yolov5目标检测
最近刚开始学目标检测,用yolov5训练自己的数据集,踩了不少坑,记录一下。
现有数据说明
我这里的数据是有图片和annotation的json文件。
其中,.json文件格式如下:
{
"images":[
{"height":图片高,
"width": 图片宽,
"id": 1(图片标序)
"file_name": 图片名称(如:XXX.jpg)
},
{"height": 600
"width": 800
"id": 2
"file_name": "BCAsamples00012_0_0_0_800_600.png"
},
...
]
"annotations":[
{"iscrowd": 0,
"image_id":所在图片的id,与"images"中的"id"相同,
"bbox":[x_min, y_min, width, height],
"segmentation":[x1,y1,x2,y2,...]这个含义暂时不清楚,
"category_id":目标类别,
"id": 1 锚框标序,
"area":width*height 锚框面积,
},
{"iscrowd": 0,
"image_id": 45,
"bbox":[247.0,444.0,40.0,149.0],
"segmentation":[[258,452,255,460,250,467,247,474]],
"category_id":3,
"id": 2,
"area": 1069
},
...
]
"categories":[
{"id": 0 类别id,
"name": 类别名称,
"supercategory": ,
},
{"id": 1,
"name":"Corrosion",
"supercategory":"Corrosion"
},
...
]
}
标签表示为txt
数据集准备
数据集图片分为训练集和验证集,标签集(labels)同样为训练集和验证集,命名必须与图片名称相同,且标签集名称必须为labels。标签中,每张图片对应一个的.txt文档,文档名称与图片名称相同,如果一张图片中没有锚框,仍需有对应的.txt文档,内容为空。
-images(图片,命名可修改)(.jpg or .png or…)
- train (训练集,命名可修改)
- val (验证集,命名可修改)
-labels(标签,命名不可修改)(.txt)
- train (训练集标签,必须与images中训练集同名)
- test (训练集标签,必须与images中验证集同名)
其中,标签内容如下:
| category | x _center_normalized | y_center_normalized | width_normalized | height_normalized |
|---|---|---|---|---|
| 类别 | 锚框中心归一化x坐标 | 锚框中心归一化y坐标 | 锚框归一化宽 | 锚框归一化高 |
如:
其中,第一列为类别,后四列为[x_center_normalized, y_center_normalized, width_normalized, height_normalized]
如果一张图片中有多个锚框,则依次按行写入
【注】:
此处锚框坐标必须进行归一化!!!!
即,其中image_width为图片宽,image_height为图片高,[x_center, y_center, width, height]为锚框坐标信息,[x_center_normalized, y_center_normalized, width_normalized, height_normalized]为归一化后的锚框坐标信息

x_center_normalized=x_center/image_width
y_center_normalized= y_center/image_height
width_normalized=width/image_width
height_normalized=height/image_height
由于我的原始数据为.json文件,故用一个函数,将其转存为.txt文件(由于我的数据集较大,设置了一个进度条,但是设计的不咋地,自动忽略):
import json
import time
import sys
import numpy
# 对单张图片进行处理
def json_to_txt(slice_image,slice_data):
# 处理图片信息
slice_image_content=""
slice_image_width=slice_image['width']
slice_image_height=slice_image['height']
# image_detects=[image_detect for image_detect in slice_data['annotation'] if image_detect['id']==slice_image['id']]
slice_annotations = [s_a for s_a in slice_data['annotations'] if s_a['image_id']==slice_image['id']]
# print(slice_annotations)
# print(slice_image['id'], '+++++++++++++++++++++++++++++++++++++++++')
for slice_annotation in slice_annotations:
# print('image_id', slice_annotation['image_id'])
# print('id', slice_image['id'])
# print('----------------------------------')
category_id=slice_annotation['category_id']
bbox=slice_annotation['bbox']
# 获取bbox[x_center,y_center,width,height]并进行归一化
x_center=(bbox[0]+bbox[2]/2)/slice_image_width
y_center=(bbox[1]+bbox[3]/2)/slice_image_height
width=bbox[2]/slice_image_width
height=bbox[3]/slice_image_height
slice_image_content += str(category_id)+" "+str(x_center)+" "+str(y_center)+" "+str(width)+" "+str(height)+"\n"
