摘要:
此博文是通过翻阅C++ Primer Plus中文第6版(2020),逐章学习记录笔记由此学习C++的基础特性和语法知识,有别于其它视频教学+代码+笔记的学习途径,更趋向传统的书籍+代码+笔记学习,Cpp第6版以C++11标准为主,学习C++基础编程绰绰有余,更高级的C++标准新特性大部分在基础阶段也用不到,反而一开始容易混淆,有需要学习C++编程的可参考此学习途径。
关键词: C++,学习笔记,C++ Primer Plus,零基础,学习途径
声明:
本文作者原创,转载请附上文章出处与本文链接。
文章目录
正文:
书籍:
《C++ Primer Plus 第6版中文版》是一本针对C++初学者的经典教材,全书共分为18章,内容涵盖了C++程序的运行方式、基本数据类型、复合数据类型、循环和关系表达式、分支语句和逻辑运算符、函数重载和函数模板、内存模型和名称空间、类的设计和使用、多态、虚函数、动态内存分配、继承、代码重用、友元、异常处理技术、string类和标准模板库、输入/输出以及C++11新增功能等内容。这本书的特点是内容详尽、讲解细致,适合初学者逐步学习和掌握C++语言,也有电子版方便阅读。

学习笔记:
笔记记录的是章节学习过程中每章的一些重点难点和拓展的地方,想到哪里记到哪里,也有一些部分写画进了实体书籍内,因为学习C++之前已经有一定的C基础,笔记基础部分较糙,随笔也是有和C进行类比对比,随意参考即可,按自己节奏走,不影响自学C++,书籍本身适合零基础学习。
一些乱记:
学习过程中拓展的重点或比较容易混淆的知识点
STD(标准库)、STL(标准模板库)。
多维数组的地址计算:
以三维数组为基础,往后递推。
有数组A[m][n][p],计算A[i][j][k]的地址。
行优先:先把右边的填满。
偏移量为inp+j*p+k
列优先:先把左边的填满。偏移量为knm+j*m+i
提醒:(更大)array[3][4]+5与array[3][4][5]不一样。
array[3][4]+5 == array[3][4] + 5*sizeof(datatype);
内存管理:
malloc(free)和new(delete)的区别:
本质:malloc/free是C/C++语言的标准库函数,new/delete是C++的运算符。对于用户自定义的对象而言,用maloc/free无法满足动态管理对象的要求。对象在创建的同时要自动执行构造函数,对象在消亡之前要自动执行析构函数。由于malloc/free是库函数而不是运算符,不在编译器控制权限之内,不能够把执行构造函数和析构函数的任务强加于malloc/free。因此C++需要一个能完成动态内存分配和初始化工作的运算符new,以及一个能完成清理与释放内存工作的运算符delete。
用法上:
int *p1 = (int *)malloc(sizeof(int) * length);
int *p2 = new int[length]; //delete [] p2;
某方面:
- 1、new自动计算需要分配的空间,而malloc需要手工计算字节数。
- 2、new是类型安全的,而malloc不是,比如:
int* p = new float[2]; // 编译时指出错误
int* p = malloc(2*sizeof(float)); // 编译时无法指出错误 - 3、operator new对应于malloc,但operator new可以重载,可以自定义内存分配策略,甚至不做内存分配,甚至分配到非内存设备上。而malloc无能为力。
- 4、new将调用constructor,而malloc不能;delete将调用destructor,而free不能。
- 5、malloc/free要库文件支持,new/delete则不要。
客户/服务器模型:
客户:是使用类的程序,只能通过公有方式定义的接口使用服务器。职责:了解这些接口。
服务器:类声明(包括类方法)构成了服务器,它是程序可使用的资源。职责:确保服务器更具接口能可靠准确地执行。
C的struct和C++的struct:
C语言中:struct是用户自定义数据类型(UDT);C++中struct是抽象数据类型(ADT)
C++语言将struct当成类来处理的,所以C++的struct可以包含C++类的所有东西,例如构造函数,析构函数,友元等,C++的struct和C++ class 唯一不同就是struct成员默认的是public, C++默认private。
这里不要记混了,C++中的struct为了和C语言兼容,所以默认也是public 的。
而C语言struct不是类,不可以有函数,也不能使用类的特征例如public等关键字 ,也不可以有static关键字,说到底它只是一些变量的集合体,可以封装数据却不可以隐藏数据。
冒号初始化:成员初始化列表
有的数据成员需要在构造函数调入之后、函数体执行之前,就进行初始化,比如引用数据成员、常量数据成员(const)(static const不行)、对象数据成员。
冒号初始化是在给数据成员分配内存空间时、进入函数体之前就进行初始化,也就是说,初始化这个数据成员时函数体还未执行。
对于在函数体内的初始化,是在所有的数据成员被分配好内存空间后才进行的。
注意:只能用于构造函数。
class Queun
{
public:
Queun(int _size):size(_size) //可正常编译
{
…;
//size = _size;会报错
}
private:
…;
const int size;
};
多个项目初始化时,这些项目被初始化的顺序为它们被声明的顺序,而不是它们再初始化列表中的排列顺序。
第2章:开始学C++
输入/输出:
// 输入:
String str;
// cin使用空白(空格、制表符和换行符)来确定字符串的结束位置。
Cin >> str;
// 从键盘输入字符串保存在str中
// 输出:
Cout << “hello!” << endl;//发送给cout的是字符串第一个字符大的地址
// 输出字符串并换行
命名空间:
C++ 标准的命名空间为 std ,包含很多标准的定义
:: 为访问修饰符
正常命名空间使用作用:
使用命名空间的目的是对标识符的名称进行本地化,以避免命名冲突。在C++中,变量、函数和类都是大量存在的。如果没有命名空间,这些变量、函数、类的名称将都存在于全局命名空间中,会导致很多冲突。
#include <iostream>
using namespace std;
namespace LabNameSpace
{
int i;
char* p = NULL;
class Student
{
...
};
}
int main()
{
LabNameSpace::i = 100;
LabNameSpace::j = &i;
LabNameSpace::Student st();
st.函数接口;
return 0;
}
函数:
和C基本一样
第3章:处理数据
和C语言共通的数据类型(int、char、float、(long)double等);
特殊头文件:(各种宏)
limits:定义了整型常量限制。
climits:定义了符号整型限制。
cfloat:定义了浮点型限制。
C++的特殊变量初始化:
int emus{7};
int rheas = {14};
不同进制显示方法:
iostream提供了控制符:dec(十)、hex(十六)、oct(八)等。
例如:cout << hex;
成员函数:
cin.get(ch);
cout.put(ch); // 现今少用,历史问题所以需要这个
转义序列的编码:
\v(类似\n)、\b(退格)、\r(回车)、\a(振铃,没啥用)等。
宽字符(每个字符存储在两个字节的内存单元中)类型、宽整型类型
wchar_t、wint_t || char16_t和char32_t
C++区别于C的数据类型:
bool、string
const限定符:
相同点:作用相同;
不同点:C变常变量、C++变常量。
表示浮点值的方法:
3.45E6 == 3.45*1000000;(E表示法)
cout.setf(ios_base::fixed, ios_base::floatfield);
这种调用迫使输出使用定点表示法。
数据类型转换:自动/强制转换。
第4章:复合类型
和C一样的数组。(除了有个不大一样的初始化:int array[10] {…};)
cin类的成员函数:
cin.getline()/get();
类成员函数的拼接使用:cin.get(name(数组), 32).get();//get()捕获\n
输入空行:cin.clear();
输入字符串比空间长:把余下的字符留在输入队列里。
// 注意:
(cin >> num).get(); //防止\n干扰下面的输入
cin.get(array, sizeof(array));
String是个类。(C环境下,还是用字符数组)
string类赋值、拼接和附加比字符数组更加方便。
str1 = str2;
str3 = str1 + str2;
str1 += str2;
// 可以用:getline(cin, str1);//用户输入
原始字符串R:
在原始字符串中,字符表示的就是自己。
cout << R"(wdsw "kind" \n "\n" dnmd)" << "\n";
// \n不表示换行符就是\n,
和C不大一样的结构体(位域、柔性结构)、共用体、枚举。
C++的结构体:C++语言将struct当成类来处理的。
使用共用体实例:管理一个小商品目录,其中一些商品的ID为整数,而另一些ID为字符串。(这种情况适用共用体)
区别:
不同的是C++结构体还可以有成员函数,不过通常在类中实现,并不常用。
C++结构体、共用体自带typedef可以不用+struct/enum。
C++枚举变量有强限制不允许赋值除枚举常量外的值,C没有限制枚举数据类型就和int一样。因此枚举变量方面延伸出许多不同。
C++枚举的取值范围:
可强制转换赋给枚举变量在取值范围里的值(Week today = (Week)8)。
OOP强调的是在运行阶段(而不是编译阶段)进行决策。
和C一样的指针。
(int* 写法是C++传出来的)
C++的动态内存用(堆)new(delete):
int *pn = new int;
delete pn;
// deleted的关键在于用于new的地址。delete可以用于NULL指针,
new创建动态数组:
(和C语言数组一样使用;不能用sizeof获取数组大小)
int *parr = new int [10];
delete [] parr;
区别:C数组,数组名不能修改。but C++new数组(实际是指针)可以修改(±)。
拓展:short tell[10];
tell == &tell;(but 数值相同;概念不同,tell+1地址值加2字节,&tell+1地址值加10字节。)
new创建动态结构:
(也适用于类)(类似C的结构指针申请动态内存)
new和delete可以分开放置(不同函数,返回地址delete就行),还是需要一一对应(数组对数组,指针对指针)。
C++根据分配内存的方法有四种管理数据内存的方式:
- 自动存储
- 静态存储
- 动态存储(手动)
- 以及新增的线程存储。(跟C作用域、生存区差不多,更加细分)
C++数组的替代品(类),都是STL库里的:
vector(动态数组的替代品)
array(定长数组的替代品)
vector:类似string类,也是一种动态数组。(比数组效率稍低)
#include <vector>
using namespace std;
// T:vector<typeNme> vt(n_elem);
array:和数组基本一样,但更安全、方便。
#include <array>
using namespace std;
// T:array<typeName, n_elem> arr;
容器比数组更安全方便的地方:
vector、array类都有at()、begin()、end()等成员函数,预防数组超界访问,不过运行时间会变长。
第5章:循环和关系表达式
和C一样的关键字:for、while、typedef、do while、
一样的运算符、复合运算符:++、–、+=、-=、……
语法技巧:
逗号运算符(优先级最低):i++, j–;//两表达式合并为一表达式
两个特性:先计算第一个表达式,然后计算第二个表达式。
一样的关系运算符:<、<=、==、>、>=、!=、
C++不同(特有的)
-
基于范围的for循环:
int arr[5] = {0,1,2.3,4}; for(int x : arr)//遍历打印数组 cout << x <<"\n"; -
函数重载:cin.get(); cin.get(ch); cin.get(parr, size);
文件尾(EOF)
(前提:如果输入来自文件)检测文件尾(EOF):判断输入结束的方式
(window系统CTRL+z 可键盘模拟EOF)
while(cin.fail()==false)
//检测到EOF返回true。
设置EOF后,cin不能再次调用;可以用cin.clear();可能清除EOF。
int ch;
