一、为什么要分库分表
海量数据请求的时候,数据库承载不了这么大的并发,性能下降,需要优化,而分表分库是对关系型数据库存储和访问机制的补充
二、什么是分库分表
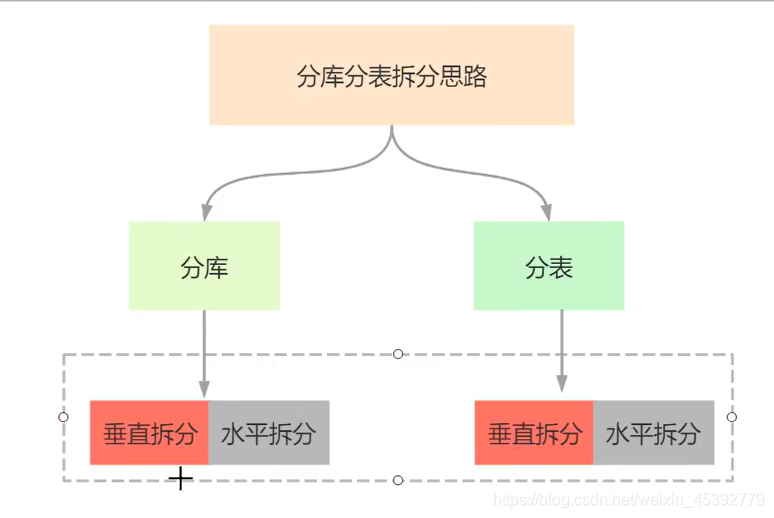
一个库一个表 拆分为 N个库N个表 分为垂直拆分,水平拆分
去中心化,分散数据
按照一定的规则,将原本数据量大的数据库拆分成多个单独的数据库,将原本数据量大的表拆分成若干个数据表,使得单一的库、表性能达到最优的效果(响应速度快),以此提升整体数据库性能。
三、分库分表的几种方式

垂直的特点:-----拆的是结构
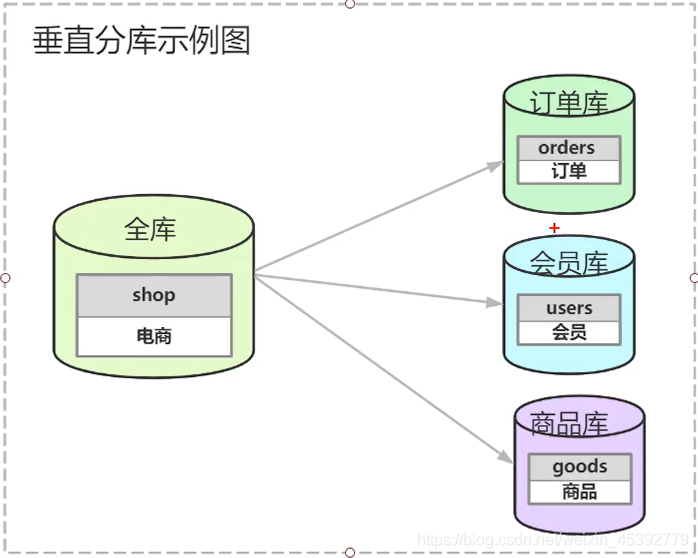
a.每个库(或表)结构不一样
b.每个库(或表)至少有一列数据是一样的
c.每个库(或表)并集是全量数据
垂直的优点:适用于项目开始前
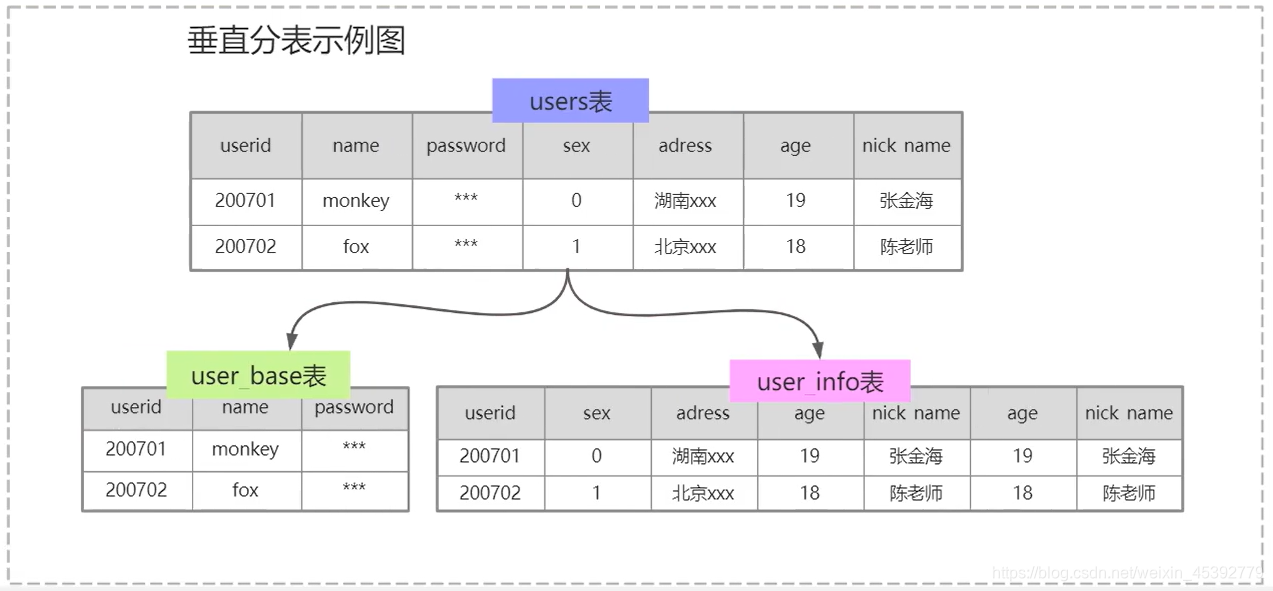
a.每个库(或表)结构不一样
b.每个库(或表)至少有一列数据是一样的
c.每个库(或表)并集是全量数据