return slice_image_content
# 对未归一化的txt数据进行归一化
def part_normalized_txt(slice_image, slice_data):
file_name = slice_image['file_name'].split('.png')[0]
txt = numpy.loadtxt(txt_path+file_name+'.txt')
# print('--------------------------')
# print(txt_path+file_name, 'n','txt',txt)
vol=txt.ndim
l=txt.shape
# print(l[0])
if vol ==1 and l[0]!=0:
if txt[1]>1 or txt[2]>1 or txt[3]>1:
slice_image_content=json_to_txt(slice_image,slice_data)
# print(txt_path+file_name,'\n','content',slice_image_content)
with open(txt_path+file_name+'.txt', 'w') as f:
f.write(slice_image_content)
elif vol>1:
# (v,c)=txt.shape
for i in range(vol):
if txt[i][1]>1 or txt[i][2]>1 or txt[i][3]>1:
slice_image_content=json_to_txt(slice_image,slice_data)
# print(txt_path+file_name,'\n','content',slice_image_content)
with open(txt_path+file_name+'.txt', 'w') as f:
f.write(slice_image_content)
break
# 对所有图片进行处理
def jsons_to_txts(slice_json, txt_path):
# 读取json文件
with open(slice_json, 'r') as slice_json_file:
slice_data = json.load(slice_json_file)
# 计时
image_total_num=len(slice_data['images'])
count=0
start_time=time.time()
last_update_time = start_time
# 读取切片数据
for slice_image in slice_data['images']:
# 打印进度条
count+=1
progress=(count/image_total_num)*100
current_time=time.time()
if current_time-last_update_time > 30:
elapsed_time=current_time-start_time
if progress>0:
estimated_remaining_time=(elapsed_time/progress)*(100-progress)
else:
estimated_remaining_time=0
sys.stdout.write('\r')