while((ch = cin.get()) != EOF)//EOF==-1。
和C语言一样用嵌套循环处理二维数组。
第6章:分支语句和逻辑运算符
和C一样的分支语句:if、if else、if else if else、switch、
一样的逻辑运算符:&&、||、!、
一样的条件运算符:?:(三目运算符) 、
一样的跳出语句:break、continue、
字符函数库cctype:#include
库内函数众多不过多阐述,主要功能为判断字符数据的种类,
例如:isalpha();//判断参数是否为字母,是返回true
isdigit();//判断参数是否为数字(0~9)
用cin>>arr[i]做判断条件,返回false还要继续输入的程序注意事项(eg:6.14)
while( !(cin >> arr[i]) ) //0、错误输入字符
{
cin.clear(); //1、重置cin以接收新的输入
while( cin.get() != '\n') //2、删除错误输入
continue;
cout << "重新输入" << "\n"; //3、提示用户再输入
}
简单文件输入、输出(I/O):感觉并不好用
输入(写入):
#include <fstream> // 1、包含头文件<fstream>
ofstream outFile, fout; // 2、创建ofstream对象
outFile.open("fish.txt"); // 3、将对象与文件或数组关联起来
char filename[50]; //如果文件不存在则创建;存在则默认丢弃其内容
cin >> filename;
fout.open(filename);
// 使用方式和cout一样
double wt = 125.8;
outFile << wt; //4、像使用cout一样使用
fout << "1234567890" << endl;
outFile.close(); //5、记得需要close
输出(读取):
#include <fstream> //1、包含头文件<fstream>
ifstream inFile, fin; //2、创建ifstream对象
inFile.open("fish.txt"); //3、将对象与文件或数组关联起来
if(!inFile.is_open()) return ; //如果文件不存在则失败,用inFile.is_open()检查
char filename[50];
fin.open(filename);
//使用方式和cin一样
double wt;
inFile >> wt; //4、像使用cin一样使用
char line[64];
fin.getline(line, 64);
inFile.close(); //5、记得需要close
第7章:函数——C+的编程模块
和C一样的函数基本知识:定义函数、函数调用、函数参数(按值按址)、函数数组参数、函数结构体参数、传C-风格字符串(数组、字符串、指针)、函数递归调用。
和C一样的const修饰指针、函数指针(数组)。
数组作参:
传统C/C++方法是将指向数组起始处的指针作为一个参数,将数组长度作为第二个参数;另一种传参数方式为指定元素区间传参:数组起始地址作一个参数,数组尾部地址作一个参数。
int arr[20];
fun(arr, arr+20);// 函数内部定义对指针++。
二维数组作参数的一种方法:
void fun(int arr[][4], int n);
int arr[3][4];
fun(arr, 3);
函数和string对象做参数:
string对象与C-风格字符串的用途几乎相同,但是string对象与结构体更相似。
第8章:函数探幽
和C一样的inline关键字,内联函数。
引用&:
如果你有一个变量是用于指向另一个对象,但是它可能为空,这时你应该使用指针;如果变量总是指向一个对象,你的设计不允许变量为空,这时你应该使用引用。
指针:(和C一样)(指针阔以为NULL)
Char* p = NULL;
引用:(C++有)(引用不能为NULL)
// 引用不占内存
Int i=1;
Int& r=i;
Int x=r; // x == 1;
在 C++ 中,引用的主要功能是作为函数的参数或返回值,也非常适用于结构和类。
用单个&实现的引用为左值引用;用&&实现的引用为右值引用,有特殊作用;
返回引用时需要注意的问题:
返回引用时最重要的一点是,应避免返回函数终止时不再存在的内存单元应用。例如错误代码:
const string &fun(string &s1, const string &s2)
{
string temp;
temp = s2+s1+s2;
return temp; //temp已释放,程序会奔溃。
}
//解决:用new(delete)、或用行参做返回值;
(浅)继承:
基类指针、引用可以指向派生类的对象。反过来不行。因为指针、引用包含的数据成员种类以基类为主。
默认参数:
void fun(int a, char *arr = "1234", double x = 0.123);
// 注意:定义中形参只要开始默认,剩下的形参就都需要默认。
**函数重载:**overload是重载,一般是在一个类实现若干重载的方法,这些方法的名称相同而参数形式不同。但是不能靠返回类型来判断。
函数模板:函数模板也可以重载和常规的一样
函数模板是C++新增的一种性质,它允许只定义一次函数的实现,即可使用不同类型的参数来调用该函数。这样做可以减小代码的书写的复杂度,同时也便于修改。但是,在代码中包含函数模板本身并不会生成函数定义,它只是一个用于生成函数定义的方案。编译器使用模板为特定类型生成函数定义时,得到的是模板实例(instantiation):
template <typename T>
T max(const T a, const T b)
{
return (a>b ? a : b);
}
...
// 这样用:
// int
int a = 1, b = 2;
max(a, b);
// float
float c = 1.0f, d = 2.0f;
max(c, d);
模板函数局限性:
函数定义了赋值a=b,那么T就不能为数组
定义了逻辑运算符a>b,T就不能定义为结构体
a*b,T不能为数组、指针和结构。
解决:另外正常定义一个对应的函数就行,类似重载,优先匹配非模板函数。
函数模板相关C++11特性:关键字decltype、新语法函数声明auto … ->typename。两个结合起来可:
template <typename T1, typename T2>
auto fun(T1 x, T2 y)->decltype(x+y) //解决第0个问题
{
decltype(x+y) count = x+y; //解决第1个问题
return count;
}
第9章:内存模型和名称空间
和C一样的.cpp、.c、.h和头文件内的#ifndef、#define、#endif、
和C一定程度一样的生存期、作用域和链接属性、
和C一样的关键字static的两种用法(修饰全局、局部)、extern、
和C一样的关键字(cv-限定符)const、volatile、
和C一样的函数链接属性、
C++11关键字constexpr可以在编译时获得复杂的常量表达式。//少用
C++11关键字auto从说明符变做用于自动类型推断
C++的存储说明符:
auto(C++11变更)、register、static、extern、thread_local、mutable:
- thread_local:可与static、extern结合使用,修饰变量的持续性与其所属线程的持续性相同(生存期)。
- mutable:可修饰const变量,使之可修改 //感觉鸡肋
注意C++中const修饰全局变量时,默认为内部链接属性;
需要外部使用用extern关键字修饰,但只能有一个文件初始化。
new运算符大括号列表初始化:
C++11可初始化常规结构体、数组等
int *pin = new int {6}; //{6}==(6) //*p = 6;
int *pstr = new int [4] {0,1,2,3};
new失败不会返回空指针,而是引发异常std::bad_alloc.
int *p=new int [40]; //==> int *p = new int(sizeof(int)*40);
定位new运算符:
指定使用的内存位置,因为这种方式正常不会申请到堆地址,所以不能用delete。要使用定位new 运算符,首先要#include ,指定内存地址就可以。
#include <new>
char buffer[1024];
…
void main(void)
{
int *p=new (buffer+16*sizeof(char)) int[32];
}// **多个对象申请同个缓冲区**,要偏移字节申请内存,不然会覆盖。
名称空间,第2章有了
第10章:对象和类
类是一种将抽象转换为用户定义类型的C++工具。
封装:
.c和.h //类的声明(数据、函数等)放在.h;具体实现定义放在.cpp中
实现类成员函数:
使用域解析运算符(::)(类作用域)来标识函数所属的类:
void Student::show();
Student其它成员函数可以直接使用show()函数,不必Student::show(),因为属于同一个类。
内联函数:
在类声明中定义的短小函数作为内联函数。(或者用inline限定符)
类里的属性:
- private:
私有数据只能由该类内部的成员函数访问,该类的继承类是无法访问私有数据的,但可通过基类成员函数访问基类私有数据。 - protected:
类型的数据在派生类中也可以访问,但在外部是无法访问的。
class Student
{
public:
//函数可在类里声明类外定义
Student();//构造函数(实例化时最先自动运行。构造函数可用于为某些成员变量设置初始值)
~Student();//析构函数(对象消亡时,自动被调用,用来释放对象占用的空间)
protected:
private:
};
Student::Student()
{
}
Student::~Student()
{
}
创建对象:
(类也算一种特殊的数据类型,和结构体等类似)
Student stu1,stu2; // 声明类变量,也可用new;
所创建的每个新对象都有自己的存储空间,用于存储其内部变量和类成员(存储于不同内存块);但同一个类的所有对象共享同一组类方法(调用同一个方法,执行同一个代码块)。
通常数据成员被放在私有部分中(数据隐藏),成员函数被放在公有部分(公有接口)。
类的构造和析构:更细的看第12章的特殊成员函数
const成员函数:确保函数不会修改调用对象内的成员变量
声明(.h):void show() const;
定义(.cpp):void Student::show() const;
函数才能用于const Student stu对象。
如果想要在常函数中对成员变量进行修改,可以在成员变量前加上 mutable 关键字进行修饰;
C++的this指针:
所有的类方法都将this指针设置为指向调用它的对象的地址。
this是对象的地址;对象本身是*this。
注意:静态成员函数并不属于某一个对象,它与任何对象都无关,因此静态成员函数没有this 指针。
对象数组:
Stock stocks[4] =
{
Stock(),
Stock(“name”, num, data),
Stock()
}
类作用域:
(C++引入的新作用域:命名空间,类和对象的作用域)
在类中定义的名称(如类数据成员名和类成员函数名)的作用域都为整个类。
因此,可以在不同类中使用相同的类成员名而不会引起冲突。
在类中定义常量的方法:
-
0、定义枚举常量。
-
1、用static、const关键字。
static const int Months = 12; // 注意:不能单纯用const关键字。
C++新型的作用域内枚举:
// 报错:
enum egg {Small, Jumbo};
enum t_shirt {Small, Large};
// 正常: 作用域变为类作用域 把class代替为struct也ok
enum class egg {Small, Jumbo};
enum class t_shirt {Small, Large};
枚举底层类型必须为整型,可进行显示类型转换:
enum class : short egg {Small, Jumbo};(改枚举底层类型为short)
抽象数据类型:
用类实现栈、对、链表、图等数据结构。
第11章:使用类
运算符重载:
重载运算符,需要使用运算符函数的特殊函数形式:operator+”运算符”。
两个相同类对象相加赋值给另一个相同类对象:
dist = sid+sara; // => dist = sid.operator+(sara);
// 看着好看,实现原理感觉和函数调用差不多。
count = s1+s2+s3 ;
=> count = s1.operator+(s2+s3);
=> count = s1.operator+(s2.operator+(s3)); //语句合法
除了
类属关系运算符"."
