线性表
一:概念和性质
-
基本概念
线性表是相同数据类型的n个数据元素的有限序列
A = ( a 1 , a 2 , . . . a i − 1 , a i , a i + 1 , . . . , a n ) A=(a_1,a_2,...a_{i-1},a_i,a_{i+1},...,an) A=(a1,a2,...ai−1,ai,ai+1,...,an)
n表示线性表A的长度,当n=0时,表示A是空表。
其中,元素a1为表头元素,无前驱;an为表尾元素,无后继;ai-1称为ai的直接前驱,ai+1称为ai的直接后继。
-
线性结构特点
在数据元素的非空有限集中:
- 存在唯一的一个被称作"第一个"的数据元素
- 存在唯一的一个被称作"最后一个"的数据元素
- 除第一个外,集合中的每个数据元素均只有一个前驱
- 除最后一个外,集合中的每个数据元素均只有一个后继
二:线性表的实现
-
顺序存储:顺序表
将表中元素顺序存放在一大块连续的存储区中,这样实现的线性结构称为顺序表,顺序表中的元素类型相同,元素之间的顺序关系是由它们的存储顺序体现的。
-
链式存储:链表
将表中元素存放在通过地址连接构造起来的一系列内存中,通过地址的指引来体现数据之间的顺序关系
三:顺序表简介
顺序表是用一组地址连续的存储单元存放一个线性表
-
特点
- 逻辑上相邻的数据元素,其物理地址也相邻,即用物理上的相邻表示逻辑上的相邻
- 实现随机存取,时间复杂度O(1)。即直到一个元素的地址后,就可以通过一次计算出其它任意一个元素的地址。
-
删除数据
线性表的删除是指将第i(1<=i<=n)个元素删除,使长度为n的线性表变成长度为n-1的线性表。为了使逻辑上的顺序相连,需将第i+1至n共(n-i)个元素前移。
在顺序表中,当删除最后一个元素时,移动次数最少,为0;当删除第一个元素时,移动次数最多,为n-1;计算它的平均移动次数,为n/2,所以它的时间复杂度为O(n)。
-
插入数据
线性表的插入是指在第i(1<=i<=n+1)个元素之前插入一个新的数据元素x,使长度为n的线性表变为长度为n+1的线性表。需将第i至第n共(n-i+1)个元素后移。
当在最后一个位置插入元素时,移动次数最少,为0;当在第一个位置插入元素时,移动次数最多,为n次;计算它的平均移动次数,为n/2,所以他的时间复杂度为O(n)。
-
结论
在顺序表中只需插入或删除操作一个元素时,平均移动表的一半元素,当n很大时,效率很低。所以顺序表不适合频繁的插入和删除操作。
-
元素外置顺序表
在Python中,list和tuple两种类型采用了顺序表的实现技术。但list和tuple中可以存放不同的数据类型,这是因为采用了元素位置顺序表,即顺序表中只存储相关元素的地址,地址的类型是相同的,通过地址再区记录数据,而针对数据的操作实际上是针对地址的操作。
四:顺序表结构
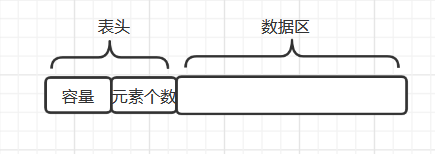
一个顺序表的完整信息包括两部分:
- 数据区:表中的元素集合
- 表头:记录表的整体情况的信息,包括元素存储区的容量和已知元素的个数
这两部分再内存中的存储方式有两种:
-
一体式结构
存储表信息的单元与元素存储区以连续的方式安排再一块存储区里,两部分数据的整体形成一个完整的顺序表对象。适用于元素个数不变的情况。
-
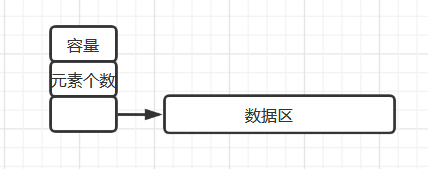
分离式结构
表对象里只保存与整个表有关的信息(即容量和元素个数),实际数据元素存放在另一个独立的元素存储区里,通过链接与基本表对象关联。适用于元素扩充的情况。
-
动态顺序表
动态顺序表:当你执行添加数据操作时,python中的列表自动的扩容,即换一块更大的存储区域,这就是所谓的动态顺序表。
列表就是动态顺序表,采用的是分离式结构,而且列表是元素外置顺序表。
五:顺序表特点
- 优点
- 逻辑相邻,物理相邻:存储空间使用紧凑,不必为结点间的逻辑关系而增加额外的存储开销。
- 可随机存取任一元素
- 方法简单,,各高级语言使用数组来实现,python列表也引用的是数组结构
- 缺点
- 插入、删除操作需要移动大约表中一半的元素,对n大的顺序表效率低。
六:链表
-
特点
用一组任意的存储单元(可以是连续的,也可以是不连续的),存储线性表的数据元素
每个数据元素ai,除存储本身信息外,还需要存储直接后继或直接前驱的信息,即利用地址(指针)实现了用不相邻的存储单元存放逻辑上相邻的元素
-
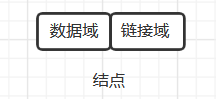
结点结构
数据域:数据元素本身信息
链接域:直接后继或直接前驱的存储地址
-
链表的分类
(1) 单链表
每个结点除包含有数据域外,只设置一个链接域,用以指向其后继结点
(2) 双向链表
每个结点除包含数据域外,设置两个链接域,分别用以指向其前驱结点核后继结点。
-
链表节点的构造
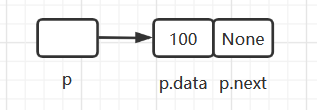
# 创建一个结点类 class Node(object): def __init__(self,data): # 初始化 self.data = data # data为自定义数据 self.next = None # next为下一个结点的地址 p = Node(100)节点结构如下:
七:单链表相关操作
-
初始化单链表
# 创建一个单链表的类 class List: def __int__(self): # 初始化单链表 self.head = None # 表头head为None # 创建一个单链表对象 l1 = List() -
判断是否为空
时间复杂度为O(1)
def is_empty(self): if self.head == None: return True return False -
头插法添加元素
