3D human pose estimation
3D Human Pose Estimation的目标是在三维空间中估计人体关键点的位置。
基于深度学习的3D HPE方法被分为三类:基于单目图像的3D HPE、基于多视角的3D HPE和基于视频的3D HPE。

随着深度学习在人体姿态估计领域的成功应用,2D HPE 的精度和泛化能力都得到了显著提升。然而,相较于 2D HPE,3D HPE 面临着更多的挑战。
一方面,受数据采集难度的限制,目前大多数方法都是基于单目图像或视频的,而从 2D 图像到 3D 姿态的映射本就是一个多解问题。
另一方面,深度学习算法依赖于大量的训练数据,但由于 3D 姿态标注的难度和成本都比较高,目前的主流数据集基本都是在实验室环境下采集的,这会影响到算法在户外数据上的泛化性能。
而当有多个视图可用或部署其他传感器时,3D HPE需要解决不同摄像机之间对应位置的关联。
与2D HPE一样,对遮挡的鲁棒性和计算效率也是三维HPE的两个关键挑战。
3D HPE from monocular RGB images
单视角单人3D HPE
由于单目图像易于获取且不受场景限制,很多方法都以此为输入数据。但是,正如前面提到的,根据 2D 图像估计 3D 姿态是一个不适定问题,即可能存在多个不同的 3D 姿态,它们的 2D 投影是同一个 2D 姿态。并且,基于单目图像的方法也面临着自遮挡、物体遮挡、深度的不确定性等问题。
基于单目图像的方法可以根据是否依赖 2D HPE 分成两类,下面将分别介绍这两类方法。
直接预测
这类方法不依赖 2D HPE,直接从图像回归得到 3D 关键点坐标。代表作 C2F-Vol[3] 借鉴了 2D HPE 中的 Hourglass 网络结构,并以 3D Heatmap 的形式表示 3D pose。为了降低三维数据带来的巨大存储消耗,采用了在 depth 维度上逐渐提升分辨率的方法。

直接预测可以更好地利用原始图像中的信息。而其最大的缺陷在于,2D-3D 的映射是一个高度非线性问题,且 3D 空间的搜索范围更广,预测难度非常大。
2D-to-3D Lifting
得益于 2D HPE 的高精度和泛化能力,许多方法选择以 2D HPE 作为中间步骤,根据 2D pose(和原始图像特征)去估计 3D pose。SimpleBaseline3D [4] 是其中的一种经典方法。该方法以 2D 关键点坐标作为输入,通过残差连接的全连接层直接将 2D pose 映射到 3D 空间。尽管模型非常简单,该算法在当时达到了 SOTA 水平,并通过实验证明了目前大多数 3D HPE 算法的误差主要来源于图像信息的理解(2D HPE)而不是 2D-to-3D lifting 过程。
