3. Strategy(策略模式)C++
策略模式属于“组件协作”模式里的一种。

1. 动机

举个例子,我们假设一个场景,做一个税种的计算,一个跨国的税计算,除了涉及金额等,还需要考虑不同国家的纳税比例。
//第一种做法就是采用分而治之的方法,if-else语句或者是switch-case语句
enum TaxBase{
CN_Tax, //中国
US_Tax, //美国
DE_Tax //德国
};
class SalesOrder{
TaxBase tax;
public:
double CalculaterTax(){
//...
if(tax == CN_Tax){
//...
}else if(tax == US_Tax){
//...
}else if(tax == DE_Tax){
//..
}
//...
}
};
这个做法只要能解决问题,其实也无可厚非。不过,上面的条件判断语句,会有一个性能负担的情况,就是如果大多数情况下只计算德国的,那么 CalculaterTax() 的其他国家算法就都失效了,而且还要去对它继续判断。但从面向对象的角度,我们看代码,不要静态地看一个软件结构的设计,而是要动态地看,要有一个时间轴的概念,要考虑到未来的变化。就拿上面的例子来说,我们需要多考虑一下,有没有一种可能,未来会多增加日本、法国等替他国家税的计算呢。如果需要增加,上面的代码应该怎么变动呢。
//增加其他国家
enum TaxBase{
CN_Tax, //中国
US_Tax, //美国
DE_Tax, //德国
FR_Tax //变动,法国
};
class SalesOrder{
TaxBase tax;
public:
double CalculaterTax(){
//...
if(tax == CN_Tax){
//...
}else if(tax == US_Tax){
//...
}else if(tax == DE_Tax){
//..
}else if(tax == FR_Tax){ //变动
//...
}
//...
}
};
由上面的代码可以看出,其实违背了一个设计原则,开闭原则(对扩展开放,对更改封闭),上面的变动都属于更改。你可以发现,单每增加一个国家的计算,都需要修改 SalesOrder 类里的 CalculateTax 方法。类模块应该以扩展的方式来支持未来的变化,而不是找到源代码,修改源代码来面对未来的变化。所以就有了第二种做法。
//第二种做法不采用枚举了,直接通过工厂模式(有可能你还没学过工厂模式,不要急,可以先看下面的实现,学了工厂模式之后可以回头再来看一下)来生成对应的类
class TaxStrategy{
public:
//context是算法上下文,保存一些参数,如税率、金额等
virtual double Calculate(const Context& context)=0;
//这里要注意,记得基类的析构函数要写成虚的,子类的析构函数才能去准确调用
virtual ~TaxStategy(){}
};
//注意:建议在真正的工程开发中,每个类是单独一个文件。这里只是为了讲解才写到一起
//这里每个国家税的计算,都有自己独立的一个 Calculate 方法。其实就是把第一种方法中的每个 if 语句下对应的代码都放到自己对应的 Calculate 方法中。事实上,我们就是把一个一个的算法,变成 TaxStrategy 的子类
class CNTax : public TaxStrategy{
public:
virtual double Calculate(const Context& context){
//...
}
};
class USTax : public TaxStrategy{
public:
virtual double Calculate(const Context& context){
//...
}
};
class DETax : public TaxStrategy{
public:
virtual double Calculate(const Context& context){
//...
}
};
class SalesOrder{
private:
//这里我们采用组合的形式,放了一个TaxStrategy指针,是为了实现多态。其实也可以放引用,虽然引用也有多态性,但是它会存在其他的毛病,在文末说明。一般来讲,如果要实现多态的变量的话,一般采用指针
TaxStrategy* strategy;
public:
SalesOrder(StrategyFactory* strategyFactory){
//这里的多态对象,我们就采用了工厂模式来创建,其实你可以理解,就是工厂里只要支持指定的国家,它就可以帮你生产一个该国家的对象出来
this->strategy = strategyFactory->NewStrategy();
}
~SalesOrder(){
delete this->strategy;
}
double CalculateTax(){
//...
Context context();
double val = strategy->Calculate(context); //多态调用
//...
}
};
这两种方法,如果我们要比较好处,还是要放到时间轴里去比。第二种方法,如果要增加对其他国家的计算,应该怎么修改呢。
class TaxStrategy{
public:
//context是算法上下文,保存一些参数,如税率、金额等
virtual double Calculate(const Context& context)=0;
virtual ~TaxStategy(){}
};
class CNTax : public TaxStrategy{
public:
virtual double Calculate(const Context& context){
//...
}
};
class USTax : public TaxStrategy{
public:
virtual double Calculate(const Context& context){
//...
}
};
class DETax : public TaxStrategy{
public:
virtual double Calculate(const Context& context){
//...
}
};
//扩展
//**********************增加法国的计算
class FRTax : public TaxStrategy{
public:
virtual double Calculate(const Context& context){
//...
}
};
class SalesOrder{
private:
TaxStrategy* strategy;
public:
SalesOrder(StrategyFactory* strategyFactory){
this->strategy = strategyFactory->NewStrategy();
}
~SalesOrder(){
delete this->strategy;
}
double CalculateTax(){
//...
Context context();
double val = strategy->Calculate(context); //多态调用
//...
}
};
这里只需要多增加一个法国的类,当然还要工厂模式里支持法国,但 SalesOrder 类,完全不用变化的,得到了复用性。遵循了开放封闭原则。
这个时候,如果我们的各个国家的类都是单独一个文件的话,就只需要增量编译,其他不用重新编译,只需要多增加这个类的编译产物(二进制文件)就好了。
有的同学会想第一种方法不也有复用性吗,只需要在 Calculate 函数最后多增加其他国家的计算方法就好了。但其实那不叫复用,而且事实上,如果你在下面增加对其他国家的计算方法,你不能保证 Calculate 函数前面就不用改动,通常情况下是需要去修改到前面的东西的,例如变量等。面向对象里的复用性指的是编译单位,二进制层面的复用性。单纯地拷贝源代码,那不叫复用。真正的复用是,代码在编译、部署之后,可以原封不动,变动的时候只需要多增加变动的二进制文件就可以了,这样才符合开闭原则。
2. 模式定义
可互相替换就是支持变化。我们要养成一个习惯,当我们拿到代码时,要可以看出哪些是稳定的,哪些是变化的。