成员指针运算符".*"
作用域运算符"::"
sizeof运算符和三目运算符"?:"
和一些特殊运算符(正常都不会想去重载)以外,
C++中的其它运算符都可以重载。但是=、()、[]、->这四个不能重载为类的友元函数。
友元函数://友元类在15章
在C++中友元函数是独立于当前类的外部函数,一个友元函数可以同时定义为两个类的友元函数,友元函数既可以在类的内部,也可以在类的外部定义;在外部定义友元函数时,不必加关键字friend;友元函数有权访问类的所有私有(private)成员和保护(protected)成员。
如果要声明函数为一个类的友元,需要在类定义中该函数原型前使用关键字 friend。
class Box
{
......
friend void printWidth( Box& box );
}
Void printWidth(Box& box);
https://www.runoob.com/cplusplus/cpp-friend-functions.html
友元函数与重载的结合运用:
重载"<<"运算符:
对一个类我们想:cout << 类对象,而不是类对象.show时,就应该运用友元与重载;友元确保cout是第一个操作数,重载确保不会变成左移运算符。
class Time
{
public:
Time(int _h=0, int _m=0, int _s=0)
{
this->h = _h;
this->m = _m;
this->s = _s;
}
~Time()
{
std::cout << "end" << std::endl;
}
// 友元重载"<<"运算符
friend std::ostream &operator<<(std::ostream &_os, const Time &_t);
private:
int h;
int m;
int s;
};
std::ostream &operator<<(std::ostream &_os, const Time &_t)
{
_os << _t.h<<":" << _t.m<<":" << _t.s;
return _os; //解决main函数内的多次cout的问题
}
int main(void)
{
Time t(11,10,18);
std::cout << "Time:" << t << "啊对对对\n";//can do
return 0;
}
类的自动转换:类型不安全
C++会自动转换兼容的类型,在无法自动转换时,可以使用强制类型转换。
类型转换作用于类:
C++中一个参数的构造函数(考虑默认函数的情况),承担了两个角色。
一个是构造;一个是默认且隐含的类型转换操作符。
// 构造函数:
Time(int _h, int _m=0, int _s=0);
……;
Time t(14);// int隐式转换为Time类型。
为了避免这种问题可以将类的构造函数声明为
explicit:explicit Time(int _h, int _m=0, int _s=0);
转换函数:
要将类对象转换为其它类型,必须定义转换函数,指出如何进行这种转换。转换函数必须是成员函数。注意:转换函数没有返回类型、没有参数,但必须返回转换后的值。
// (定义)(类名)
Time::operator double()
{
……;
return num; // num 为 double类型
}
// 调用:
Time t(10,30,40);
double count = (double)t;
// 扩展:cout输出浮点数后两位
#include <iomanip>
std::cout << std::fixed << std::setprecision(2) << t_num << "\n" ;
第12章:类和动态内存分配
类的静态成员:
无论创建了多少对象,程序都只创建一个静态类变量副本,也就是说,类的所有对象共享同一个静态成员。注意:不能在类声明中初始化静态成员变量,因为静态类成员是单独存储的,不是类的成员。
在类外初始化:(类型) (类名)::(变量名)=…;
例外情况是:1、const修饰;2、枚举;都是常量。
特殊成员函数:C++11如果没有定义的函数,类会生成的默认成员函数
默认构造函数、默认析构函数、拷贝构造函数、赋值运算符重载、&操作符重载。
C++11新增:移动构造函数、移动赋值运算符。
默认构造函数:
构造函数是一个特殊的成员函数,名字与类名相同,创建类类型对象时由编译器自动调用,保证每个数据成员都有一个合适的初始值,并且在对象的生命周期内只调用一次。
特点:
- 函数名与类型相同。
- 没有返回值(void都不行)。
- 对象实例化时编译器自动调用对应的构造函数。
- 构造函数可以重载。
- 无参的构造函数和全缺省的构造函数都称为默认构造函数,并且默认构造函数只能有一个。
- 创建类类型对象时,由编译器自动调用,并且在对象的生命周期内只调用一次。
- 有初始化列表(可带可不带)Animal(): a(0),b(8.8){}//就是初始化赋值
- 如果类中没有显式定义构造函数,编译器会自动生成一个无参的构造函数
不能被const修饰//构造函数就是为了修改变量的 - 没有this指针,因为构造函数是创建对象的,都没有对象哪来的this指针
默认析构函数:
与构造函数功能相反,析构函数不是完成对象的销毁,局部对象销毁的工作是由编译器完成的,而对象在销毁时,自动调用析构函数,完成类的一些资源清理工作。
特点:
- 析构函数名是在类名前加上~
- 没有参数,没有返回值、
- 一个类有且只有一个析构函数//不存在重载
- 如果显式没有定义析造函数,则编译器自动生成一个析造函数
- 对象生命周期结束后,编译器自动调用析构函数
- 析构函数不是销毁对象,而是完成对象资源的清理工作//突出作用
- 如果类中涉及资源的管理,析构函数一定要显式给出
- 后构造的对象先释放
- 有this指针
拷贝构造函数:
顾名思义,就是创建一个和原对象一模一样的对象,比如双胞胎。
拷贝构造函数:只有单个形参,该形参是对本类类型对象的引用(一般常用const修饰),已经存在的类型对象创建新对象时由编译器自动调用。
特点:
- 只有一个形参
- 拷贝构造函数是构造函数的一种重载形式
- 若显示未定义,系统会默认生成拷贝构造函数(浅拷贝)
Date d1(2108,12,12); - 涉及资源管理的问题,一定要显示定义拷贝构造函数
Date d2(d1);//否则调用析构函数会出问题 - 拷贝构造函数的参数必须使用引用,如果使用传值会无穷递归调用
Date(const Date& d)//如果传值会一直创建临时对象。调用拷贝构造函数 - 编译器自己生成的拷贝构造函数是浅拷贝的方式,也叫值拷贝。
浅拷贝:
按内存存储字节序完成拷贝
通俗易懂的说就是,你给我什么东西,我就拷贝什么,你给我地址,我就拷贝地址
拷贝构造函数可以连续赋值
Date d1(2108,12,12);
Date d2;
Date d3;
d3 = d2 = d1;
深拷贝:
如果要对地址进行拷贝并且有new/delete等操作,就需要进行深拷贝,防止二次释放地址(2次delete)
深拷贝可以用拷贝构造函数 或 赋值运算符的重载实现。
第一种:拷贝构造函数深拷贝
STRING( const STRING& s ):_str(NULL)//冒号初始化(构造函数专用)
{
// 调用了构造函数,完成了空间的开辟以及值的拷贝
STRING tmp(s._str);
//交换tmp和目标拷贝对象所指向的内容
swap(this->_str, tmp._str);
}
第二种:=赋值运算符深拷贝
STRING& operator=(const STRING& s)
{
//不让自己给自己赋值
if ( this != &s ){
//调用构造函数完成空间的开辟以及赋值工作
STRING tmp(s._str);
//交换tmp和目标拷贝对象所指向的内容
swap(this->_str, tmp._str);
}
return *this;
}
赋值运算符重载:
https://blog.csdn.net/liitdar/article/details/80656156
这里介绍 =(赋值)运算符的重载。
operator是c++的关键字,专门用于定义重载运算符的函数。operator =就是函数名,表示对运算符=重载。
特点:
-
参数类型最好是引用,可以提高效率//&
-
检测是否存在自己给自己加赋值的情况
-
一个类中如果显式没有给出赋值运算符的重载,编译器会自己生成,同样地,生成的也是按照浅拷贝的方式进行赋值
ClassA obj1; obj1.a = 1; obj1.b = 2; obj1.c = 3; ClassA obj2; obj2 = obj1; -
至少要有一个自定义类型(类类型)的参数//有地址重用的,delete会出问题
ClassA& operator=(const ClassA& cls)
{
//避免自赋值
if(this != cls){
//避免内存泄漏
if(pl != NULL){
}
}
return *this;
}
&操作符重载:
一般情况下不用重新定义,编译器会默认生成。只有特殊情况下(想让别人获取到指定内容时)会重新定义。//一般情况下又会加const修饰
const Date* operator&()const
{
return this;
}
...
Date d;
d.operator&()->nub;
C++11关键字nullptr:更好的选择
nullptr是nullptr_t 类型的右值常量,专用于初始化空类型指针,nullptr_t 是C++新增的数据类型,可称为“指针空值类型”。可以这样说,nullptr只是该类型的一个实例对象。
char *str = nullptr;
//用NULL在多态上面会有调用问题。
资料:https://zhuanlan.zhihu.com/p/401919037
静态成员函数:
用关键字static、及类Student内public声明;
static int HowMany(……);
// 调用
int count = Student::HowMany();
注意:由于静态成员函数不与特定的对象相关联,因此只能使用静态数据成员。没有this指针。
包含类成员的类的逐成员复制:
class Magazine
{
private:
Student title;
string publisher;
…
};
Magazine m1(…);
Magazine m2 = m1;
默认的逐成员复制和赋值行为有一定的智能,会自主区分调用Student、string类中的复制构造、赋值。
如果Magazine定义了复制构造、赋值函数,则这些函数需要显示调用Student、string类中的复制构造、赋值。
返回值类型判定:
如果方法或函数要返回局部对象,则应返回对象,而不是指向对象的应用;
如果方法或函数要返回一个没有公有复制构造函数的类(如ostream类)的对象,它必须返回一个指向这种对象的引用。
动静对象:
静态对象:class c;
动态对象:class *c = new class;
new 类,就是创建类对象,调用类相对应的构造函数;delete 对象,就是调用相对应的析构函数。
定位new运算符用于类:
delete不能与定位new运算符配合使用,所以使用了定位运算符申请内存的类的对象,调用析构函数需要显式调用,(class)c->~class();
只要不是定位new运算符申请的内存,正常new都是在堆内申请的。
套中套:类中嵌套结构体和类
在类声明中声明的结构体、类或枚举被称为嵌套在类中,其作用域为整个类,
这种声明不会创建数据对象,而只是指定了可以在类中使用的类型。
如果是在类的私有部分声明,则只能在这个类使用被声明的类型;
如果是在类的公有部分声明,则可以在类外声明class::struct类型的变量。
好处:声明不会与同名全局声明或其它类同名声明冲突。
第13章:类继承
继承:(继承数据、继承方法)
首先,基类的私有成员是会被派生类继承的,但是不能被派生类访问;从物理上讲是复制过来了,在内存中确实有复制。但是从程序上看是被屏蔽了,不能直接调用。
其次,对于基类public类型的成员变量,无论是公有继承还是私有继承,都可以直接在派生类中定义的成员函数直接访问。
对于基类private类型的成员变量,无论是公有继承还是私有继承,在派生类中定义的成员函数都不能直接访问基类的私有成员,只能通过基类的public或protect成员函数访问。
派生类构造函数必须使用基类构造函数,并且还是成员初始化列表。不然就是使用基类的默认构造函数。
class Clock : public Time
{
class(string _str,int _h, int _m, int _s):Time(_h,_m,_s)
{
this->str = _str;
}
……;
};
创建派生类对象时,程序是先调用基类的构造函数,再调用派生类的构造函数,析构则相反。
基类指针、引用可以指向派生类对象、引用,但反过来不行。
一个用法://p499-13.10 (书内)
数组内可以包含多个类型(伪)
Base array[8];
array[1] = new Base (…);
array[0] = new BasePuls(…);
array[0] = new BasePulsPuls (…);
// 这种操作称为向上强制转换,向上强制转换是可传递的,也就是说,如果从BrassPuls派生出BrassPulsPuls类,则Base指针、引用可指向Base、BrassPuls、BrassPulsPuls类。
在派生类中调用基类的公有方法,标准是用作用域解析运算符调用。
Base::Show();
虚函数:关键字(virtual)
如果要在派生类中重新定义基类的方法,通常应将基类方法声明为虚的。为基类声明一个虚析构也是一种惯例。
声明虚函数是为了派生类对基类成员函数的覆盖(重写)
虚函数要求返回值,参数名,参数个数,函数类型都相同
未使用关键字(virtual)修饰函数时,基类、派生类对象具有同名函数时,调用哪个类型的函数以对象、指针、引用的数据类型为主。
//对象与指针、引用是区分开的,不能组合
BasePlus dot(…);
Base &ptr = dot;
ptr.fun(); //use Base
使用virtual修饰函数后,以对象所指向的数据类型为主。
BasePlus dot(…);
Base &ptr = dot;
ptr.fun(); // ( virtual) use BasePlus
在构造函数执行完以后虚函数表才能正确初始化,所以在构造函数中调用虚函数时此时虚函数表还没有被正确初始化,
调用的是本类的函数,即静态类型所对应的函数,同理在析构函数中也不能调用虚函数,因为此时虚函数表已经被销毁。
class Base
{
virtual Show();
};
class BasePuls : public Base
{
Show(); // == virtual Show();
// 方法在基类中被声明为虚后,在派生类中将自动成为虚方法,
// 在派生类中用virtual指出了也不错。
};
虚函数实现原理:虚函数表(vtbl)
基类对象包含一个自动添加隐藏的成员指针,该指针指向基类中所有虚函数的地址表(数组)(vtbl)。派生类对象也包含一个指向(new)独立地址表的指针,如果派生类提供了虚函数的新定义,则该虚函数表将保存新函数的地址;如果派生类没有重新定义虚函数,该vtbl将保存函数原始版本的地址。如果派生类定义了新的虚函数,则该函数的地址也将被添加到vtbl中。
调用虚函数时,程序将查看存储在对象中的vtbl地址,然后转向相应的函数地址表。
虚析构函数:
在C++中,析构函数的作用是:当一个对象被销毁时,调用析构函数对类对象和对象成员进行释放内存资源。
当我们定义一个指向派生类类型对象指针时,构造函数按照从基类到派生类的顺序被调用,但是当删除指向派生类的基类指针时,派生类的析构函数没有被调用,只是调用了基类的析构函数,此时派生类将会导致内存泄漏。
我们需要将基类的析构函数声明为虚函数,此时在调用析构函数的时候是根据ptr指向的具体类型来调用析构函数,此时会调用派生类的析构函数,再自动调用基类析构。
继承的多种特征:
1 重载overload (类就有的)
overload是重载,一般是在一个类实现若干重载的方法,这些方法的名称相同而参数形式不同。但是不能靠返回类型来判断。
重载需要注意:
- 位于同一个类中
- 函数的名字必须相同
- 形参列表不同
- 若一个重载版本的函数面前有virtual修饰,则表示他是虚函数,但他也是属于重载的一个版本
- 不同的构造函数(无参构造、有参构造、拷贝构造)是重载的应用
2 覆盖override
override是重写(覆盖)了一个方法,以实现不同的功能。一般用于子类在继承父类时,重写(覆盖)父类中的方法。函数特征相同,但是具体实现不同。
重写需要注意:
- 被重写的函数不能是static的,必须是virtual的
- 重写函数必须有相同的类型,名称和参数列表
- 重写函数的访问修饰符可以不同。尽管virtual是private的,派生类中重写改写为public、protect也是可以的
3 重定义redefining
派生类对基类的成员函数重新定义,即派生类定义了某个函数,该函数的名字与基类中函数名字一样。
重定义也叫做隐藏,子类重定义父类中有相同名称的非虚函数(参数可以不同)。如果一个类,存在和父类相同的函数,那么这个类将会覆盖其父类的方法,除非你在调用的时候,强制转换为父类类型,否则试图对子类和父类做类似重载的调用时不能成功的。
重定义需要注意:
- 不在同一个作用域(分别位于基类、派生类)
- 函数的名字必须相同
- 对函数的返回值、形参列表无要求
- 若派生类定义该函数与基类的成员函数完全一样(返回值、形参列表均相同),且基类的该函数为virtual,则属于派生类重写基类的虚函数
- 若重新定义了基类中的一个重载函数,则在派生类中,基类中该名字函数(即其他所有重载版本)都会被自动隐藏,包括同名的虚函数
4 多态性polymorphism
多态的概念比较复杂,一种不严谨的说法是:继承是子类使用父类的方法,而多态是父类使用子类的方法。
一般我们使用多态是为了避免在父类里大量重载引起代码臃肿且难于维护。
多态分为两类:静态多态性(静态联编)和动态多态性(动态联编),以前学过的函数重载和运算符重载实现的多态性属于静态多态性,在程序编译时系统就能决定调用哪个函数,因此静态多态性又称为编译时的多态性。静态多态性是通过函数的重载实现的。动态多态性是在程序运行过程中才动态地确定操作所针对的对象。它又称运行时的多态性。动态多态性是通过虚函数(重写)实现的。
class Base
{
private:
virtual void display() {cout<<"Base display()"<<endl;}
void say() {cout<<"Base say()"<<endl;}
public:
void exec() {display();say();}
void fun1(string a) {cout<<"Base fun1(string)"<<endl;]
void fun1(int a) {cout<<"Base fun1(int)"<<endl;}
//overload,两个fun1函数在Base类的内部被重载
};
class ChildA : public Base
{
public:
void display() {cout<<"ChildA display()"<<endl;}
//override,基类中的display为虚函数,故此处为重写(覆盖)
void fun1(int a,int b) {cout<<"ChildA fun1(int,int)"<<endl;}
//redefining,fun1函数在Base类中不为虚函数,故此处为重定义
void say() {cout<<"ChildA say()"<<endl;}//redefining
};
抽象类:做基类 命名后缀+ABC标识
但是当一个类中有一个或多个纯虚函数的时候,这个类就自动成为了抽象类,即不可以实例化抽象类,但是可以定义指针和引用。结合基类指针管理派生类对象使用。
例如:(圆(Circle)是椭圆(Ellipse)的一种,但又不能简单的圆继承椭圆,所以从两者中抽象出它们的共性作为基类)
用一个抽象基类(BaseEllipse)指针数组即可同时管理Circle和Ellipse对象。
继承和动态内存:
基类内有new,派生类内没new:则不需要对析构函数、复制构造函数、赋值运算符进行特殊操作。
基类内有new,派生类内也有new:
-
1、则派生类的析构会自动调用基类的析构函数;
-
2、派生类的复制构造函数需要:在初始化成员列表中调用基类的复制构造函数
hasDMA::hasDMA( const hasDMA &hs ) : baseDMA( hs ){ …… } -
3、派生类的赋值运算符需要:通过作用域解析运算符显式调用基类赋值运算符
hasDMA &hasDMA::operator=( const hasDMA &hs ) { baseDMA::operator=( hs ); ……; }
友元函数的继承:
派生类调用基类的友元函数( << ),需要强制类型转换:
hasDMA hs;
cout << ( cons baseDMA& )hs; // 派生类对象:hs
// 派生类友元( << )调用基类友元( << )也是同样方法。
第14章:C+中的代码重用
代码重用的方法:
继承、组合、类模板
模板类valarray:提供用于处理数值的算术支持
#include <iostream>
#include <valarray>
