Go中Map底层原理剖析_go map底层实现-CSDN博客
目录
五、 go语言实现和扩展后的map底层原理: runtime包下map.go文件
Map 键值对key,value
注意: map唯一确定的key值通过哈希运算得出哈希值
1)key值必须唯一,所以map不可重复
2)key值不能是动态变化的值类型,不能是切片类型,map类型。也不能是嵌套的切片,map类型。

一、 map的声明及初始化:
1) mapObject := map[ string ] string{}
2) mapObject := make(map[ string ] string , 10)
通过make关键字设定了容量的参考值,并且map没有cap()查看容量方法
3)var mapObject map[ string] int //对象地址为空
仅声明了类型,并没有初始化的操作,所以没有在内存中开辟空间。
注意) : mapObject_zhiZhen := new(map[ string ] string) //对象地址为空
虽然new关键字会初始化对象,但是map类型对象初始化的默认值为nil,类比于java,就像引用类型对象默认的初始化值为null。

二、 map的增删改查操作:
mapObject := map[string ] string { }
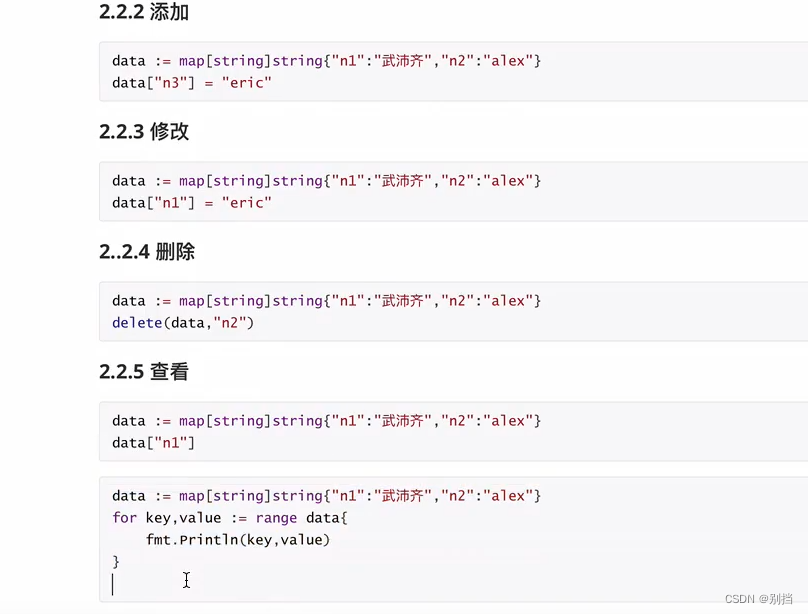
添加 :
修改:
mapObject[ "key1" ] = "value1"
删除:
delete(mapObject,"key1")
查看:
for key,value := range mapObject{
fmt.Println(key,value)
}
三、 map的赋值操作与切片对比:
v1 := map[ string ] string{ }
v2 := v1
v1,v2 指向的是同一个内存地址,无论是否发生扩容机制。
v3 := [ ] int{11,22,33 }
v4 := append(v3,44)
v3,v4内存地址发生改变,究其原因是v3切片容量已经满了(容量默认为v3的元素个数3),v4就会开劈新的内存空间创建新的切片对象并复制原有的所有元素。
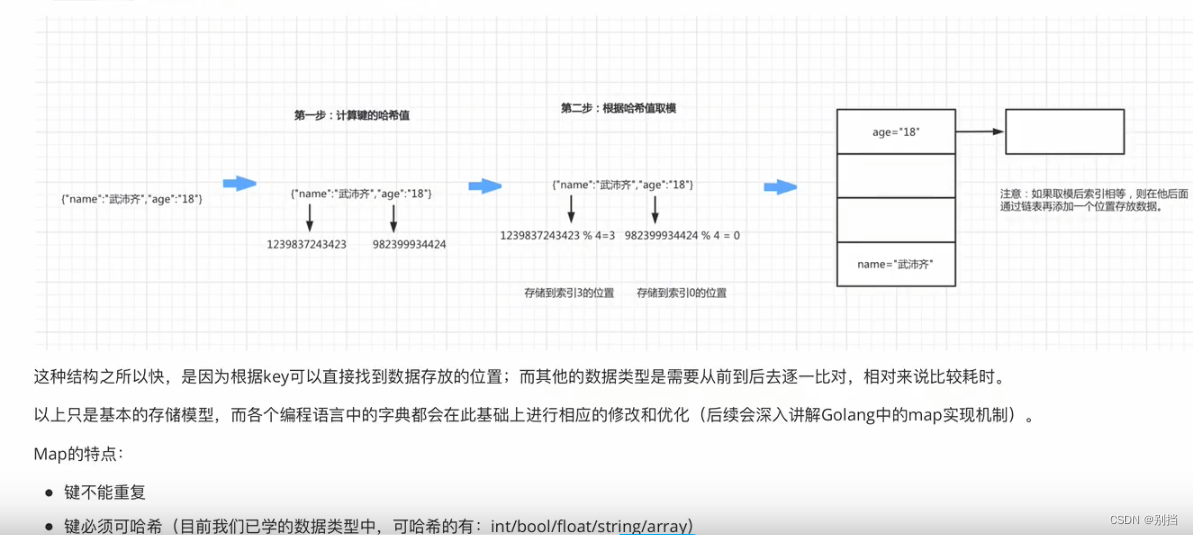
四、 通用所有语言的map哈希底层原理:
通过唯一确定的key值通过哈希运算计算出哈希值。每一个key,value键值对都通过哈希值进行存放,具体的存放方法是:
假定一个最优的存放队列是4,每一个map元素都放在这4个队列其中之一,而放在哪个队列中就根据哈希值和队列数的模:
模值是0就放在第一个;
模值是1就放在第二个;
模值是2就放在第三个;
模值是3就放在第四个。
这样就把所有散列的map元素按哈希值与队列数的模值这样的规律放好,将来想找到某一个map元素,就根据模值找到这个元素所在的队列,在根据这个元素的哈希值具体查找到这个元素,这样的话效率对比查找某个map值需要遍历整个map集合来说效率就高了3/4。
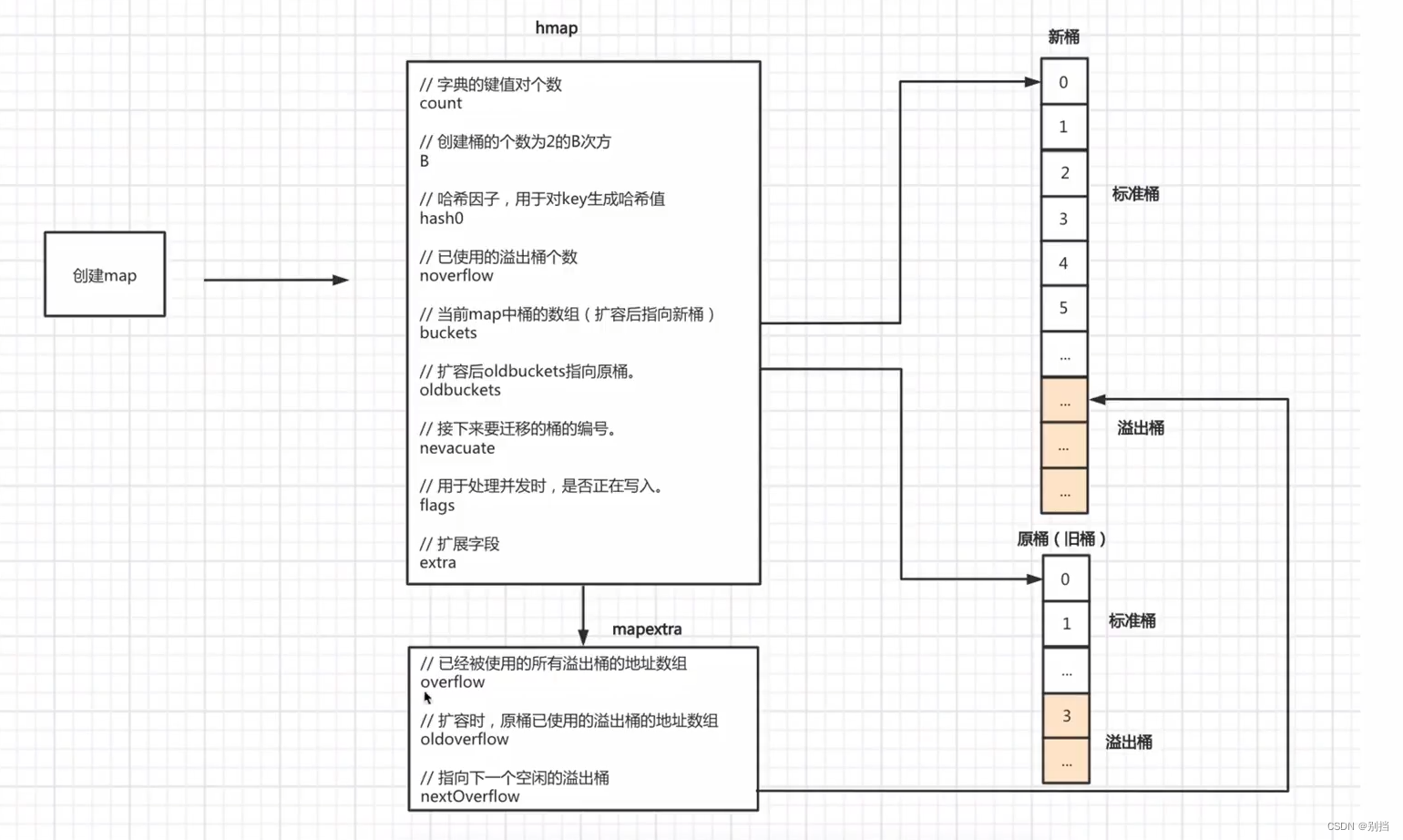
五、 go语言实现和扩展后的map底层原理: runtime包下map.go文件
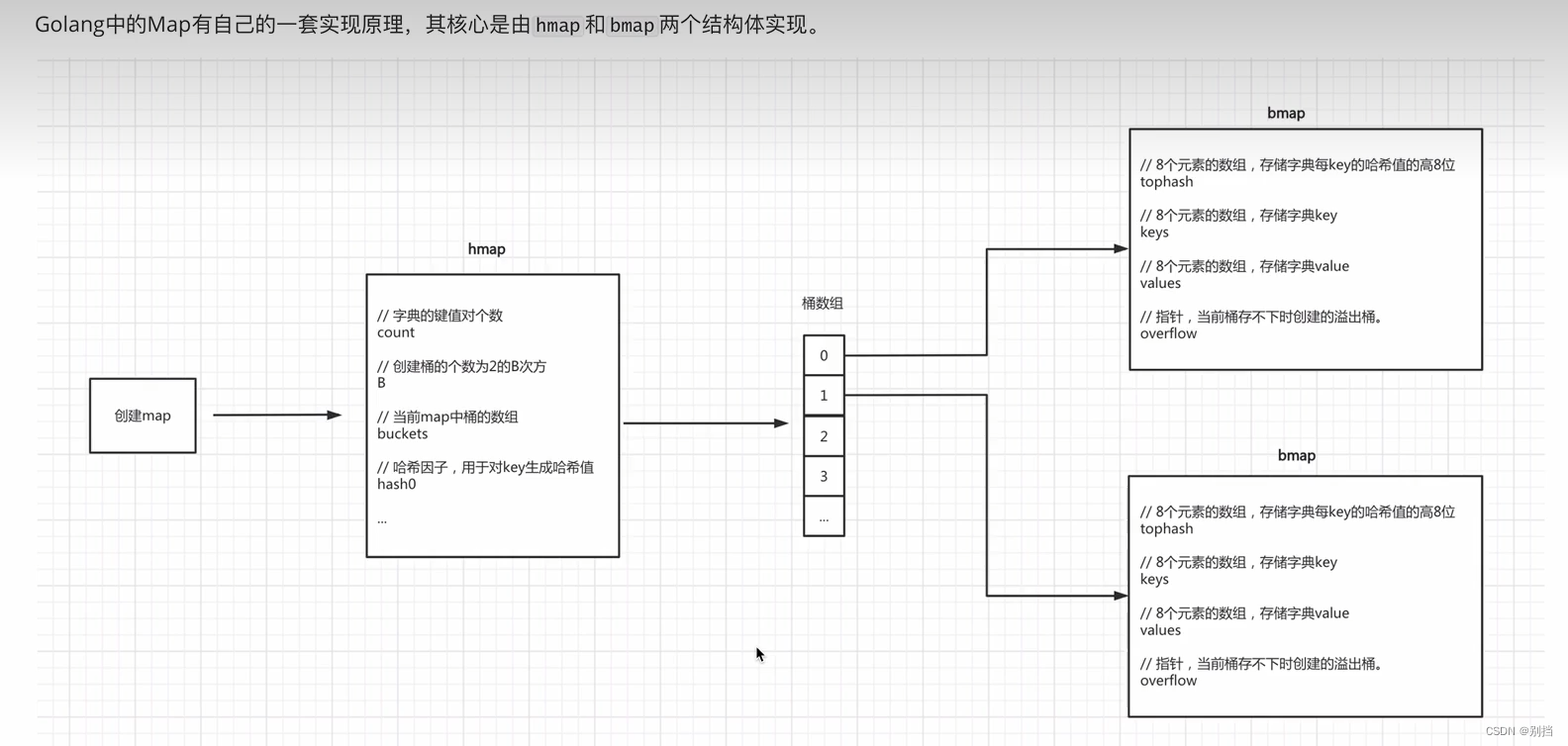
go语言的map底层会有两个对象hmap,bmap
hmap实现了根据map元素个数count创建最优桶个数B,存放所有桶的桶数组buckets。哈希因子是为了将所有的key按此哈希因子的统一规律进行哈希运算得到哈希值。
bmap代表的是桶数组中的桶对象,bmap负责存储key,value值。并且还会存储
key的哈希值的高8位,目的是为了根据map元素哈希值实现快速查找。
map对象创建底层原理:
一)、初始化hmap对象,bmap对象。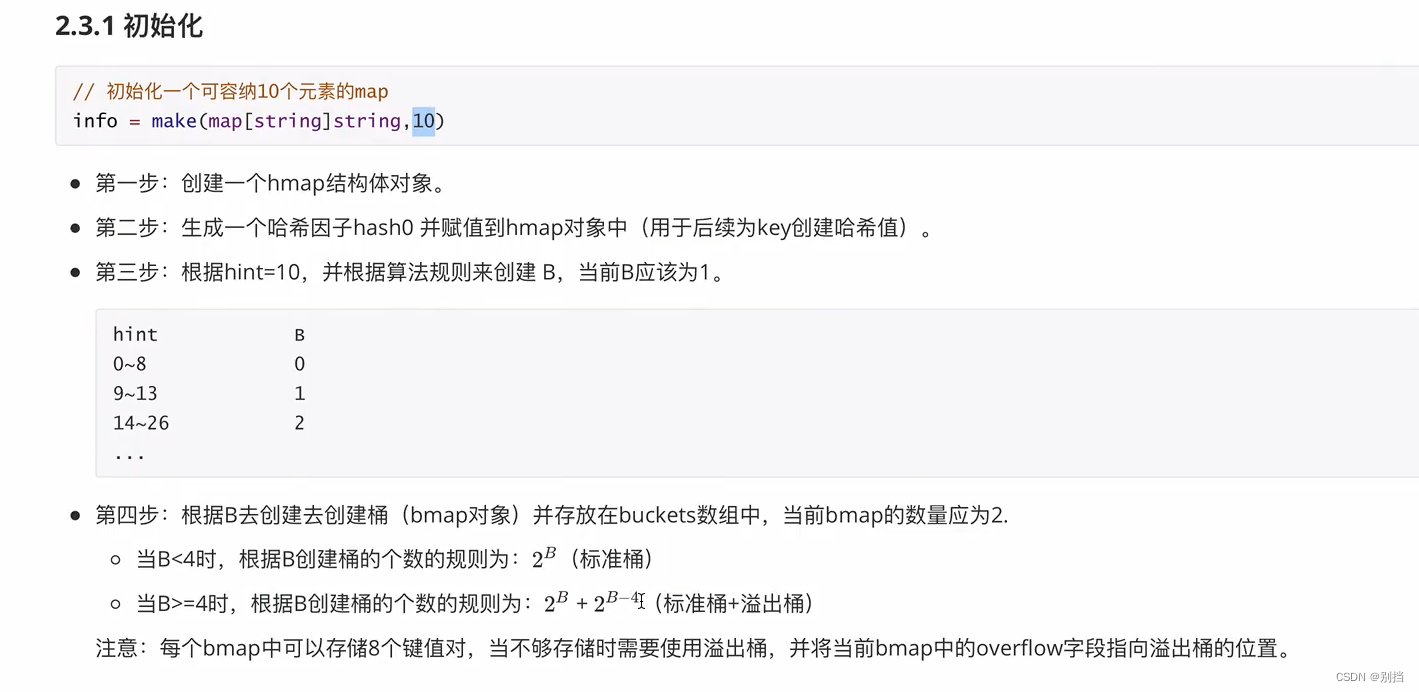
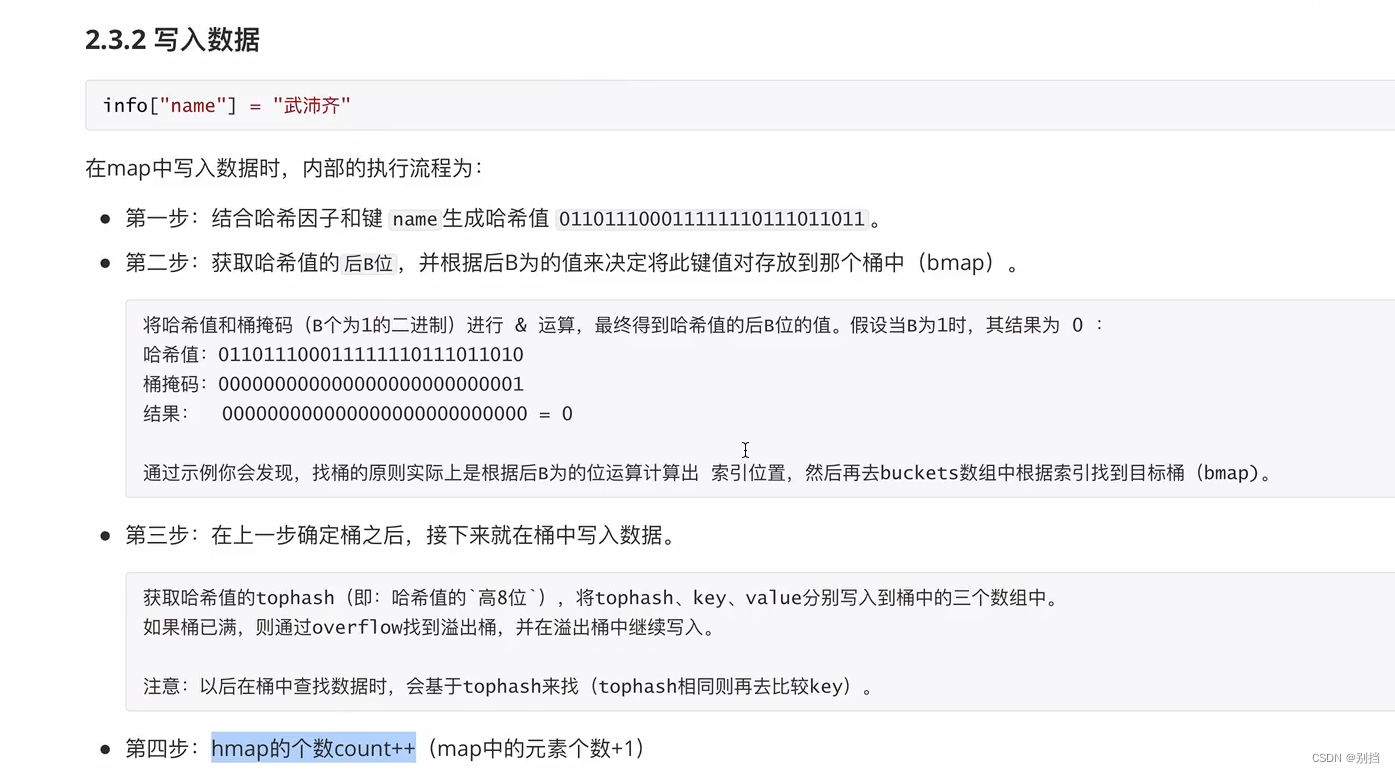
二)、将键值对信息写入bmap中。
所有元素的存放到对应bmap的计算方法:
哈希值与B的&运算,但是B值与哈希值相比较高位全部为0,高位&运算的二进制结果都为0,没有意义,通常取哈希值低B位进行运算得到对应标准桶的索引下标。
map对象的扩容底层原理:等量扩容,翻倍扩容:

等量扩容:
溢出桶太多,存放队列的元素从有规律到杂乱无章,重新将标准桶和溢出桶所有元素按哈希值排列一遍。触发等量扩容并没有改变map的标准桶个数B,只是将所有元素重新排列一遍。
注意点在于等量扩容先保留旧桶数组buckets对象,创建新桶数组buckets对象,
然后再将旧桶元素存放在新桶数组中。这个过程改变了map对象的地址
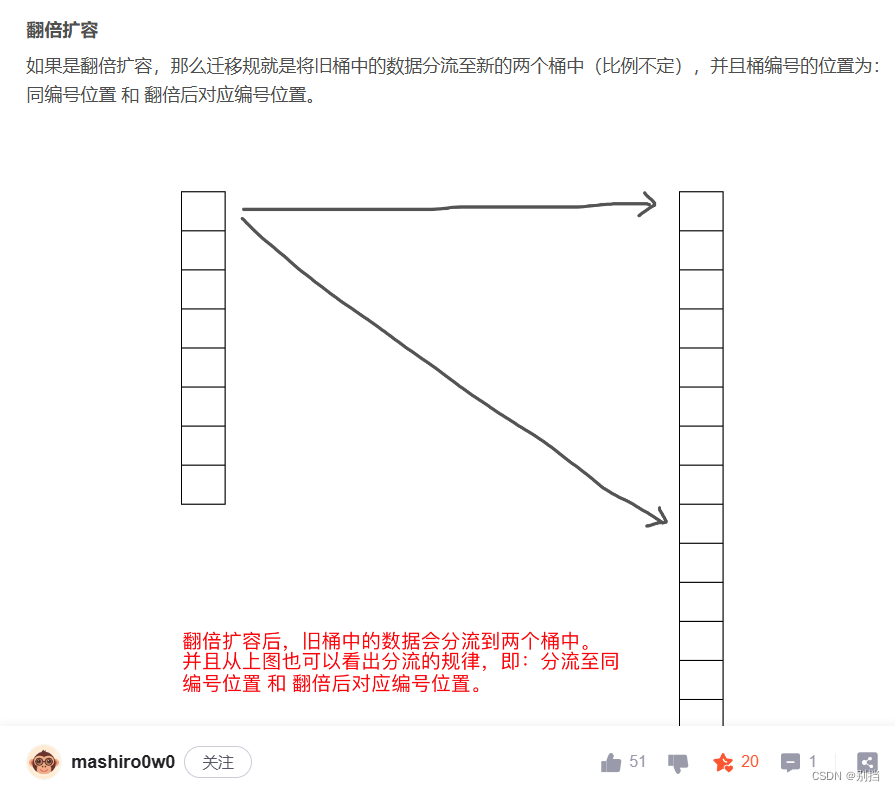
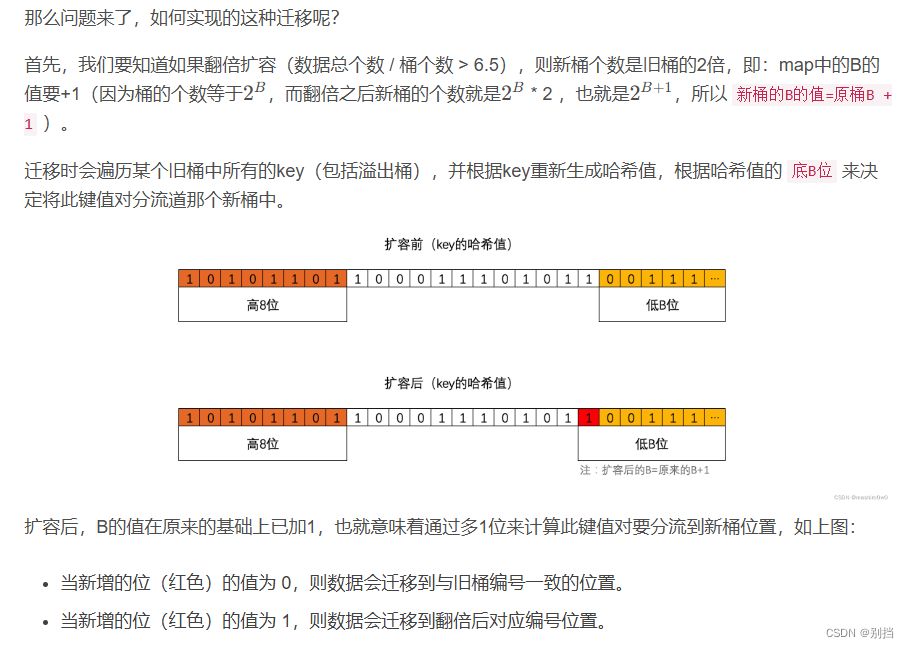
翻倍扩容:
简单来说就是B = B + 1,所有元素的存放位置根据B需要重新计算。
但计算过程也不需要从头开始计算。同一个map哈希因子不变,哈希值并没有改变,
只需要关注元素存放的下标位置。
而元素从旧桶到新桶也只能有两个选择,一个选择是原来的位置index,另一个选择
是 index+B 。因为 哈希值 的低B位与B值进行&运算得到索引下标。B变为B+1时,不确定
的就是哈希值的低B位增加的那一位是0还是1。如果是0直接还是原位置index,如果是1就是
index+B

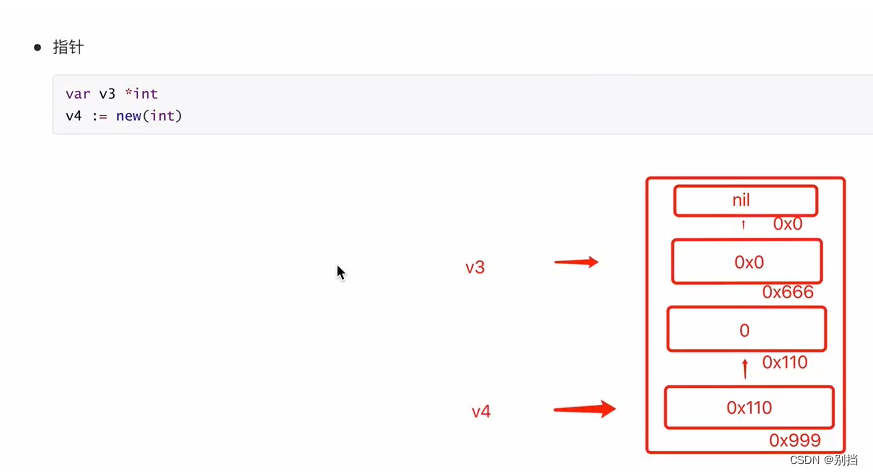
指针
指针两种创建方式
*int
不创建对象,指针对象指向nil
new(int)
new关键字创建出int对象,指针指向一个默认初始化值为0的int对象
指针的运用
1)指针类型在方法赋值中的*操作
changDate方法如果参数为string类型,会将name值重新克隆一份创建一个data对象保存起来,实现的是 data := name的操作,所以data改变并不会改变name值
changeDate方法参数为指针 *string类型, data := &name , 令 *data = "hhhh"