3. 结构
绝大多模式我们是可以找出它稳定的部分和变化的部分。单例模式除外。
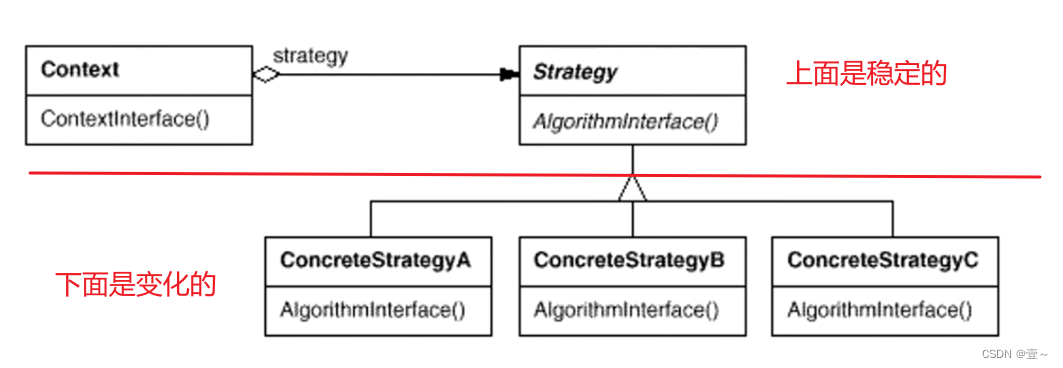
4. 要点总结
注意:

- 策略模式使得我们去构建可重用的算法,从而使得类型可以在运行时才去根据需要动态切换。
- 而且我们要有一种敏觉,但出现很多的条件判断语句时,我们可以考虑一下策略模式。当然如果条件判断是很固定的(例如性别和一个星期七天等很固定的),这种情况就排除。如果未来会有多的扩展,就可以考虑策略模式。
- 还有我们为什么说第一种方法会有性能负担呢,其实 CalculaterTax() 函数里,如果其他国家的计算比较少用到,但是如果它们的计算方法复杂而且所占内存多的话,这时是把整个 CalculaterTax() 函数都装载到进程的代码段里的,但实际上却没有被全部使用。第二种方法就不存在这个问题,第二种方法是运行时才调用,一般是执行哪个才调用哪个的方法,这种我们一般称为代码拥有良好的本地性。代码是存放在进程的代码段里的,最好的情况是,该代码段加载到CPU的高级缓存里面,那样执行得最快。但如果代码段过长的话,就需要有一部分放到主存里面,如果主存放不下,还要通过虚拟内存,放到硬盘里面。这样子在调用时,速度就会慢下来了。所以策略模式还可以缓解这个问题,当然,策略模式只是顺带有这个好处,重点还不是这里。主要解决的是,用扩展的方式来应对未来算法需求变化。
前面提到的,不用引用,是为什么呢?
引用具有多态性的主要原因是它可以指向派生类的对象,并且在使用基类引用调用虚函数时,会根据所引用的实际对象类型来调用相应的派生类函数,实现多态行为。
然而,引用也可能会存在一些问题,这取决于具体的使用情境:
-
生命周期管理:引用本身不拥有对象的所有权,它只是对对象的别名。因此,在使用引用时,必须确保所引用的对象在引用的整个生命周期内是有效的。如果引用超出了所引用对象的生命周期,就会产生悬空引用(dangling reference)的问题,这可能导致未定义的行为。
-
不可重新绑定:一旦引用被初始化,就无法重新绑定到另一个对象上。这意味着在某些情况下,如果需要更改引用指向的对象,则必须通过重新设计或使用指针来实现。
-
空引用:引用不能指向空值(null),因此在某些情况下,如果需要表示对象的缺失或空状态,则无法使用引用。
-
局部性:引用通常具有更严格的局部性,它必须在初始化时指定,并且无法在后续代码中更改。这可能会限制其在某些情况下的灵活性。
总的来说,引用在提供简洁性和语义清晰度方面具有优势,但在某些情况下可能会受到其不可重新绑定和生命周期管理等方面的限制。因此,在选择引用或指针时,需要考虑到具体的需求和设计考量。
举个例子:
#include <iostream>
class Base {
public:
virtual void display() {
std::cout << "Base display()" << std::endl;
}
};
class Derived1 : public Base {
public:
void display() override {
std::cout << "Derived1 display()" << std::endl;
}
};
class Derived2 : public Base {
public:
void display() override {
std::cout << "Derived2 display()" << std::endl;
}
};
int main() {
Derived1 obj1;
Derived2 obj2;
Base& ptr = obj1; // 使用基类引用指向 Derived1 对象
ptr.display(); // 输出 Derived1 display()
// 无法重新绑定引用到其他对象
// ptr = obj2; // 这里会报编译错误
return 0;
}