目录
1.2.2 使⽤ elastic stack 能收集哪些⽇志
1.3 Elastic Stack 企业级"EFK"架构图解
1.4 Elastic Stack 企业级"ELK"架构图解
1.5 Elastic Stack 企业级"ELFK"架构图解
1.6 Elastic Stack 企业级"ELFK" + "kafka"架构图解
一、Elastic Stack 在企业的常见架构
1.1 没有⽇志收集系统运维⼯作的⽇常痛点概述
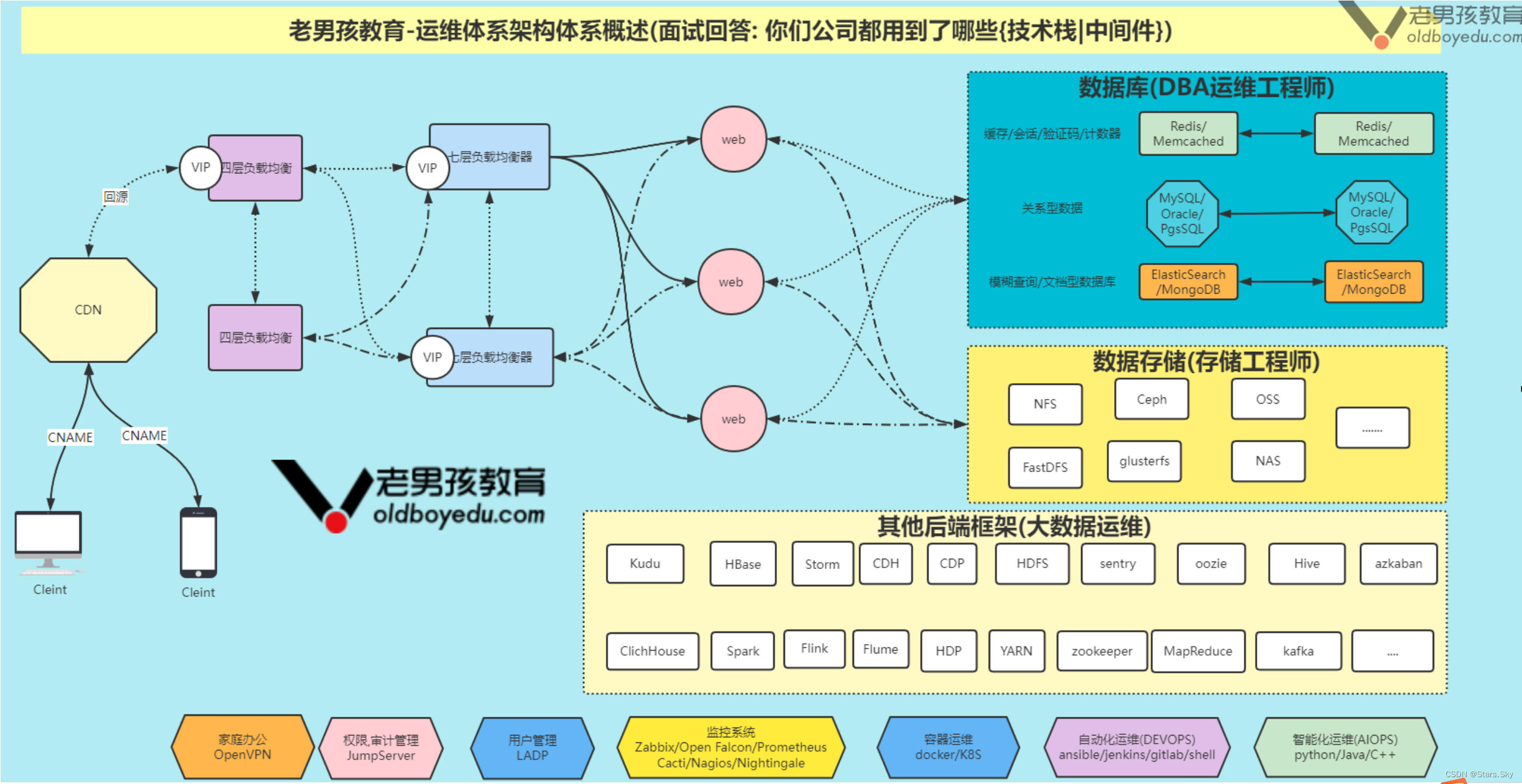
如上图所示,简单画了⼀下互联⽹常⽤的⼀些技术栈相关架构图,请问如果让你对上图中的各组件⽇志进⾏收集,分析,存储,展示该如何做呢?你是否也会经常⾯临⼀下的运维痛点呢?
-
痛点1: ⽣产出现故障后,运维需要不停的查看各种不同的⽇志进⾏分析?是不是毫⽆头绪?
-
痛点2: 项⽬上线出现错误,如何快速定位问题?如果后端节点过多、⽇志分散怎么办?
-
痛点3: 开发⼈员需要实时查看⽇志但⼜不想给服务器的登陆权限,怎么办?难道每天帮开发
-
取⽇志?
-
痛点4: 如何在海量的⽇志中快速的提取我们想要的数据?⽐如:PV、UV、TOP10 的 URL?如果分析的⽇志数据量⼤,那么势必会导致查询速度慢、难度增⼤,最终则会导致我们⽆法快速的获取到想要的指标。
-
痛点5: CDN 公司需要不停的分析⽇志,那分析什么?主要分析命中率,为什么?因为我们给⽤户承诺的命中率是 90% 以上。如果没有达到 90%,我们就要去分析数据为什么没有被命中、为什么没有被缓存下来。
-
痛点6: 近期某影视公司周五下午频繁出现被盗链的情况,导致异常流量突增 2G 有余,给公司带来了损失,那⼜该如何分析异常流量呢?
-
痛点7: 上百台 Mysql 实例的慢⽇志查询分析如何聚集?
-
痛点8: docker、K8S 平台⽇志如何收集分析?
-
痛点N: ......
如上所有的痛点都可以使⽤⽇志分析系统"Elastic Stack"解决,将运维所有的服务器⽇志,业
务系统⽇志都收集到⼀个平台下,然后提取想要的内容,⽐如错误信息,警告信息等,当过滤到这
种信息,就⻢上告警,告警后,运维⼈员就能⻢上定位是哪台机器、哪个业务系统出现了问题,出
现了什么问题。
1.2 Elastic Stack 分布式⽇志系统概述

The Elastic Stack, 包括 Elasticsearch、Kibana、Beats 和 Logstash(也称为 ELK Stack)。
Elastic Stack 官网:欢迎来到 Elastic — Elasticsearch 和 Kibana 的开发者 | Elastic
-
ElaticSearch:简称为 ES, ES 是⼀个开源的⾼扩展的分布式全⽂搜索引擎,是整个 Elastic Stack 技术栈的核⼼。它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理 PB 级别的数据。
-
Kibana:是⼀个免费且开放的⽤户界⾯,能够让您对 Elasticsearch 数据进⾏可视化,并让您在 Elastic Stack 中进⾏导航。您可以进⾏各种操作,从跟踪查询负载,到理解请求如何流经您的整个应⽤,都能轻松完成。
-
Beats:是⼀个免费且开放的平台,集合了多种单⼀⽤途数据采集器。它们从成百上千或成千上万台机器和系统向 Logstash 或 Elasticsearch 发送数据。
-
Logstash:是免费且开放的服务器端数据处理管道,能够从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中。
1.2.1 Elastic Stack的主要优点有如下⼏个
-
处理⽅式灵活:elasticsearch 是实时全⽂索引,具有强⼤的搜索功能。
-
配置相对简单:elasticsearch 全部使⽤ JSON 接⼝,logstash 使⽤模块配置,kibana 的配置⽂件部分更简单。
-
检索性能⾼效:基于优秀的设计,虽然每次查询都是实时,但是也可以达到百亿级数据的查询秒级响应。
-
集群线性扩展:elasticsearch 和 logstash 都可以灵活线性扩展。
-
前端操作绚丽:kibana 的前端设计⽐较绚丽,⽽且操作简单。
1.2.2 使⽤ elastic stack 能收集哪些⽇志
-
容器管理⼯具:docker
-
容器编排⼯具:docker swarm,Kubernetes
-
负载均衡服务器:lvs,haproxy,nginx
-
web 服务器:httpd,nginx,tomcat
-
数据库:mysql,redis,MongoDB,Hbase,Kudu,ClickHouse,PostgreSQL
-
存储:nfs,gluterfs,fastdfs,HDFS,Ceph
-
系统:message,security
-
业务:包括但不限于 C,C++,Java,PHP,Go,Python,Shell 等编程语⾔研发的 App。
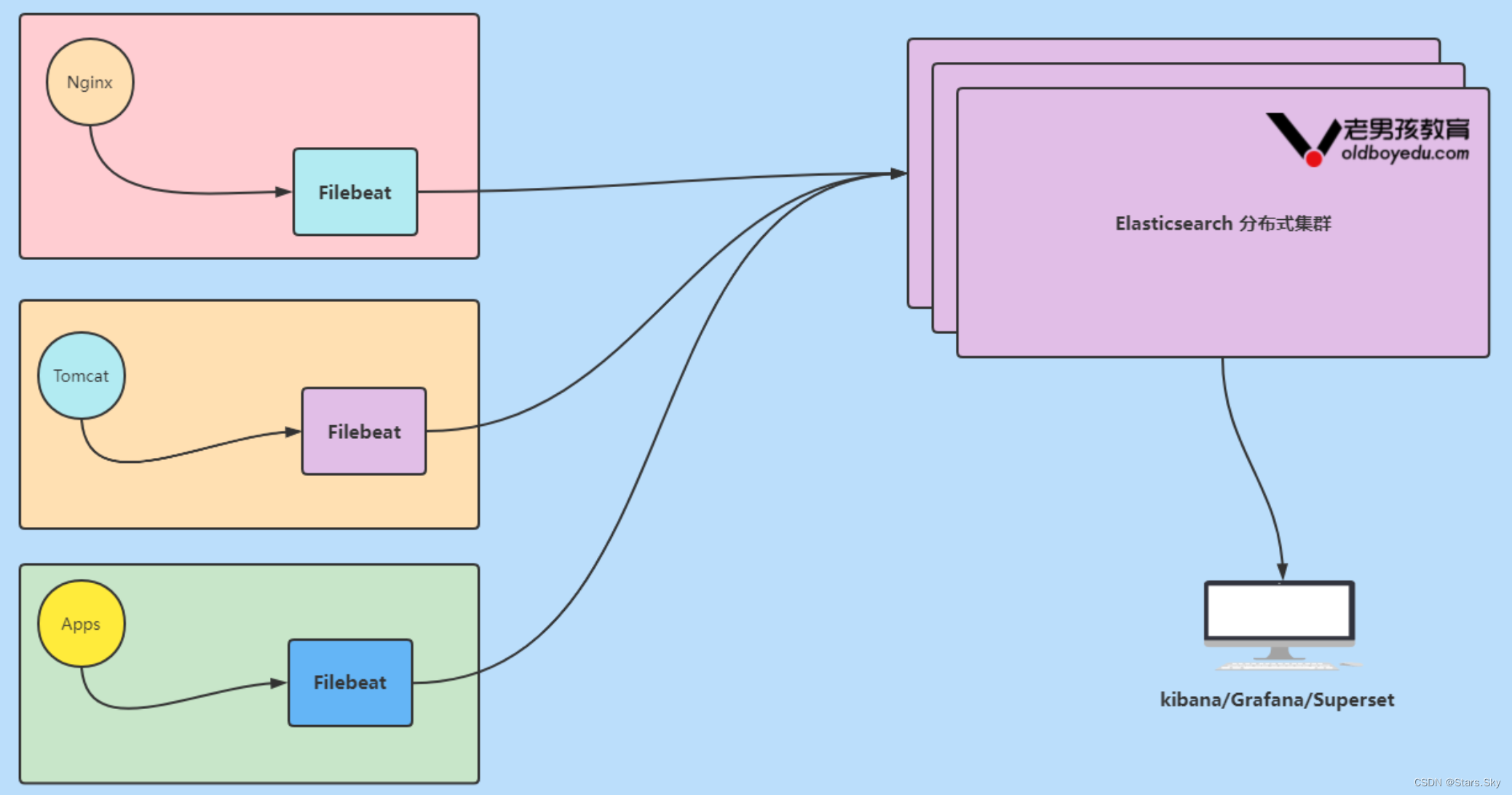
1.3 Elastic Stack 企业级"EFK"架构图解
1.4 Elastic Stack 企业级"ELK"架构图解
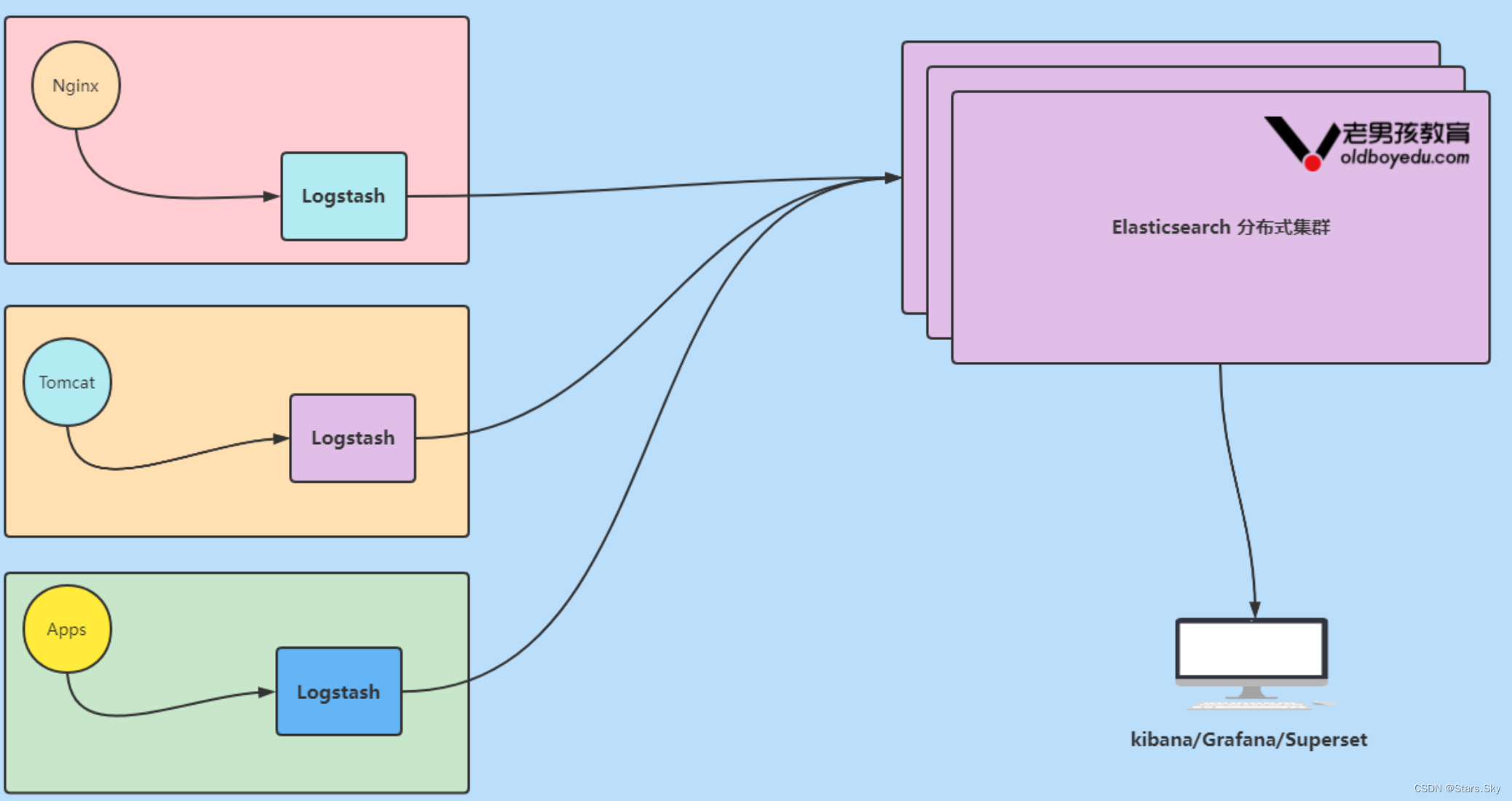
数据流⾛向: 源数据层(nginx,tomcat) ---> 数据采集/转换层(Logstash) ---> 数据存储层(ElasticSearch)。
1.5 Elastic Stack 企业级"ELFK"架构图解
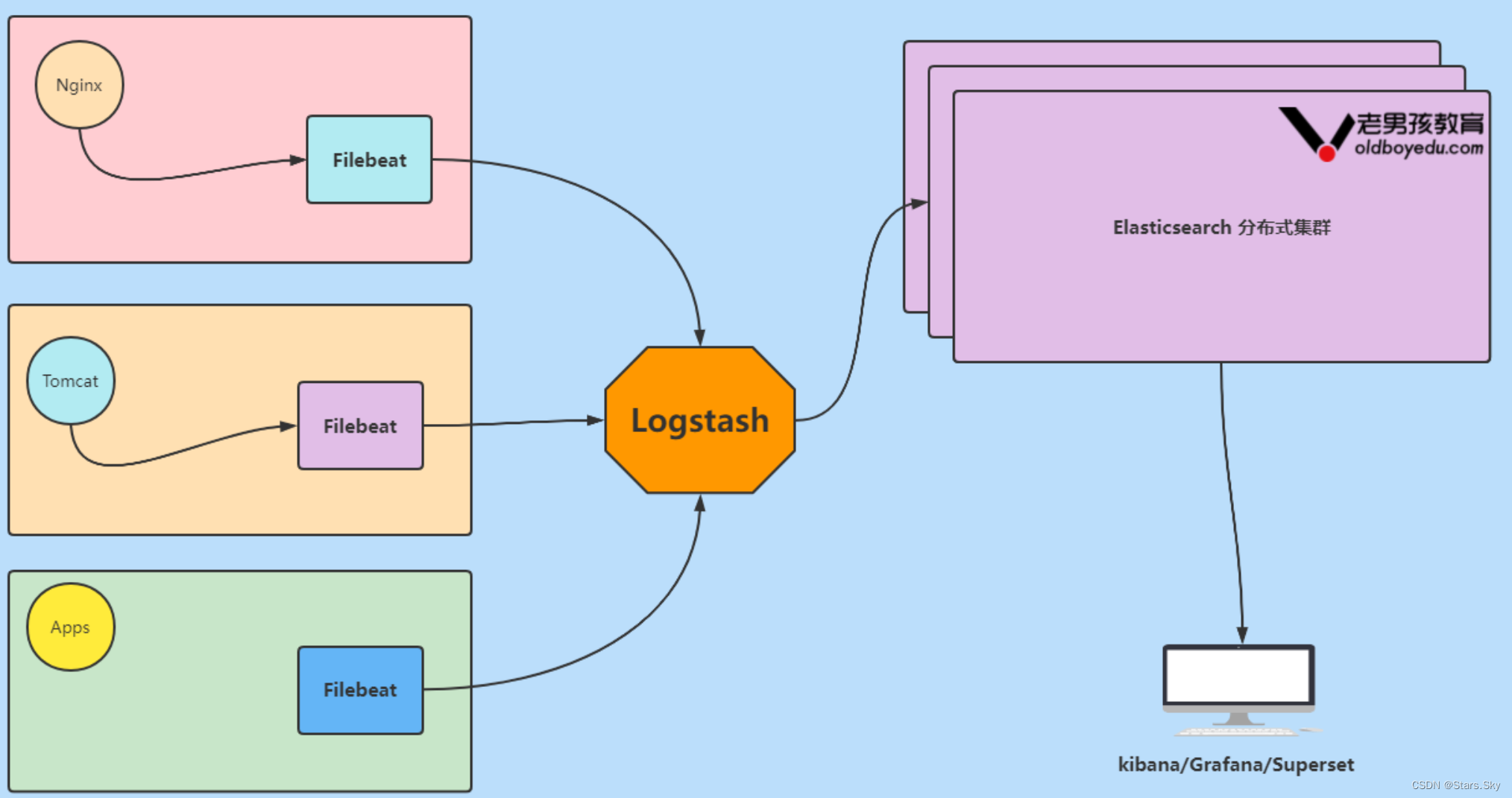
数据流⾛向: 源数据层(nginx,tomcat) ---> 数据采集(filebeat) ---> 转换层(Logstash) ---> 数据存储层(ElasticSearch)。
1.6 Elastic Stack 企业级"ELFK" + "kafka"架构图解
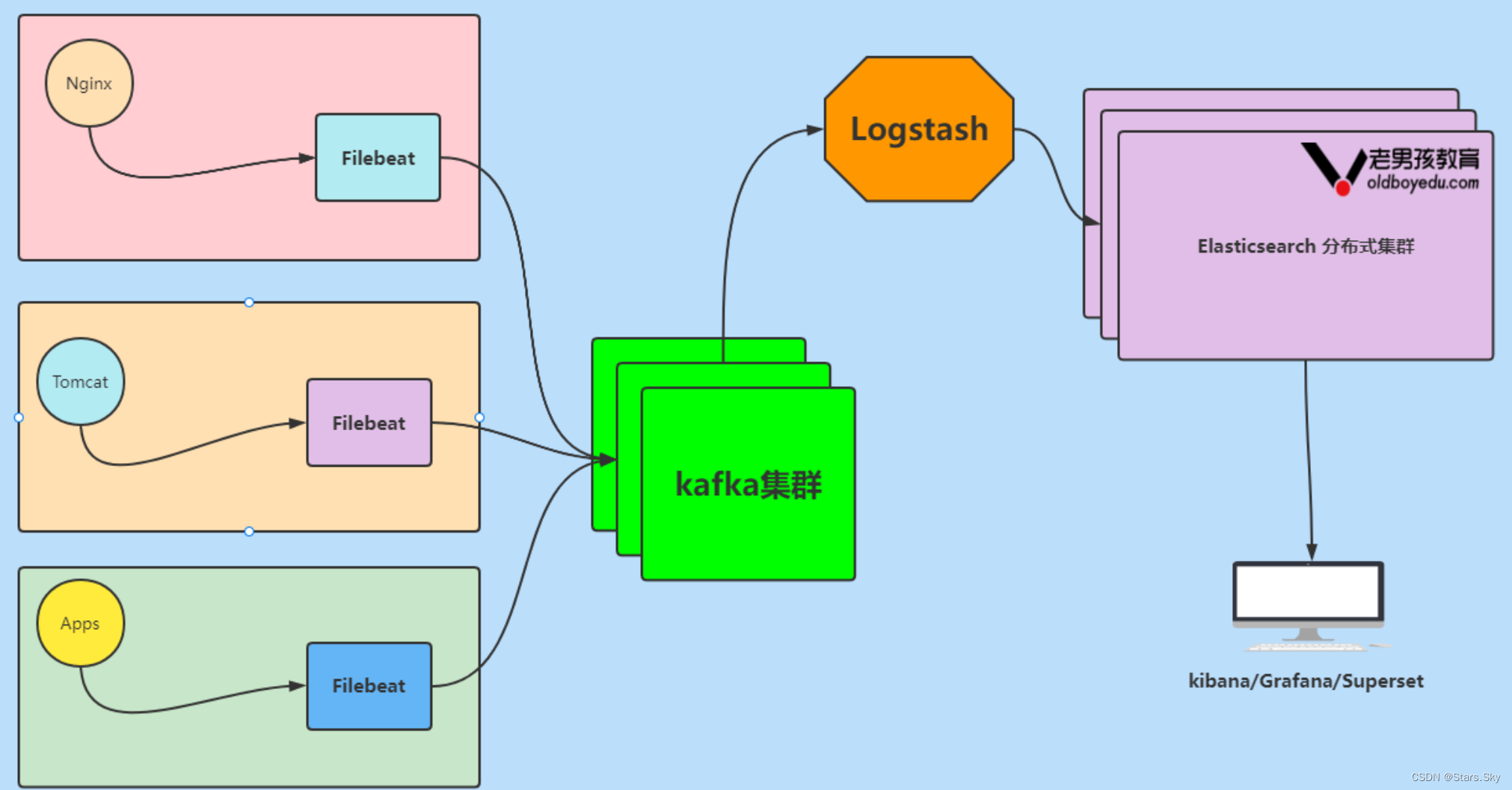
数据流⾛向: 源数据层(nginx,tomcat) ---> 数据采集(filebeat) ---> 数据缓存层(kafka)---> 转换层(Logstash) ---> 数据存储层(ElasticSearch)。
二、ElasticSearch 和 Solr 的抉择
2.1 ElasticSearch 和 Lucene 的关系
2.1.1 Lucene 的优缺点
优点:可以被认为是迄今为⽌最先进,性能最好的,功能最全的搜索引擎库(框架)。
缺点:
-
只能在 Java 项⽬中使⽤,并且要以 jar 包的⽅式直接集成在项⽬中;
-
使⽤很复杂,你需要深⼊了解检索的相关知识来创建索引和搜索索引代码;
-
不⽀持集群环境,索引数据不同步(不⽀持⼤型项⽬);
-
扩展性差,索引库和应⽤所在同⼀个服务器,当索引数据过⼤时,效率逐渐降低;
值得注意的是,上述的 Lucene 框架中的缺点,Elasticsearch 全部都能解决。ElasticSearch 是⼀个实时的分布式搜索和分析引擎。它可以帮助你⽤前所未有的速度去处理⼤规模数据。
ES 可以⽤于全⽂搜索,结构化搜索以及分析,当然你也可以将这三者进⾏组合。有哪些公司在使⽤ ElasticSearch 呢,全球⼏乎所有的⼤型互联⽹公司都在拥抱这个开源项⽬:
用例 • ELK Stack成功案例 | Elastic Customers
2.2 ElasticSearch 和 Solr 如何抉择
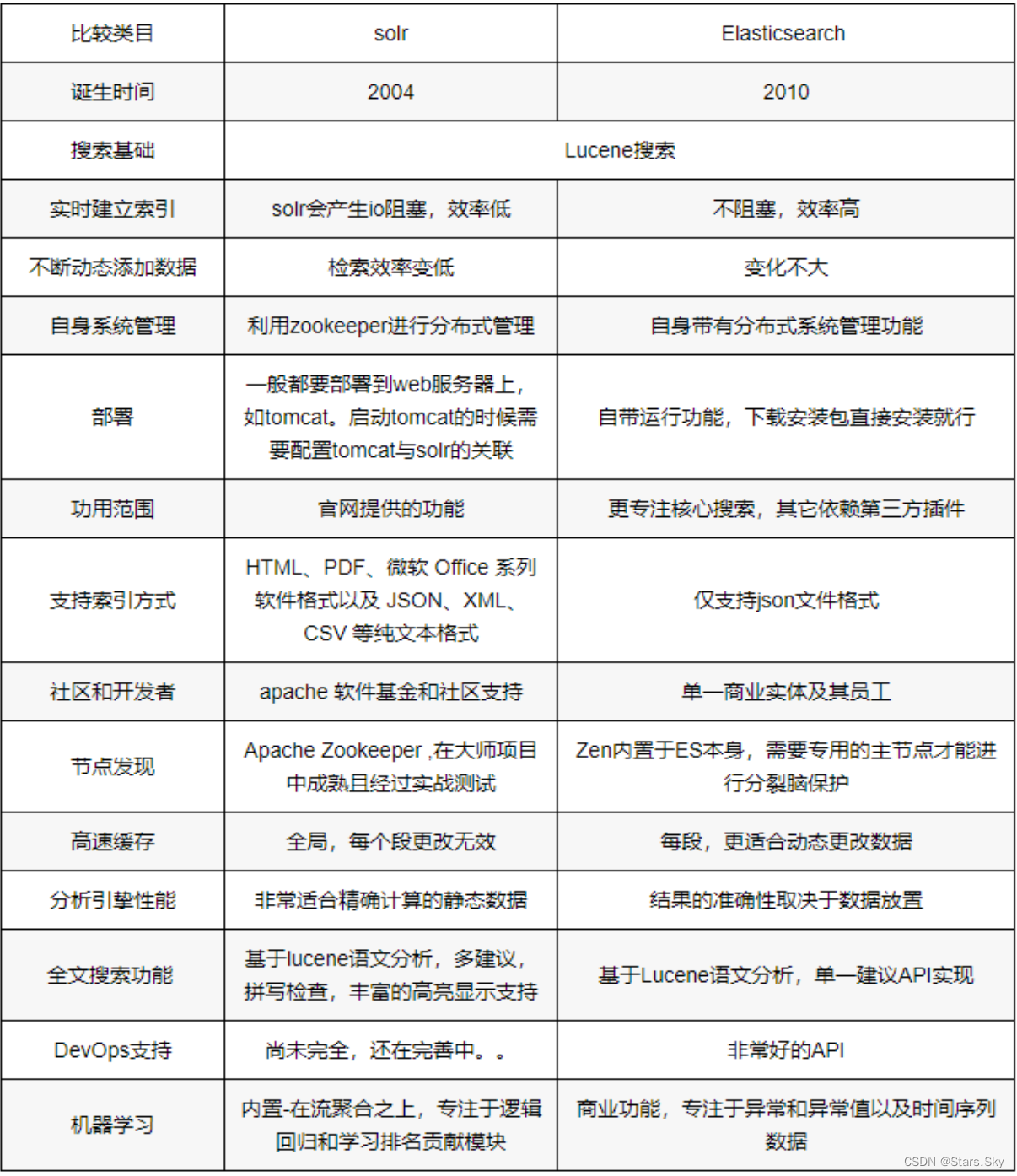
Solr 是 Apache Lucene 项⽬的开源企业搜索平台。其主要功能包括全⽂检索、命中标示、分⾯搜索、动态聚类、数据库集成,以及富⽂本(如Word、PDF)的处理。
Solr 是⾼度可扩展的,并提供了分布式搜索和索引复制。Solr 是最流⾏的企业级搜索引擎,
Solr4 还增加了 NoSQL ⽀持。
Elasticsearch(下⾯简称"ES")与 Solr 的⽐较:
-
Solr 利⽤ Zookeeper 进⾏分布式管理,⽽ ES ⾃身带有分布式协调管理功能;
-
Solr ⽀持更多格式(JSON、XML、CSV)的数据,⽽ ES 仅⽀持 JSON ⽂件格式;
-
Solr 官⽅提供的功能更多,⽽ ES 本身更注重于核⼼功能,⾼级功能多有第三⽅插件提供;
-
Solr 在"传统搜索"(已有数据)中表现好于 ES,但在处理"实时搜索"(实时建⽴索引)应⽤时效率明显低于 ES。
-
Solr 是传统搜索应⽤的有⼒解决⽅案,但 Elasticsearch 更适⽤于新兴的实时搜索应⽤。
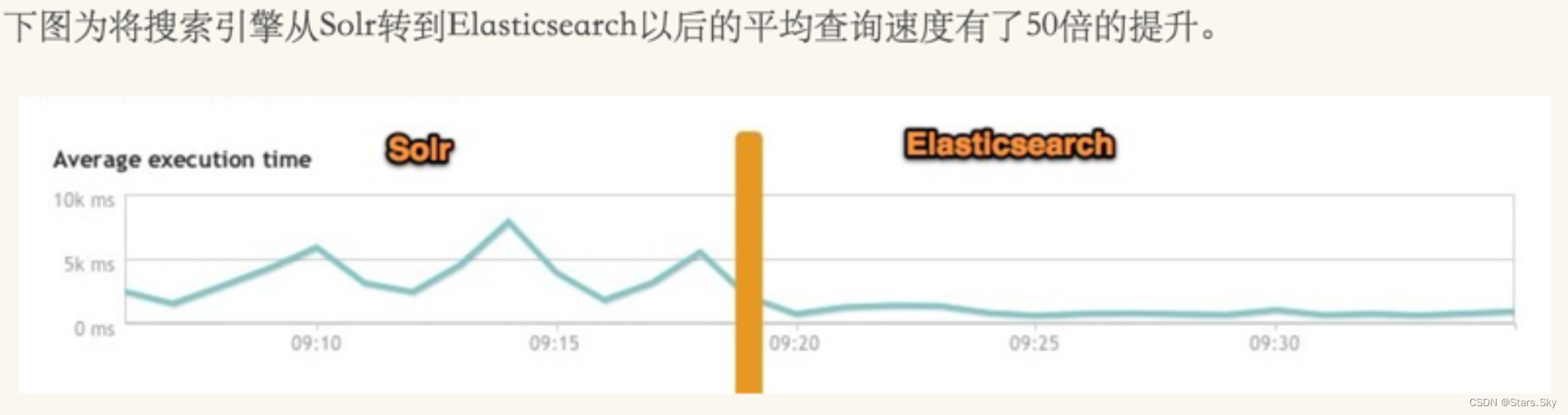
如下图所示,有⽹友在⽣产环境测试,将搜索引擎从 Solr 转到 ElasticSearch 以后的平均查询速度有了将近 50 倍的提升。