一、推荐系统简介
我们现在身处的时代是信息大爆炸的时代,每时每刻都有海量的信息产生,对于人类而已,浏览所有的信息去寻找自己想要的信息代价太大,搜索系统和推荐系统应运而生。利用搜索系统,用户可以输入关键词搜索自己想要的信息;而推荐系统则不需要用户输入关键词,自己猜测用户可能对什么东西感兴趣,从而进行推荐。所以推荐系统和搜索系统是互补的关系。推荐系统的另一种功能就是发现商品的长尾。长尾产品是需求不旺或销量不佳的产品,但是相比销量巨大的热门商品,长尾商品却在数量上占有优势。发现商品的长尾即把一些销量不佳的冷门商品推荐给个别有个性化需求的人,从而产生更多的利润。
二、推荐系统架构
推荐系统的主要架构如上图所示。数据平台为建模,召回,A/B测试提供数据;推荐系统算法工程师利用数据平台提供的数据对用户行为进行建模,得到不同的模型和召回策略;召回策略和平台数据会产生初始的推荐列表,对初始推荐列表进行过滤,排序,重排以后就得到了最终的推荐列表;AB测试是一种很常用的在线评测算法的实验方法。它通过一定的规则将用户随机分成几组,并对不同组的用户采用不同的算法(模型),然后通过统计不同组用户的各种不同的评测指标比较不同算法(模型),比如可以统计不同组用户的点击率,通过点击率比较不同算法(模型)的性能;前端是与用户交互的平台,在上面展示推荐的结果。
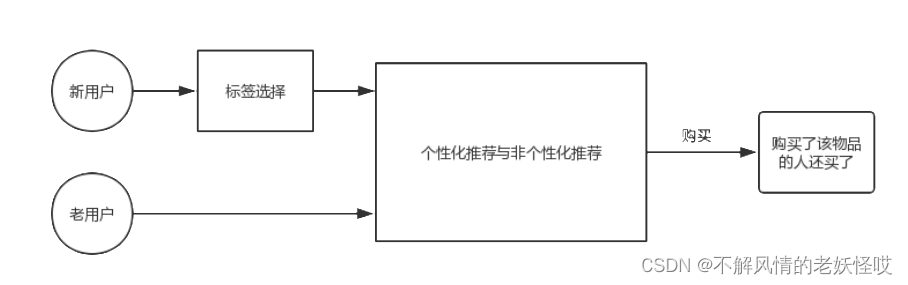
推荐系统功能设计如下图所示:
新用户选择自己喜欢的标签,推荐系统根据用户选择的标签进行推荐。老用户因为注册时已经进行过标签选择,所以推荐系统直接进行推荐。当用户产生购买行为以后,对该商品的相关的商品进行推荐。
标签选择是为了解决冷启动问题:当系统没有用户行为数据时,可以根据用户选择的标签进行推荐。用户产生购买行为后,继续推荐购买该商品的人还经常购买的商品。
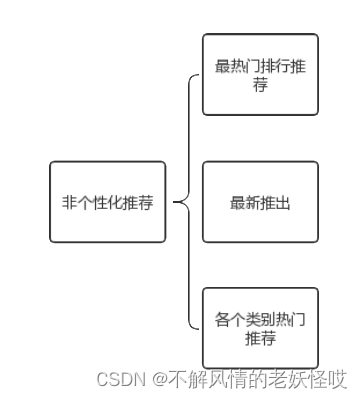
非个性化推荐功能如图所示:
非个性化推荐由三个部分组成:最热门排行榜,最新推出和各类热门推荐。最新推出就是最新上市的商品,需要给它们一个平台进行展示。热门商品就是,最近时间被很多人购买的商品,根据商品被购买次数和时间,我们可以计算商品的热门程度。
主要代码如下:

def RecentPopularity(goods_IDs, purchasing_date, T, alpha=1 / 24 / 3600):
ret = Counter()
for i in range(len(goods_IDs)):
if purchasing_date[i] >= T:
continue
ret[goods_IDs[i]] += 1 / (1.0 + alpha * abs(T - purchasing_date[i]))
good_list = np.array(ret.most_common())
return good_list[:, 0]
(goodsIDs是推荐列表,purchasing_date是购买时间,T是当前时间,时间都计算从1970年1月1日至今所过的秒数。alpha是衡量时间对热度影响的参数。)
个性化推荐功能如图所示:
个性化推荐主要由三部分组成:基于标签的推荐,基于搜素的推荐和基于时间上下文的itemCF推荐。
1.基于标签的推荐
根据用户的标签选择和用户的行为数据,生成推荐列表。
用户的兴趣可能随着时间的改变而改变,我们需要分析用户的行为数据来计算用户对标签商品的实时喜好程度。初始的时候,给每个用户选择的标签都赋予一个初始值。当用户对某标签下的商品产生购买行为以后,根据用户的标签的权重对商品进行随机推荐,生成推荐列表。
主要代码如下:


def ItemSimilarity(user_IDs, item_IDs, item_labels, purchasing_date, alpha):
user_set是一个全局变量,数据类型:字典
global user_set
if type(user_IDs) == int:
user_ID = user_IDs
item_ID = item_IDs
time = int(purchasing_date)
item_label = item_labels
if user_ID not in user_set:
user_set[user_ID] = {}
user_set[user_ID][item_ID] = [time, item_label]
else:
for i in range(len(user_IDs)):
user_ID = user_IDs[i]
item_ID = item_IDs[i]
time = int(purchasing_date[i])
label = item_labels[i]
if user_ID not in user_set:
user_set[user_ID] = {}
user_set[user_ID][item_ID] = [time, label]
C = {}
N = {}
for user in user_set.keys():
for item_i in user_set[user].keys():
time_i, label_i = user_set[user][item_i]
if item_i not in N.keys():
N[item_i] = 0
C[item_i] = {}
N[item_i] += 1
for item_j in user_set[user].keys():
time_j, label_j = user_set[user][item_j]
if item_i == item_j:
continue
if item_j not in C[item_i].keys():
C[item_i][item_j] = 0
C[item_i][item_j] += 1 / (1 + alpha * abs(time_i - time_j))
W = {}
for item_i in C.keys():
W[item_i] = Counter()
for item_j in C[item_i].keys():
W[item_i][item_j] = C[item_i][item_j] / np.sqrt(N[item_i] * N[item_j])
return W
def label_based_recommendation_rank(user_ID,initial_list,T,initial_value,beta):
labels_rank=Counter()
if isinstance(initial_list,int):
labels_rank[initial_list]+=initial_value
else:
for i in initial_list:
labels_rank[i]+=initial_value
if user_ID in user_set:
for item_ID in user_set[user_ID].keys():
item_label=user_set[user_ID][item_ID][1]
purchasing_time=user_set[user_ID][item_ID][0]
labels_rank[item_label]+=1/(abs(T-purchasing_time)*beta)
return labels_rank
ItemSimilarity函数生成商品相似度矩阵,更新用户倒排表。这里主要用到了用户倒排表也就是user_set。
label_based_recommendation_rank函数,根据用户行为和初始标签选择,计算用户对标签的偏好。
2.基于搜索内容的推荐
根据用户搜索的历史行为,选择搜索列表中的商品,随机进行推荐。
主要代码如下:

def search_goods(X):
cur = db.cursor()
cur.execute(f'select lastsearch from login where id={X}')
results=cur.fetchall()
#若无查询记录,直接返回空tuple
if results==():
return ()
else:
results=results[0][0]
cur.execute(f'select id from buygood where goodsname like "%{results}%"')
results=cur.fetchall()
return results
search_goods函数,实现用户X基于搜索的推荐,用户上次搜索的关键词存储在数据库中的表login中。
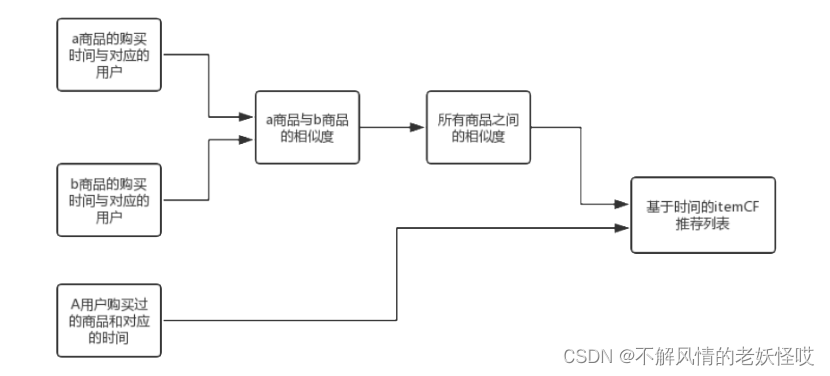
3.基于时间上下文的itemCF
先计算所有商品之间的相似度:ab两商品之间的相似度,由同一时间购买这两个商品之间的人数来衡量,购买的人越多,时间越相近,则ab相似度越高。计算相似度的函数也就是之前的ItemSimilarity函数。根据用户的购买历史,计算某商品和用户购买历史上所有商品的相似度并求和,则为该商品和该用户的相似度。根据商品和用户的相似度,生成推荐列表。
主要代码如下:
def time_based_item_CF(purchased_list, W):
rank = Counter()
if isinstance(purchased_list, float):
purchased_list = [purchased_list]
for i in W.keys():
if i not in purchased_list:
for j in purchased_list:
rank[i] += W[i][j]
if rank.most_common() == []:
return []
else:
return np.array(rank.most_common())[:, 0]
“购买了该物品的人还买了” 功能:
当用户购买某商品后,推荐其他用户购买该商品时经常购买的商品。生成推荐列表,对初始推荐列表进行过滤、排名,得到最终推荐列表。
根据之前产生的物品相似度矩阵W,可以很容易的得到和某商品最相似的(同时购买最频繁)商品列表。
主要代码如下:

def most_similarity_items(W,item_ID):
listt = np.array(W[item_ID].most_common())
if len(listt)==0:
return []
else:
return listt[:,0]