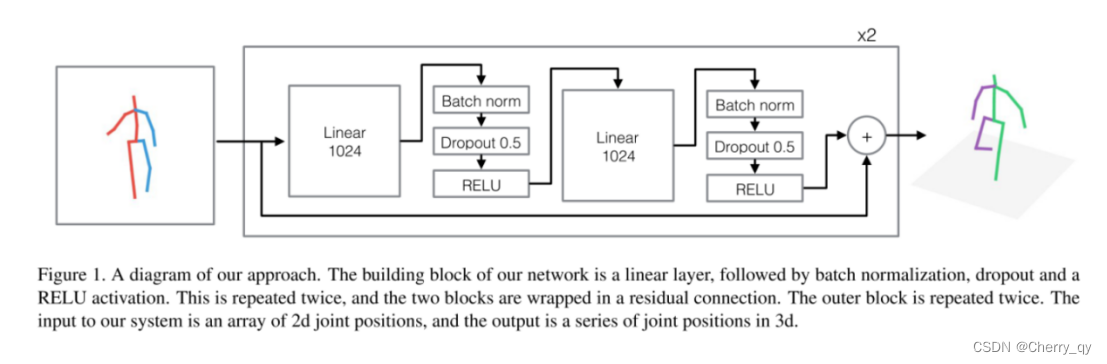
由于上述算法仅以 2D pose 作为输入,因此高度依赖 2D pose 的准确性,一旦 2D HPE 失败,将会严重影响后续的 2D-to-3D lifting。为了解决这一问题,也有一些算法同时学习 2D 和 3D 姿态 [5],这样一方面可以为 2D-to-3D lifting 引入来自于原始图像的信息,另一方面也为 2D/3D 数据集混合训练提供了可能,进一步提升算法的泛化能力。
其他一些方法:
GCNs
运动学模型是一种具有运动学约束的连接骨骼和关节的关节身体表征。许多方法利用基于运动学模型的先验知识,如骨骼关节的连通性信息、关节的旋转特性和固定的骨长比来进行合理的姿态估计。
弱监督/自监督
Transformer架构:Zheng等人[294]提出了第一个纯基于变压器的三维HPE方法,不涉及卷积的架构。空间变压器模块编码人体关节之间的局部关系,而时间变压器模块捕获整个序列中各帧之间的全局依赖关系。Li等人[125]提出了一种串变压器编码器(STE),以减少序列冗余和计算成本。Li等人[126]进一步设计了一个多假设变换器来利用多姿态假设的时空表征。Zhao等人[291]集成了具有图卷积的变压器架构,使用更少的参数捕获人体运动结构和隐式联合关系。
单视图多人3D HPE
对于多人场景下的 3D HPE,和 2D 的情况类似,也可以分成 top-down 和 bottom-up 这两类。其中,top-down 方法 [10] 需要先利用目标检测算法确定人体的 bounding box,然后对于每一个 bounding box 中的人体,计算其根关节的绝对坐标以及其他关节相对于根关节的坐标。而 bottom-up 方法 [11] 则首先预测所有关节的位置,再根据关节间的相对关系将属于同一个人的关节联系起来构成完整的人体。Bottom-up 方法的主要优点在于它的运行时间基本不会受到待检测人体数量的影响,因此在拥挤场景下 bottom-up 方法更有优势。再者,bottom-up 方法的关键点定位是在整体图像的基础上完成的,而 top-down 方法则是在 bounding box 区域内完成的,因此 bottom-up 方法更有利于把握全局信息,从而能更准确地定位人体在相机坐标系下的绝对位置。

Multi-view 3D HPE
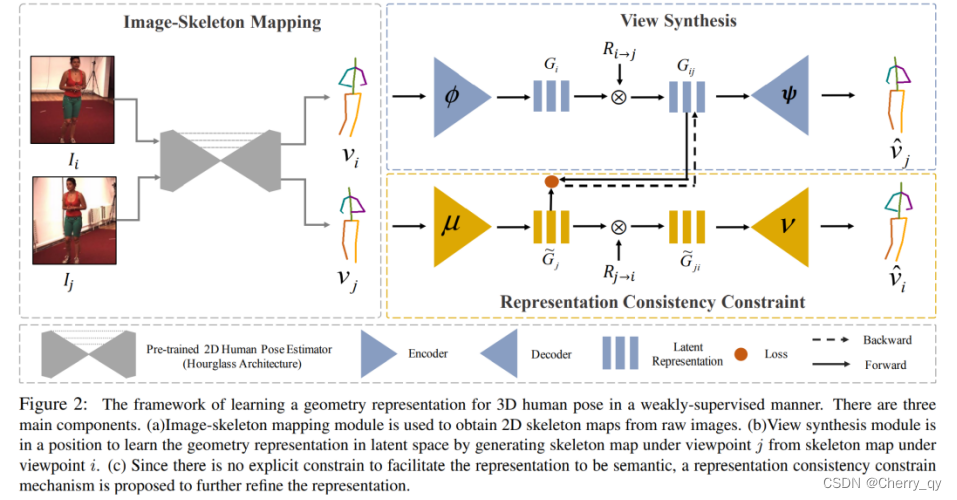
为了解决遮挡问题,目前最有效的方法之一就是融合多视角信息。为了从多目图像中重建 3D pose,关键在于如何确定场景中同一个点在不同视角下的位置关系。一些方法引入多视角间的一致性约束,例如在 [6] 中,同时输入两个视角的图像,对于其中某一个视角的 2D pose 输入,根据两个视角间的转换关系,预测另一个视角的 3D pose 输出。