int main(void)
{
// valarray<type> name;
std::valarray<double> vlab = {1.3, 5.2, 13.14, 65.0, 1.0};
std::cout << vlab[3] << "\n";
std::cout << vlab.sum() << "\n";
std::cout << vlab.size() << "\n";
……;
return 0;
}
继承与组合是类与类之间的
在功能上来看,它们都是实现系统功能重用,代码复用的最常用的有效的设计技巧,都是在设计模式中的基础结构。
继承是在编译时刻静态定义的,即是静态复用,在编译后子类和父类的关系就已经确定了。而组合这是运用于复杂的设计,它们之间的关系是在运行时候才确定的,即在对对象没有创建运行前,整体类是不会知道自己将持有特定接口下的那个实现类。
继承:初始化列表以类名进行初始化;
组合:初始化列表以类对象名进行初始化;
多种继承:
| 特征 | 公有继承 | 保护继承 | 私有继承 |
|---|---|---|---|
| 公有成员变成 | 派生类的公有成员 | 派生类的保护成员 | 派生类的私有成员 |
| 保护成员变成 | 派生类的保护成员 | 派生类的保护成员 | 派生类的私有成员 |
| 私有成员变成 | 只能通过基类的接口 | 只能通过基类的接口 | 只能通过基类的接口 |
| 能否隐式向上转换 | 是 | 是 | 否 |
多重继承:MI (p551)
一些事务往往会拥有2个或2个以上事务的属性,所有有多重继承。
class SingingWaiter : public Waiter , public Singer
{
……;
};
多重继承也会有一些问题:
-
1、多重派生类从多个基类中继承同名的方法。(普通多重继承)
// 解决1:用作用域解析运算符来指派 SingingWaiter name(…); name.Waiter::Show(); // name.Singer::Show(); // 解决2:可在派生类中类中定义方法指派使用哪个基类方法(原理也差不多) void SingingWaiter::Show() { Singer::Show(); } // 但是这样忽略了Waiter::Show(); // 所以相对更好的解决方法是各个类用模块化设计:公开Set()、保护Get();//p563 -
2、 菱形多重继承需要虚基类,相对应的类的构造也要采用一种新格式(但是基本不会用到吧)
特殊菱形多继承会有几处需要注意的地方:
继承重名和1、一样解决。
其外不做特殊处理的话,派生类SingingWaiter会继承多个Worker类,所以需要对祖父类Worker进行虚修饰,虚基类(虚继承)。从虚基类的一个或多个实例派生而来的类将只继承了一个基类对象。将基类作为虚是要求程序完成额外计算的。Class Singer : virtual public Worker{…}; Class Waiter : public virtual Worker{…}; //都可 // 这样class SingingWaiter : public Waiter , public Singer {…};时就不会多次继承祖父Worker类了。
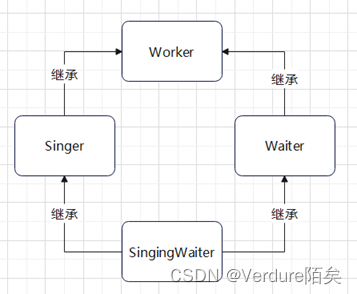
需要派生类构造函数、继承的同名方法做处理
用到虚基类Worker的派生类SingingWaiter的构造函数,需要显式的调用所需的基类构造函数:
SingingWaiter(…):Worker(…), Waiter(…), Singer(…){……};
// 注意:对于虚基类是需要这么做的、合法的;而非虚基类是非法的。
类模板:内的成员函数都是函数模板
资料:https://www.icode9.com/content-1-795084.html
类模板与函数模板的定义和使用类似。
有时,有两个或多个类,其功能是相同的,仅仅是数据类型不同。
//声明一个模板,虚拟类型名为numtype
template <typename(也可用class) numtype>
class Compare //类模板名为Compare
{
private :
numtype x,y;
public :
Compare(numtype a,numtype b)
{
x=a;y=b;
}
numtype max( )
{
return (x>y)?x:y;
}
numtype min( )
{
return (x<y)?x:y;
}
};
注意:上面列出的类模板中的成员函数是在类模板内定义的。如果改为在类模板外定义,不能用一般定义类成员函数的形式:
numtype Compare::max( ) {…} //不能这样定义类模板中的成员函数
而应当写成类模板的形式:
template <typename numtype>
numtype Compare<numtype>::max(void)
{
return (x>y)?x:y;
}
实例对象:
Compare cmp(4,7);//改为其它数据类型,例如。
Compare 整体作为一个类。
包含非类型参数模板:
template <typename Type, int n>……;
ArrayTP<double, 12> arr; //编译器将使用double替换Type,将12替换n
注意:
模板代码不能修改参数的址也不能使用参数的地址,例如:n++、&n是不允许。实例化模板时,用作表达式参数的值必须是常量表达式。用栈管理速度快。
缺点:
每种数组大小都将生成自己的模板(类声明)。
ArrayTP<double, 12> arr1;
ArrayTP<double, 13> arr2;
模板多功能性:
模板类可用作基类,也可用作组件类,还可用作其它模板的类型参数。
-
1、递归使用模板:
ArrayTP< ArrayTP< int, 5 >, 10 > name; // == int name[10][5]; // name是一个包含10个元素的数组,其中每个元素都是一个包含5个int元素的数组。 -
2、类模板的类型参数可以有一个或多个,每个类型前面都必须typename,如:
template <typename type1,typename type2> -
3、可以为类型参数提供默认值:
template <typename type1,typename type2 = int>…… // 如果省略type2的值,则编译器将int替换type2。
模板的具体化:
-
1、隐式实例化
编辑器在需要对象之前,不会生成类的声明ArrayTP<double, 30> *pt; //不会生成类声明 *pt = new ArrayTP<double, 30>; //生成类声明 -
2、显示实例化
template class ArrayTP<string, 15>; //生成ArrayTP<string, 15> 类声明 -
3、显示具体化(较实用)
显示具体化是特定类型的定义。相同模板因为不同参数类型需要不同的实现时,就需要对其特例化。比如>=<等运算符用于c-字符串需要替换成strcmp函数。当参数类型为<const char *, int>时,优先显示具体化模板。template <> class ArrayTP<const char *, int>{……}; -
4、部分具体化(鸡肋)
成员模板:在类声明中的类模板 //mabey有用
template <typename T>
class beta
{
public:
beta(T t, int i):q(t),n(i){}
private:
template <typename V>
class hold;
hold<T> q;
hold<int> n;
};
template <typename T>
template <typename V> //不能:template <typename T, typename V>
class beta<T>::hold //beta<T>::
{
private:
V val;
public:
hold(V v=0):val(v){}
};
将模板用作参数:
Tname是参数随便起;
蓝色的是类型。 p587(书)
template <template <typename T> class Tname>
class Clab{…};
模板类与友元
友元无参:friend void counts(); //成为模板所有实例化的友元
友元有参:
template <typename T>
class HasFriend
{
//和约束模板友元函数实习原理一样
friend void report(HasFriend<T> &);
};
约束模板友元函数
要使类的每一个具体化都获得与友元匹配的具体化。
// 先声明为模板函数:
template <typename T> void counts();
template <typename T> void report(T &);
// 然后,在模板类中声明为友元函数:
template <typename TT>
class HasFriendT
{
friend void counts<TT>();
// 编译器通过HasFriend<TT>判断是哪个实例化的友元,所以<>内可不需要内容
friend void report<>(HasFriend<TT> &);
};
template <typename T>
void counts(){…}
模板别名
一种用typedef关键字:
typedef std::array<int, 12> arri;
另一种使用模板提供一系类别名:
template <typename T>
using arrtype = std::array<T, 12>;
arrtype<double> arrd; // std::array<double, 12>;
arrtype<int> arri; // std::array<int, 12>;
第15章:友元、异常和其他
友元类:
当一个类B成为了另外一个类A的“朋友”时,那么类A的私有和保护的数据成员就可以被类B访问。我们就把类B叫做类A的友元。我们把类B设置成了类A的友元类,但是这并不会是类A成为类B的友元。两者之间不存在继承关系。这也就是说,友元类和原来那个类之间并没有什么继承关系,也不存在包含或者是被包含的关系(举例:电视机与遥控器)
声明友元类的方法其实很简单friend class B;
https://www.cnblogs.com/renzhuang/articles/6592024.html
class Animal
{
public:
friend class CatAnimal;
int a;
.......
private:
void lab();
};
class CatAnimal
{
public:
void Clab(Animal& b)
{
b.a=10;
b.lab();
}
};
友元成员函数:
和友元函数不同,并且需要注意两个问题
class Animal; // 问题1:类内包含Animal所以需要前向声明
class CatAnimal
{
public:
void Clab(Animal& b)
// erron:
/*{
b.a=10;
b.lab();
}*/
// 问题2:不能在类中内联定义,需要到Animal定义后定义该成员函数
// 因为Animal只是声明了还没定义,所以Animal相关的成员不能出现
};
class Animal
{
//少部分直接访问保护、私有成员的,就不需要定义友元类
friend void CatAnimal::Clab(Animal& b);
// 包含CatAnimal::Clab所以要在CatAnimal定义后定义。(问题一)
};
inline void CatAnimal::Clab(Animal& b) //一样类内内联定义
{
b.a=10;
b.lab();
}
// 友元关系:相互友元、共同的友元
嵌套类:
在另一个类中声明的类被称为嵌套类;和包含不同,不过挺像的。
template <typename Item> //模板中的嵌套
class Queue
{
// (private:)
class Node
{
public:
Item item;
Node *next;
Node(const Item &i):item(i),next(nullptr){}
};
};
// 使用Node构造需要通过两次作用域解析运算符完成:
Queue::Node::Node(…);
嵌套类、结构和枚举的作用域特征:
| 被声明的位置 | 包含它的类是否可使用它 | 包含它的类派生出的类是否可使用它 | 在外部是否可使用 |
|---|---|---|---|
| private: | 是 | 否 | 否 |
| protected: | 是 | 是 | 否 |
| public: | 是 | 是 | 是,通过:: |
而嵌套类内的成员属性(公友、保护、 私有、友元)决定程序对嵌类成员的访问权限,例如:Queue只能访问Node内的公有成员。
异常:
相对较新的特性,并且有些编译器默认关闭这种特性
异常终止、自定义返回错误码(不重要)
异常处理机制:try、catch、throw(C无C++有)
try{
Judge(); // 只有在try块内调用才能触发
}
catch(const char *s){
//处理语句
}
catch(…) //可以多个catch,由throw、()内的数据类型确定是调用哪个catch
…
void Judge()
{
if(错误条件)
throw “erron”; // 抛出“erron”会传到catch的s;如果没找到相应的处理程序,程序块将异常终止
}
…
// 改进:
// catch(…)的()内更推荐的是定义异常类,通过throw传输异常类对象给catch
…
class BadType1{…};
class BadType2{…};
…
catch(BadType1 &b){…}
catch(BadType2 &d){…}
…
throw BadType1(…);
throw BadType2(…); //抛出异常类的构造函数
栈解退:函数调用的机制
程序将调用函数的指令的地址(返回地址)放到栈中,当被调用的函数执行完毕后,程序将使用该地址来确定从哪里开始继续执行。另外,函数调用将函数参数放到栈中。程序进行栈解退以回到能够捕获异常的地方时,将释放栈中的自动存储型变量,变量是类对象,就调用类对象的析构函数(但并不意味着类对象消失,或着还能引用)。
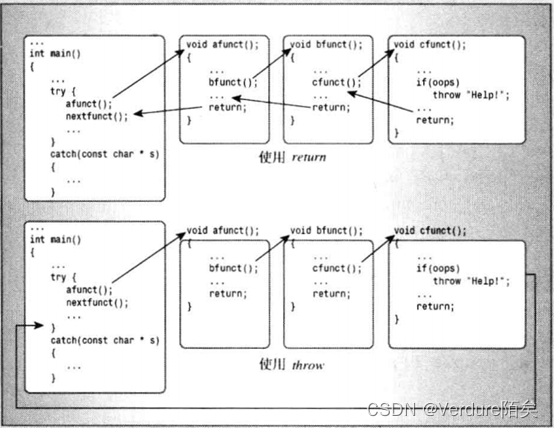
int main()
{
…;
try{
fun();
}
catch(…)
{
…;
}
}
void fun()
{
…;
catch(BadType1 &bt1){
…;
throw; // 会向上把异常(bt1)发送给main()函数内的catch
}
}
异常处理特性
引发异常时编译器总是创建一个临时拷贝:
problem oops;
throw oops;
…;
catch(problem &p){} // p将指向oops的副本而不是oops本身
// 为什么用引用呢,主要用到引用的特性:基类引用可以执行派生类对象。
class bad_1;
class bad_2 : public bad_1{};
class bad_3 : public bad_1{};
…;
catch(bad_1 &be){}// 可捕获bad_1、2、3类型的异常;但感觉有点鸡肋
catch(...){} // 可捕获任何异常;作用类似于switch语句中的default
**C++提供一种可继承的异常基类exception **
与异常处理特性结合使用
#include <exception>
class bad_1 : public exception{};
class bad_2 : public exception{};
//exception类中包含返回一串字符串的what虚成员函数,可在派生类中重新定义它
头文件stdexcept定义了几个公有继承exception的派生类,
主要分logic_error系列类(domain_error、invalid_argument、length_error、out_of_bounds)和
runtime_error(range_error、overflow_error、underflow_error)系列类。
对于使用new导致的内存分配问题,
C++最新处理方式是让new引发bad_alloc异常,头文件new包含bad_alloc类的声明也是公有继承exception;以前new出问题是返回一个空指针。
可通过:
int *pi = new (std::nothrow) int;
int *pi = new (std::nowthrow) int[200]; // 来指定
异常、类和继承组合使用:套中套,娃中娃。
RTTI(运行阶段类型识别)
旨在为程序在运行阶段确定对象的类型提供一种标准;知道类型后,就可以知道调用特定的方法是否安全。//基类指针引用指向派生类
注意:RTTI只适用包含虚函数的类层次结构。
旧版不支持;编译器可能关闭RTTI特性;
C++3个支持RTT1元素:
- dynamic_cast运算符
- typeid运算符
- type_info类
dynamic_cast(安全的类型转换)(偏向用这个)
Type *p = dynamic_cast<Type *>(pt);
通常,如果指向的对象(*pt)的类型为Type或者是从Type直接或间接派生而来的类型,则表达式将指针pt转换为Type类型的指针,否则,结果为0,空指针。
用Type &p也可以但是由于引用不能为空指针,所以dynamic_cast会引发 throw bad_cast(); //异常; bad_cast异常类于<typeinfo>内定义
typeid运算符和type_info类
typeid类似sizeof;typeid运算符返回一个对type_info对象的引用;
而type_info类重载了==和!=运算符;type_info是在<typeinfo>内定义的一个类;
typeid(Type) == typeid(*p) //*p指向一个Type对象
// 表达式的结果为bool值true or false;
如果p是一个空指针,程序将引发bad_typeid异常,在<typeinfo>内声明。
类型转换运算符
四种类型转换运算符:dynamic_cast、const_cast、static_cast、和reinterpret_cast
dynamic_cast运算符
和上述一致,安全的类层次结构中进行向上转换。
const_cast运算符
用于执行只有一种用途的类型转换,
即改变值为const或volatile;使用语法与dynamic_cast相同;
const Type *pt;
Type *pe = const _cast<Type *>(pt);//*pe成为一个可用于修改*pt的指针
使用的原因是,有时候可能需要这样一个值,它在大多数时候是常量,而有时又是可以修改的。
static_cast运算符
和dynamic_cast效果类似,假设High是Low的基类,而Pond是一个无关的类,则从High到Low的转换(不安全)、从Low到High的转换(安全的)都是合法的,而从Low到Pond的转换是不允许的。使用语法类似
High bh;
Low blow;
High * pb = static_case <Low *> (&blow);
Low * pl = static_case <High *> (&bh);
还是更多用dynamic_cast。
而static_case更多的是做整型转枚举、double转int、float转long等操作。
reinterpret_case运算符
用于危险的类型转换,大概率是用不上。
第16章:string类和标准模板库(STL)
string类
string类是由头文件string支持的,头文件string.h、cstring,
这是c-风格字符串操作函数例如:strcpy等。
各种构造函数;+=、=、<<、[]等运算符重载。
string类的输入,
string版本的getline()将自动调整目标string对象的大小,使之能存储输入的字符
// c-风格的
cin.getline(cstr, 100, ':'); //最后一个为可选参数,指定哪个字符确定输入边界,默认为’\n’;
// string类的:
getline(str, ':');
// 调整的大小有限制因素:
// 1、string对象允许的最大长度,由常量string::npos指定,值很大正常不会带来实际限制,除非试图读取整个文件的内容到string对象;
// 2、程序可使用的内存量;
string对象字符串比较:>、<、!=、==、>=、<=
(新)size() == length(); //值一样
许多功能函数:……;
string类自动调整大小是倍化增加,
当存储空间不足时,就会开辟一块两倍大小的新内存块,把旧内存块内容放置于新内存块中。
字符串种类
string库实际上是基于basic_string模板类的,并不是基于char类型;
模板basic_string有4个具体化,每个具体化都有一个typedef名称;
typedef basic_string<char> string; //正常使用这个
typedef basic_string<wchar_t> wstring;
typedef basic_string<char16_t> u16string; //C++11
typedef basic_string<char32_t> u32string ; //C++11
智能指针模板类
常规指针做不到自己释放内存;而指针类由于有析构函数则能完成自动释放内存,即智能指针:unique_ptr(唯一性智能指针)、shared_ptr(共享性智能指针) ;
weak_ptr(管理弱引用)(shared_ptr指针的一种辅助工具)、auto_ptr(C++11删除了,浅拷贝问题)
要创建使用智能指针,需要#include <memory>,该文件模板定义,使用通常的模板语法实例化所需的智能指针。
std::unique_ptr<double> pdu(new double);
std::shared_ptr<string> pss(new string);
// new string是构造函数shared_ptr<string>的参数:
std::shared_ptr<std::string> pss(new std::string(str));
智能指针都应避免的一点是:不能用于非堆内存。 //感觉定位new也不行
string vacation(“hello world”);
shared_ptr<string> pss(&vacation); //error
// 程序将把delete用于非堆内存,这是错误的;
shared_ptr:共享性智能指针
跟踪引用特定对象的智能指针数,即Sptr智能指针指向对象,引用计数将加1,另一个Sptr智能指针指向相同的对象,则引用计数+1;而Sptr智能指针过期时,计数-1,仅当最后一个指针过期时,才调用delete。
unique_ptr:唯一性智能指针
所有权概念,对于特定的对象,智能有一个Uprt智能指针可指向它,否则编译器会报错。Uptr可new []
STL:标准模板库
STL提供了一组表示容器、迭代器、函数对象和算法的模板;
- 容器:是一个与数组类似的单元,可以存储若干个值。STL容器是同质的,即存储的值的类型相同;
- 迭代器:能够用来遍历容器的对象,与能够遍历数组的指针类似,是广义指针;
- 函数对象:是类似于函数的对象,可以是类对象或函数指针;
- 算法:是完成特定任务(如对数组进行排序或在链表中查找特定值)的处方;
例如:
//vector动态数组模板类;容器的一种;参数:数据类型、大小
vector<double> vtd(5);
vector<double>::iterator pd; //为容器定义一个迭代器pd
pd = vtd.begin(); //vrd容器第一个元素;begin、end等返回迭代器类型
//and rbegin、rend可反向输出容器内容(可反转容器特有);
//或者用到auto自动类型推断
auto pd = vtd.end(); // vtd.end()是超过结尾,它是一种迭代器,指向容器最后一个元素后面的元素;类似C字符串后面的空字符
...