(在指针类型对象前加上*表示该指针指向的实际地址。) 这时改变的就是实际的name值

2)非指针类型对象的&操作:
在其他类型对象前加上&表示取该对象的地址,变成指针类型

结构体
type Person struct {
name string
age int
hobby [ ]string
}
创建结构体对象:
1)var p1 = Person { "武沛齐", 19 , [ ] string {"爱好1","爱好2" } }
2)var p1 = Person { name : "武沛齐" , age: 19 , hobby : [ ] string {"爱好1","爱好2" } }
3) var p1 Person
p1.name = "武沛齐"
p1.age = 18
p1.hobby = [ ] string {"女人","篮球"}

嵌套结构体:
克隆结构体对象p1得到p2对象,会将p1对象所有属性值复制一份到p2中,得到一个全新的对象。所以p1与p2对象是两个独立的对象。
注意:p2中如果复制了p1的属性中的指针类型的属性值,这时克隆的到p2中对应指针类型属性的还是同样的地址,如果改变p1指针属性值,p2还是会改变。

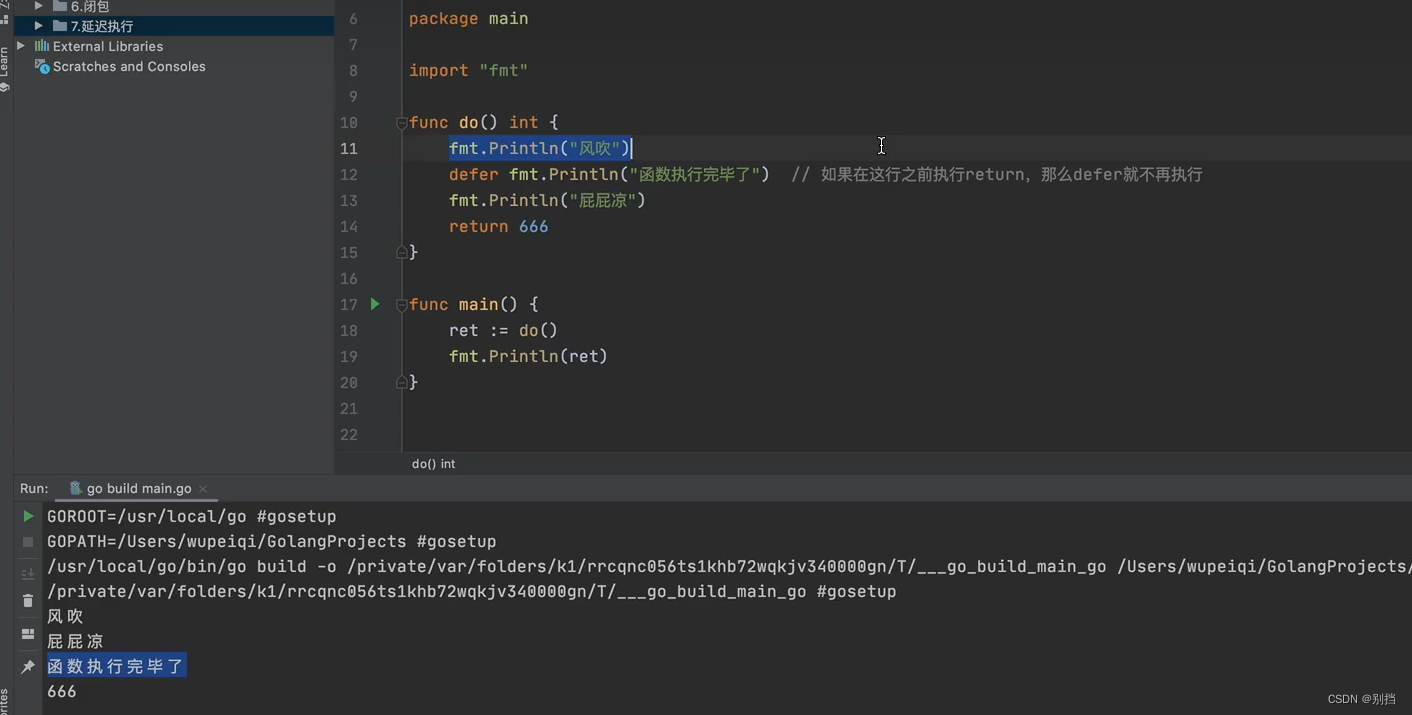
函数
函数本身作为一种数据类型
函数本身作为函数的形式参数

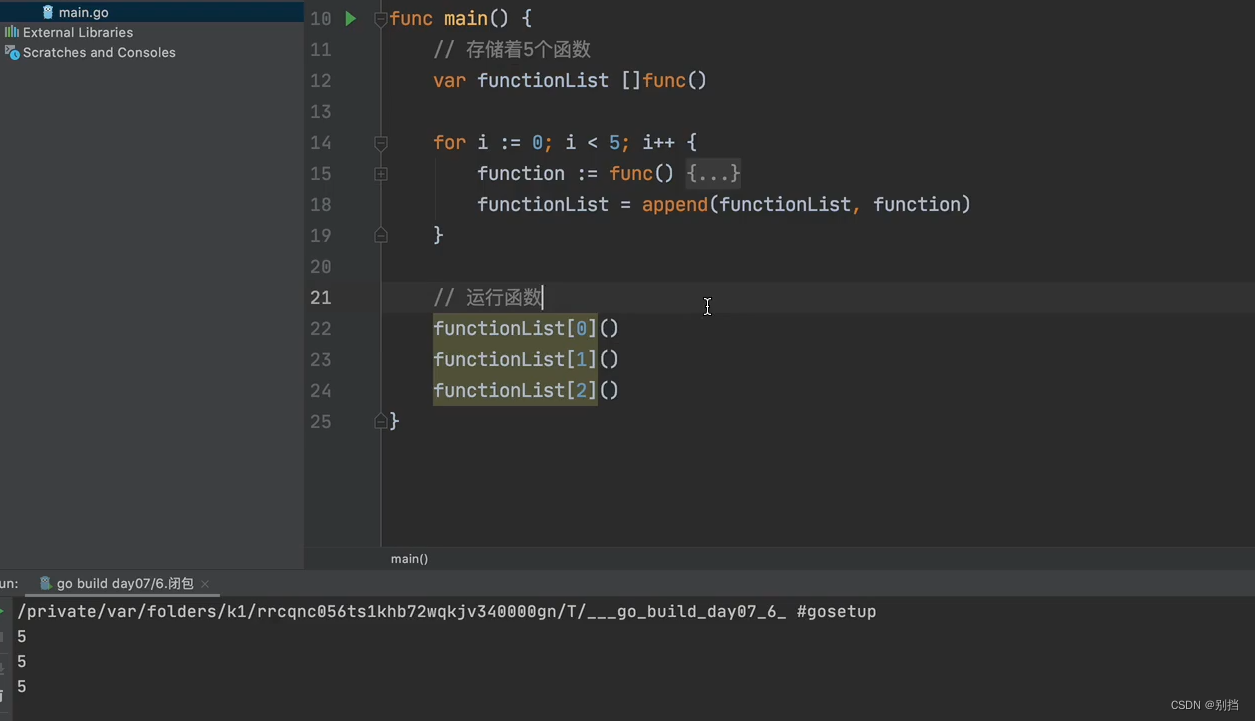
函数本身作为一种数据类型,创建函数对象和运行对象函数
functionObj := func () { fmt.Println(i) } //只创建了函数对象functionObj,并没有调用
functionList[ 0 ] () //调用函数 ,等价于functionObj()
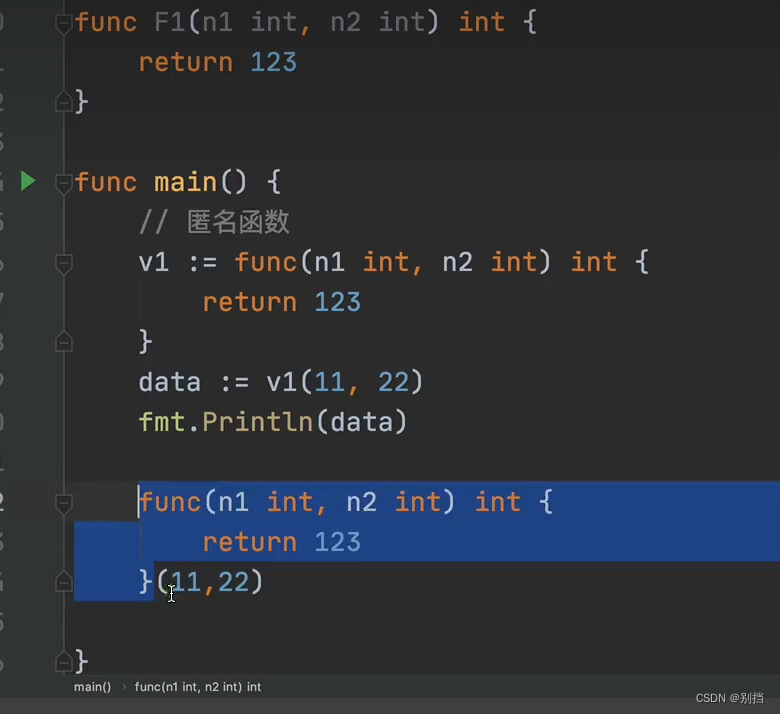
匿名函数
对比java的匿名内部类,go语言要比较好理解。匿名函数只有方法体没有方法名,
只存在一个方法类型对象可供使用。