progress_bar = '[' + '=' * int(progress / 2) + ' ' * (25 - int(progress / 2)) + ']'
print(f'Progress: {progress_bar} {progress:.2f}% | Elapsed: {elapsed_time:.2f}s | Remaining: {estimated_remaining_time:.2f}s', end='')
# 更新上一次更新时间
last_update_time = current_time
# 直接从.json转换到归一化txt
slice_image_content=json_to_txt(slice_image,slice_data)
# 写入txt文件
file_name = slice_image['file_name'].split('.png')[0]
with open(txt_path+file_name+'.txt', 'w') as f:
f.write(slice_image_content)
# 直接从.json转换到归一化txt 结束
# # 由于我之前的txt文件有一些未归一化(因为运行中断),故此处选择未归一化的txt进行归一化
# part_normalized_txt(slice_image, slice_data)
# 打印最后一次进度条
count+=1
progress=(count/image_total_num)*100
current_time=time.time()
if current_time-last_update_time > 30:
elapsed_time=current_time-start_time
if progress>0:
estimated_remaining_time=(elapsed_time/progress)*(100-progress)
else:
estimated_remaining_time=0
sys.stdout.write('\r')
progress_bar = '[' + '=' * int(progress / 2) + ' ' * (25 - int(progress / 2)) + ']'
print(f'Progress: {progress_bar} {progress:.2f}% | Elapsed: {elapsed_time:.2f}s | Remaining: {estimated_remaining_time:.2f}s', end='')
# 更新上一次更新时间
last_update_time = current_time
if __name__=='__main__':
slice_json= r'/root/autodl-tmp/project/building_defect_detect/data/test_xml_slice.json' # or 'train_xml_slice.json' 训练集(.json)路径
txt_path = r'/root/autodl-tmp/project/building_defect_detect/data/labels/test_data_slice/' # 训练集(images)路径
jsons_to_txts(slice_json, txt_path)
