一、河马优化算法
河马优化算法(Hippopotamus optimization algorithm,HO)由Amiri等人于2024年提出的一种模拟自然界中河马觅食行为的新型群体智能优化算法。该算法由Mohammad Hussein Amiri等人于2024年2月发表在Nature旗下子刊《Scientific Reports》上。
HO算法的灵感来源于河马生活中的三种突出行为模式:幼河马由于好奇心而偏离群体的倾向;河马的防御性行为,当受到捕食者攻击或其他生物侵入领地时触发;河马逃离捕食者的行为。HO算法通过自适应地调整搜索空间的分辨率和搜索速度,以快速而准确地找到最优解,具有收敛速度快、求解精度高等特点。
(一)算法流程
-
初始化:在HO算法中,河马代表优化问题的候选解,每个河马在搜索空间中的位置更新代表决策变量的值。
-
位置更新:HO算法使用了一个三阶段模型,结合了河马在河流或池塘中的位置更新、对捕食者的防御策略和逃避方法。这个模型数学上被定义,并且通过这个模型来更新河马的位置。
-
防御和逃避:当河马受到攻击时,它们会展现出防御行为,通过旋转身体面向攻击者并张开有力的下颌。如果防御行为无效或者河马不够强大,它们会以大约30公里/小时的速度快速撤退,通常向附近的水体移动,如池塘或河流。
-
迭代更新:在每次迭代中,根据优化问题的目标函数值更新河马的位置,直到满足停止条件,如最大迭代次数或预设的目标函数值。

参考文献:
[1]Amiri, Mohammad Hussein, et al. “Hippopotamus Optimization Algorithm: a Novel Nature-Inspired Optimization Algorithm.” Scientific Reports, vol. 14, no. 1, Springer Science and Business Media LLC, Feb. 2024, doi:10.1038/s41598-024-54910-3.
原文链接:https://blog.csdn.net/2401_82411023/article/details/136414874
二、多目标河马优化算法
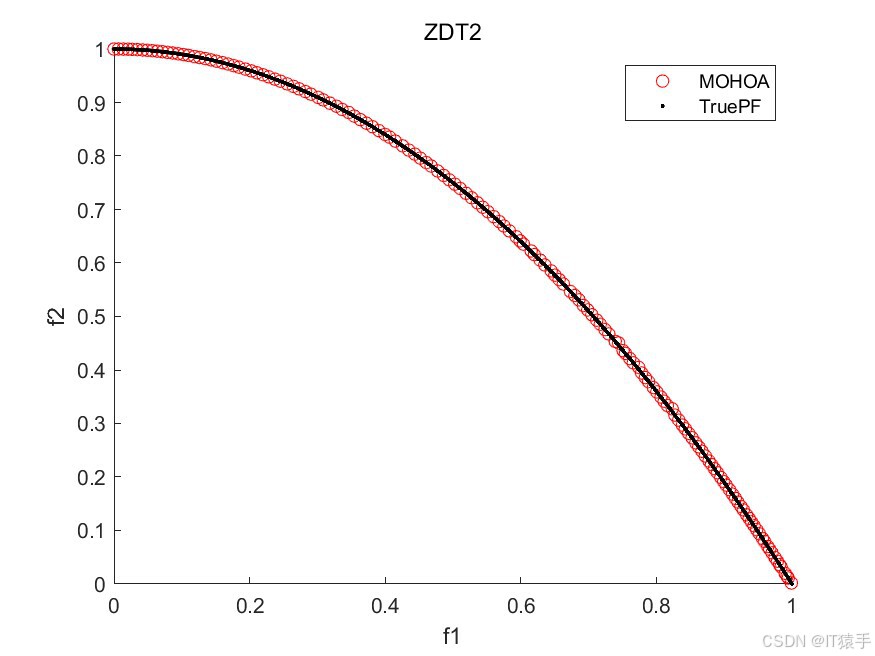
