爬虫的基本流程
1. 向网页发起请求
2. 获取获取网页源码
3. 通过正则或者Xpath表达式提取规律信息
4. 获取数据
以本人刚学爬虫时写的代码为案例
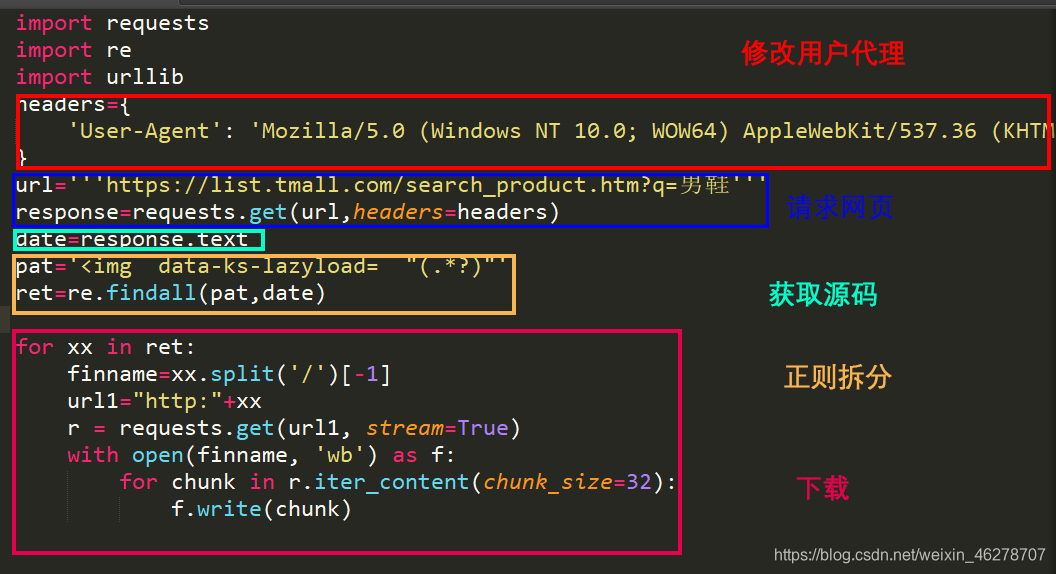
运行基本流程
- 请求网址:爬虫通过请求网址获取网页源码 。 图中蓝色部分表示请求网站并获取其源码 获取的源文件就为网页右键——查看源文件 中的代码一致
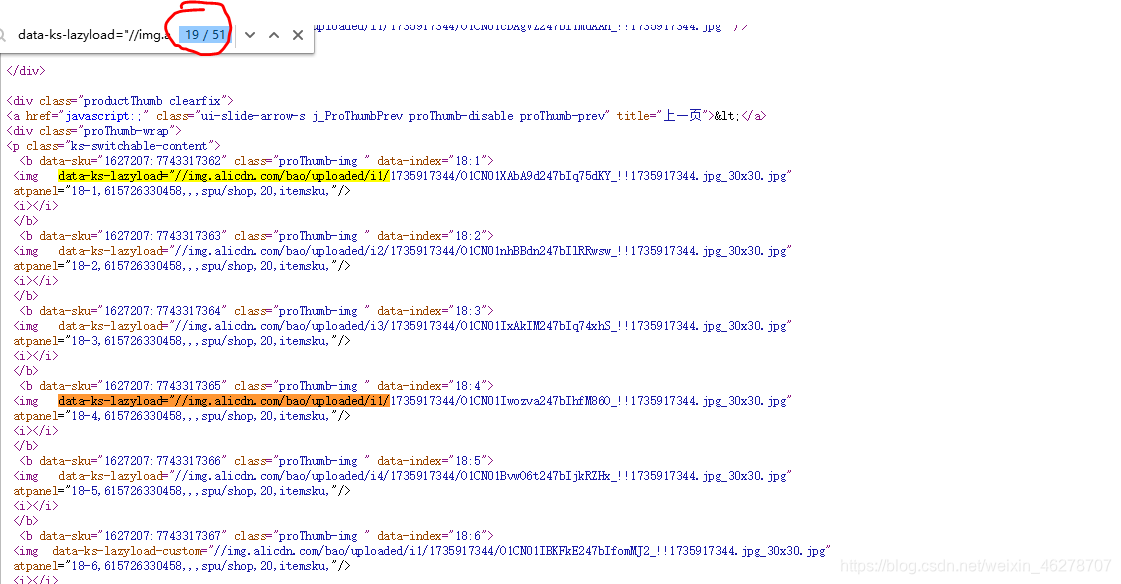
- 拆分源码:在爬取出的源码中找出自己想要的规律信息,如下图获取网页图片信息:
- 获取数据:获取数据后可以将数据保存到数据库,制作图表进行数据分析,或者批量下载图片等等,后续有时间都会持续更新
代码如下(示例):
import requests