// 以下是一些容器的特有函数方法;而begin、end等是容器的通用方法
//将元素添加到矢量末尾,增加矢量长度
vtd.push_back(double d)
//删除矢量中给定区间元素;从it1到it2
vtd.erase(iterator it1, iterator it2);
//在it1(本容器)前插入it2~it3(其它同类型容器)区间元素
vtd.insert(it1,it2,it3)
vector的成员函数swap()的效率比STL非成员函数swap()高,但非成员函数让您能够交换两个类型不同的容器的内容;
以下3种具有代表性的STL非成员函数
普遍适应多种容器;for_each、random_shuffle、sort
// for_each
//可代替for循环;被指向的函数不能修改容器元素的值
//参数:元素区间、函数对象
for_each(vtd.begin(), vtd.end(), ShowReview);
/* ==
vector<Review>::iterator pr;
for (pr = vtd.begin(); pr ! = vtd.end(); pr++)
ShowReview (*pr);
*/
//基于范围的for循环:可修改容器内容,用引用参数;区间固定为整个容器
for(auto &x : vtd) ShowReview (x);
// random_shuffle
//随机排列该区间内的元素;需要容器支持随机访问eg:vector
//参数:元素区间
random_shuffle(vtd.begin(), vtd.end());
// sort
//版本一:对区间内的元素使用<运算符,进行升序排序
//参数:元素区间
/*需要容器支持随机访问;如果容器类型为自定义类则需要提供成员或非成员函数operator<() (P681;好像内置有交换语句函数返回bool类型)*/
sort(vtd.begin(), vtd.end());
//版本二:参数为元素区间、函数对象;和版本一自定义类差不多
sort(vtd.begin(), vtd.end(), Fun);
迭代器类型:各种迭代器的类型并不确定,而只是一种概念性描述
每个容器类vector、list、deque等都有定义了相应的迭代器类型,可能是指针,对象等等,但都有*、++等功能;
STL定义了5种迭代器,
分别是输入迭代器、输出迭代器、正向迭代器、双向迭代器、随机访问迭代器。
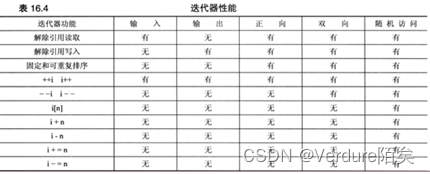
迭代器类型形成了一个层次结构。
正向迭代器具有输入迭代器和输出迭代器的全部功能,同时还有自己的功能;
双向迭代器具有正向迭代器的全部功能,同时还有自己的功能;
随机访问迭代器具有双向迭代器的全部功能,同时还有自己的功能。//套娃
例如:
vector<int>类的迭代器是随机迭代器,它允许使用基于任何迭代器类型的算法;
而list<int>类的迭代器是双向迭代器,只能向下兼容,不能向上使用随机迭代器的算法。
迭代器是广义指针,而指针满足所有的迭代器要求。迭代器是STL算法的接口,而指针是迭代器,因此STL算法可以使用指针来对基于指针的非STL容器进行操作。例如,可将STL算法用于数组:
double array[SIZE];
sort(array, array+SIZE); //对数组进行排序
STL提供了一些预定义迭代器:
需要#include
除了ostream_iterator(输出迭代器模型)和istream_iterator(输入迭代器模型)
之外,还有reverse_iterator(反向迭代器)、
(三种插入迭代器)back_insert_iterator、front_insert_iterator和insert_iterator等。//会挑容器;具体功能实例看书
容器种类
STL具有容器概念和容器类型。概念是具有名称(如容器、序列容器、关联容器等)的通用类别;容器类型是可用于创建具体容器对象的模板。
以前的11个容器类型分别是deque、list、queue、priority_queue、stack、vector、map、multimap、set、multiset和bitset(本章不讨论bitset,它是在比特级处理数据的容器);C++11新增了forward_list、unordered_map、unordered_multimap、unordered_set和unordered_multiset,且不将bitset视为容器,而将其视为一种独立的类别。
容器特征(操作)的复杂度由快到慢分为:编译时间、固定时间、线性时间;
C++11新增的基本容器要求:移动构造函数、移动赋值运算符、const返回类型;
容器序列:
序列容器的迭代器至少是正向迭代器,并且元素将按特定顺序排列,不会在两次迭代之间发生变化。因为序列中的元素具有确定的顺序,因此可以执行诸如将值插入到特定位置、删除特定区间等操作。
7种序列容器类型:
vector(动态数组的类表示)、deque(双端队列)、list(双向链表)、forward_list(单链表)、queue(适配器类(队))、proproty_ queue(另一个适配器类)、stack(适配器类(栈))、array(定长数组)。
关联容器
关联容器是对容器概念的另一个改进,关联容器将值与键关联在一起,并使用键来查找值。关联容器的优点在于,它提供了对元素的快速访问。与序列相似,关联容器也允许插入新元素,但不能指定元素的插入位置。原因是关联容器通常有用于确定数据放置位置的算法。关联容器通常是使用某种树实现的。
STL提供了4种关联容器:
set、multiset、map和multimap。
set:
对于set来说,值就是键;可反转、经过排序的
set<string, less<string>> A; //要存储的值类型;对键进行排序的比较函数或对象
// == set<string> A; 第二个参数是默认参数,默认使用less<>。
STL提供了一些通用函数算法:
//并集,包含两个集合合并后的内容
set_union(A.begin(), A.end(), B.begin(), B.end(),
insert_iterator<set<string>>(C, C.begin())); //最后一个参数需要为输出迭代器
set_intersection(…); //交集,两个集合都有的元素
set_difference(…); //两个集合的差,第一个集合减去两个集合都有的元素
两个有用的set方法有lower_boun、upper_bound
//将参数作为键,并返回一个迭代器,该迭代器指向A集合中第一个不小于键参数的成员
A.lower_bound(…);
//将参数作为键,并返回一个迭代器,该迭代器指向A集合中第一个大于键参数的成员
A. upper_bound(…);
multimap:
键和值的类型不同,且同个键可能与多个值想关联;可反转、经排序
multimap<int, string, less<int>> codes; //键的类型;值的类型;对键进行排序的比较函数或对象
// == multimap<int, string> codes; 第三个参数是默认参数,默认使用less<>。
插入对象数据:
实际的值类型是将键类型和数据类型结合为一对。
使用pair<class T, class U>将这两种值存储到一个对象中,
例如:
pair<const int, string>
对于pair对象,可以使用first和second成员来访问其两个部分;
pair<const int, string> item(213, “little city”); //item.first == 213; item.second
插入元素可:
codes.insert(pair<const int, string> (213, “little city”) ); //== codes.insert(item);
multimap的成员方法有
count、lower_boun、upper_bound、equal_range、
无序关联容器
无序关联容器也是将值与键关联在一起,并使用键来查找值。底层差别在于,无序关联容器是基于数据结构哈希表的,这旨在提高添加和删除元素的速度以及提高查找算法的效率。有4种无序关联容器,
它们分别是unordered_set、unordered_multiset、unordered_map和unordered_multimap。
函数对象
函数对象也叫函数符,函数符是可以以函数方式与( )结合使用的任意对象,这包括函数名、指向函数的指针和重载了( )运算符的类对象(即定义了函数operator()()的类)。
class Linear
{
private:
double slope;
double y0;
public:
Linear(double sl =1,double y=0):s1ope(s1_),y0(y_){}
double operator()(double x)
{
return y0 + slope * x;
}
};
// 这样,重载的()运算符将使得能够像函数那样使用Linear对象:
Linear f2(2.5,10.0);
double y2 = f2(0.4);
// 在表达式y0+slope*x中,y0和slope的值来自对象的构造函数,而x的值来自operator()()的参数。
函数符概念
不用参数就可以调用的函数符称为生成器(generator)。
一个参数可以调用的函数符称为一元函数(unary function)。
两个参数可以调用的函数符称为二元函数(binary function)。
当然,这些概念都有相应的改进版:
返回bool值的一元函数是谓词(predicate);
返回bool值的二元函数是二元谓词(binary predicate)。
能较好的适用这些概念及更灵活功能更强大的主要函数法为重载了( )运算符的类对象。
预定义的函数符
(前置)函数transform()有两个版本,
-
版本一:
//把容器内的每个元素sqrt,并打印出来;4个参数; vector<double>gr8(arrl,arrl LIM); ostream iterator<double,char>out (cout,"") //前两个参数为容器区间;第三个指定结果复制到哪个迭代器;最后一个是一个函数符; transform(gr8.begin(),gr8.end(),out,sqrt); -
版本二:
//两个数组相加,并打印出来;5个参数; double add(double x,double y)return x +y; //前两个参数为第一个容器区间;第三个参数为另一个容器的起始位;第四个指定结果复制到哪个迭代器;最后一个是一个接收2个参数的函数符; transform(gr8.begin(),gr8.end(),m8.begin(),out,add);//有个弊端,必须为每种类型单独定一个函数;∴模板函数符;
头文件functional定义了多个模板类函数对象,其中包括plus<>()。
所以可改成:
#include <functional>
transform(gr8.begin(), gr8.end( ), m8.begin( ) , out, plus<double>() ); //临时函数符
……;
算法
STL将算法库分成4组:
非修改式序列操作、修改式序列操作、排序和相关操作、通用数字运算。
前3组在头文件algorithm中描述,第4组是专用于数值数据的,有自己的头文件,称为numeric。
非修改式序列操作:
对区间中的每个元素进行操作。这些操作不修改容器的内容。例如,find()和for_each()就属于这一类。
修改式序列操作:也对区间中的每个元素进行操作。它们可以修改容器的内容。可以修改值,也可以修改值的排列顺序。transform()、random_shuffle()和copy()属于这一类。
排序和相关操作:
包括多个排序函数(包括sot())和其他各种函数,包括集合操作。
数字操作:
包括将区间的内容累积、计算两个容器的内部乘积、计算小计、计算相邻对象差的函数。通常,这些都是数组的操作特性,因此vector是最有可能使用这些操作的容器。
算法版本:
就地版本、复制版本(_copy)、特殊版本(_if)、组合版本(_copy_if),replace、replace_copy、replace_if、replace_copy_if;//详情看书
有时可以选择使用STL方法或STL函数。
通常方法是更好的选择。
首先,它更适合于特定的容器;
其次,作为成员函数,它可以使用模板类的内存管理工具,从而在需要时调整容器的长度。
例如,假设有一个由数字组成的链表,并要删除链表中某个特定值(例如4)的所有实例。如果la是一个list<int>对象,则可以使用链表的remove()方法:
la.remove(4);// 调用该方法后,链表中所有值为4的元素都将被删除,同时链表的长度将被自动调整。
还有一个名为remove()的STL算法,它不是由对象调用,而是接受区间参数。因此,调用该函数的代码如下:
remove(1a.begin(),1a.end(),4);// 由于该remove()函数不是成员,因此不能调整链表的长度。
它将没被删除的元素放在链表的开始位置,并返回一个指向新的超尾值的迭代器。这样,便可以用该迭代器来修改容器的长度。
杂:valarray类模板面向数值计算,挺好用的;……;
第17章:输入、输出和文件
C++输入输出的标准类库iostream,fstream
C++程序把输入和输出看作字节流。输入时程序从输入流中抽取字节;输出时,程序将字节插入到输出流中。
通过使用缓冲区可以更高效地处理输入和输出。缓冲区是用作中介的内存块,它是将信息从设
备传输到程序或从程序传输给设备的临时存储工具。
实现、管理流和缓冲区的一些类:
- streambuf类为缓冲区提供了内存,并提供了用于填充缓冲区、访问缓冲区内容、刷新缓冲区和管理缓冲区内存的类方法;
- ios_base类表示流的一般特征,如是否可读取、是二进制流还是文本流等;
- ios类基于ios base,.其中包括了一个指向streambuf对象的指针成员;
- ostream类是从ios类派生而来的,提供了输出方法:
- istream类也是从ios类派生而来的,提供了输入方法:
- iostream类是基于istream和ostream类的,因此继承了输入方法和输出方法。例如,使用ostream对象(如cout)来处理输出。
程序包含iostream类库将自动创建的8个流对象(4窄4宽)
-
cin对象对应于标准输入流。在默认情况下,这个流被关联到标准输入设备(通常为键盘)。wcin对象与此类似,但处理的是wchar_t类型。
-
cout对象与标准输出流相对应。在默认情况下,这个流被关联到标准输出设备(通常为显示器)。wcout对象与此类似,但处理的是wchar_t类型。
-
cerr对象与标准错误流相对应,可用于显示错误消息。在默认情况下,这个流被关联到标准输出设备(通常为显示器)。这个流没有被缓冲,这意味着信息将被直接发送给屏幕,而不会等到缓冲区填满或新的换行符。wcerr对象与此类似,但处理的是wchar_t类型。
-
clog对象也对应着标准错误流。在默认情况下,这个流被关联到标准输出设备(通常为显示器)。这个流被缓冲。wclog对象与此类似,但处理的是wchar_t类型。
-
对象代表流一这意味着什么呢?当iostream文件为程序声明一个cout对象时,该对象将包含存储了与输出有关的信息的数据成员,如显示数据时使用的字段宽度、小数位数、显示整数时采用的计数方法以及描述用来处理输出流的缓冲区的streambuf对象的地址。下面的语句通过指向的
streambuf对象将字符串“Bjarna free”中的字符放到cout管理的缓冲区中:cout << "Bjarne free";
重定向
输入重定向(<)和输出重定向(>)
ostream类对象cont输出
使用cout和<<运算符(插入(insertion)运算符)
int clients = 22;
cout << clients;
插入运算符被重载,使之能够识别C++中所有的基本类型,使之能输出对应的类型
输出指针:
char name[20] = "Dudly Diddlemore";
char * pn =,-Violet D* AmoreM;
cout << "Hello!";
cout << name;
cout << pn;
// cout语句都显示字符串
cout << &pn; // 要打印地址用解引用
拼接输出:
cout << "potluck" // 返回的是cout对象。
// 这种特性使得能够通过插入来连接输出
cout << "We have" << count << "unhatched chickens. \n";
// 表达式cout« “We have”将显示字符串,并返回cout对象。至此,上述语句将变为:
cout << count << "unhatched chickens. \n";
ostream其他方法
put()方法和write()方法,前者用于显示字符,后者用于显示字符串。
// put
cout.put('c');
cout.put(65);
//write
#include <iostream>
#include <cstring>
int main()
{
using std::cout;
using std::endl;
const char * state2 = "Kansas";
int len = std::strlen(state2);
int i;
for (i = 1; i <= len; i++) {
cout.write(state2, i);
cout << endl;
}
return 0;
}
width():调整字段宽度
fill():改变填充字符
precision():设置浮点数的显示精度
setf():控制小数点被显示时其他几个格式选项,
有两种重载,对应单参数和双参数
单参数为bitmask类型:
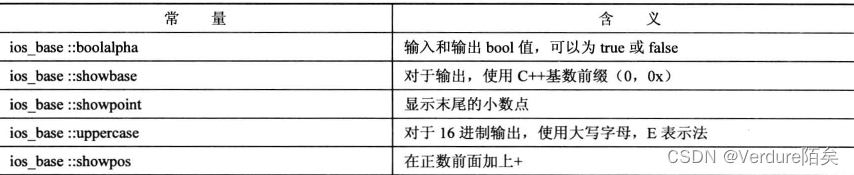
双参数,setf(long, long)的参数:
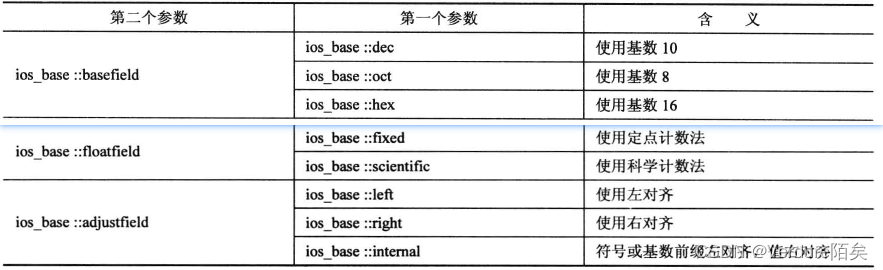
// 双
cout.setf(ios_base::left, ios_base:adjustfield);
// 单
cout.setf(ios_base::showpos);
cout.setf(ios_base::showpoint);
调用setf()的效果可以通过unsetf()消除,后者的原型如下:
void unsetf(fmtflags mask);
头文件iomanip
使用iostream工具来设置一 些格式值(如字段宽度)不太方便。为简化工作,C++在头文件iomanip 中提供了其他一些控制符,它们能够提供前面讨论过的服务,但表示起来更方便。3个最常用的控制符分别是
setprecision()、setfill()和setw(),它们分别用来设置精度、填充字符和字段宽度。
istream类对象cin输入
cin对象将标准输入表示为字节流。通常情况下,通过键盘 来生成这种字符流。
int val;
cin >> val;
抽取运算符>>重载,cin对象根据接收值的变量的类型,使用其方法将字符序列转换为所需的类型。
cin >> 检查输入
例如,对于下面的代码:
int elevation;
cin >> elevation;
// 假设键入下面的字符: -123Z
运算符将读取字符-、1、2和3,因为它们都是幣数的有效部分。但Z字符不是有效字符,因此输入中 最后一个可接受的字符是3。Z将留在输入流中,下一个cin语句将从这里幵始读取。与此同时,运算符将 字符序列-123转换为一个整数值,并将它赋给elevation。
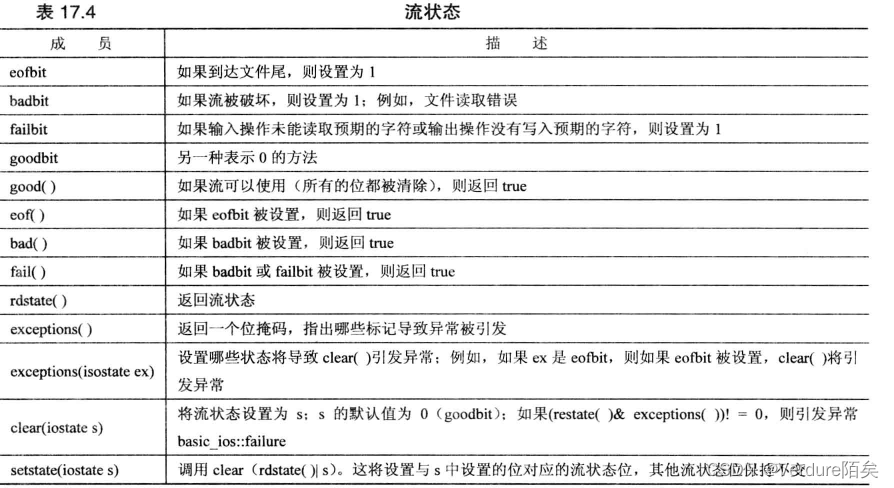
流状态
cin或cout对象包含一个描述流状态(stream state)的数据成员(从ios_base类那里继承的)。流状态 由3个ios base元素组成:eofbit、badbit或failbit,其中每个元素都是一位,可以是1 (设置)或0 (清 除)。
当c i n 操作到达文件末尾时,它将设置eofbit;当cin操作未能读取到预期的字符时(像前一个例 子那样),它将设置failbit。
I/O失败(如试图读取不可访问的文件或试图写入写保护的磁盘),也可能将 failbit设置为1。
在一些无法诊断的失败破坏流时,badbit元素将被设置。
当全部3个状态位都设置为0时,说明一切顺利。稈序可 以检查流状态,并使用这种信息来决定下一步做什么。
istream对象的错误状态被设置,if或while语句将判定该对象为false
流状态成员函数:
其他istream类方法
单字符输入:
- 成员函数 get(char &)
- 成员函数get(void)
- 字符串输入:getline()、get()和 ignore()
其他istream方法包括read()、peek()、gcount()和putback()。
文件输入和输出
C++在头文件fstream 中定义了多个新类,其中包括用于文件输入的 ifstream类和用于文件输出的ofstream类。C++还定义了一个fstream类,用于同步文件I/O。这些类都是从头文件iostream中的类派生而来的,因此这些新类的对象可以使用前面介绍过的方法。
#include <iostream>
#include <fstream>
#include <string>
int main()
{
using namespace std;
string filename;
cout << "Enter name for new file:"
cin >> filename; // 输入文件路径名
// 为新文件创建输出流对象,并将其命名为out
ofstream fout(filename.c_str());
// => ofstream fout;fout.open(filename.c_str());
if(!fout.is_open()){ // 检查文件是否成功打开
}
fout << "For your eyes only!\n"; //write to file
cout << "Enter your secret number:"; //write to screen
float secret;
cin >> secret;
fout << "Your secret number is " << secret <endl;
fout.close(); //close file,刷新缓冲区
// 为新文件创建输入流对象并将其命名为fin
ifstream fin(filename.c_str());
if(!fin.is_open()){ // 检查文件是否成功打开
}
cout << "Here are the contents of " << filename <<":\n";
char ch;
// read character from file and
while (fin.get (ch))
cout <ch;
// write it to screen
cout <"Done\n";
fin.close();
return 0;
}
在控制台键入文件名,查看该程序所在的目录,将看到一个相应的文件,使用文本编辑器打开该文件,其内容将与程序输出相同。
打开文件模式
在C++中,使用std::ifstream或std::ofstream(以及std::fstream)来打开文件时,你可以指定多种打开模式。这些模式是通过std::ios_base类中定义的一系列常量来指定的,可以通过按位或(|)操作符组合多个模式。
以下是常用的文件打开模式:
std::ios::in: 以输入模式打开文件,用于读取文件内容。这是std::ifstream的默认模式。std::ios::out: 以输出模式打开文件,用于写入文件内容。这是std::ofstream的默认模式。如果文件已存在,并且没有使用std::ios::app或std::ios::trunc,则内容会被覆盖。std::ios::app: 以追加模式打开文件,用于在文件末尾添加内容。如果文件不存在,则创建它。std::ios::ate: 打开文件后立即将文件指针定位到文件末尾。这通常与输入文件一起使用,以便从文件的末尾开始读取。std::ios::trunc: 如果文件已存在,则删除文件的所有内容。通常与std::ios::out一起使用来创建一个新文件或覆盖现有文件。std::ios::binary: 以二进制模式打开文件,而不是文本模式。这在跨平台文件操作或处理非文本数据时特别有用。
你可以通过按位或操作符组合这些模式来指定多个模式。例如:
std::ifstream inFile("example.txt", std::ios::in | std::ios::binary); // 以二进制输入模式打开文件
std::ofstream outFile("example.txt", std::ios::out | std::ios::trunc); // 以输出模式打开文件,并覆盖现有内容
std::ofstream appFile("example.txt", std::ios::out | std::ios::app); // 以追加模式打开文件,在文件末尾添加内容
std::fstream file("example.txt", std::ios::in | std::ios::out | std::ios::trunc); // 同时支持读写操作,并覆盖现有内容
文件指针
seekp是std::ostream(及其派生类,如std::ofstream和std::fstream)的一个成员函数,用于设置输出流中的“put”指针(即写指针)的位置。
#include <fstream>
#include <iostream>
int main()
{
std::ofstream outfile("example.txt");
if (!outfile) {
std::cerr << "Failed to open file!" << std::endl;
return 1;
}
outfile << "Hello, World!" << std::endl;
outfile << "This is a test." << std::endl;
// 将写指针移动到文件的开头
outfile.seekp(std::ios_base::beg);
// 在文件的开头写入新的内容,这会覆盖原有的内容
outfile << "Start of file" << std::endl;
// 将写指针移动到当前位置之后10个字符处
outfile.seekp(10, std::ios_base::cur);
outfile << "Inserted text" << std::endl;
outfile.close();
return 0;
}
seekg是std::istream(及其派生类,如std::ifstream和std::fstream)的一个成员函数,用于设置输入流中的读取位置(即“get”指针的位置)。和seekp类似用法。
定位与寻址
tellp(): 返回输出流中的“put”指针的位置。tellg(): 返回输入流中的“get”指针的位置。
第18章:探讨C+新标准
看看即可,不在基础内,现在出现更多新特性了,有需要的话要专门去看~