针对单目标优化问题,河马优化算法已显示出其有效性。然而,在面对多目标优化问题时,需要一种能够同时处理多个冲突目标的算法。因此,本文提出多目标河马优化算法(Multi-objective Hippopotamus optimization algorithm, MOHOA)。MOHOA是HO算法的多目标扩展,它能够有效地解决多目标优化问题。
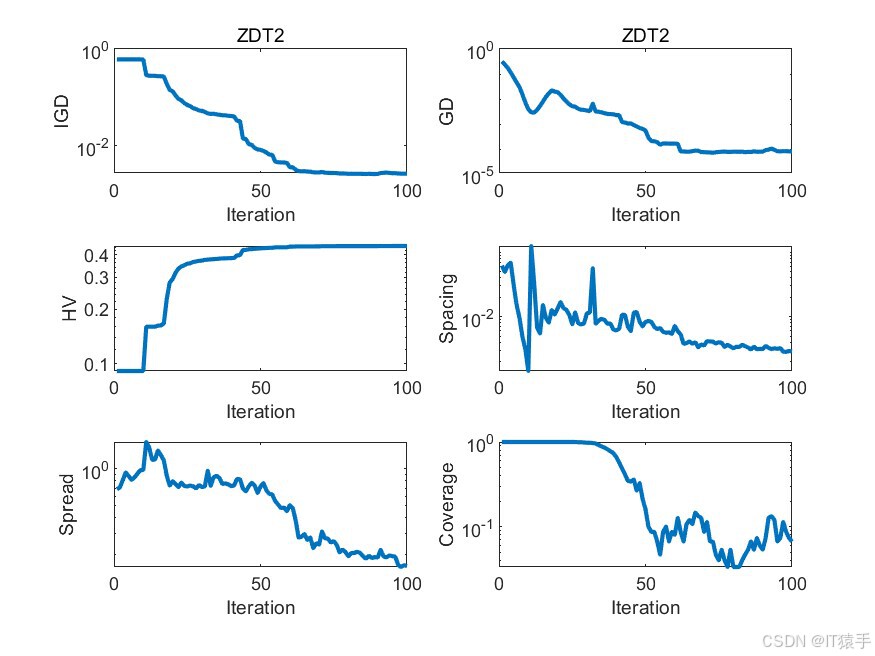
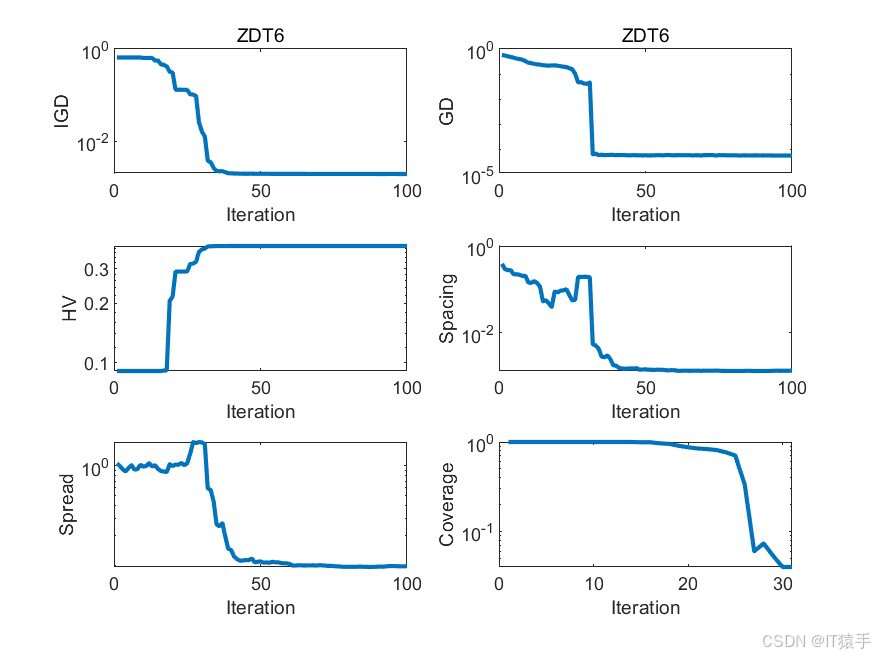
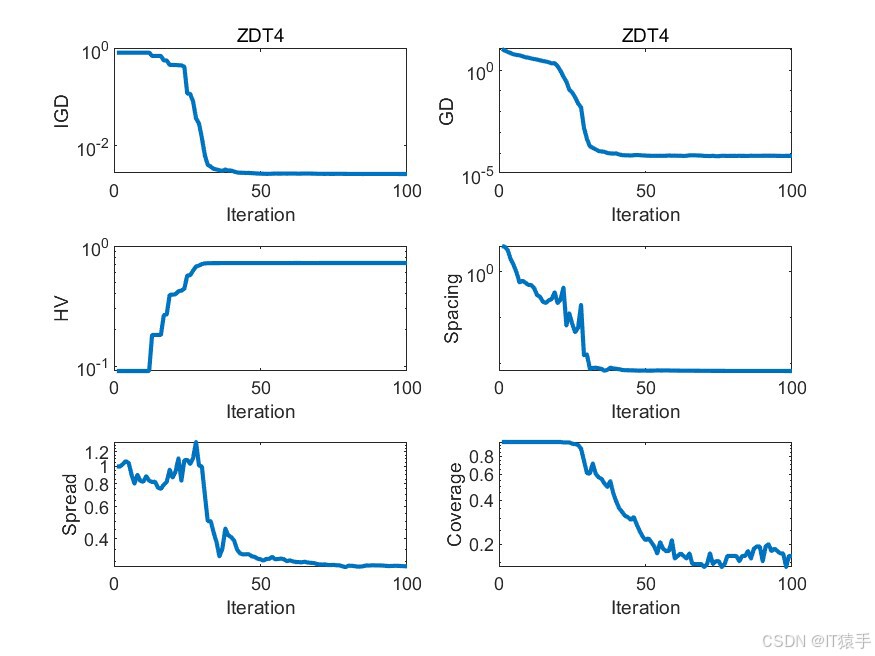
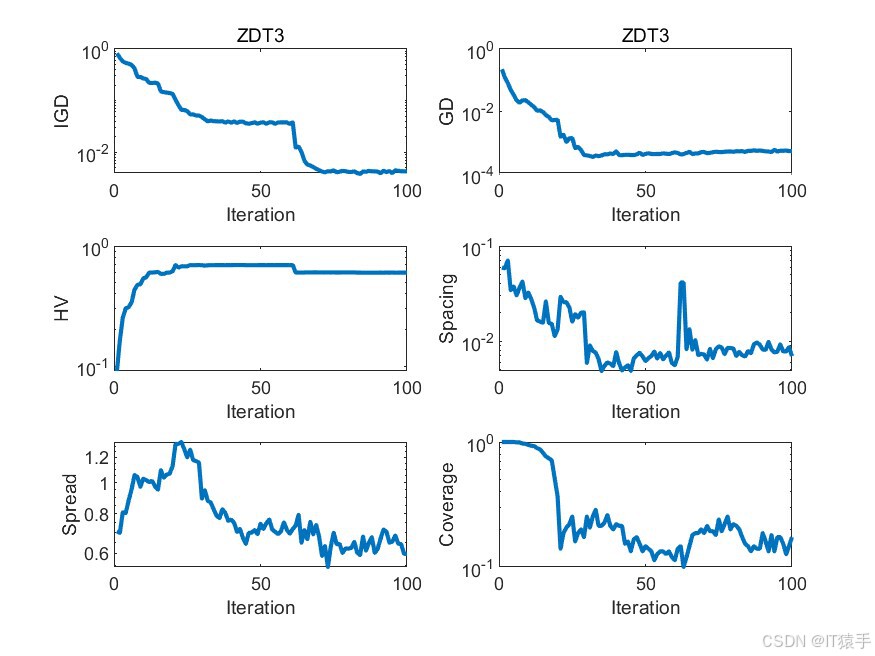
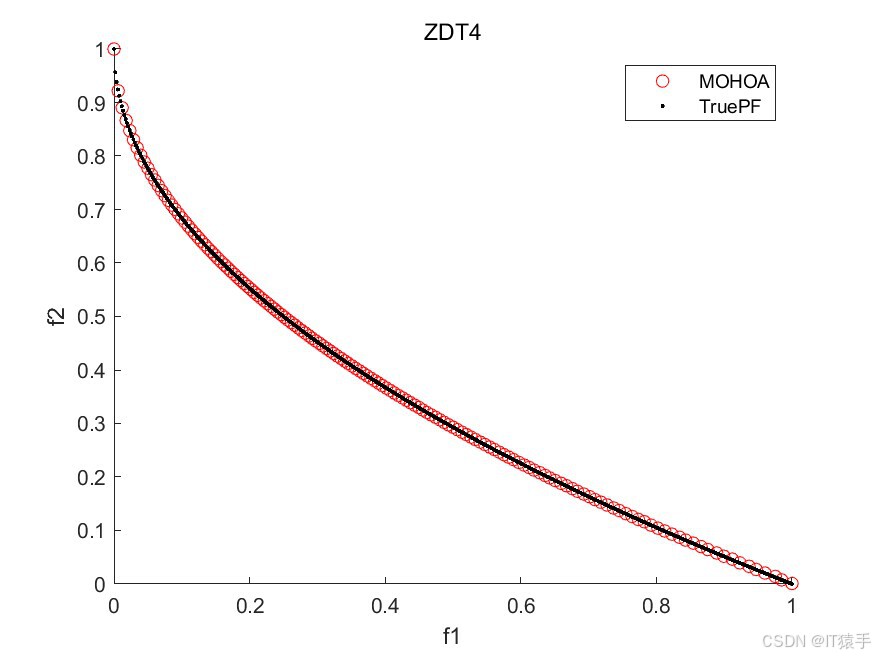
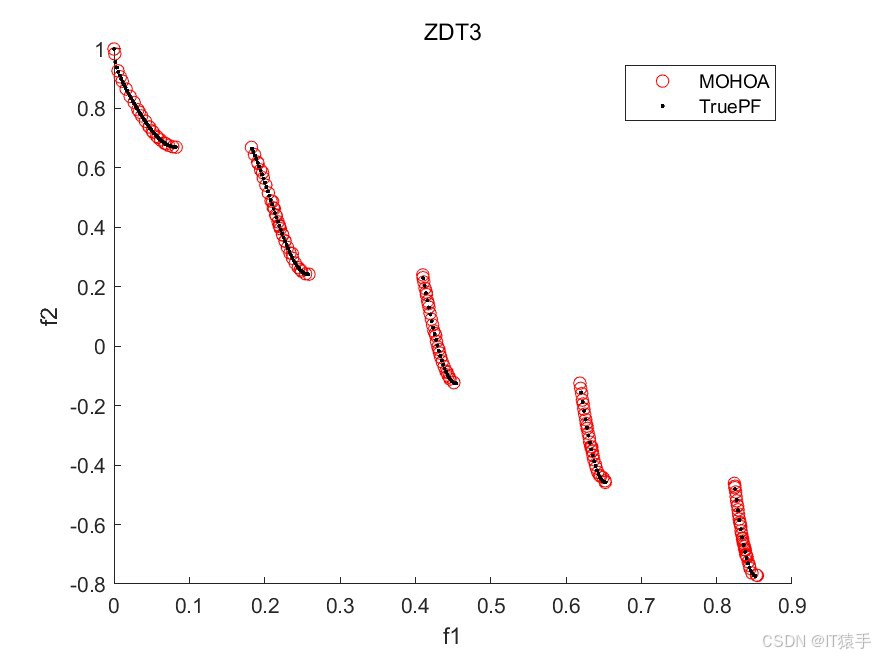
为了评估MOHOA的性能,我们将其应用于一组标准的基准测试函数,这组函数包括ZDT1、ZDT2、ZDT3、ZDT4和ZDT6。这些函数在测试多目标优化算法的效率方面被广泛采用。此外,为了全面评估算法的收敛性和解的多样性,我们使用了六种不同的性能度量指标:GD、IGD、HV、Spacing、Spread和Coverage。通过这些指标的综合分析,我们可以有效地评估该算法在处理多目标优化问题时的整体性能。
MOHOA算法的执行步骤可以描述如下:
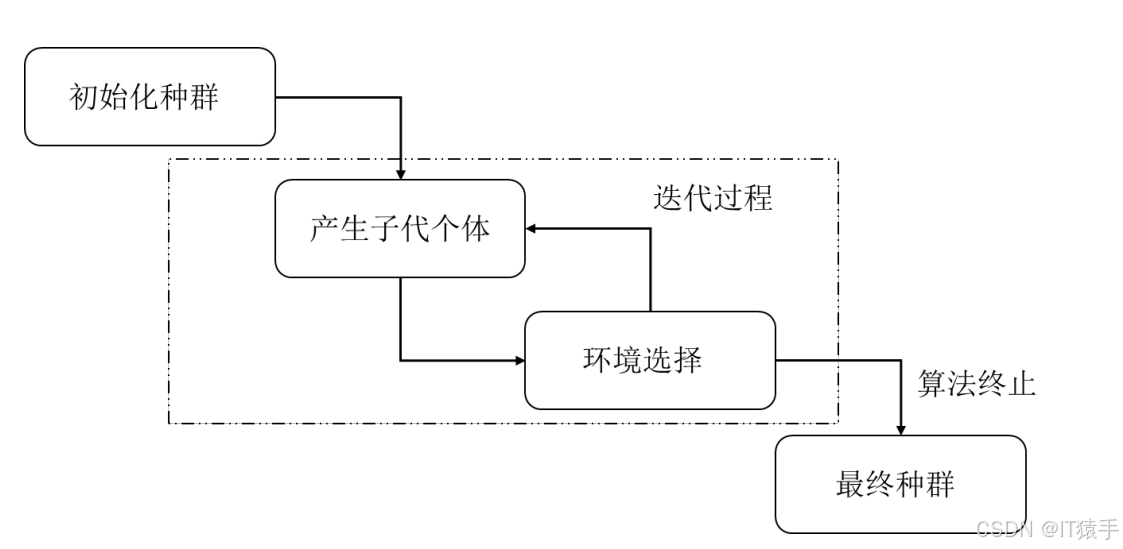
-
初始种群的生成:算法首先随机生成一个初始种群,其中每个个体象征着一个可能的解决方案。
-
个体的评估与筛选:算法对初始种群中的个体进行评估,并根据特定的标准筛选出合适的个体。
-
新个体的产生:通过配对操作,从筛选后的个体中生成新的子代个体。
-
环境选择过程:算法通过环境选择机制对新产生的子代个体进行评估,以确定哪些个体将进入下一代。
-
终止条件的判断:算法会持续进行迭代,直到满足预设的终止条件,这些条件可能包括达到最大迭代次数或解决方案的质量达到既定标准。
-
近似Pareto解集的形成:当满足终止条件后,最后一次环境选择中保留的个体将构成近似的Pareto解集。
在这一过程中,环境选择机制扮演着至关重要的角色。它负责从子代个体中挑选出能够支配其他个体或与其他个体互不支配的精英个体。这些精英个体代表了当前种群中的最优质解。随着算法的不断迭代,每次迭代都能选出新的精英个体,最终能够逼近问题的最优解。
2.1、六种性能评价指标介绍
-
GD(Generational Distance)世代距离:
GD指标用于评价获得的帕累托前沿(PF)和最优帕累托前沿之间的距离。对于每个属于PF的解,找到与其最近的最优帕累托前沿中的解,计算其欧式距离,GD为这些最短欧式距离的平均值。GD值越小,代表收敛性越好,找到的PF与最优帕累托前沿越接近。 -
IGD(Inverted Generational Distance)逆世代距离:
IGD与GD相似,但同时考虑了多样性和收敛性。对于真实的最优帕累托前沿中的每个解,找到与其最近的PF中的解,计算其欧式距离,取平均值而不需开方。如果PF的数量大于最优帕累托前沿的数量,那么IGD就能最完整地表达PF的性能,IGD值越小,代表算法多样性和收敛性越好。 -
HV(Hypervolume)超体积:
HV也称为S metric,用于评价目标空间被一个近似集覆盖的程度,是最为普遍的一种评价指标。需要用到一个参考点,HV值为PF与参考点之间组成的超立方体的体积。HV的比较不需要先验知识,不需要找到真实的帕累托前沿。如果某个近似集A完全支配另一个近似集B,那么A的超容量HV会大于B,因此HV完全可以用于Pareto比较。 -
Spacing:
Spacing是衡量算法生成的非支配解集中各个解之间平均距离的指标。Spacing值越小,表示解集内部的解越密集,多样性越高。 -
Spread:
Spread指标衡量算法生成的非支配解集在Pareto前沿上的分散程度。高的Spread值意味着解集在前沿上分布得更均匀,没有聚集在某个区域。 -
Coverage:
Coverage指标衡量一个算法生成的Pareto前沿覆盖另一个算法生成的Pareto前沿的比例。如果算法A的Coverage指标高于算法B,那么意味着算法A生成的Pareto前沿在某种程度上包含了算法B生成的Pareto前沿。
2.2、部分MATLAB代码
%% 参数说明
%testProblem 测试问题序号
%Name 测试问题名称
%dim 测试问题维度
%numObj测试问题目标函数个数
%lb测试问题下界
