
文章目录
前言
在前面的章节中,详细讨论了循环神经网络(RNN)及其衍生模型,经过对RNN的不断改良,它们现在已经具备了长期记忆的能力,这无疑是语言模型领域的一项重大突破。然而,现在的多模态技术以及GPT的出现,绝大多数都选择了基于Transformer的架构,这是为何呢?
本章节将围绕这个问题展开,将深入讲解自注意力机制,揭示这个如今在整个自然语言处理领域产生了深远影响的技术的精髓。这将为读者理解后续的BERT模型、GPT技术,以及多模态技术如CLIP等内容奠定坚实的基础。本文的目标是让读者在学习这部分内容后,对这些技术有一个全面而清晰的认识,并能构建完整的知识体系。
https://arxiv.org/pdf/1706.03762 Transformer 原文链接
一、Seq2Seq
在学习Transformer的前提要明确什么是Seq2Seq,即Sequence to Sequence模型的简称,通常由两部分构成一部分是Encoder(编码器)和Decoder(解码器)。和字面意思一样就是利用一个序列去预测另一个序列的功能,如文本摘要、机器翻译、对话生成等。而Transformer 就是Seq2Seq这一架构的经典模型。
1.1 Seq2Seq的基本架构
首先看下Seq2Seq的最简单的构成。编码器的主要职责是将传入的自然语言文本进行解析,之后将其转化为计算机能够理解和处理的向量格式。例如,在机器翻译场景中,Encoder(编码器)将“我喜欢吃苹果”这样的句子编码为一连串的向量,这些向量包含了原文的语义信息,被编码成易于计算机识别的数据形态。随后,Decoder(解码器)将这些向量解码,生成目标语言的句子,如将之前的句子翻译为"I like to eat apples"。在这个过程中,常用循环神经网络(RNN)或其他高级形式长短时记忆网络(LSTM)来实施编码环节,借此有效捕捉并处理输入序列的特征。
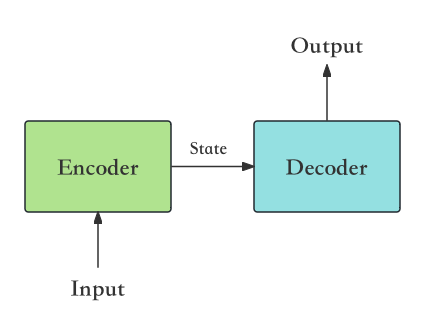
Seq2Seq架构讲解
如上图所示,Seq2Seq模型的基本架构包括几个关键组件。首先,以句子“我喜欢吃苹果”作为Input输入。这个输入句子被编码器Encoder处理,编码器的核心作用是将输入的自然语言句子转化为计算机可以理解和处理的向量表示形式。编码后产生的状态State则代表了原始输入句子的向量化表达。
该状态随后被传递到解码器Decoder,解码器的任务是将这些向量转换回自然语言文本。在本例中,经过解码器处理的结果是输出Output:“I like to eat apples”。这一转换过程展现了Seq2Seq模型的核心能力 —— 使用序列数据(本例中的自然语言句子)生成新的序列数据,即用一个句子来预测另一个句子。
因此,如果一个模型能够接收到一个序列作为输入,并且生成另一个序列作为输出,那么它可以被归类为Seq2Seq模型。这个输入序列和输出序列可以是不同长度的,也可以是不同类型的数据,只要模型能够有效地进行序列到序列的转换。
Seq2Seq模型在自然语言处理中的应用最为广泛,比如机器翻译、文本摘要、对话生成等任务,但它也被用于其他领域,如语音识别、时间序列预测等。
1.2 Seq2Seq的框架实例
本节介绍了Seq2Seq的基础结构,在实际应用中,编码器(Encoder)和解码器(Decoder)的具体实现可能采用不同的神经网络架构,如循环神经网络(RNN)、长短期记忆网络(LSTM)或卷积神经网络(CNN)。这些选择依赖于特定任务的需求和性能目标。
为了加深理解,本节将重点讲解基于RNN的Seq2Seq模型。通过这种方式,读者可以获得对Seq2Seq模型细节方面更深入的认识。这样的知识基础将有助于读者在后续内容中更好地理解模型的内在机制以及如何针对特定的应用进行调整和优化。
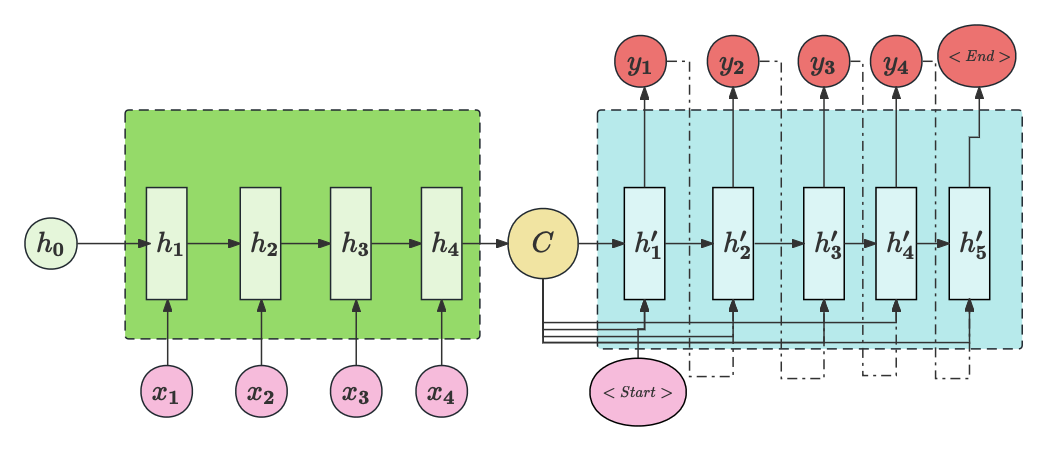
上图展示了基于RNN的Seq2Seq模型。模型将输入序列 x 1 − x 4 x_1-x_4 x1−x4 分别在不同的时间步送入 RNN 中进行编码,得到对句子的编码向量 C C C。这个 C C C 可以有多种表达方式。最简单的方法是将编码器的最后一个隐状态赋值给 C C C。此外,也可以对最后的隐状态进行一些变换,比如线性变换,得到 C C C;或者对所有的隐状态进行变换得到 C C C。具体而言, C C C 可以是 h 4 h_4 h4,也可以是对 h 4 h_4 h4 进行线性变换后得到的结果,或者是对全部隐藏状态结果进行线性变换得到的结果,取决于任务需求和模型效果。
在解码器部分,使用了整个句子的向量表示
C
C
C 和特殊的起始符号 <Start> 作为解码器的初始输入。接着,解码器会开始生成输出序列,这个过程类似于RNN的推理过程。在每个时间步,解码器会生成一个单词,并将上一个时间步的输出作为当前时间步的输入,以及上一层的隐藏层结果和句子向量
C
C
C一起辅助生成当前时间步的输出。这个过程会持续进行,直到模型预测出结束符号 <End>,此时解码结束,模型停止计算,生成了完整的解码序列。
二、Transformer
在详细介绍Transformer之前,先对这个厉害的模型下一个简单的定义,Transformer模型就是利用注意力机制摆脱了RNN和CNN架构,从而实现了并行能力和总体性能上升的seq2seq模型。剩下的和其他的seq2seq模型并无区别。先对这个模型来一个浅显的定义,然后后续学习完后再来理解这句话的含义吧。
2.1 Transformer的整体架构
首先来看下模型的整体架构:
一眼望去,十分复杂,错综复杂的数据流向,和上文中的seq2seq就不是一个量级的模型,为何是这么复杂的结构呢?他怎么还会是一个seq2seq模型呢?他的encoder和decoder在哪里呢?
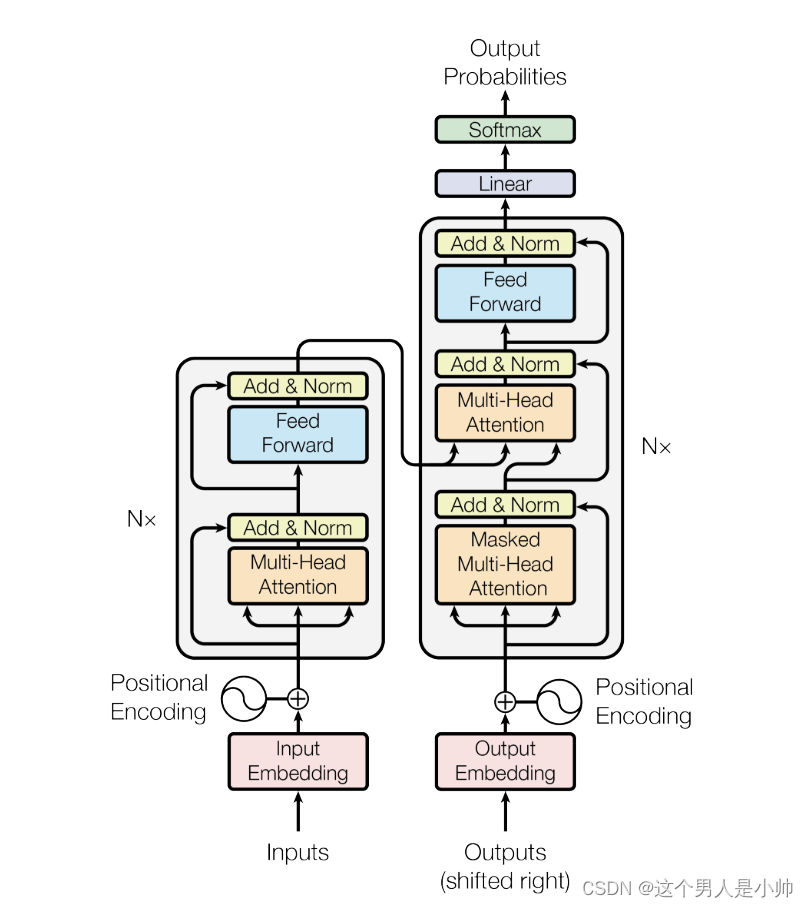
带着这些疑问,对上图进行梳理,找出图中的encoder和decoder,输出输出部分进行逐个击破。
首先对上图的区域进行划分,便于类比上文中描述的seq2seq模型。
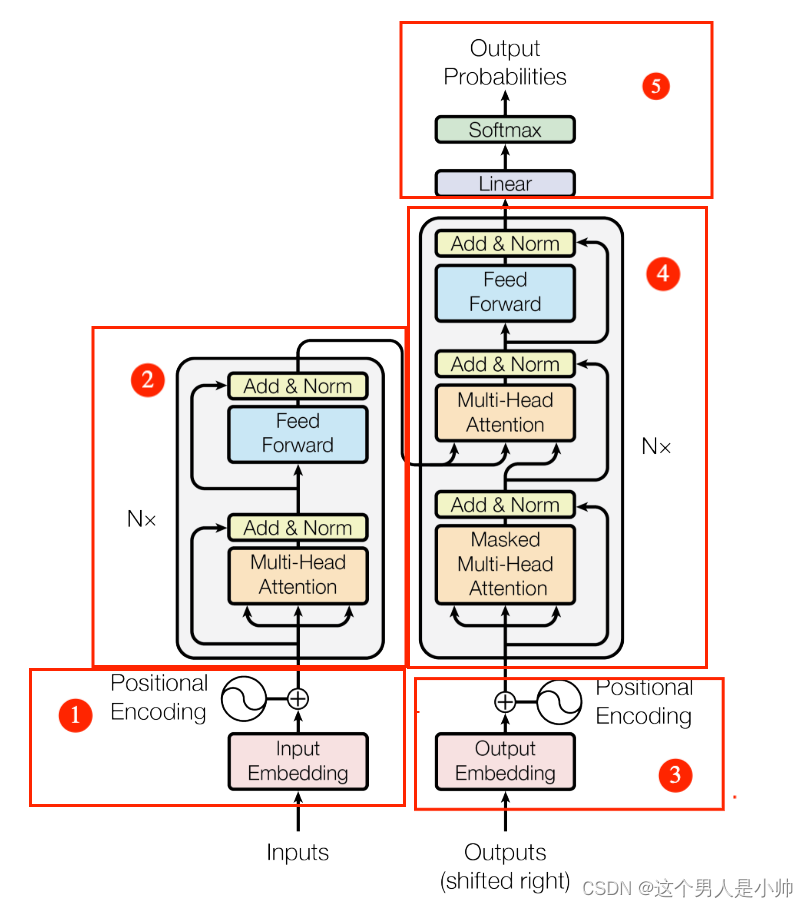
- 第一个部分是Encoder的输入。
- 第二个部分是Transformer的编码器部分,即Encoder。
- 第三个部分为解码器的输入,即上文中的
<Start>以及模型对前文的预测结果会再次送入到decoder中用于对后文的预测作为模型的部分输入。(如果对这部分存在疑惑可以回过头再此看下RNN的那个实例)。 - 第四个部分是解码器,即模型的Decoder。
- 第五个部分是模型的预测结果模块,模块输入一个向量,输出预测的结果。
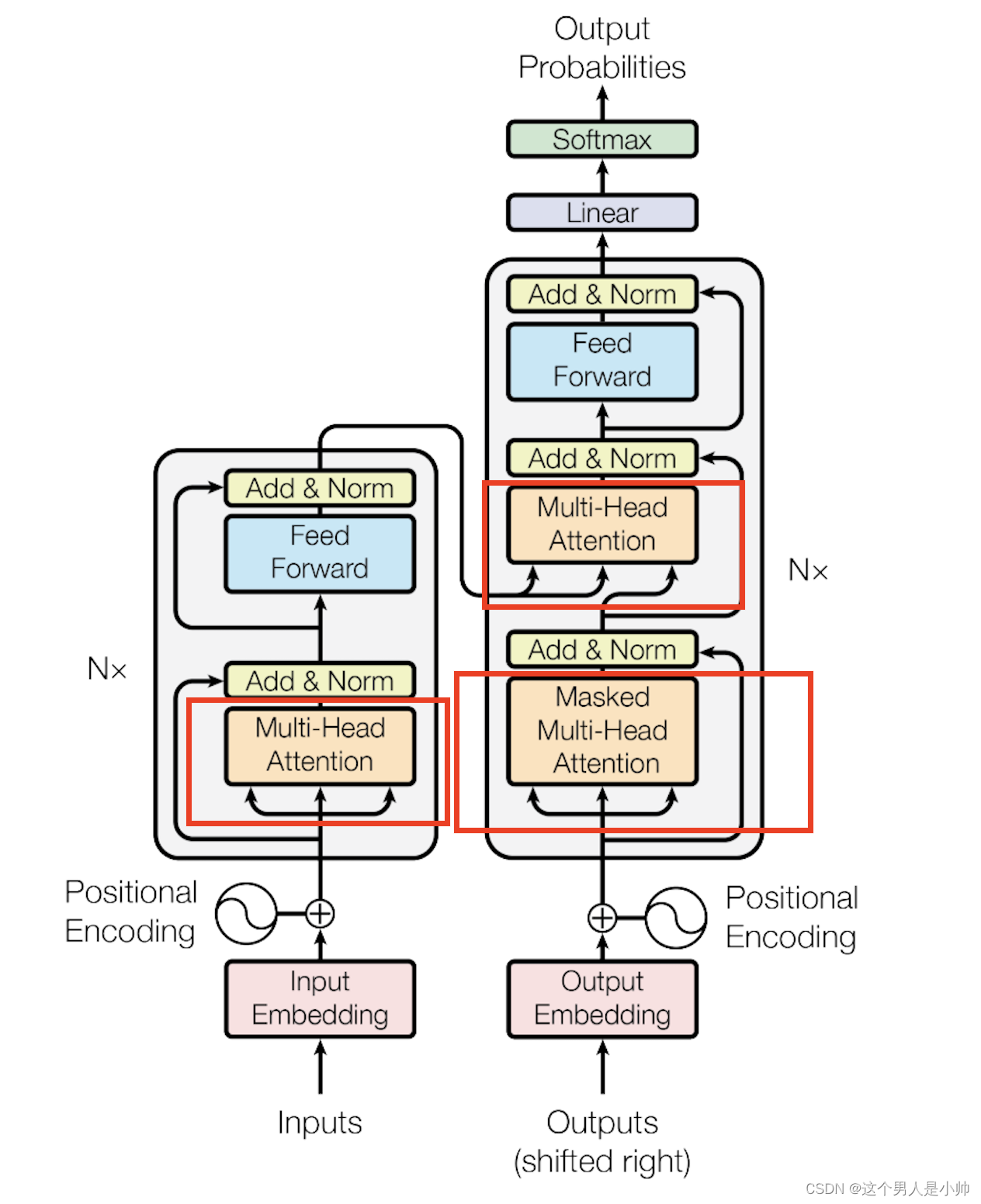
现在看起来这个Transformer的图结构简单的多。还有一个细节存在这个图中就是Encoder和Decoder部分有一个小的N*(表示N倍),即编码部分是由多个Encoder block构成,解码部分也是由多个Decoder block构成。那么整体的结构简化成下图:
可以看到Transformer整体还是由Encoder和Decoder两个部分组成,而且编码器和解码器都包含6个block(原论文中是默认6个块)。
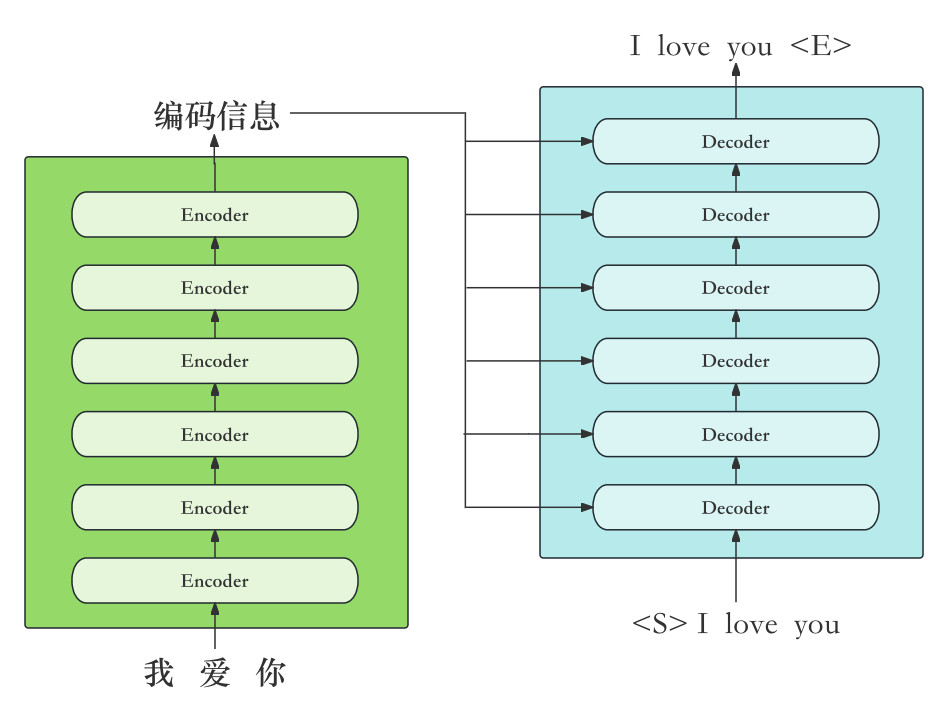
通过以机器翻译(由中文我爱你翻译为英文I love you)为例来讲解Transformer的运作机理
2.2 Transformer的输入
首先来看模型的输入部分,分为两种,一种是Input Embedding(输入信息向量),一部分是Positional Encoding(位置编码),接下来分开进行讲解。
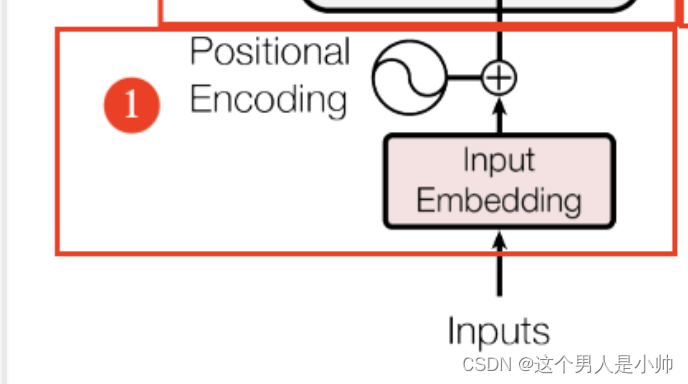
2.2.1 Input Embeding
先来看输入信息的Embedding,即就是将输入的句子进行向量化。
这个input Embeding 具体是如何得到的呢?
可以采用 Word2Vec、Glove 等算法预训练得到,也可以在 Transformer 中训练得到。以Word2vec举例子大致的过程如下:
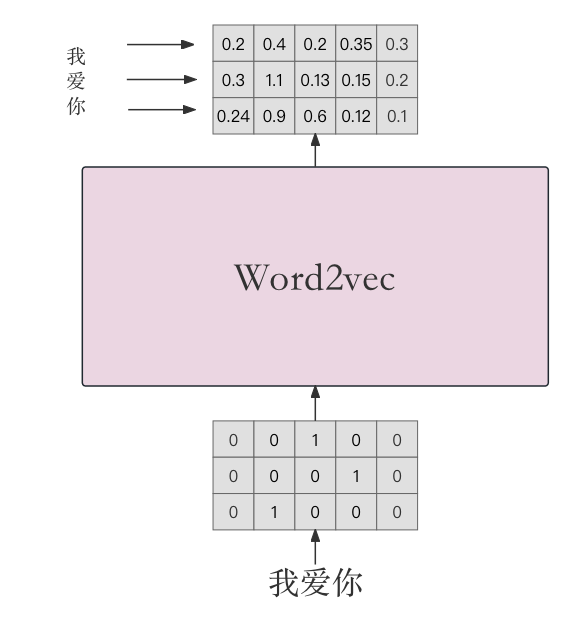
在这个流程中,首先将“我爱你”进行独热编码作为Inputs的输入,然后将编码后的向量作为送入到Word2vec模型中。Word2vec模型将对每个字进行编码,并输出一组向量,其中每一行表示输入句子中每个字的嵌入表示。这组向量矩阵构成了输入句子的嵌入矩阵,作为Transformer模型的Input Embedding模块的输出,用于后续的处理和训练。
2.2.2 Positional Encoder
位置编码(Positional Encoding)是Transformer模型中用来为输入序列中的每个‘token’(理解成字也可以)提供位置信息的一种技术。由于Transformer模型没有像RNN那样显式地处理序列中的位置信息(RNN顺序输入符合人类语言方式故此不需要),因此需要一种方式来为模型提供位置信息,以便模型能够区分序列中不同位置的单词或符号。
在处理序列数据,尤其是语言这种高度依赖于顺序的数据时,位置信息是至关重要的。没有位置信息,模型就无法理解词与词之间的顺序关系,从而可能会导致理解上的重大偏差。例如,句子“我爱你”和“爱你我”,虽然包含相同的词,但顺序的不同改变了句子的整体意义和语境。
在没有位置信息的情况下,如果模型只是简单地处理单词的嵌入而不考虑它们在句子中的位置,那么“我爱你”和“爱你我”这样的句子在模型看来可能没有差异。位置编码是向模型提供序列中单词顺序信息的机制。由于Transformer模型并不是专门针对自然处理序列数据的,它本身并不理解单词的位置信息。位置编码解决了这个问题,它向模型提供每个单词在序列中的位置信息。这对于正确理解和生成自然语言至关重要,因为语言中单词的顺序会影响句子的整体意义。
初次学习Transformer的读者在明确了位置编码是什么后可以直接跳到Encoder部分,并不影响后续的阅读。如果十分感兴趣的话可以在学习了重要的部分后再来看这部分的内容
由于位置编码涉及的知识篇幅较长单独占用一片blog,需要深入学习的同学可以点击这里。
2.2.3 Transformer的输入
上文中介绍模型的输入部分分为两种,一个是单词的嵌入表示(Input Emebeding)另一部分是位置编码(Positional Encoding)加和操作得到了最终的模型输入。
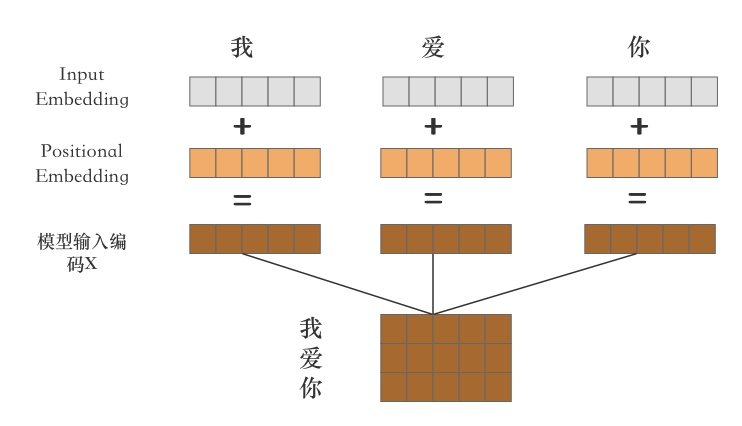
最终得到了输入信息表示形式使用 X X X 来表示,送入到下一阶段的Encoder中进行编码。
2.3 Transformer的自注意力机制
在深入研究编码器(Encoder)之前,首先需要理解自注意力机制,这是因为自注意力机制是 Transformer 框架中的核心组件,它被广泛应用在编码器和解码器中。在掌握了自注意力机制如何工作后,便于理解和学习后续的相关内容。事实上,引入自注意力机制和位置信息是 Transformer 架构的精髓之处,它们实现了计算的并行化,大幅提高了模型的运行效率,并有效处理了不同距离之间的单词关联问题。
通过整体架构图可以看到编码器和解码器中均采用了这种操作。
2.3.1 注意力机制
在学习自注意力机制之前,先明确下什么是注意力?
“ 提到注意力,我不禁想起小时候老师经常训诫我,强调只有将注意力集中在学习上才能取得好成绩,然而我总是被《七龙珠》漫画吸引,结果导致期末成绩低迷。”
从这个角度看,要想获得期待的结果,必须把大部分注意力放在正确的地方。如果把上述例子中的`“我(学生)” 比作一个神经网络,那么老师就像是训练模型的人,期望模型(学生)能将更多的注意力放在学习上。这样,在考试(测试)时,通过之前的训练,学生(神经网络)能正确完成试卷,进而提升成绩。在上述例子中展示了注意力机制的重要性:通过使模型专注于关键信息,从而提升其性能。
那么注意力机制该如何表示出来呢?
看下面这个图片:

观察上面这张图片,重点关注图中标注的“锦江饭店”四字。如果你被要求注意这些字,你的视觉焦点大多集中在这个区域,对周围环境的关注度自然减少。例如,如果现在问你旁边的楼梯共有多少节,你可能会感觉这个问题有些突兀,大部分注意力都会聚焦在文字所在的区域,而对周围的细节视而不见。如下图所展示:
人的注意力是有限的,当我们将大部分注意力投入到某一特定区域时,其他信息往往被忽略。比如,在观看图中文字时,可能会将大约80%的注意力集中在文字上,19%的注意力分散在文字周围的区域,而只有1%的注意力覆盖更远的区域。这样的分布可以通过百分比来表示。

在技术中,类似的注意力机制也可以用百分比来描述,其中模型会学习在处理输入信息时如何分配这些百分比,以便优先处理最关键的信息。这种方法不仅帮助模型专注于最重要的数据,还模仿了人类如何在大量信息中筛选出关键细节的方式。
那么,如何表示注意力机制呢?使用百分比的方式来描述对不同区域的关注程度即可。
百分比信息是如何得到的呢?不同的注意力机制会有不同的答案实现方式。其中,自注意力机制(Self-Attention)是一个典型的例子。
2.3.2 权重矩阵 W W W
在神经网络中将权重矩阵使用 W W W 来进行表示, X X X 作为模型的输入。在Transformer中也是相同的方式。
权重矩阵 W W W 在神经网络中的作用是什么?
在线性代数中,权重矩阵 W W W 的作用可以被理解为将输入向量 X X X 投射到一个新的特征空间。如果这种解释显得过于抽象,可以从一个更直观的角度来理解:可以将输入向量 X X X 中的每一个维度看作是一个特征,而 W W W 作为权重系数,通过不同的组合比重将这些特征融合,从而生成新的特征。这些新生成的特征随后被用作模型后续计算的基础。
在之前的博文中讲过神经网络本质上就是去拟合各种各样的函数,而 W W W 矩阵就是函数的权重,激活函数使得神经网络可以让模型拟合非线性函数,神经网络通过堆叠多层,并在每层之间使用激活函数,学习复杂的函数,能够解决异或这样的复杂问题。
明确了神经网络就是函数的特性,现在举例子。
以函数 X 1 = f ( X ) X_1 = f(X) X1=f(X) 为例, X X X 是原始输入, X 1 X_1 X1 即是经过函数映射变换后的结果, 二者都是关于同一事物的不同表达形式。所以 f ( X ) f(X) f(X) 是对 X X X 的一种新的解释或显示方法。
如果将其类比到一个人穿衣服,原始的人就是
X
X
X,穿上衣服的人就是
f
(
X
)
f(X)
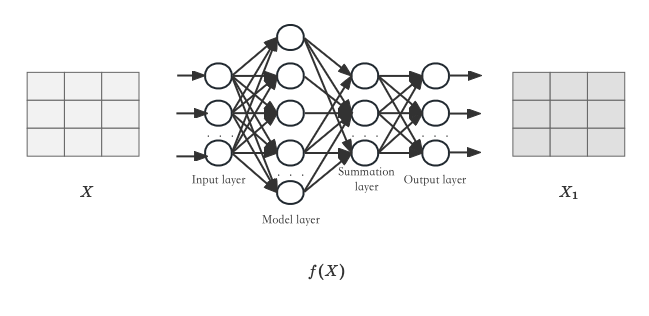
f(X),他们本质上是同一个人,但其展现给外部的形象和感受是不同的。神经网络的权重矩阵就是这样的一件衣服,可以改变输入数据的表现形式,但不改变其本质。回过头来再下图展示的神经网络结构。
上图中展示了一个简单的三层网络,包括输入层、隐藏层和输出层。不包含激活函数和偏置项,在这个网络中
W
X
WX
WX 操作那就更简单了,就是不断的加权求和加权求和,最后得到一个新的表达形式
X
1
X_1
X1 还是上文例子中的那种关系。它们之间的本质联系仍得以保留。
2.3.3 Self-Attention
在明确了以上知识的情况下,回过头来看Self-Attention究竟做了什么?也就是下图中标红的模块具体做了些什么呢?
论文中给出了这个模块的内容结构图:
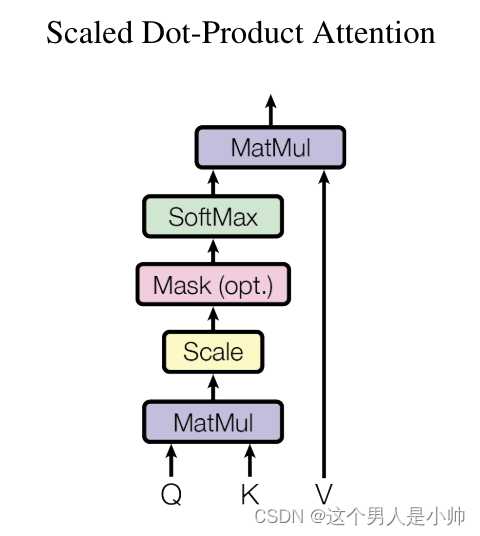
2.3.3.1 Self-Attention 的 Q,K,V
首先来看模型的输入部分,一共输入了三个矩阵 Q , K , V Q,K,V Q,K,V。其中这个 Q Q Q 指的是Querry, K K K 是Key, V V V 是Value。不需要理解是什么意思,先看下究竟做了什么呢?在上文中说过模型输入实际上是Positional Encoding 和 Input Embedding的加和矩阵 X X X,如何变成的 Q , K , V Q,K,V Q,K,V 呢?
先来看下输入矩阵 X X X 是如何变成 Q , K , V Q,K,V Q,K,V 的?
实际上只是利用了三个不同的权重矩阵
W
W
W对
X
X
X ,做了三次线性变换。具体过程如下:
Q
=
X
W
q
K
=
X
W
k
V
=
X
W
v
\begin{align*} Q &= XW_q \\ K &= XW_k \\ V &= XW_v \end{align*}
QKV=XWq=XWk=XWv
在上文中举例,提及了通过权重矩阵 W W W 进行转换得到的 X 1 X_1 X1 矩阵,事实上与初始的矩阵 X X X 代表了相同的信息内容。
这意味着,当Transformer模型把输入 X X X 复制成三份,并分别通过 W q W_q Wq、 W k W_k Wk、 W v W_v Wv 进行线性变化时,实际上获取的是 X X X 经过不同 W W W上的不同表示。这些不同的形式,无论是经过 W q W_q Wq 还是 W k W_k Wk 的变化,仍旧和输入信息一致,每一行是一个词汇的嵌入表述,只不过 W W W的权重不同,关注了不同的信息重点。简而言之,虽然这些经变化后的矩阵呈现出不同的数据状态,但它们的核心都是对原始输入 X X X 里每个单词嵌入表示的不同角度的阐释。
为了更加直观下图展示整体
Q
,
K
,
V
Q,K,V
Q,K,V计算的整体过程。
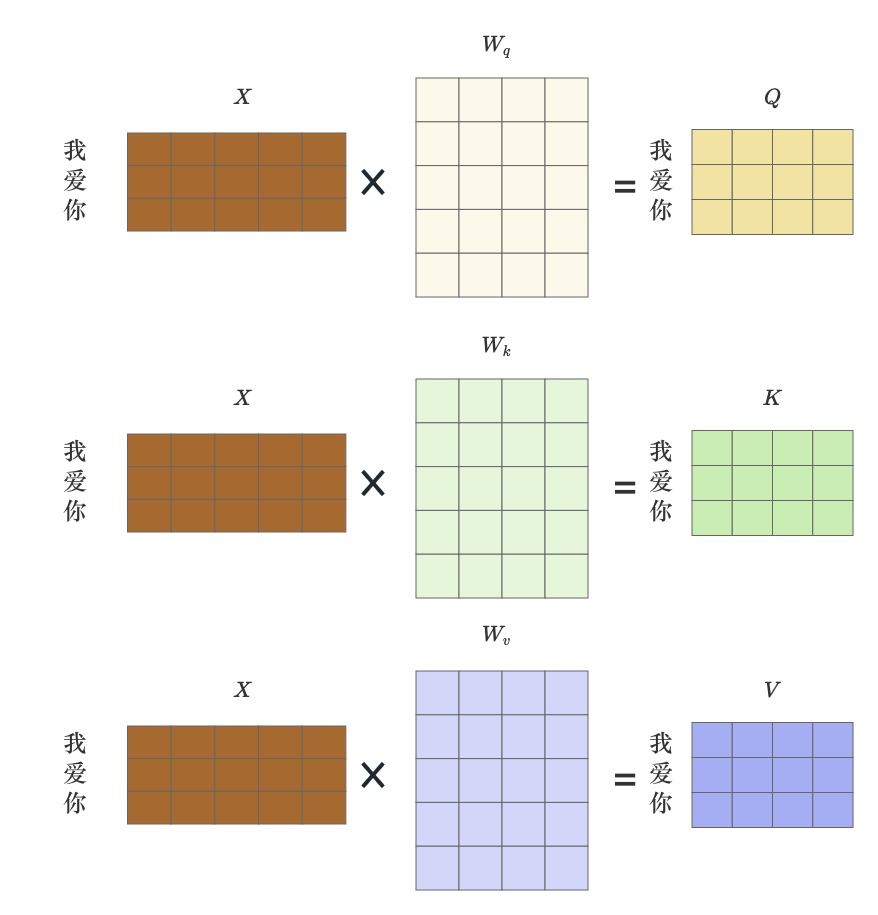
在当前阶段,已经通过权重矩阵 W q W_{q} Wq、 W k W_{k} Wk、 W v W_{v} Wv 对"我爱你"这三个词语进行了向量化的转换,得到了它们的不同表示形式,即 Q Q Q、 K K K、 V V V矩阵,准备工作做好了。
2.3.3.2 注意力在Transformer的作用
说了半天这个注意力能有什么用呢?这个形式的在翻译任务上有什么用呢?
举个例子
当尝试将 “昨天我吃了苹果” 逐字翻译成英文时,我们得到 “yesterday I eat apple” ,明显违反了英语语法。正确的翻译应是 “yesterday I ate an apple” 。这一问题凸显了翻译过程中必须注意的关键点:单词 “吃” 的翻译不单单依赖于它自身,还受到 “昨天” 这一时间背景词的影响。这正是注意力机制的作用——它不仅关注单独的单词,还在乎单词之间的联系。
就是在翻译过程中要翻译 “吃” 的时候考虑昨天,计算内部就是将两种向量做加法,使用加法“吃+昨天” ,那么具体使用怎么样的配比呢?
如何在翻译过程中平衡“吃+昨天”对翻译结果的影响?直觉上将80%的注意力放在“吃”上,而20%放在“昨天”上,数值如何得到呢?这就是 Self-Attention 的应用。模型输入是
X
X
X 每行向量为一个词的矩阵,内积操作仅通过一个矩阵无法完成的。(
Q
,
K
Q,K
Q,K的作用),一个不行就使用两个,复制一份矩阵
X
X
X ,两个相同的矩阵做乘法不就是内积操作吗?每个单词和不同单词进行内积得到一个数值,有没有更好的方法呢,在复制得到的两个
X
X
X 上都使用
W
W
W 权重矩阵不是更好嘛,就能依靠深度学习的可学习特性,实现这个数值按照目标的方向优化了,因此通过输入
X
X
X 依赖于
W
q
W_{q}
Wq、
W
k
W_{k}
Wk分别生成
Q
Q
Q 和
K
K
K 这两个矩阵,并通过它们的矩阵乘法计算内积,便能确定每个单词对其它单词的注意力。然后和
X
X
X 矩阵做乘积就实现了加权求和。 同理,再次使用
W
v
W_{v}
Wv 权重矩阵对
X
X
X 进行可学习操作得到
V
V
V 矩阵代表基础的单词向量表示
X
X
X 模型的性能不是会更好嘛 (
V
V
V的作用) ,因此,上例子中的“吃”和“昨天”。使用
Q
K
QK
QK 得到的注意力系数,和
V
V
V 矩阵做乘积。就会得到了:
吃的 E m b e d d i n g = 80 % 吃的 E m b e d d i n g + 20 % 明天的 E m b e d d i n g 吃的Embedding = 80\%吃的Embedding+ 20\% 明天的Embedding 吃的Embedding=80%吃的Embedding+20%明天的Embedding
用于后续的翻译任务,得到了一个融合了不同词义信息的新矩阵。这个新向量最终将输入模型进行翻译,显著提高了翻译的准确度。
2.3.3.3 注意力分数的计算过程
论文中的给出的实际计算过程如下:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V
- Q Q Q 代表Query矩阵;
- K K K 代表Key矩阵;
- V V V 代表Value矩阵;
- d k d_k dk 是Key矩阵的维度,用于缩放内积的大小,防止梯度消失;