时间复杂度为O(1)
# 头插法 def add_(self, item): s = Node(item) # 修改指针,且顺序不能相反 s.next =self.head self.head = s -
扫描指针和遍历单链表
单链表的特点是每个节点只保存其直接后继的地址,在已知单链表的head首地址的情况下,如果要访问到单链表中的所有结点,需要一个扫面指针
时间复杂度为O(n)
# 循环遍历 def travel(self): p = self.head # 定义指针,p指向第一个结点 while p != None: # 判断指针是否指向了链表末尾 print(p.data) # 打印p指向的结点数据 p = p.next # 指针下移到下一个结点 -
求单链表的表长
对链表中的n个元素扫描一遍,时间复杂度为O(n)
def length(self): p = self.head # 赋初值,p为扫描指针 count = 0 # 计数器 while p != None: count += 1 p = p.next # 指针移动 return count -
按序号查找
按序号查找操作与pos取值有关,设计到全遍历,所以它的时间复杂度为O(n)
在链表中即使知道被访问结点的序号i,也不能像顺序表中那样直接按序号i访问结点,而只能从链表的head出发,顺链域逐个结点向下搜索,直到搜索到第i个结点为止。因此,链表不是随机存取结构。
基本思想:借助扫描指针,从第一个结点开始扫描,判断当前结点是否是第i个,如果是,返回地址,否则继续向后查找,直至找到或链表结束。
def searchpos(self, pos): p = self.head count = 1 if pos < 1: # 判断输入位置是否合法 return None else: while p != None and count!= pos: count += 1 p = p.next return p -
按值查找
按值查找也需要对链表进行全遍历,所以它的时间复杂度为O(n)
def searchitem(self, item): p = self.head while p != None and item != p.data: p = p.next if p.data == item: return p elif p == None: return None -
尾插法建立单链表过程
时间复杂度为O(n)
def append(self, x): p = self.head while p.next != None: # 首先要把指针达到链表的末尾 p = p.next s = Node(x) # 生成结点 p.next = s # 修改链接 -
在指定位置插入元素
时间复杂度为O(n)
def insert(self, pos, x): p = self.head count = 0 if pos >= self.length(): # 如果pos位置小于1,则不合法 return -1 # 插入失败返回-1 while count < pos: # 寻找插入点 p = p.next count += 1 s = Node(x) s.next = p.next p.next = s return 1 # 插入成功返回1 -
按值删除元素
def remove(self, item): p = self.head if p.data == item: # 如果删除的是第一个结点,需要单独处理 self.head = p.next else: while p != None and p.data != item: pre = p p = p.next pre.next = p.next return p -
单链表特点
- 它是一种动态结构,整个内存空间为多个链表公用
- 不需要预先分配空间
- 链接域占用额外存储空间
- 不能随机存取,查找速度慢
八:双链表的定义和描述
-
双链表定义
每个结点包含两个链接域,一个指向直接前驱(prior),一个指向直接后继(next)。如下图所示:

双链表由头指针head唯一确定
将双链表中的头结点和尾结点链接起来可以构成循环链表,并称之为双向循环链表。如下图所示:
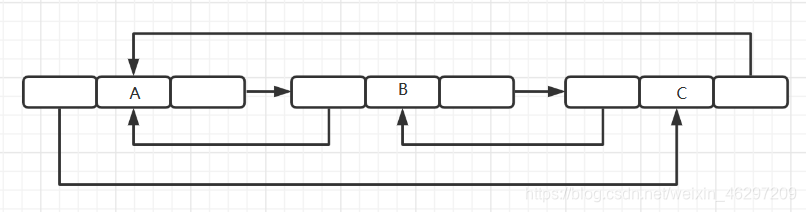
-
双向链表结点类的描述
class DLNode: def __init__(self, data): self.data = data self.prior = None self.next = None -
某个结点前插入结点
注:注意赋值的顺序
def insert(self, item): p = self.head while p.data != item: p = p.next s = DLNode() s.priot = p.prior p.prior.next = s s.next = p p.prior = s return p -
删除某结点
def remove(self, item): p = self.head while p.data == item: p.next.prior = p.prior p.prior.next = p.next
九:顺序表和链表的比较
-
从空间上考虑
- 当线性表的长度变化较大时,难以估计其存储规模,以采取动态链表作为存储结构为好。
- 当线性表的长度变化不大时,为了提高存储密度,以采取顺序表作为存储结构。存储密度是指结点数据本身所占的存储量和整个结点结构所占的存储量之比。
-
从时间上考虑
- 如果线性表的操作主要是进行按序号访问数据元素,很少做插入、删除操作,采用顺序表为宜。
- 对于频繁地进行插入和删除的线性表,采用链表存储结构为宜。
十:线性表的应用
-
顺序表实现合并问题
