Baseline模型
首先,将resnet50作为baseline model,方便后续进行对比,以下是我baseline的训练参数,使用了前10000张图片进行训练,一方面是因为1000张数量确实有点少,另外一方面是怕数据如果不是打乱存放的话,有可能前1000张大部分都是属于同一类数据导致不均衡。
model = timm.create_model('resnet50', pretrained=True, num_classes=2)
model = model.cuda()
epoches=10
img_size=384
batch_sizes=32模型选择
对于不同的预训练模型效果肯定是大不相同,尤其对于Transformer模型来说,模型特性使得对这种大数据集有天然的优势,在赛题给定200M用thop库衡量参数量的情况下,理论上来说模型越接近于200M效果肯定是越好的,所以打印了以下模型的参数量作为参考。另外,预训练模型在imagenet1K 和21K训练的效果肯定也有所不同,所以也需要实验验证。
| Model | Params | epoch | img_size | batch_size | Train_size | Score |
| Resnet50 | 23.5 | 10 | 384 | 32 | 10000 | 0.84 |
| vit_base_patch32_224 | 85.6 | 10 | 224 | 32 | 10000 | 0.5 |
| vit_base_patch32_384 | 85.6 | 10 | 384 | 32 | 10000 | 0.52 |
| vit_base_patch32_224_in21k | 85.6 | 10 | 224 | 32 | 10000 | 0.5 |
| efficientnet_b0 | 10 | 384 | 32 | ALL | 0.59 |
结果如上表所示,其中存在很多问题仍待解决:
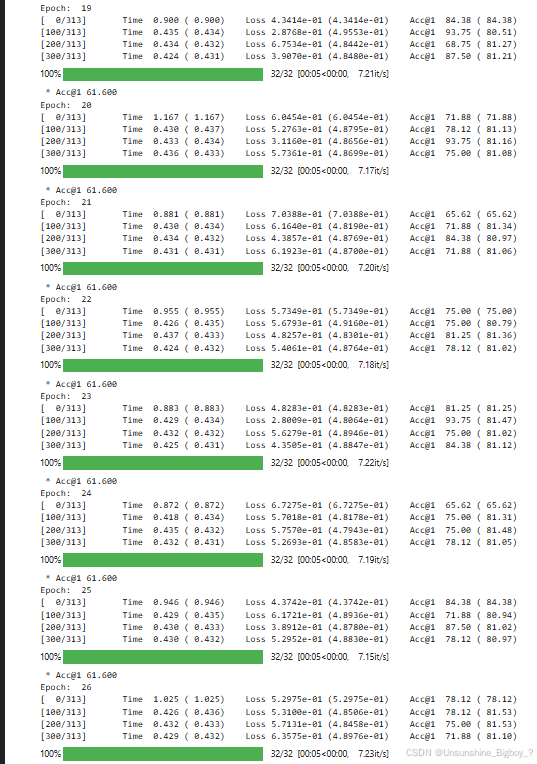
1. 对于Vit模型,使用同样的训练代码,但是都存在在验证时测试集Acc不更新的问题,也就是在不同的epoch中,测试集的验证Acc一直维持在61.6,如下图所示,包括也尝试了SwinTransformer也是同样的问题:

2. 针对efficientnet_b0 模型来说,别人的结果最终全量数据训练3个epochAcc可以到0.99,但是最终复现失败,整个训练过程貌似随机性比较大。
3. 针对img size对最终的结果是否有影响暂时还未验证。
Vit模型验证集Acc保持不变的问题
针对这个问题尝试了以下思考:
1. 对于Vit模型来说,需要大量的数据来表现其在大数据上的能力,所以可能是训练轮次或者训练的数据量不够,于是我尝试增大epoch和使用全量数据进行训练和验证,但是下面是我的模型设置以及最终结果,10000个数据作为训练,跑了26epoch都仍然还是没有改变。使用全量数据也是同样的结果。
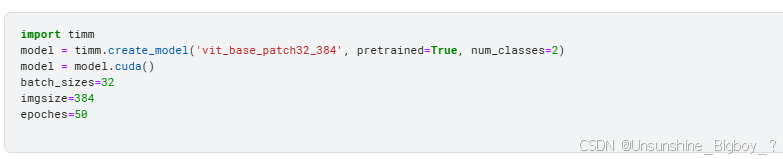
2. 有可能是因为进行了img的resize,因为Vit模型其实对输入有非常明确的定义,图片大小打印出来为512,resize至384可能和256还是存在区别。于是,我尝试将效果较好的effcienctnetb0也resize成384,其实效果还是跟256差不多的。Vit模型哪怕使用了224验证集也是一直卡在61.6,所以应该不是size的问题。
3. 模型的问题,我尝试了混合模型,vit_base_resnet50_384,结果依旧一样。
4. 预训练的问题,尝试不使用预训练模型,从0开始训练,结果依旧没有改变。
5. 训练过程的代码问题,尝试打印Vit和resnet输出的结果进行比较,
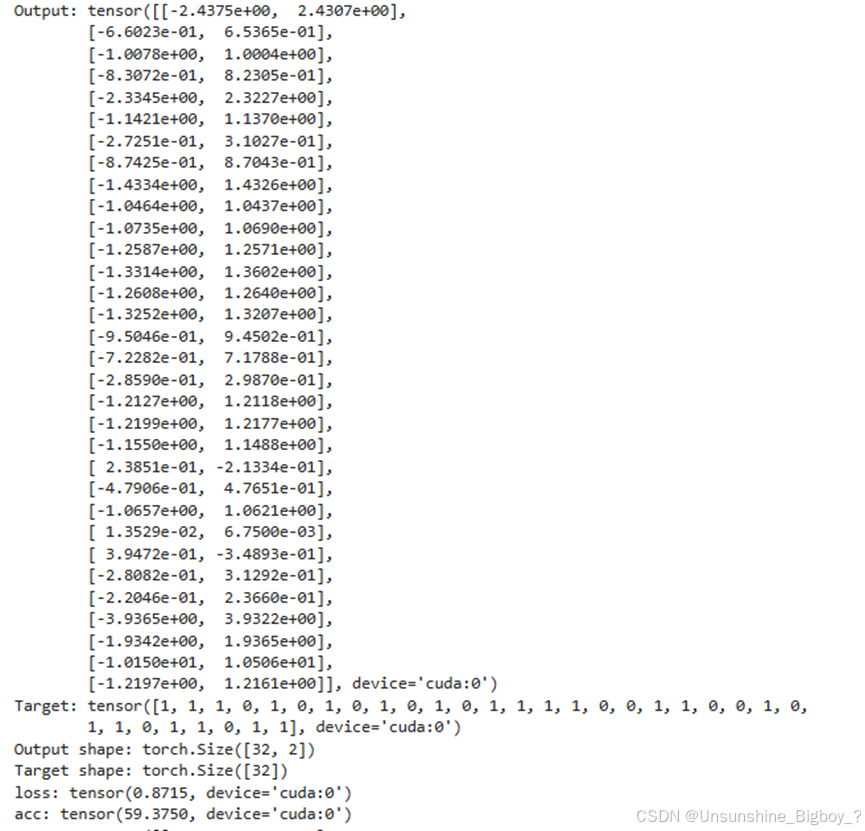
下图分别是Vit在epoch 1和 epoch 2的结果,可以看到模型将所有数据都预测成了第一类,完全不存在第二类,但是loss是不相同的,Acc确实一样的,说明Vit模型在交叉熵损失上是有区别的,也就是输出的概率在不同的epoch是不一样的,但是计算的ACC却是一样的。两者的计算方式不一样,对于损失来说,是经过softmax之后输出0~1的概率,而对于Acc来说,只需要直接取最大值对应的标签就行。所以两者的相对大小没有改变,但是整体变大了,使得ACC没有变,但是经过softmax之后的损失变小了。可能在这里存在问题。


对于resnet50来说,它没有完全将所有的数据都分类成0,还是有少许分类成1的。