结合多目图像可以帮助解决遮挡问题,并且也能够在一定程度上解决深度不确定问题。但是这类方法对于数据采集的要求比较高,且模型结构相对复杂,在实际场景中的应用具有一定的局限性。
其他方法:
除了 RGB 图像以外,也有越来越多的传感器被应用于 3D HPE 任务中。常见的有深度相机、雷达、IMU(惯性测量单元)等。
深度和点云传感器:深度传感器由于其低成本和提高利用率,在三维计算机视觉任务中得到了越来越多的关注。使用深度传感器可以缓解深度模糊问题。
与深度图像相比,点云可以提供更多的信息。最先进的点云特征提取技术,PointNet [195]和PointNet++ [196],已经展示了出色的分类和分割任务的性能。
具有单目图像的IMUs:可穿戴惯性测量单元(IMUs)不依赖于视觉信号,可以通过记录没有物体遮挡和衣服阻塞的运动来跟踪人体各部位的方向和加速度。
射频装置:基于射频(RF)的传感技术也被用于3D HPE。在不携带无线发射机的情况下,人们能够在WiFi范围内穿越墙壁和反弹出人体,这是部署基于射频的传感系统的主要优势。此外,由于非视觉隐私可以保护数据。然而,与视觉摄像机图像相比,射频信号具有相对较低的空间分辨率,而且射频系统已显示出可以产生粗糙的三维姿态估计。
3D HPE from videos
基于视频的方法就是在以上两类方法的基础上引入时间维度上的信息。相邻帧提供的上下文信息可以帮助我们更好地预测当前帧的姿态。对于遮挡情况,也可以根据前后几帧的姿态做一些合理推测。另外,由于在一段视频中同一个人的骨骼长度是不变的,因此这类方法通常会引入骨骼长度一致性的约束限制,有助于输出更加稳定的 3D pose。
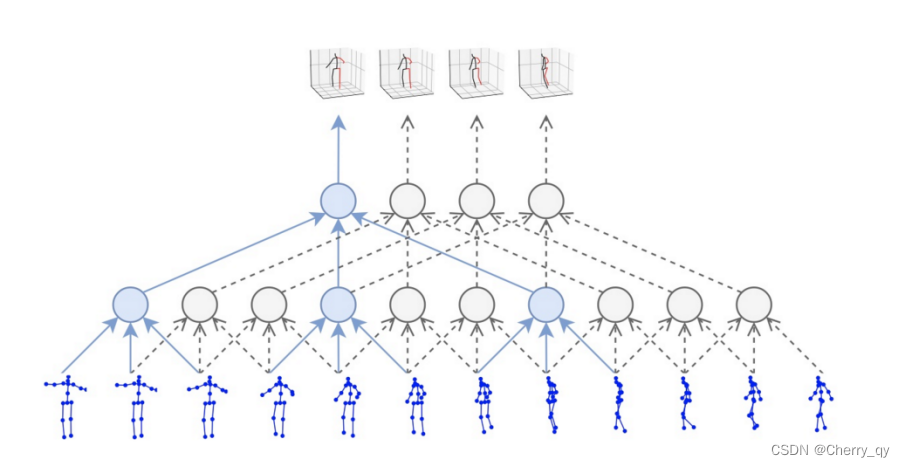
VideoPose3D [7] 以 2D pose 序列作为输入,利用 Temporal Convolutional Network (TCN) 处理序列信息并输出 3D pose。TCN 的本质是在时间域上的卷积,它相对于 RNN 的最大优势在于能够并行处理多个序列,且 TCN 的计算复杂度较低,模型参数量较少。在 VideoPose3D 中,作者进一步利用 dilated convolution 扩大 TCN 的感受野。具体的网络结构与 SimpleBaseline3D 类似,采用了残差连接的全卷积网络。除此以外,VideoPose3D 还包含了一种半监督的训练方法,主要思路是添加一个轨迹预测模型用于预测根关节的绝对坐标,将相机坐标系下绝对的 3D pose 投影回 2D 平面,从而引入重投影损失。半监督方法在 3D label 有限的情况下能够更好地提升精度。