print('\n get slice test txt data done')
slice_json1=r'/root/autodl-tmp/project/building_defect_detect/data/train_xml_slice.json' # or 'train_xml_slice.json' 测试集(.json)路径
txt_path1 = r'/root/autodl-tmp/project/building_defect_detect/data/labels/train_data_slice/' # 测试集(images)路径
jsons_to_txts(slice_json1, txt_path1)
print('\n get slice train txt data done')
编辑配置
下载yolov5:下载地址:https://github.com/ultralytics/yolov5
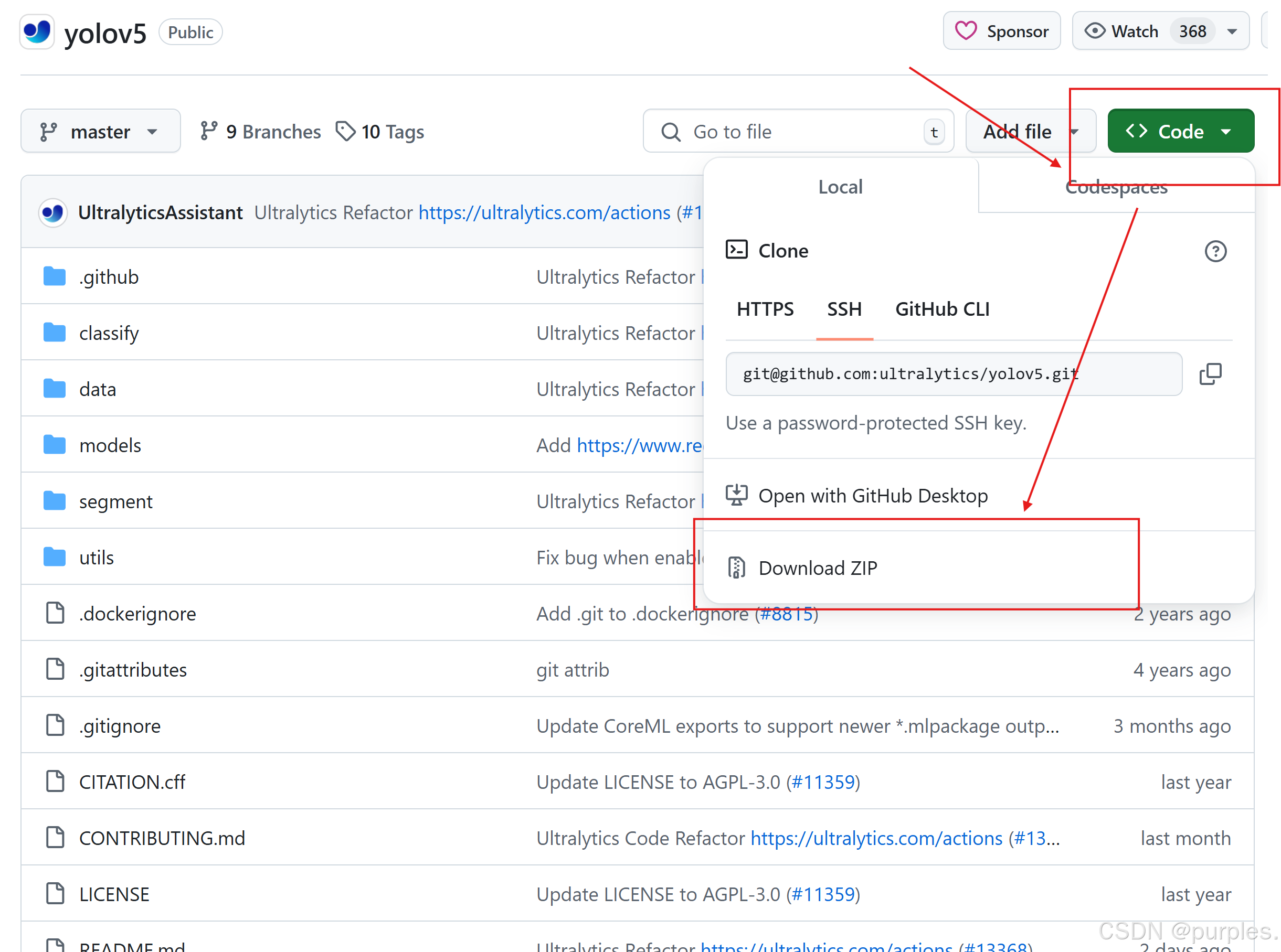
此处使用yolov5n.pt模型,下载地址:https://github.com/ultralytics/yolov5
此处将yolov5n.pt放在yolov5\weights目录下,也可以放在其他位置,如yolov5等,后续配置对应即可
data.yaml配置
打开./yolov5/data/,找到coco128.yaml并复制一份,重命名为mydata.yaml(此处可自行命名,后面配置时名称对应即可)
对mydata.yaml进行编辑:
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: /root/autodl-tmp/project/building_defect_detect/data # dataset root dir
train: images/train_data_slice # train images (relative to 'path')
val: images/test_data_slice # val images (relative to 'path')
test: # test images (optional)
# train_labels: data/labels/train_slice
# val_labels: data/labels/test_slice
# Classes
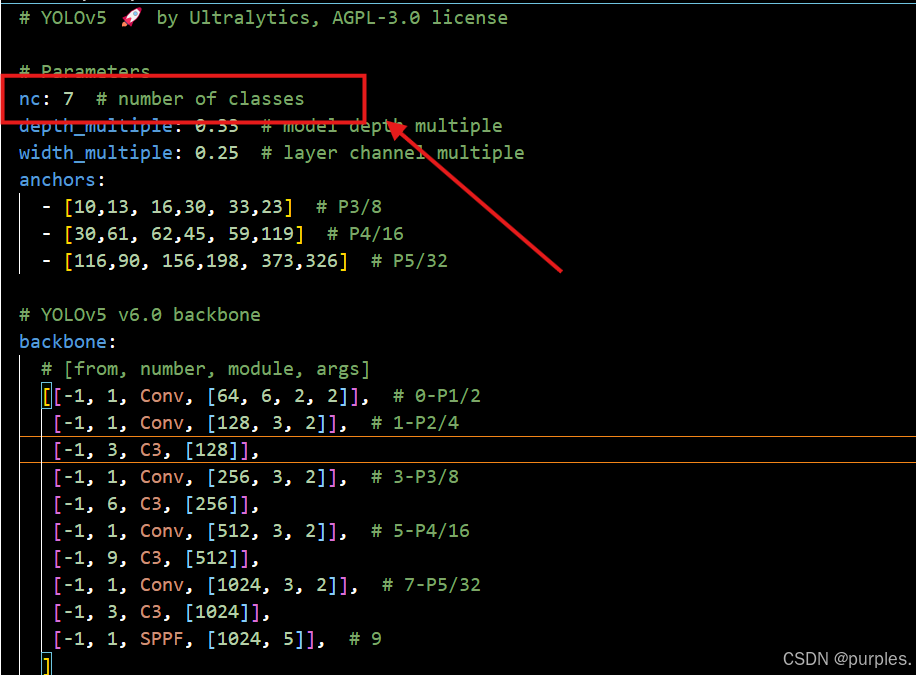
nc: 7 # number of classes
names:
0: Spalling
1: Corrosion
2: Peeling
3: Cracks
4: Corrosion Stain
5: Crazing
6: Repaired Crack # class names
其中,
path为数据集与标签集所在文件夹路径,
train为训练集(\images\train)所在相对路径,
val为验证集(\images\val)所在相对路径
test为测试集所在路径,若没有测试集就不用填
nc为类别数
names为类别名称,还可写为(顺序与类别id对应):
names: [ 'Spalling', 'Corrosion', 'Peeling', 'Cracks', 'Corrosion Stain', 'Crazing', 'Repaired Crack' ]