已知两个长度分别为m和n的升序序列,实现将它们合并为一个长度为m+n的升序序列,并给出所写的程序时间复杂度。
la = [1,3,5,7] lb = [2,4,6,8,10,11] lc = [] def Merge(la, lb, lc):ll i = 0 j = 0 while i <len(la) and J < len(lb): if la[i] > lb[j]: lc.append(lb[j]) j += 1 else: lc.append(lb[i]) i += 1 if i >= len(la): lc.extend(lb[j:]) elif j >= len(lb): lc.extend(la[i:])时间复杂度为O(m+n)
-
链表实现合并问题(采摘结点法)
# 定义结点类 class Node: def __init__(self, data): self.data = data self.next = None # 定义结点类 class List: def __init__(self): self.head = None def is_empty(self): return self.head def append(self, data): p = self.head n = Node(data) if self.head == None: self.head = n else: while p.next != None: p = p.next p.next = n def search(self): p = self.head while p != None: print(p.data) p = p.next def Merge(la, lb, lc): pa = la.head pb = lb.head tail = lc.head while pa != None and pb != None: if pa.data <= pb.data: if lc.head == None: lc.head = pa else: tail.next = pa tail = pa pa = pa.next else: if lc.head == None: lc.head = pb else: tail.next = pb tail = pb pb = pb.next if pa != None: tail.next = pa elif pb != None: tail.next = pb # 创建la,lb链表 la = List() lb = List() data = int(input("请输入链表a的值,输入-1结束")) while data != -1: la.append(data) data = int(input("请输入链表a的值,输入-1结束")) data = int(input("请输入链表b的值,输入-1结束")) while data != -1: lb.append(data) data = int(input("请输入链表a的值,输入-1结束")) # 查看lc列表 lc = List() Merge(la, lb, lc) print(lc.search()) -
列表实现顺序表的基本操作
class seqlist: # 创建一个顺序表类 def __init__(self, max_space=30): self.max_space = max_space # 设置列表的最大长度 self.lst = max_space*[0] # 划分列表空间 self.length = 0 # 记录长度 # 增加元素 def append(self, item): # 判断是否已超出空间最大长度 if self.length >= self.max_space: print("已超出最大存储空间") else: self.lst[self.length] = item self.length += 1 # 遍历元素 def printdata(self): for i in range(self.length): print(self.lst[i], end=" ") # 按值来查找元素 def searchdata(self, data): for i in range(self.length): if self.lst[i] == data: print("元素存在") return i if i == self.length: return False # 按索引插入元素 def insert(self, index, item): if self.length == self.max_space: print("顺序表已满") else: if index < 0 or index > self.length: print("输入字符为无效字符") else: i = self.length - 1 while i >= index: self.lst[i+1] = self.lst[i] i -= 1 self.lst[index] = item self.length += 1 # 按索引删除元素 def deleteindex(self, index): if self.length == 0: print("列表为空") else: if index < 0 or index > self.length: print("输入字符无效") else: i = index while i < self.length: self.lst[i] = self.lst[i + 1] i += 1 self.length -= 1 # 按值删除元素 def deletedata(self, data): i = self.searchdata(data) if i: self.deleteindex(i)