。此时,我们可以根据
x
\mathbf{x}
x 和
x
t
\mathbf{x}_t
xt 来估计得分:
∇
log
p
t
(
x
t
)
=
−
E
[
x
t
−
x
t
2
∣
x
t
]
\nabla\log p_t(\mathbf{x}_t)=-\mathbb{E}[\frac{\mathbf{x}_t-\mathbf{x}}{t^2}|\mathbf{x}_t]
∇logpt(xt)=−E[t2xt−x∣xt]
其中
x
∼
p
data
\mathbf{x}\sim p_\text{data}
x∼pdata,
x
t
∼
N
(
x
;
t
2
I
)
\mathbf{x}_t\sim\mathcal{N}(\mathbf{x};t^2\mathbf{I})
xt∼N(x;t2I)。当我们使用 Euler ODE 求解器,在
N
→
∞
N\rightarrow\infty
N→∞ 时,这个无偏估计足以替代上述蒸馏训练 CM 时的预训练扩散模型,原文定理 2 给出了证明。
consistency training 的目标函数定义为:
L
(
θ
,
θ
−
)
:
=
E
[
λ
(
t
n
)
d
(
f
θ
(
x
+
t
n
+
1
z
,
t
n
+
1
)
,
f
θ
−
(
x
+
t
n
z
,
t
n
)
)
]
\mathcal{L}(\theta,\theta^-):=\mathbb{E}[\lambda(t_n)d(f_\theta(\mathbf{x}+t_{n+1}\mathbf{z},t_{n+1}),f_{\theta^-}(\mathbf{x}+t_n\mathbf{z},t_n))]
L(θ,θ−):=E[λ(tn)d(fθ(x+tn+1z,tn+1),fθ−(x+tnz,tn))]
注意这里的损失
L
(
θ
,
θ
−
)
\mathcal{L}(\theta,\theta^-)
L(θ,θ−) 仅与 CM 参数
θ
,
θ
−
\theta,\theta^-
θ,θ− 有关,与预训练扩散模型参数
ϕ
\phi
ϕ 无关。
总结
本文首先回顾了连续时间 SDE/ODE 扩散模型相关的基础知识,并选定了 EDM 的形式化。然后介绍 Consistency Models,考虑一个一致性函数 f f f,其可以从任意时刻一步映射到一致的结果 x ϵ \mathbf{x}_\epsilon xϵ。训练一个神经网络 f θ f_\theta fθ 来拟合这个 f f f,即为 CM。CM 可以从纯噪声一步采样得到生成样本,也可以多步采样来均衡生成质量和采样速度。CM 的训练模式有蒸馏和原生训练两种,核心都是构建相邻时刻数据点 pair 对,然后最小化 CM f θ f_\theta fθ 对二者输出值的差异,生成一致性的结果。区别在于,蒸馏训练模式使用预训练的扩散模型来得到相邻时刻的 pair 对,而原生训练模式则直接通过扩散模型前向加噪公式来进行无偏估计。