垂直的缺点:
a.如果单表数据量大,读写压力大
b.受业务限制,会影响性能
c.部分业务无法关联(比如用户到对应商品信息,需要各种Java调用或者join,提高开发复杂度)
分库的垂直拆分:按业务来拆分
分表的垂直拆分:大表拆成小表
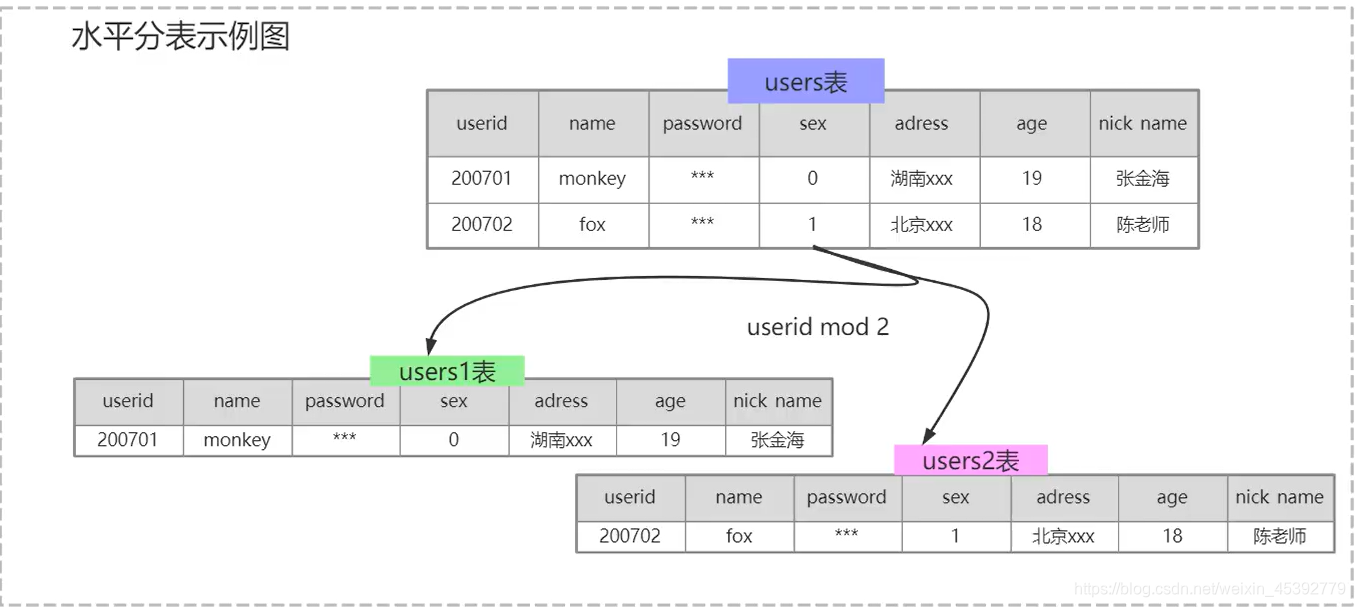
水平的特点:(要均衡)------拆的是数据
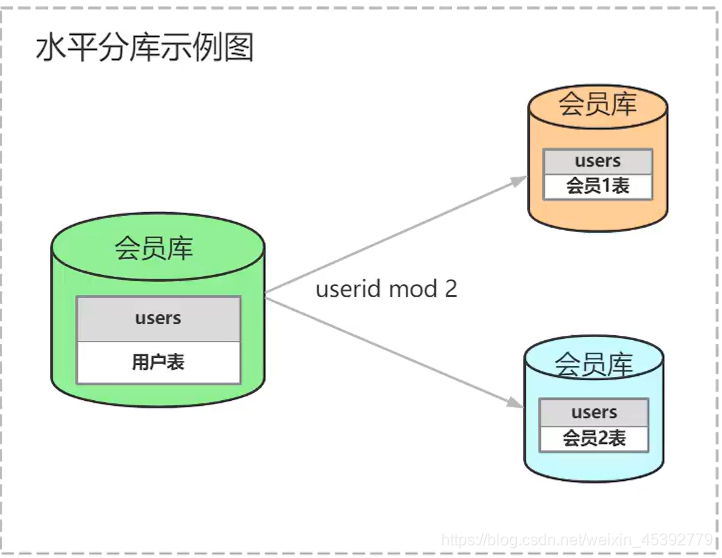
a.每个库(或表)结构一样
b.每个库(或表)数据是不一样的
c.每个库(或表)并集是全量数据
水平的优点:适用于项目使用过程中(分担数据库压力)
a.单库(表)的数据保持在一定的量(减少),有助于性能提高。
b.提高了系统的稳定性和负载能力
c.拆分的表的结构相同、程序改造减少
水平的缺点:
a.数据库的扩容很有难度,维护量大(比如改变规则)
b.拆分规则很难抽象出来
c.分片事务的一致性的问题部分业务无法关联(订单数据拆分)
水平分库:
水平分表:
四、分库分表带来的问题
1.分布式事务
2.跨库join查询
3.分布式全局唯一ID
框架:
jdbc直连层:
shardingsphere、tddl
proxy代理层:
mycat、mysql-proxy
支持跨语言

五、读写分离原理
让主数据库处理事务性增、改、删操作(INSERT、UPDATE、DELETE),而从数据库处理SELECT查询操作。数据库复制被用来把事务性操作导致的变更同步到集群中的从数据库。
读写分离,解决的是,数据库的写入,影响了查询的效率
通过主从复制的方式来同步数据,再通过读写分离来提升数据库的并发负载能力。
六、分库分表源码分析
七、如何不停机迁移分表分库
https://blog.51cto.com/u_14257804/2391224

八、如何动态的扩容
https://blog.csdn.net/ZGL_cyy/article/details/112383767?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_baidulandingword-1&spm=1001.2101.3001.4242

九、分库分表的主键唯一