- softmax 函数用于将内积转换成权重分布。
下图直观的展示了
Q
K
T
{QK^T}
QKT计算注意力矩阵的过程:
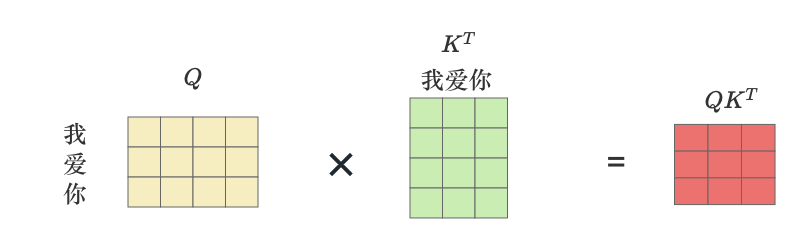
上文中描述
Q
Q
Q 矩阵的第一行表示的是 “我” 的词向量而
K
T
K^T
KT 矩阵的第一列也是 “我” 的词向量嵌入表示,生成
Q
K
T
{QK^T}
QKT中(1,1)的数值,再次通过 “我” 和 “爱” 进行乘积, “我” 和 “你” ,完成计算 “我”这个字和全部字的内积结果,从而得到注意力系数。
现在看起来本质上就是一个词向量和所有的词向量做了一次内积的结果作为注意力。然后通过Softmax层计算最终的注意力系数:

2.3.3.4 Self-Attention 的输出
在使用Softmax操作后
Q
K
T
{QK^T}
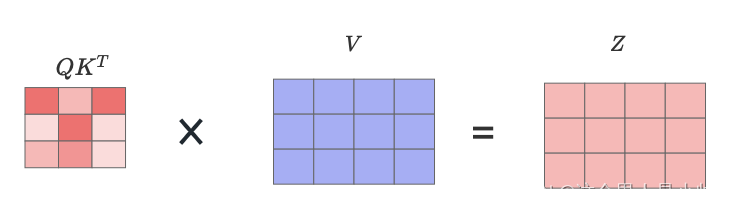
QKT 矩阵中的每一行的和为1,第一行表示第一个单词和句子中全部单词的注意力分数,第二行同理。现在权重找到了只需要进行加权求和,权重是
Q
K
T
{QK^T}
QKT 而 值 就是通过线性变换的
V
V
V 矩阵:
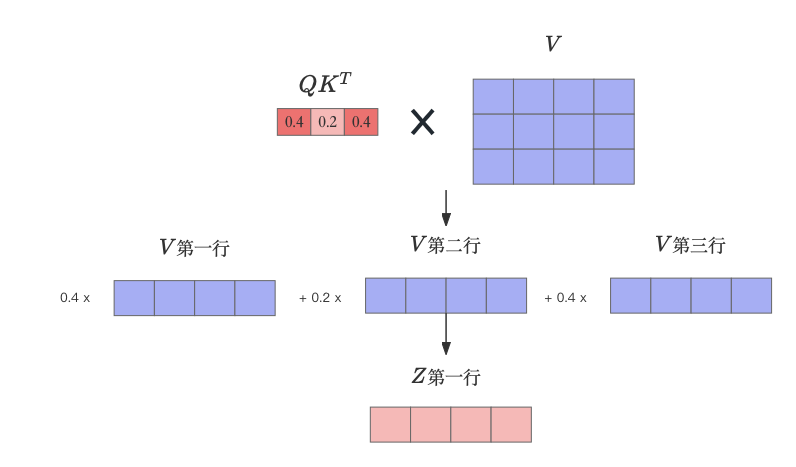
从而每个单词的向量表示都融合经过注意力计算相关联的单词信息,生成了最终的输出
Z
{Z}
Z 矩阵。下图中展示了计算
Z
{Z}
Z 矩阵第一行的细节便于读者理解这种行为。
2.3.3.5 Multi-Head Attention
在上文中,探索了通过自注意力(Self-Attention)机制如何计算出最终的输出矩阵 Z Z Z。目前,将焦点转向多头注意力(Multi-Head Attention)机制。事实上,前一段中的自注意力可以被看作是多头注意力中的一个单独的“头”——它实质上是在多头机制中的单个注意力计算方法。多头注意力机制的创意源于这样一个概念:正如卷积神经网络通过部署多个卷积核来从不同的角度捕捉和分析数据以提升模型的性能,多头注意力的目的也在于使模型能够从多个层面关注数据,从而提高其性能。
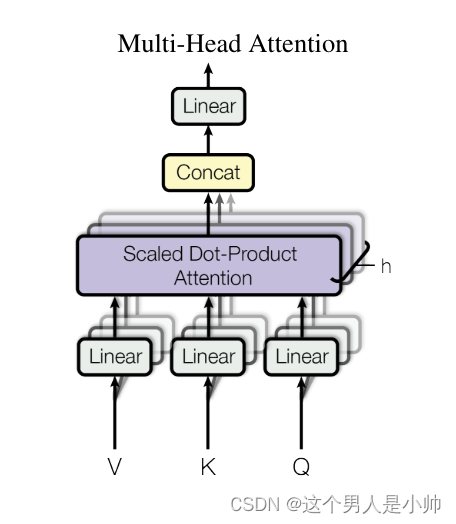
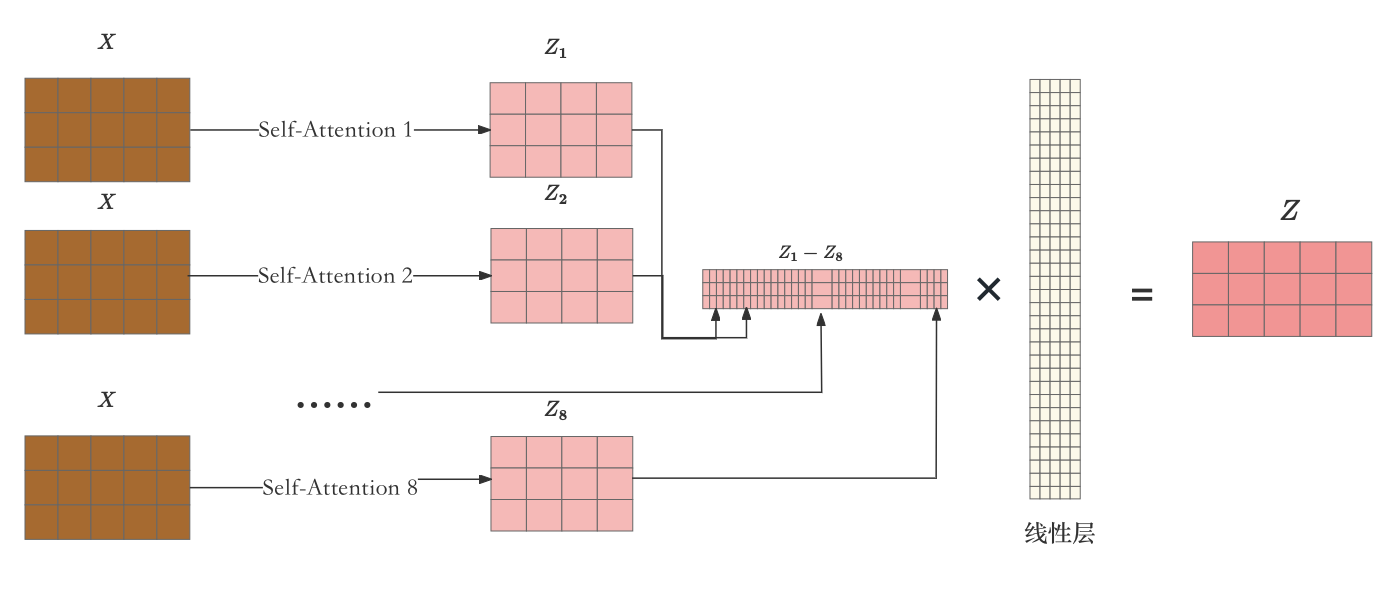
想象人类在分析任何事物时总是希望多角度观察,以获得更准确全面的认识,这就是为什么多个卷积核和多头注意力极为重要。它们赋予模型以类似多角度观察的能力,因而模型能通过整合多种信息流来提升其综合识别和处理数据的能力。下图是论文中 Multi-Head Attention 的结构图:
首先,使用输入信息
X
X
X计算
Q
Q
Q、
K
K
K、
V
V
V矩阵得到单个头的结果(注意一个头一组
Q
Q
Q、
K
K
K、
V
V
V矩阵),将单个头结果送入Concat模块进行拼接,再次送入到线性层作为模型做终的输出。论文中给出的头数
h
=
8
h=8
h=8。就是采用了多个的Self-Attention,这样每一次就会得到多组的
Z
i
Z_i
Zi 拼接,然后松土线性层生成新的特征矩阵。具体的细节如下:
值得注意的是文中采用了多层的Encoder架构,所以每层里面都有多头注意力机制,为了保证维度的一致行, 不至于出现维度太大的情况,会在线性层将维度变成输入信息维度一致的,所以输入
X
X
X 和输出
Z
Z
Z 的维度信息是一致的。
2.4 Encoder 的结构信息
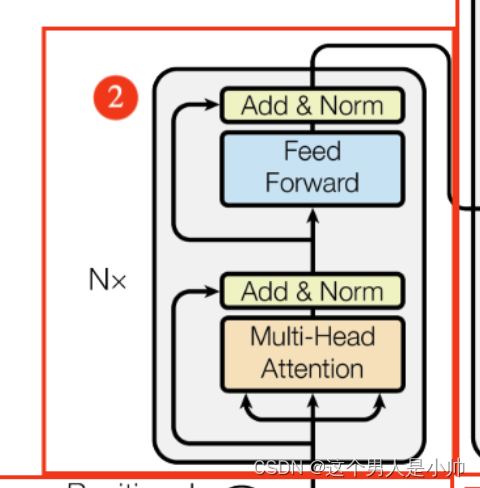
上文中讲解了模型的输入信息,将输入信息送至第一个Encoder模块中。数据经过多个Encoder层最终输出数据编码结果,用来指导模型的Decoder解码任务。下图是模型的Encoder模块细节:
简单的看下Encoder是由Multi-Head Attention、Add & Norm、Feed Forward、Add & Norm四个小模块组成的。前文中已经在注意力部分对多头注意力进行了详细的解释,本部分只对Add & Norm和 Feed Forward 详细讲解。
2.4.1 Add & Norm
在上图可以直观的看到 Add & Norm有两处,两处接收的信息不同,但是功能都是一样的,第一个接受的是多头注意力的输出结果和Encoder的输入信息,具体的计算公式如下:
X ′ = L a y e r N o r m ( X + M u l t i H e a d A t t e n t i o n ( X ) ) X' =LayerNorm(X + MultiHeadAttention(X)) X′=LayerNorm(X+MultiHeadAttention(X))
另一处的公式如下:
L a y e r N o r m ( X ′ + F e e d F o r w a r d ( X ′ ) ) LayerNorm(X' + FeedForward(X')) LayerNorm(X′+FeedForward(X′))
X ′ X' X′ 是第一个 Add & Norm 操作的输出,然后 F e e d F o r w a r d ( X ′ ) FeedForward(X') FeedForward(X′) 是前馈全连接网络对 X ′ X' X′的处理结果。 这两部分相加后再输入到Layer Normalization。这样命名有助于清晰地表示每个步骤处理的是不同阶段的数据。
搞明白了输入信息现在来看下为什么这个层的命名是Add & Norm?模块内部做了什么?
Add
在深度学习领域,存在一种普遍的期望:模型越深,其性能应该越优秀。然而,现实中的挑战是,随着模型层次的加深,模型可能开始“忘记”初始层输入的数据形态,这会导致性能的逐步下降。为了解决这一问题,残差网络(ResNet)的概念应运而生。残差网络通过引入残差连接(即
X
+
f
(
X
)
X + f(X)
X+f(X) 的形式)来防止信息的丢失,其中
X
X
X 代表某层的输入,而
f
(
X
)
f(X)
f(X) 表示该层对输入
X
X
X 进行处理后的结果。这样的设计使得深度模型能够保持或提升其性能,而不是因深度增加而遭受性能损失。下图是残差结构:
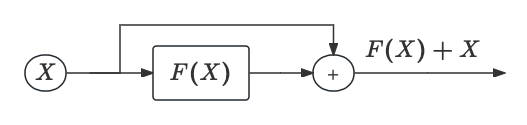
Transformer模型采用了类似的思想,其内每个Encoder层后面都跟随着一个残差连接和层归一化(Layer Normalization)的组合。这种结构的一个关键思想是让原始输入信息能够直接传递到后续层次,从而让模型在进行深层计算时,仍然保留对初级信息的“记忆”。此外,Transformer模型通常包含多层的Encoder block堆叠起来作为编解码器架构的组成部分,而每一层的残差连接都是实现这种复杂网络高效学习与信息传递的必要手段。
通过这种方式,Transformer以及残差网络解决了深度模型中潜在的“遗忘”问题,确保了信息在模型的每一层都得到有效的保持与利用,进而提升了模型的整体性能。
Norm
当前阶段使用的层归一化操作,对数据进行归一化处理本质上就是为了增加模型的收敛速度,还有就是方便计算,和上文中的残差网络属于常见的Trick。当然这部分存在可以细聊的知识,篇幅原因本章节不做过多赘述,想了解的读者可以参看台大Hung-yi Lee的机器学习课程。
2.4.2 Feed Forward
在Transformer架构中,前馈全连接网络(Feed Forward Network,简称FFN)是每个Encoder和Decoder层中的一个关键组成部分,它对自注意力层(Self-Attention Layer)或跨注意力层(Cross-Attention Layer,仅Decoder使用)的输出进行进一步的处理。这个前馈网络相对于注意力机制来说,是一种更加标准的神经网络层,但在Transformer模型中起到了非常重要的作用。
Transformer模型中的前馈全连接网络包括两个线性变换和一个非线性激活函数,这个过程可以用以下公式表示:
FFN ( x ) = max ( 0 , x W 1 + b 1 ) W 2 + b 2 \text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2 FFN(x)=max(0,xW1+b1)W2+b2
其中, x x x 是网络的输入, W 1 W_1 W1 和 W 2 W_2 W2 是权重矩阵, b 1 b_1 b1 和 b 2 b_2 b2 是偏置项, max ( 0 , ⋅ ) \max(0, \cdot) max(0,⋅) 是ReLU(Rectified Linear Unit)激活函数。
自注意力层和前馈全连接网络的差别:
-
自注意力层:这个部分的确是以矩阵的形式处理整个序列,这使得每一个位置都能同时关注到序列中的所有其他位置。这种处理方式利用并行化计算的能力,能够高效地处理整个序列。因此,自注意力机制可以视作是对整个输入数据进行一次全局映射的操作。按行操作
-
前馈全连接网络(FFN):这部分的处理方式与自注意力层不同,它确实是按序列中的每一行(即每个位置)独立进行处理。对于序列中的每个元素,FFN应用相同的变换,但不会考虑到序列中的位置关系,每个元素的处理是独立的。即使这看起来似乎不利于并行计算,但实际上现代硬件(如GPU)能够高效地并行处理这种按位置独立的操作。按向量位操作
因此,自注意力层通过矩阵运算实现了各个向量之间的加权求和修改向量表示从而获取到了全剧信息,而前馈全连接网络则独立地对每个位置进行处理,在更细的力度上着眼修改嵌入表示,所实现的功能不同,集合起来效果更佳。
2.4.3 Encoder的输出
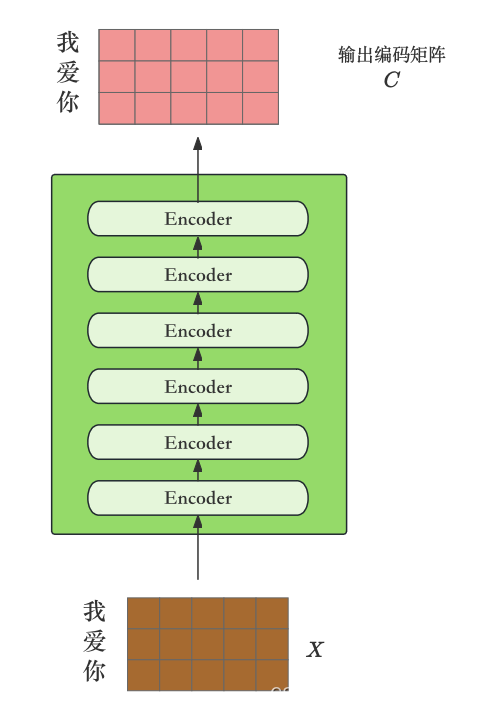
上文提到的Encoder由多个关键部件组成,包括多头注意力(Multi-Head Attention)、Add & Norm 层和前馈全连接网络(Feed Forward)。这些组件共同构建一个基本单元,称为Encoder block。在Transformer的架构中,通常会堆叠六个这样的Encoder blocks来形成完整的编码器。编码器的最终输出是一个编码矩阵,其中每个句子经过向量化后,每个token对应矩阵的一行。这样的设计确保了每个token不仅包含了自身的信息,还融合了上下文的语义,从而得到一个全面的表示。具体细节如下:
最后一个 Encoder block 输出的矩阵就是编码信息矩阵
C
C
C,在解码器阶段编码信息矩阵
C
C
C会用于指导生成解码信息。简单的说就是会传入到Decoder中使用。
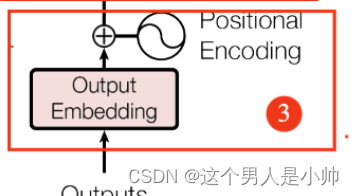
2.5 Decoder模块的输入
上文中,探讨了从输入数据到编码器(Encoder)编码的完整过程,最终形成了编码信息矩阵 C C C ,该矩阵承担着指导解码器(Decoder)进行工作的重任。在接下来的内容中,将解读解码器模块(Decoder)的输入信息。即下图中整体框架部分3的内容。
由于模型结构的独特性,在训练和测试阶段,解码器的输入信息会有所不同,因此,将分别对这两个部分进行详尽的阐释。
2.5.1 训练阶段Decoder的输入:
首先讲训练部分:
上文中详述了在Transformer的编码器部分,模型会先将输入序列 (“ 我爱你” 的独热编码) 中的每个词通过预训练的Word2Vec模型转换为词向量,然后将这些词向量与位置编码相结合,训练阶段的输入则是 <Start> I love you 中的每个词通过预训练的Word2Vec模型转换为词向量和位置信息的融合的结果。具体如下图:
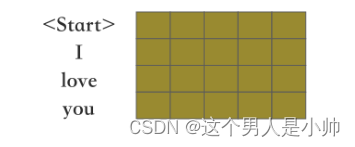
为什么是要预测的真实结果和开始符号的向量表示矩阵呢作为训练阶段的输入呢?
这是由于模型采用了 Teacher Forcing技术 用于加快模型的训练。
2.5.1.1 Teacher Forcing
在没有Transformer之前翻译任务的结构都是通过RNN实现的,想补课的同学请看这里,RNN是一个串联的结构,在翻译当前时间步(词)的时候需要考虑模型上一个时间步的输出结果,那么在生成当前时间步收到了上一个时间步生成的错误信息,这就会导致当前时间步接受的输入都是错误的,那么生成正确的信息的难度很大,只能依赖于当前时间步的输入信息了,==(注意这里说的是输入并不是上一个时间步的输出信息)==这样的话不就是越翻译越跑偏吗?大大降低了模型的性能以及增加模型的训练时间。
如何改善这一问题呢?
可以使用Teacher Forcing这一技巧。在训练过程中,并不使用模型的预测作为下一个时间步的输入,而是直接使用上一个时间步正确的结果。这种方法能够加快模型学习的速度,并提高其性能。可以同时将全部答案(I love you ) 加上 开始符号(<begin>) 一起送入网络中,预测结果。
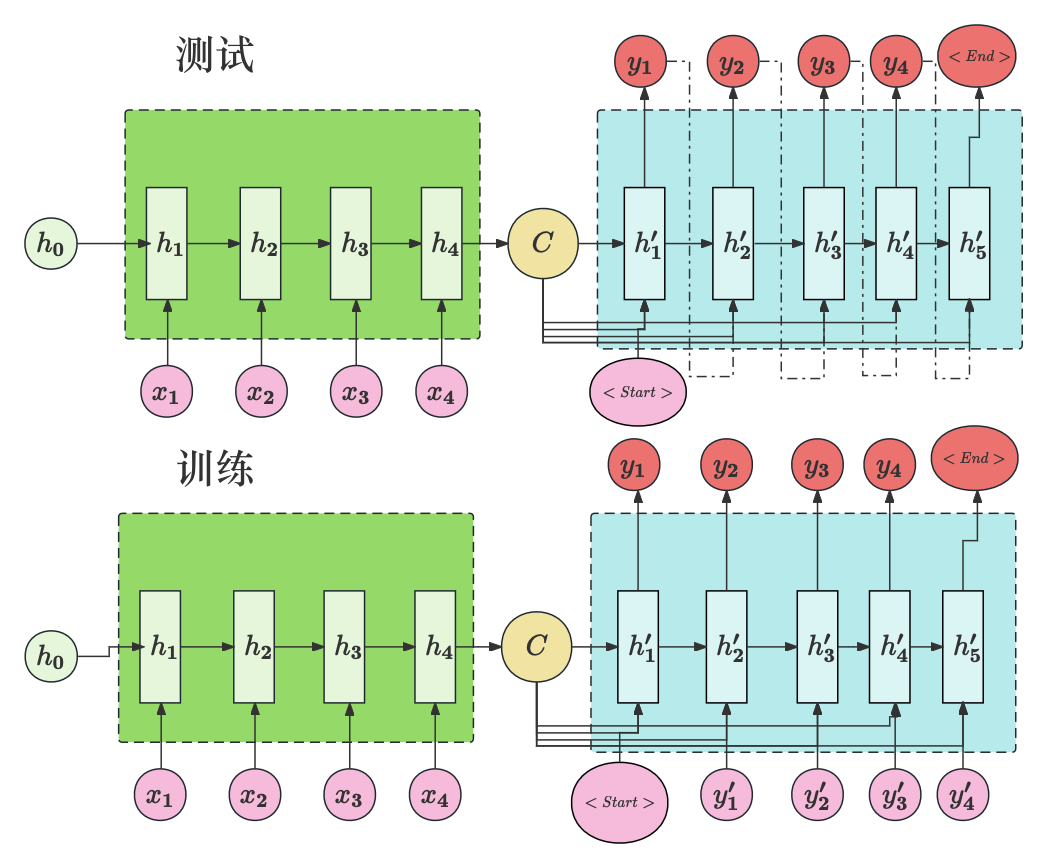
上图中描述了训练和测试之间引入了Teacher Forcing机制的差异,读者可以思考下认真观察这两部分的差异,图中使用 y ′ y' y′ 作为真实标签 ,测试阶段将输出作为下一个阶段的输入,而训练阶段则没有。反之训练阶段有真实值输入模型而测试则没有。因此观察解码器在每个时间步生成输出的依据包括以下三部分:
-
上一个时间步的隐藏状态:这包含了解码器在上一个时间步的计算结果和前面所有步骤的信息摘要。
-
上一个时间步的输出:在Teacher Forcing策略的训练过程中,这通常是真实的标签序列中的相应元素,而非模型预测的输出。
-
编码器生成的上下文向量 C C C :这个向量捕获了编码器对整个输入序列的理解。
这三者共同决定了解码器在当前时间步的输出结果,或者说是解码器在给定先前生成的序列和固定的上下文的条件下,对当前输出的预测。在预测下一时间步时,这一输出结果可能被作为输入(在训练时使用Teacher Forcing时是输入的则是真实数据),而当前的隐藏状态也会传递至下一时间步。
在Transformer架构中训练阶段Decoder模块的输入也采用了相同的机制,模型在训练时模型输入信息也是开始符号和需要预测真实结果。
上图中展示了模型的解码器部分整体架构,通过多个Decoder block进行拼接构成了整体的解码器,还有(外部的输入)这里一会再解释,在训练阶段引入了Teacher Forcing机制使用真实数据(<Start> I love you) 作为模型的输入,希望通过输入真实标签和(外部的输入)生成最终的翻译结果 (I love you <End>)。
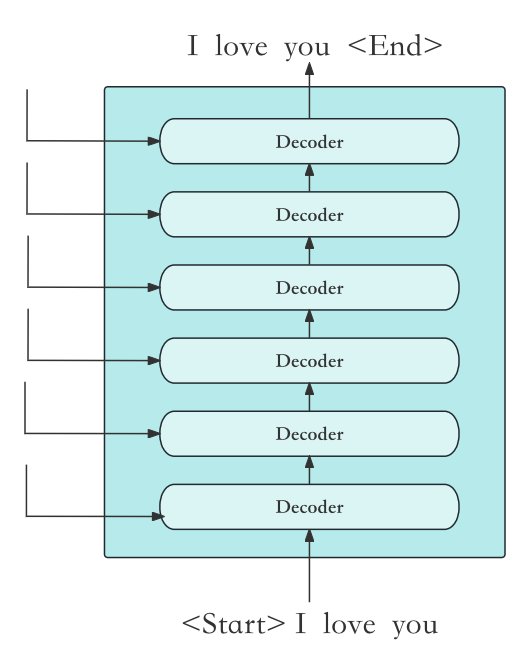
2.5.2 测试阶段阶段Decoder的输入:
Transformer模型在训练阶段受益于其自注意力机制的设计,可以高效地进行并行化处理。这意味着训练时,整个输入序列((<Start> I love you)可以一次性被模型处理,而不需要像循环神经网络(RNN)那样逐步处理序列的每个元素。这大大提高了训练的效率和速度。
然而,到了测试或者说是推理(inference)阶段,情况就发生了变化。在推理阶段,模型生成输出序列时,是逐步生成的,因为每一步生成的词都依赖于之前所有步骤中生成的词——这在进行翻译或任何类型的文本生成任务时都是如此。因此,尽管Transformer模型可以在训练阶段充分利用并行化计算,但在推理阶段却不能一次性得到整个输出序列。每次生成一个词后,都需要将到目前为止的输出序列重新送入模型,以生成下一个词。具体行为如下图所示:
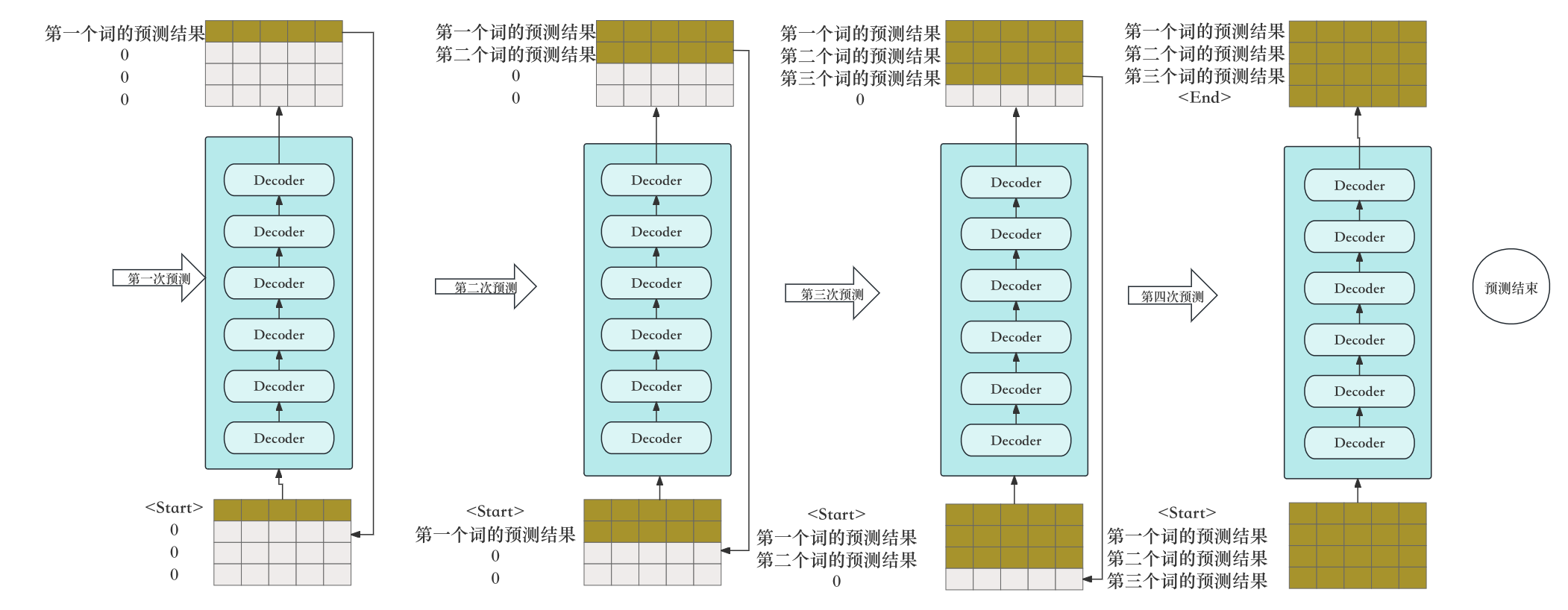
这一过程中,Transformer的优势之一——并行处理能力,在推理时不能完全发挥,因为在每个时间步,它需要等待之前的所有输出都被生成后,才能进行下一步的生成。尽管如此,通过某些技术,如缓存先前步骤的计算结果,可以在一定程度上提高推理阶段的效率。
读者可以详细对比下训练和测试的输入不同感受下模型的变化,在Transformer模型的训练阶段,由于使用了自注意力机制,解码器可以处理整个目标序列,并且所有的解码步骤可以同时进行。这是因为在训练时已经知道了整个正确的输出序列(真实的目标语句),所以可以利用它去一次性训练整个模型。这个过程中,可以并行计算不同位置的自注意力,从而极大地提升训练效率。这种计算目标序列中不同位置的自注意力的能力是Transformer模型的核心特性之一。
然而,在测试(或推理)阶段,情况就有所不同了。此时模型是没有接触到整个目标序列的,因此需要逐步生成每个输出词,并且在每次生成之后,都需要将到目前为止生成的序列反馈给模型,来预测下一个词。在这个过程中不能并行处理,因为每一步的输出取决于前面所有步骤的输出。因此,推理阶段确实需要运行多次解码器,每次输出一个新的词,然后包括这个词在内的序列再次作为输入,直到生成整个序列结束符号或达到预设的序列长度限制为止。
2.6 Decoder 的结构信息
在熟悉了Decoder模块的输入信息后,模型终于开始开始进行解码工作了,上文汇总也详述了模型和Encoder模块一样同样是由多个Decoder block模块构成,对输入信息进行解码。下面小节主要是针对图中解码器的部分进行详解。
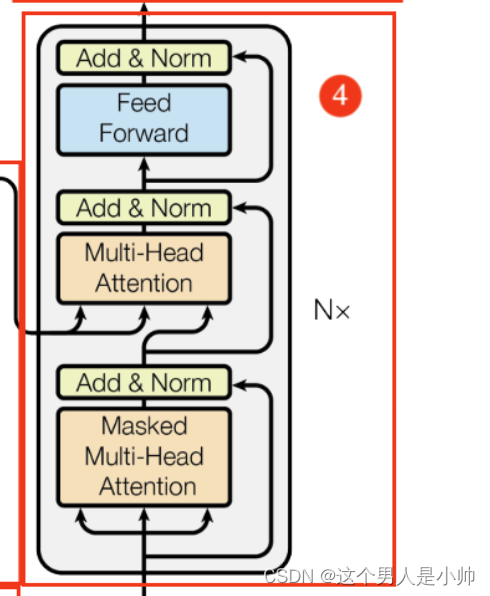
即上图中整体框架部分4的内容。简单的看下Decoder是由Masked Multi-Head Attention、Add & Norm、 Multi-Head Attention、Add & Norm、Feed Forward,Add & Norm 这些小模块组成的。前文中已经对 Multi-Head Attention、Add & Norm、Feed Forward等模块进行了详细的解释,本章只对部分进行细化讲解。
2.6.1 Masked Multi-Head Attention
首先就迎来了第一个问题为什么Decoder模块中要有一个Masked呢,为什么不采用Multi-Head Attention?
思考一下模型在测试的时候,使用真实数据(\<Start> I love you)作为输入看起来好像没什么问题,但是仔细想想,RNN使用Teacher Forcing机制模型时顺序翻译的,使用<Start>预测 I ,逐步的翻译,但是Transfomer是并行化注意力结构如果在使用自注意力机制的时候融合<Start>的向量聚合到了I 向量的信息这不就是看到答案了吗?那不就是失去了效果,真的有用不也是作弊得到的嘛,故此为了不让模型的注意力机制看到答案引入Mask 机制解决这一问题。
Mask 机制具体是如何实现的呢?
其实很简单就是构建一个只有0和1的矩阵,这个矩阵的维度和训练输入信息的维度是一致的。即当前例子中训练输入4个向量(<Start> I love you) 那这个矩阵就是一个4*4的矩阵,具体形式如下:
矩阵之所以被称为mask矩阵就是需要它遮盖东西,还有哪个矩阵的形状和这个mask矩阵一致呢?就是测试阶段的decoder输入矩阵(<Start> I love you) 生成的
Q
K
T
QK^T
QKT注意力系数矩阵。
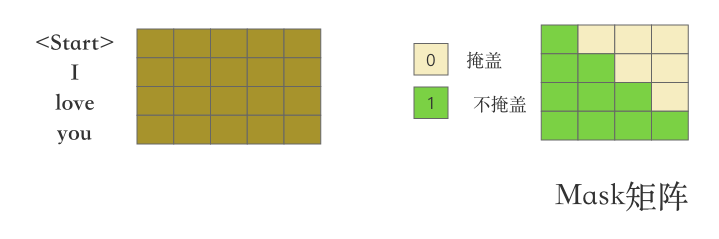
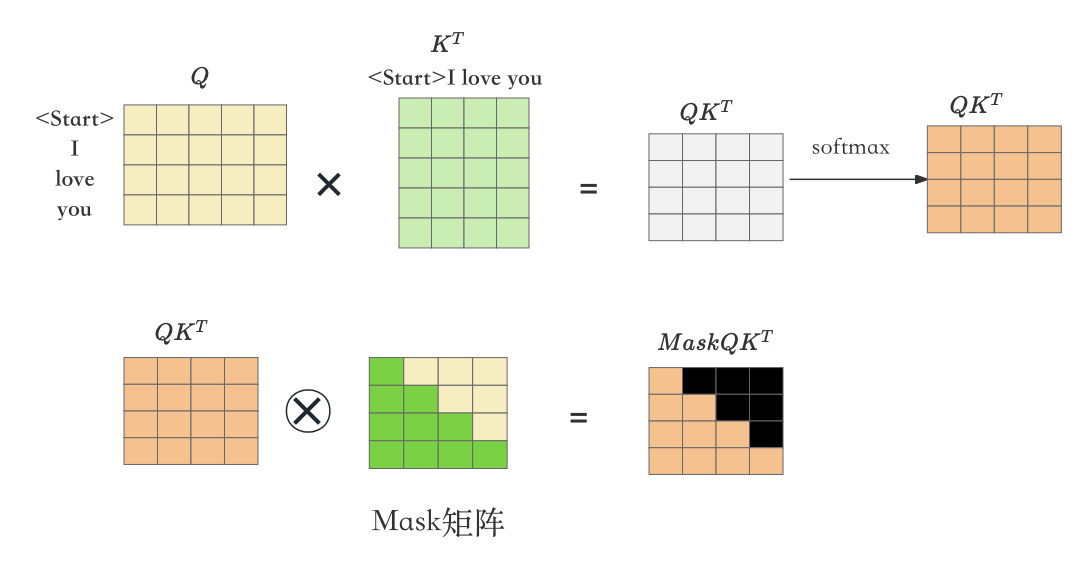
在Transformer模型的Decoder部分,生成mask矩阵的根本目的是为了实现遮挡效果。这个遮挡是针对由测试阶段的输入序列( “ I love you”)生成的注意力系数矩阵而言的。通过这样做,确保了在计算注意力系数后,所谓的"黑色区域"(mask遮挡的部分)其值为0。这意味着,在聚合其他单词向量以生成第一个单词 “” 的向量时,其实是无法聚集到后续单词提供的有效信息的。这种机制有效地防止了模型在生成过程中“偷看”后面的单词,从而确保了生成结果的可靠性和公平性。为了更深入理解这一点,建议手动计算相关的注意力系数,以便更清晰地把握其工作原理。
训练的时候防止偷看可以使用 Masked Multi-Head Attention 那么测试的时候模型不知道答案啊是不是就不需要这个机制了呢?
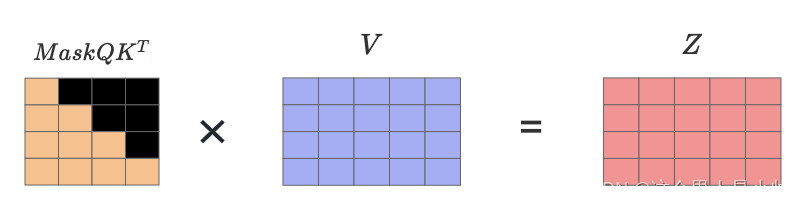
在讨论了模型在测试阶段的输入和输出逻辑后,可以注意到,在模型预测的起始阶段,第一次输入开始字符输出第一个单词的预测,而第二次则是输入了两个有效的向量去预测两个两个向量,第一个词被预测的次数随着模型预测的次数增加,如果需要预测n个单词那么第一个词就会被预测n次,输入序列会逐渐增加更多词向量,从而影响后续单词的预测。具体来说,随着预测过程的展开,模型对于每个新预测的单词,都需要重新考虑之前所有已预测的单词。 因此,若不采用mask机制,模型在预测第一词时所依据的信息将随每一次预测的增加而累积,导致第一个单词的预测结果可能不断变化,甚至出现偏差。这是因为,在没有mask的情况下,每次预测第一个单词时,模型都能“看到”随后生成的信息,这破坏了自回归模型在时间序列上的条件独立性。
总结一下:
- 在不使用mask机制的情形下,同一个单词在模型不同时间步的预测结果会出现不一致现象,这显得模型较为粗糙,并且由于引入了未来的信息,违反了序列预测的基本原则。
- Mask机制对预测过程的每一步都有重要影响,能够避免信息的未来泄露,保障了预测任务的准确性。
- 正确实现mask机制虽然增加了模型架构的复杂性,但相比于修改模型,这种一致性方法更合逻辑,无论是在训练阶段还是测试阶段都能保持模型的稳健性。
上文中可以看到Masked Multi-Head Attention层使用了Mask矩阵去掩盖后续的信息,而Multi-Head Attention注意力部分是相同的并没有什么特殊的地方,后续的残差连接以及Norm模块都是相同的操作。
2.6.2 Multi-Head Attention
值得注意的是Decoder模块中的第二个Multi-Head Attention模块,比较特殊的是其他的Multi-Head Attention三个输入信息都是通过输入数据转换过来的,简单点说就是都是通过输入信息经过不同的
W
W
W 层转换成了
Q
,
K
,
V
Q,K,V
Q,K,V矩阵用于进行自注意力的计算,但是当前的模型三个
Q
,
K
,
V
Q,K,V
Q,K,V,来自两个不同的输入数据。先看下图:
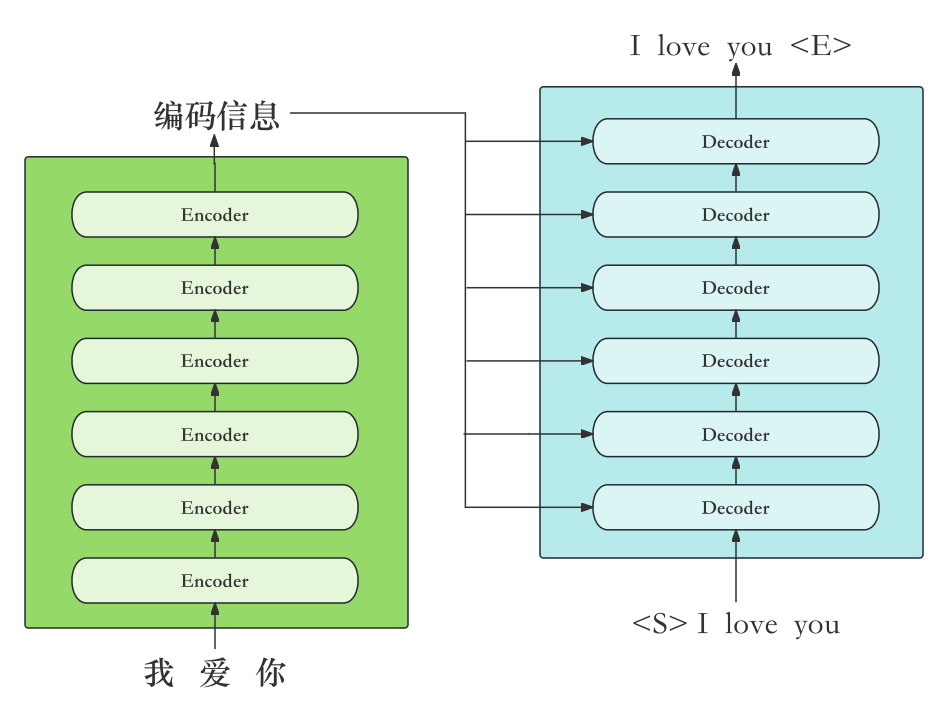
Encoder部分生成的编码信息 C C C,会被用来指导每一个Decoder block进行解码。就是说上文中的第二个Multi-Head Attention层的三个 Q , K , V Q,K,V Q,K,V 两个来自编码器一个来自解码器的输入。论文中给出的实际上 K 、 V K、V K、V矩阵输入源来自Encoder的输出编码矩阵,而 Q Q Q 矩阵是由经过Add & Norm层之后的输出计算来的。
这样在翻译的过程中就可以看到编码器对 "我爱你"这句话的编码信息,还能看到模型已经解码的部分信息,这样做的优点就是解码的过程中,每一位单词都可以利用到 Encoder 所有单词的信息,这也是为什么使用解码器的输出作为 Q Q Q 而不 V V V 的原因,这样每一个单词的反对都会收到编码器输出的影响,从而有效的捕获翻译所需的信息。
后续的Add & Norm、Feed Forward模块和Encoder一致本文就不再过多赘述了。
2.7 Decoder模块的输出
在翻译任务中,模型本质上是通过多分类机制来进行工作的。具体而言,模型会将每个输入向量通过线性变换层处理,然后传入softmax层来预测每个词的概率分布。这个过程会产生一个矩阵向量,其中每一行代表一个单词的向量信息。通过使用这些向量信息,并将其通过线性层及softmax层处理,模型便能够进行最终的预测。
以一个包含"I"、“love”、“you”、“today”、“me"五个单词的简单例子来说明,对于目标词"I”,模型的输出概率分布可能呈现为[0.5,0.1,0.1,0.2,0.1]。在这个概率分布中,“I"位置的概率值最高,因此,模型预测的第一个单词便是"I”。
如果对这部分有疑问的读者可以参看本专栏的word2vec下的文章,里面提供了针对翻译问题的多分类优化解读(层次softmax哈夫曼编码)以及文章翻译过程的详解。
三、总结
本章节旨在通过整理模型的输入输出部分,帮助读者全面、深入地理解当前模型的工作机制,为学习后续的多模态技术与新型模型打下坚实的基础。文中为了让读者更易于理解,对某些情况的解释可能简化或略带主观,如有疑问或需要深入探究的地方,诚邀各位在评论区提出宝贵意见。本章内容参考了部分大佬的文章与分析,以期在准确性与可读性之间寻得平衡。若对某些观点存有异议,建议阅读原始文献以获得更深入的理解。
希望通过本章节的阐述,能够为读者提供一个清晰的框架,从而更好地把握多模态技术和新兴模型的概念与应用。如有任何问题或建议,欢迎大家积极交流,共同进步。