%ub测试问题上界
%SearchAgents_no 种群大小
%Max_iter最大迭代次数
%Fbest 算法求得的POF
%Xbest 算法求得的POS
%TurePF 测试问题的真实pareto前沿
%Result 评价指标随迭代次数的变化值
testProblem=2;
[Name,dim,numObj,lb,ub]=GetProblemInfo(testProblem);%获取测试问题的相关信息
SearchAgents_no=200;%种群大小
Max_iter=200;%最大迭代次数
[Fbest,Xbest,TurePF,Result] = MOHOA(Max_iter,SearchAgents_no,Name,dim,numObj,lb,ub);%算法求解
2.3、部分结果
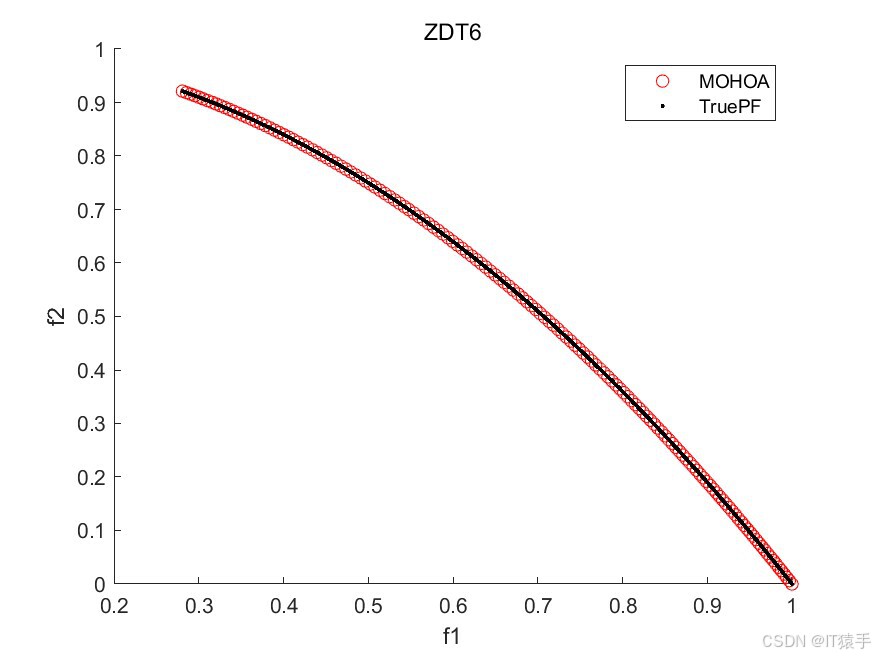
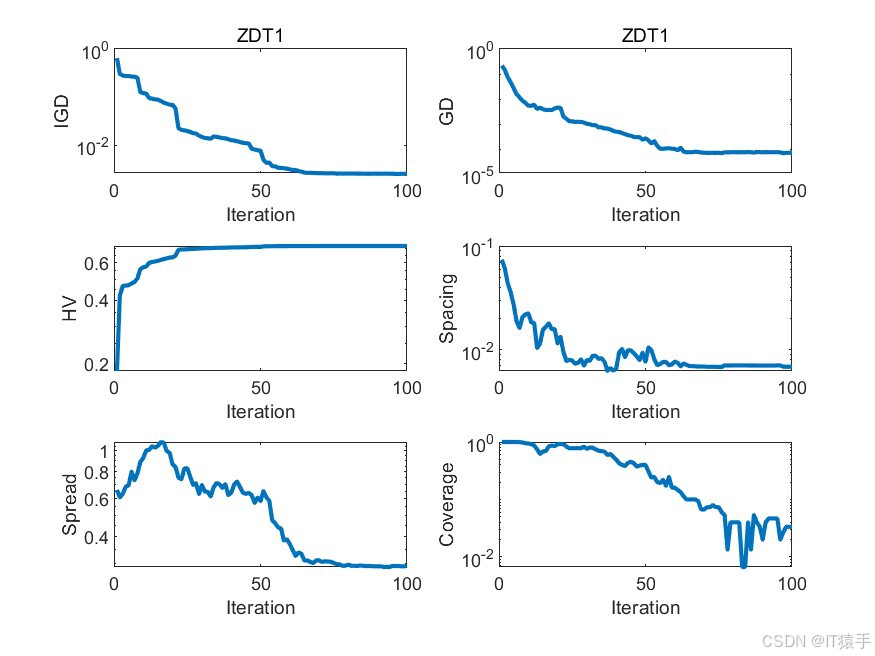
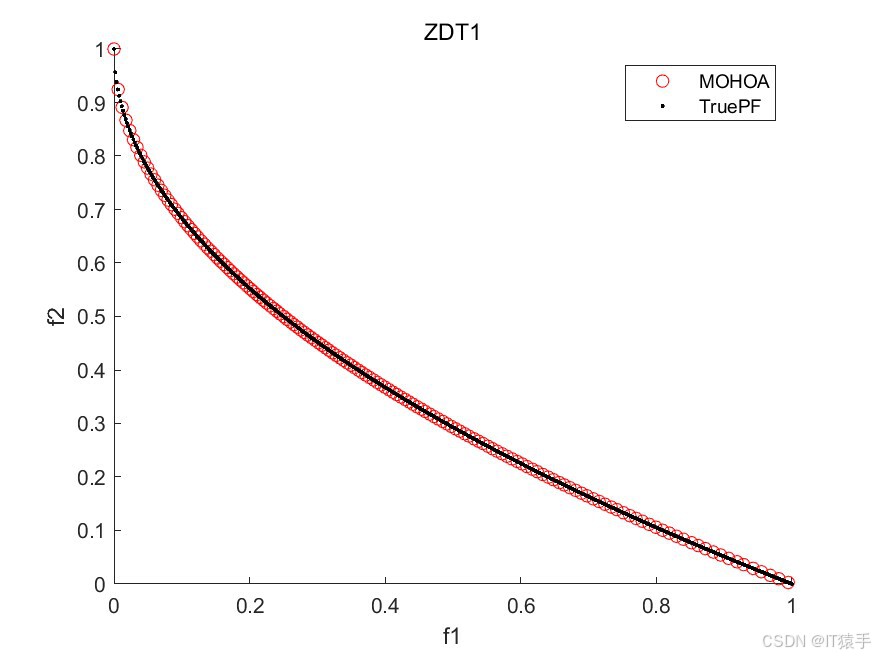
三、完整MATLAB代码
见下方名片