由于此处只写了images的路径,会自动搜索同目录下名为labels的标签集,故标签集名称必须为labels,其中训练集和验证集必须与训练集中的对应,标签集名称与图片名称相同。
yolov5n.yaml配置
在/yolov5/models中找到模型对应的.yaml文件,此处为yolov5n.yaml,将其中的nc修改为类别数即可:
train.py配置
在yolov5文件夹中打开train.py,找到如下进行配置(很多其他的方法是运行时设置(见服务器远程VSCode跑代码),我是直接在这里改的):
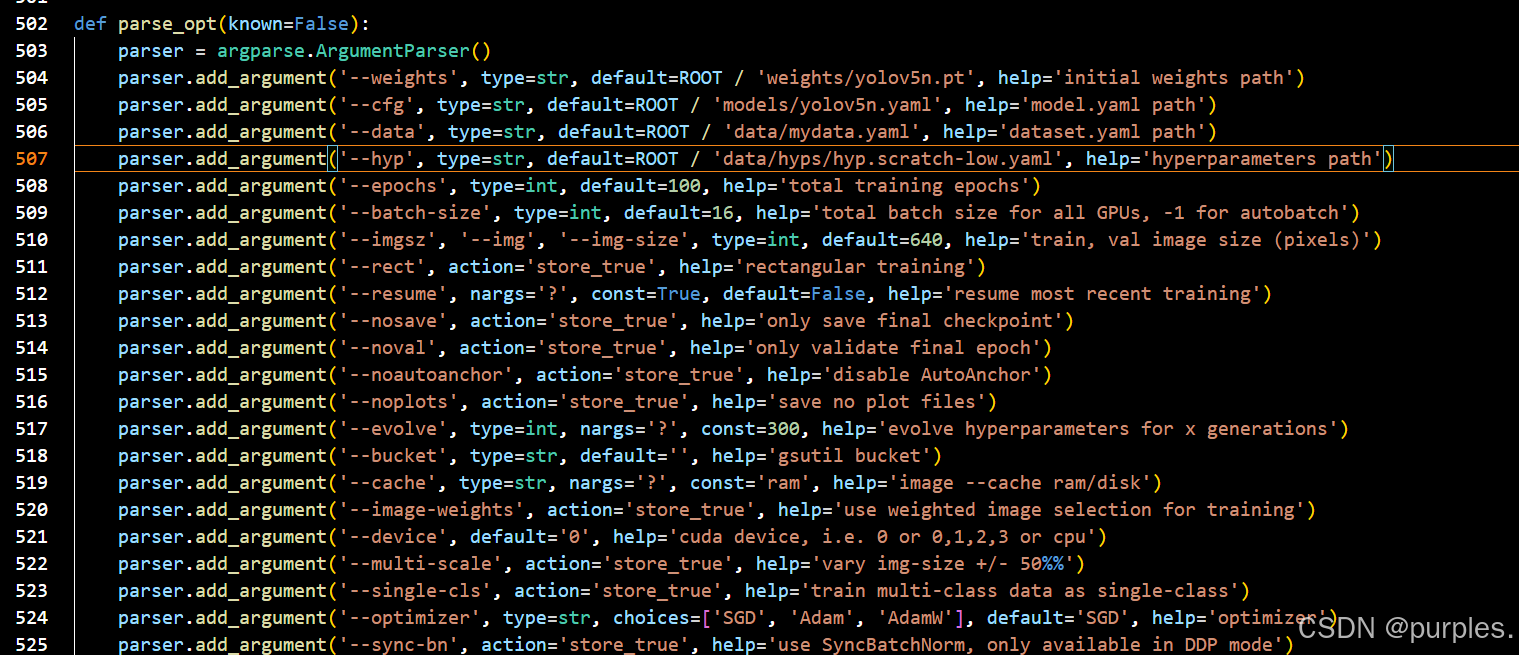
其中,
--weights 为模型位置,此处为'weights/yolov5n.pt',写yolov5n.pt的位置即可
--cfg为模型的.yaml文件位置,此处为'models/yolov5n.yaml'
--data为数据集的.yaml文件位置,此处为'data/mydata.yaml'
'--epochs'为迭代次数
'--device'为使用gpu或cpu,,可写0 or 0,1,2,3 or cpu
其余参数可自行查找,按需修改
此处服务器有三张卡(0,1,2为三张卡序号):
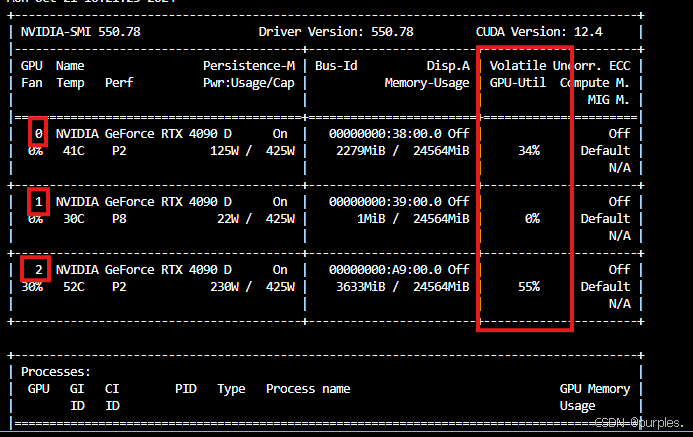
使用三张卡来跑:-- device 0,1,2,即,使用0,1,2三张卡。另外,因为batch-size均分给三张卡,因此,必须为使用的卡的数量的整数倍
此处设置为--batch-size 15
设置完成后,运行train.py即可。
trouble shooting
总结一下遇到的问题,解决方法不一定对,但是能跑通了至少,有不对的欢迎指出,感谢!
1. requests.exceptions.ProxyError: (MaxRetryError(“HTTPSConnectionPool(host=‘huggingface.co‘, port
报错内容:
requests.exceptions.ProxyError: (MaxRetryError(“HTTPSConnectionPool(host=‘huggingface.co’, port=443): Max retries exceeded with url: /bert-base-uncased/resolve/main/config.json (Caused by ProxyError(‘Unable to connect to proxy’, OSError(0, ‘Error’)))”), ‘(Request ID: b738272e-359a-4cb6-bb90-0250b631d263)’)
此处为下载模型时出错,主要为从hunggingface.co下载模型时出错,可能是网络问题,类似于从github下载网络超时。
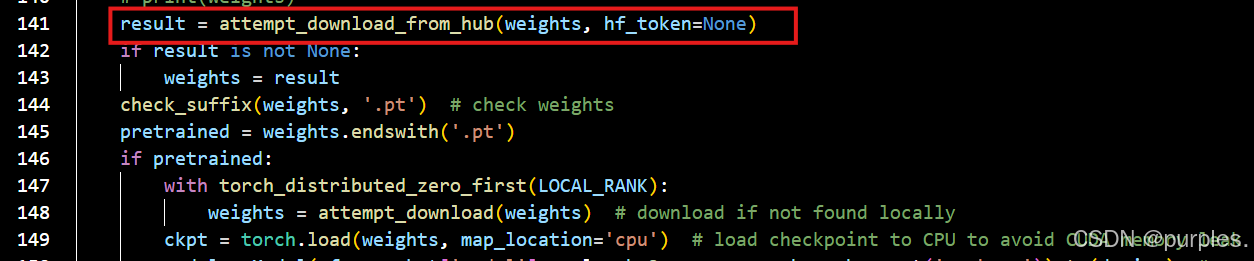
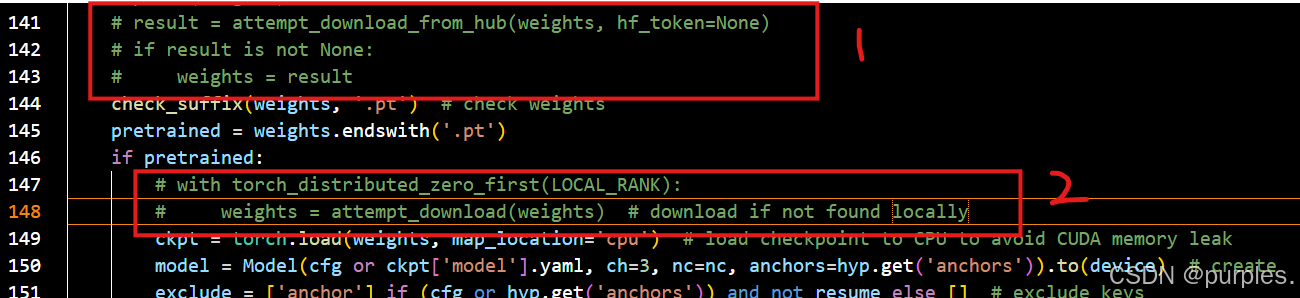
检查了一下,发现这里下载的模型是yolov5n.pt,而我已经下载过该模型了,按理说应该是本地没找到且下载失败才会报错,但是这里不知道为什么没有查找本地。于是这里我就直接注释掉了下载模型部分。
其中,框1为下载模型并判断模型是否为空,框2为在本地没找到时下载模型
2. All labels empty in {cache_path}/train.cache, can not start training.
报错内容:
All labels empty in {cache_path}, can not start training. {HELP_URL}"AssertionError: train: All labels empty in {train_data_path}
这是由于数据标签有误,我这里是因为标签没有归一化,具体处理方法见前面.txt准备方法
.json直接训练(不保证能用)
这里使用数据标签的xml.json文件进行yolo训练,是看见别人的用法,具体我也不是很清楚,把配置方法说一下:
数据准备
数据集分为训练集和验证集,标签为json文件(训练集和验证集的),也就是我的最初数据。
编辑配置
数据.yaml文件,对应于上一个方法中的mydata.yaml:
train: ./data/images/train_data_slice # 训练数据集路径
val: ./data/images/test_data_slice # 验证数据集路径
test: ./data/images/test_data_slice # 验证数据集路径
train_ann: ./data/train_xml_slice.json
val_ann: ./data/test_xml_slice.json
test_ann: ./data/test_xml_slice.json
# 类别名称
nc: 7 # 类别数
names: [ 'Spalling', 'Corrosion', 'Peeling', 'Cracks', 'Corrosion Stain', 'Crazing', 'Repaired Crack' ]
其中,
train为训练集(\images\train)所在路径,
val为验证集(\images\val)所在路径
test为测试集所在路径,若没有测试集就不用填
train_ann为训练集annotation的.json路径
val_ann为验证集annotation的.json路径
test_ann为测试集annotation的.json路径
nc为类别数
names为类别名称
训练文件,运行以下文件:
import os
import cv2
import random
import numpy as np
import torch
from ultralytics import YOLO
# Load a model
model = YOLO("yolov5n.pt")
# Train the model
train_results = model.train(
data="./mydata.yaml", # path to dataset YAML
epochs=10000, # number of training epochs
imgsz=(800, 600), # training image size
device=[2], # device to run on, i.e. device=0 or device=0,1,2,3 or device=cpu
)
path = model.export(format="onnx")
将其中参数修改为数据集对应参数即可。
由于此方法不是我自己改的,其他地方有没有修改我就不清楚了,不知道能不能通用