本文是在win10环境下成功配置环境的注意事项
首先电脑已安装python,pip,或者有python和anaconda(使用虚拟环境也可以)
一、win+r,cmd打开

按第一步 输入pip install neosca
二、按第二步,安装java
一定要安装在D盘或者其他盘
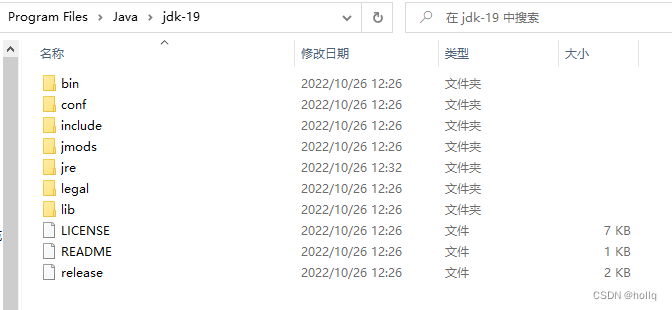
安装完,发现没有jre文件夹,此时在当前目录下打开cmd(选中路径,输入cmd,enter即可)
输入
bin\jlink.exe --module-path jmods --add-modules java.desktop --output jre
然后就有jre了
接着,配置环境变量,右键 我的电脑(此电脑)->属性->高级系统设置->环境变量,添加前两个,第二个写自己安装的路径。
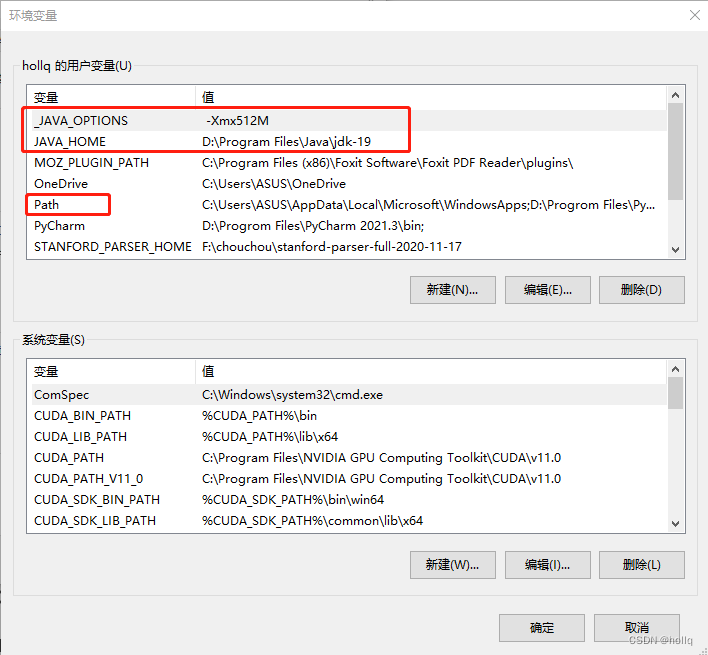
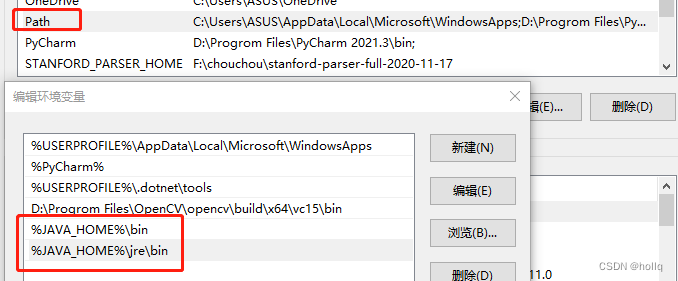
Path需要新建两个
_JAVA_OPTIONS -Xmx512M
JAVA_HOME D:\Program Files\Java\jdk-19
Path
%JAVA_HOME%\bin
%JAVA_HOME%\jre\bin最后,java配置成功

三、下载第三步的两个包,设置环境变量(同上),前面的变量名固定,值为绝对路径
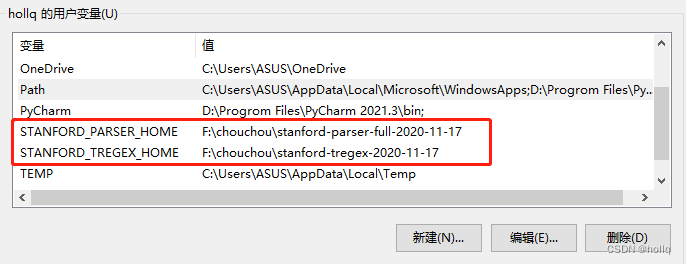
STANFORD_PARSER_HOME F:\chouchou\stanford-parser-full-2020-11-17
STANFORD_TREGEX_HOME F:\chouchou\stanford-tregex-2020-11-17四、输入,测试环境配置完成
nsca sample1.txt 
五,跑实际数据又遇到UnicodeDecodeError: ‘gbk‘ codec can‘t decode byte的问题,搜了一下
Python 的 open 方法默认编码取决于平台,如果是 Windows 平台,默认编码是 gbk,如果文件是 utf-8 编码,就会报这个错误。
解决:报错路径中的neosca-master\neosca\utils\analyzer.py中第131行,按下面改一下,问题解决。
with open(fn_parsed) as f:
改为
with open(fn_parsed,'r', encoding='utf-8') as f: