📖标题:SelfCite: Self-Supervised Alignment for Context Attribution in Large Language Models
🌐来源:arXiv, 2502.09604
🌟摘要
我们介绍了SelfCite,这是一种新颖的自我监督方法,可以对齐LLM,为生成的回复中的陈述生成高质量、细粒度的句子级引用。SelfCite不依赖于昂贵和劳动密集型的注释,而是利用LLM本身通过上下文消融提供的奖励信号:如果需要引用,从上下文中删除引用的文本应会阻止相同的反应;如果足够,仅保留引用的文本应能保持相同的回应。该奖励可以指导推理时间最优的N抽样策略,显著提高引文质量,并可用于偏好优化,直接微调模型以生成更好的引文。SelfCite的有效性通过在五个长篇问答任务中将引用F1在LongBench Cite基准上提高到5.3分来证明。
🛎️文章简介
🔸研究问题:如何提高大语言模型(LLM)生成响应时的上下文引用质量?
🔸主要贡献:论文提出了SelfCite框架,通过自监督上下文消减和奖励函数,显著提升了LLM生成上下文引用的质量,无需人工标注。
📝重点思路
🔸问题定义:定义了生成带有上下文引用的回答的任务,并提出了评估引用质量的指标。
🔸奖励设计:通过上下文消减设计了自监督奖励函数,计算必要性和充分性得分。
🔸必要性得分(Necessity Score):通过移除引用内容后,计算生成相同响应的概率下降情况。概率下降越多,引用越必要。
🔸充分性得分(Sufficiency Score):通过仅保留引用内容,计算生成相同响应的概率保持情况。概率保持越高,引用越充分。
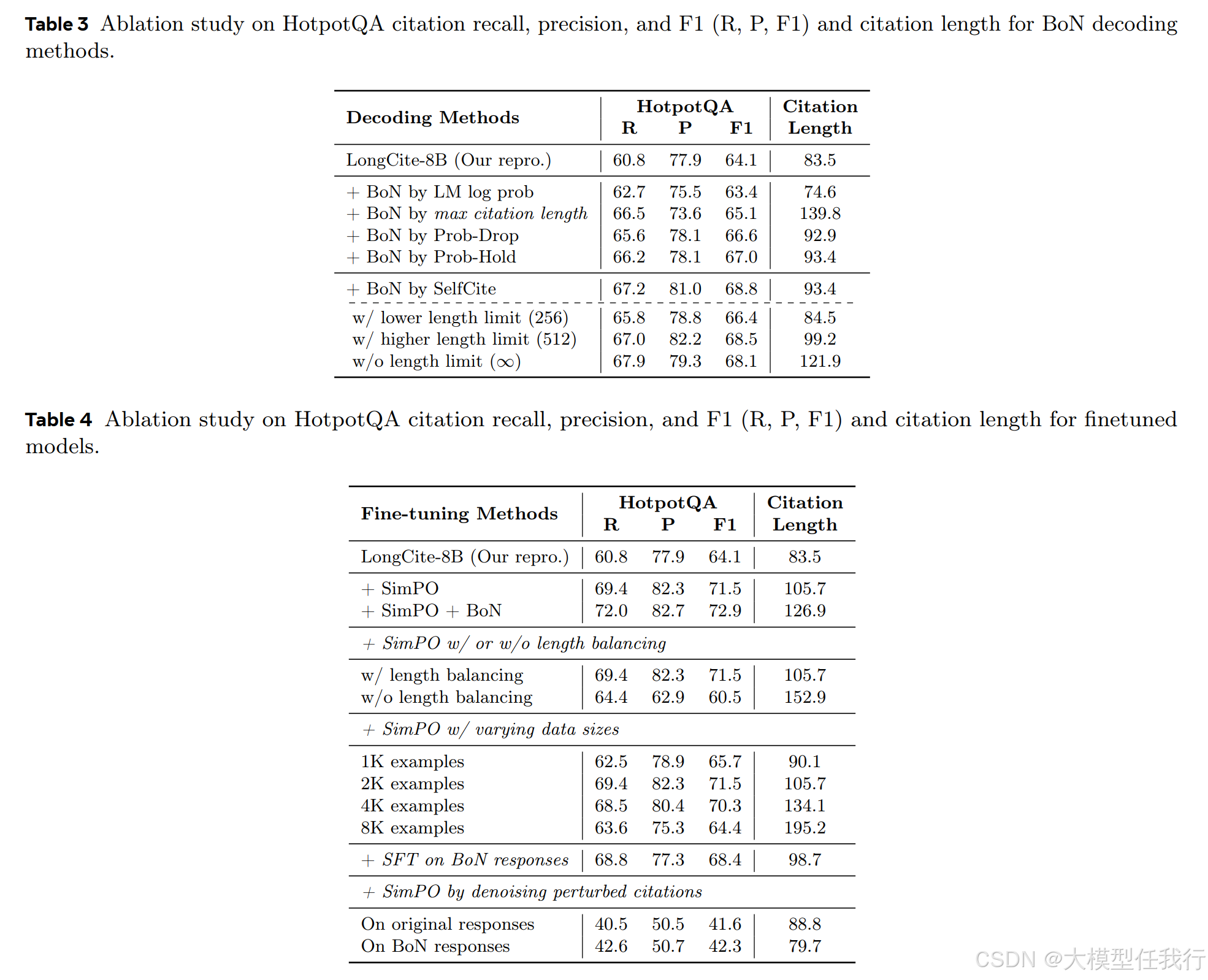
🔸最佳N抽样:生成多个候选引用,选择最优的以提升引用质量。
🔸偏好优化:利用SimPO方法,将奖励信号用于模型微调,提升引用生成能力。
🔎分析总结
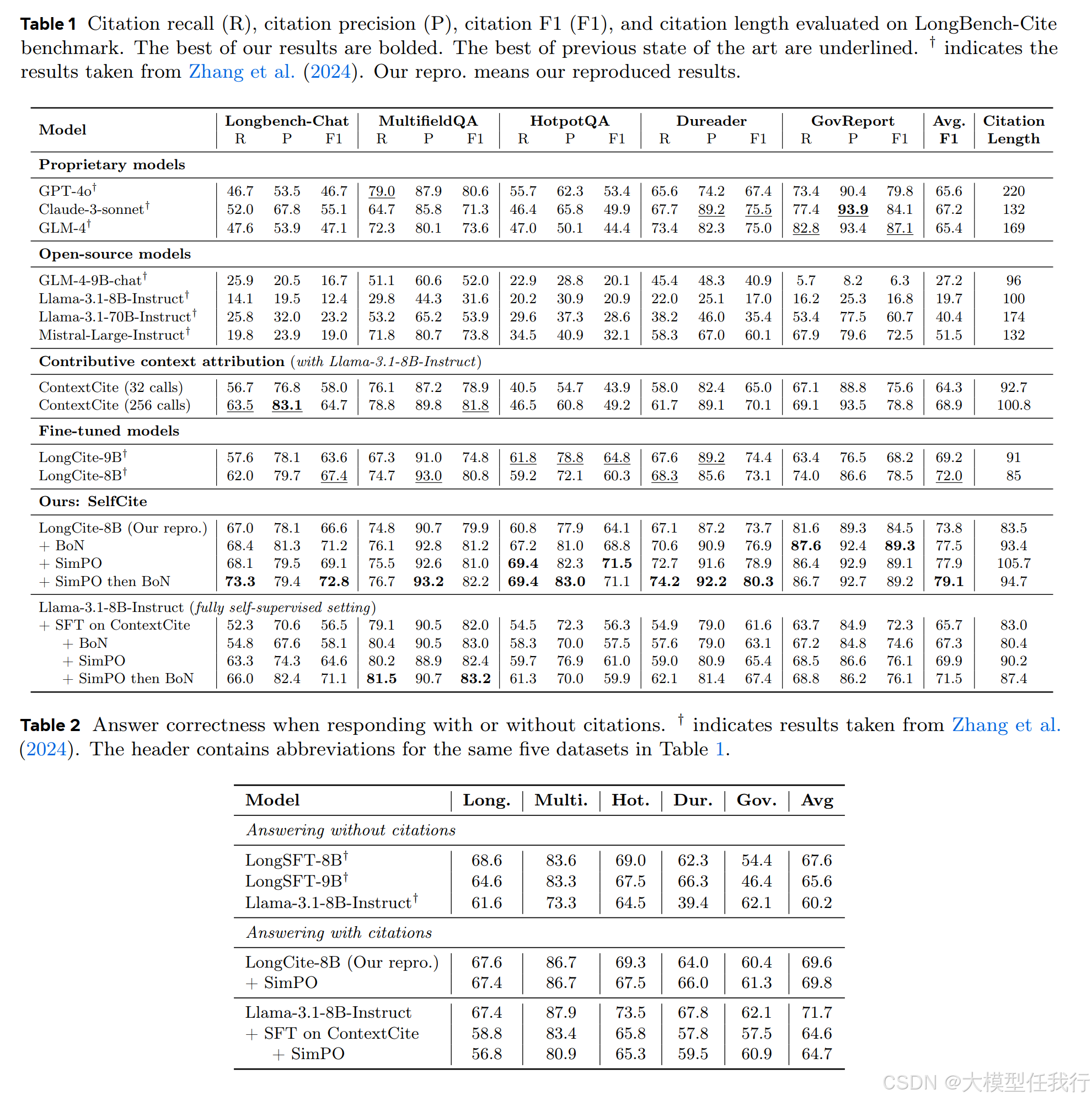
🔸引用质量提升:在LongBench-Cite基准测试中,F1分数提高了5.3个百分点。
🔸SimPO效果:通过SimPO优化,保持了最佳N抽样的改进,无需最佳N抽样。
🔸方法效率:上下文消减比基于线性回归的ContextCite更高效和准确。
🔸引用长度:SelfCite生成的引用更短,更精细,避免了不必要的长段落。
💡个人观点
论文的核心是根据剔除上下文后的影响,来构建奖励函数并进行偏好优化。
🧩附录